서론
dacon에서 진행되는 따릉이 대여량 예측 AI 경진대회에 참가했다. 대회는 22년 6월 13일에 시작했는데, 나는 대회를 조금 늦게 확인해서 1주일이 지난 6월 20일부터 시작했다. 대회를 계속 진행하면서 내가 시도한 내용들, 깨달은 내용들을 정리하면 더 좋을 것 같아서 2달동안 잊고지냈던 velog를 켰다.
대회 링크 : https://dacon.io/competitions/open/235915/overview/description
주어진 데이터나 대회의 목적 자체는 심플하다. 18년도부터 20년도까지의 데이터를 훈련시켜 21년도의 데이터를 예측하는 것이다. 데이터는 대여량을 포함해 온도, 습도, 강수량, 미세먼지 농도, 풍속 등 기후 데이터가 주어진다.
본론
거두절미하고 먼저 데이터를 불러와서, 데이터가 어떻게 생겼는지부터 확인해보자.
데이터 반입
import pandas as pd
train = pd.read_csv('train.csv')
test = pd.read_csv('test.csv')
sample_submission = pd.read_csv('sample_submission.csv')데이터 요약
train.describe().transpose()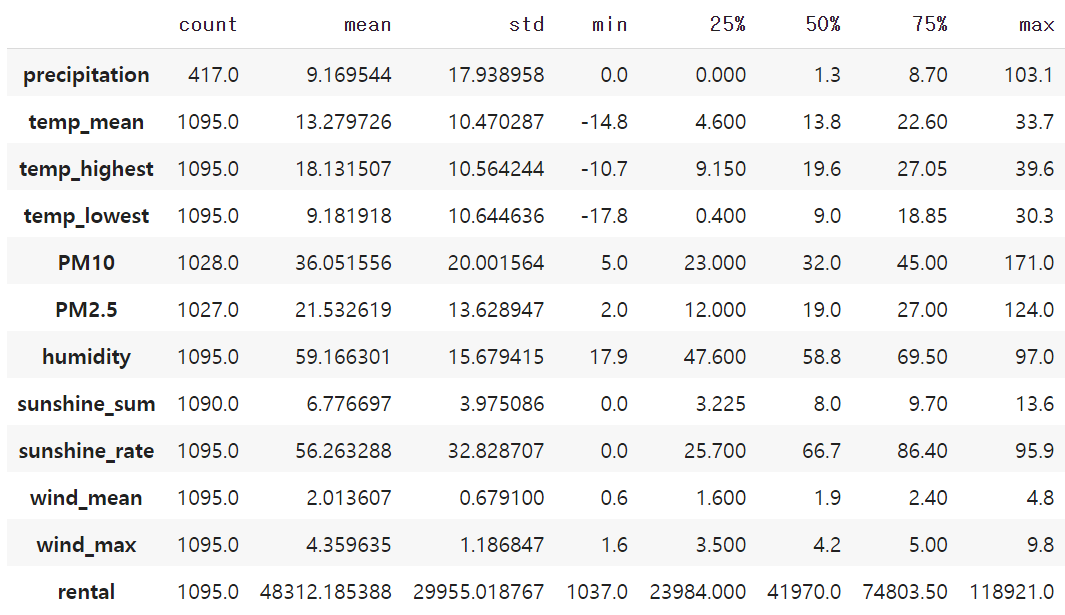
transpose를 하거나 말거나는 취향 차이인데, 나는 확실히 transpose해서 dataframe을 확인하는게 깔끔하더라. transpose를 안하면 column명의 길이때문에 dataframe이 가로로 늘어진다.
데이터 요약을 보고 떠오르는 점은 2가지다.
- precipitation, PM10, PM2.5, sunshine_sum 변수에 결측치가 존재한다(count수가 다른 column에 비해 부족).
- 변수마다 scale이 달라서, scale을 조정해줄 필요가 있어보인다.
결측치 확인
train.isna().sum()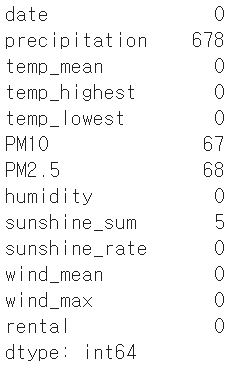
예상대로 앞서 말한 4개 변수에 결측치가 존재한다. 결측치의 비중이 극히 낮으면 무시해도 모델의 학습에는 큰 영향이 없겠지만, 이번 경우는 다르다. precipitation은 절반 이상이 결측치다. PM10, PM2.5도 6% 가량이 결측치다. 또한, precipitation(강수량)은 딱 봐도 따릉이 대여량과 관계가 있어보이는 변수다. 보통은 비가 오는 날에는 자전거를 잘 안타지 않나? 여하튼, 결측치는 어떻게든 처리해주도록 하자.
결측치 처리
결측치 처리에도 다양한 방법이 있는데, 크게 나누면 2가지다.
1. 결측치가 포함된 row 제거
완전한 데이터가 아니니, 아예 그 row 자체를 사용하지 않는 방법이다. 데이터가 넘쳐나면 이렇게 처리하는 것도 좋다
2. 특정 값으로 대체
결측치를 특정한 값으로 대체한다. 즉, 앞의 1번 방법과는 달리 결측치가 포함된 row를 어떻게든 활용하자는 주장이다. 이 방법에도 여러가지가 있는데, 가장 단순한 방법은 0, mean 등의 데이터로 일괄 대체하는 것이다. 조금 복잡한 방법은 모델을 사용하는 것이다. 본 데이터를 예로 들자면, 다른 변수들로 precipitation을 예측하는 regression 모델을 만들고, 모델의 예측값을 통해 결측치를 대체하는 방법이다.
어떻게 처리할 것인가?
결론부터 말하자면 precipitation은 random forest regressor를 통해 처리하고, 나머지 변수들은 보간법(interpolate)을 통해 처리하려고 했다. 근데 이게 멀리 돌아가는 방법이었다는 걸 나중에서야 알았다...
train['PM10'].interpolate(method = 'linear', inplace = True)
train['PM2.5'].interpolate(method = 'linear', inplace = True)
train['sunshine_sum'].interpolate(method = 'linear', inplace = True)주어진 데이터가 시계열(time series) 데이터이기 때문에 보간법을 사용해줬다. 보간법을 간단히 설명하면, 두 점이 주어졌을 때, 그 두 점 사이의 값을 추론하는 방법이다. 그래프를 통해 결과를 간단하게 시각화해보자.
결측치 처리 전
import matplotlib.pyplot as plt
plt.figure(figsize=(25, 10))
plt.plot(train['PM10'])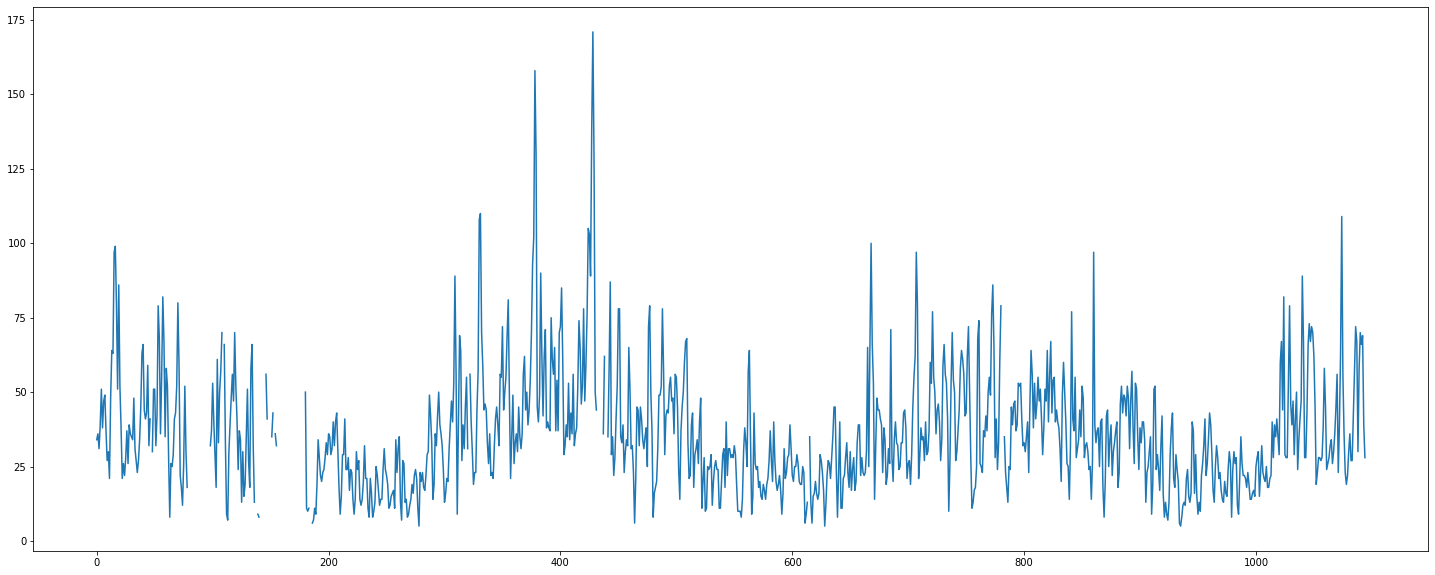
중간중간 line이 끊어진 구간을 확인할 수 있다. 다만, 한 눈에 들어온다는 느낌은 없다... 결측치가 연속적으로 존재하는 구간은 확인이 가능하지만, 연속적으로 존재하지 않는 구간은 확인이 어렵다. 결측치가 존재하는 구간을 highlight 해보자.
mv_list = list(train['PM10'][train['PM10'].isna()].index)
mv_timeline = []
start_time = 0
end_time = 0
start_switch = True
end_switch = True
for i in range(1, len(mv_list), 1):
if(start_switch == True):
start_time = mv_list[i-1]
if(end_switch == True):
end_time = mv_list[i-1]
if((mv_list[i] - mv_list[i-1] == 1) and (i != len(mv_list)-1)):
start_switch = False
end_switch = False
end_time = mv_list[i]
elif((mv_list[i] - mv_list[i-1] == 1) and (i == len(mv_list)-1)):
end_time = mv_list[i]
mv_timeline.append((start_time, end_time))
else:
mv_timeline.append((start_time, end_time))
start_switch = True
end_switch = True
plt.figure(figsize=(25, 10))
plt.plot(train['PM10'])
for mv in mv_timeline:
plt.axvspan(mv[0], mv[1], color='red', alpha=0.2)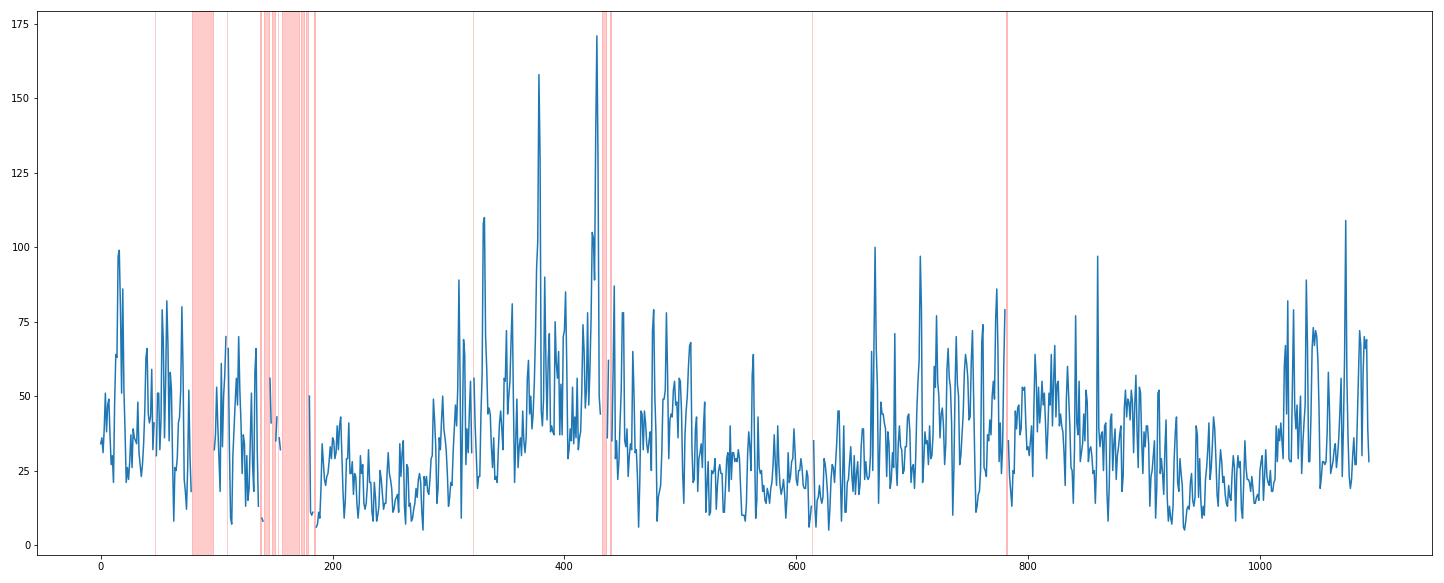
highlight하니 확실히 눈에 잘 들어온다! 결측치를 처리했을 때의 데이터도 동일한 방법으로 시각화해보자.
interpolate(linear)
plt.figure(figsize=(25, 10))
plt.plot(train['PM10'].interpolate(method = 'linear'))
for mv in mv_timeline:
plt.axvspan(mv[0], mv[1], color='red', alpha=0.2)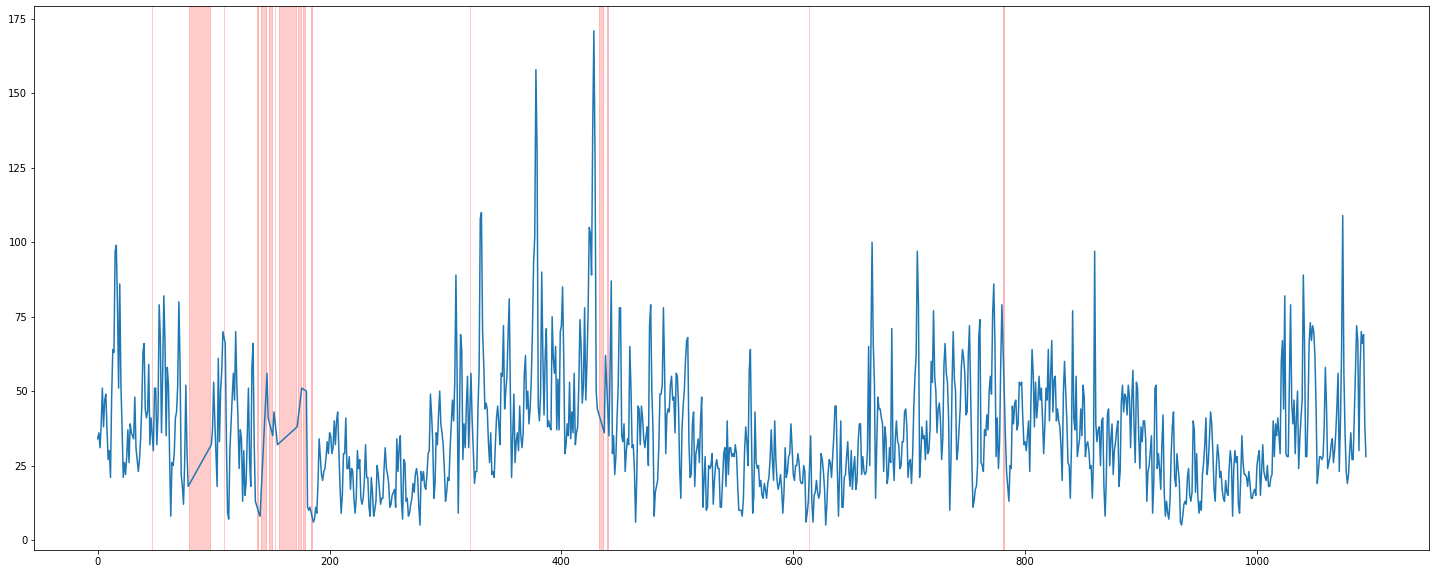
무난하지만, 기존 그래프의 형태와는 확실히 이질적이다. linear라 그냥 직선이다.
interpolate(quadratic)
plt.figure(figsize=(25, 10))
plt.plot(train['PM10'].interpolate(method = 'quadratic'))
for mv in mv_timeline:
plt.axvspan(mv[0], mv[1], color='red', alpha=0.2)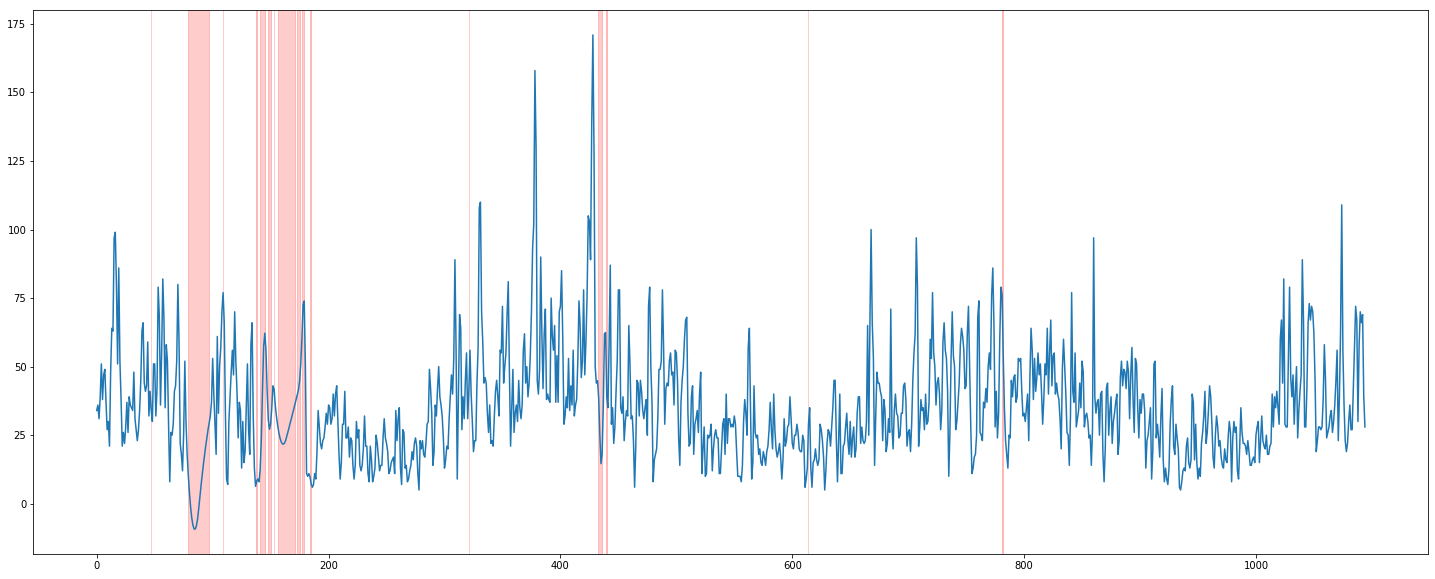
quadratic은 특정 구간에서 음수를 반환한다. 이건 안 된다.
interpolate(polynomial)
plt.figure(figsize=(25, 10))
plt.plot(train['PM10'].interpolate(method = 'polynomial', order=3))
for mv in mv_timeline:
plt.axvspan(mv[0], mv[1], color='red', alpha=0.2)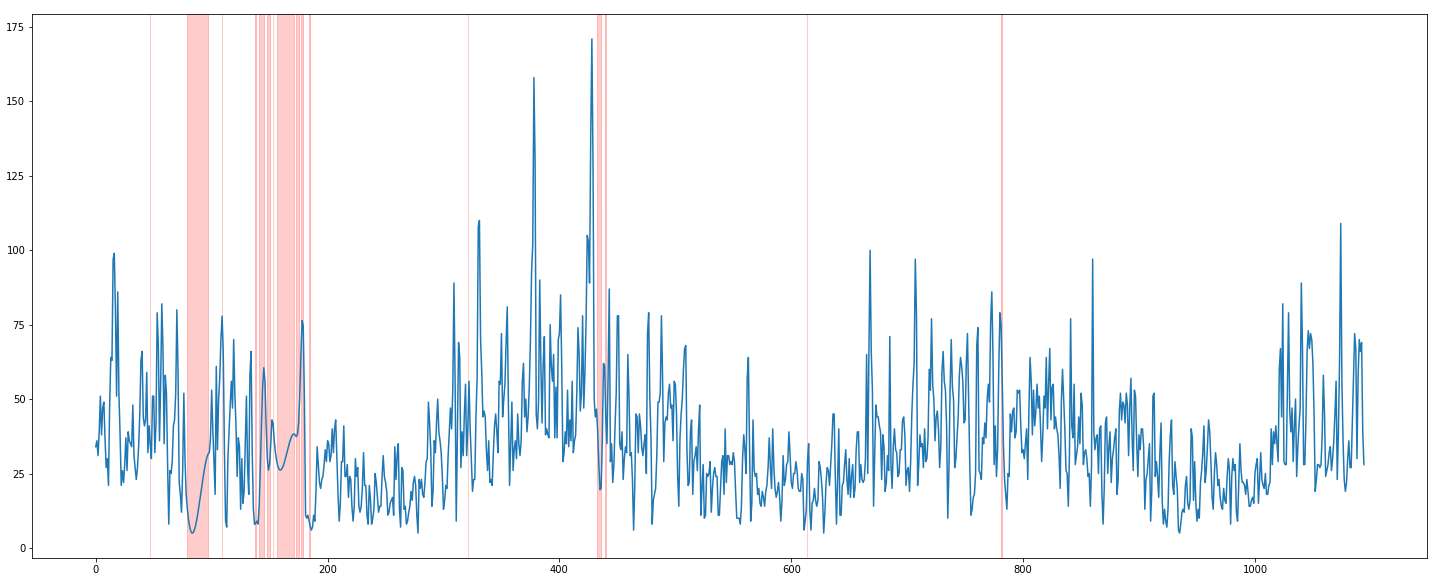
그래프로 보았을 때에는 훨씬 낫다. 다만, 확실히 모델을 사용해서 결측치를 처리한다면 그래프의 모양이 더 자연스러워지지 않을까 한다. 물론 이 경우에서는 나머지 데이터를 통해 미세먼지 농도를 예측하는건, 변수 간의 연관성이 없어보여 힘들 것으로 예상되기에, 이 정도에서 만족하자.
따릉이 대여량 확인(y)
우리가 예측하고자 하는 변수(y)인 rental도 시각화해보자. 수치로 확인하는 것도 좋지만, 시각화하여 확인하면 여러모로 한 눈에 알기 쉬워서 편하다.
plt.figure(figsize=(25, 10))
plt.plot(train['rental'])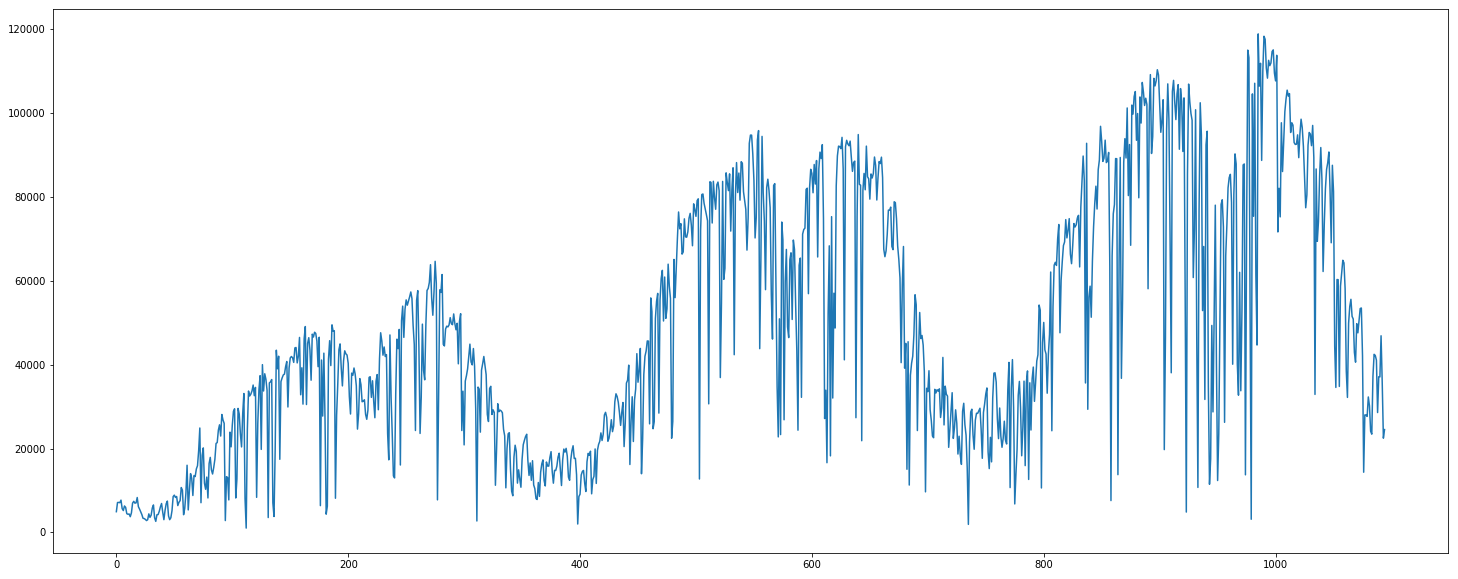
대여량 그래프를 보고 떠오른 점은 2가지다.
1. trend가 존재한다 : 따릉이 대여량은 매 년 성장중이다.
2. seasonality가 존재한다 : 여름, 겨울은 대여량이 적고, 봄, 가을은 대여량이 많다.
2번의 경우는 사실 사전에 어느정도 예상했던 내용이었다. 사계절이 뚜렷한사실 점점 희미해지고 있지만 우리나라는 자전거와 같은 야외활동의 경우 계절의 영향을 받을 수 밖에 없다. 이 부분은 이후에 계절 변수를 추가한 이후 다시 시각화해보자.
1번의 경우는 조금 놀랍긴 하다. 따릉이 서비스가 시작된 지 몇 년이 지났음에도 대여량은 계속 성장중이다. 얼핏 봐도 20년도 대여량은 18년도에 비해 2배가량 성장했다.
요일, 계절 변수 추가
요일, 계절 변수를 추가해보자. 2020, 8, 31 등의 숫자로 넣어주는건 당연히 안된다. 높은 숫자일수록 영향력이 커지기 때문이고, 실제 날짜가 갖는 의미를 정확히 반영하는 것도 불가능하다. one-hot-encoding을 통해 추가해주자.
def month_to_season(x):
if(x in [3, 4, 5]):
return 'spring'
elif(x in [6, 7, 8]):
return 'summer'
elif(x in [9, 10, 11]):
return 'fall'
elif(x in [12, 1, 2]):
return 'winter'
train['date'] = pd.to_datetime(train['date'])
test['date'] = pd.to_datetime(test['date'])
train['day'] = pd.DatetimeIndex(train['date']).day
test['day'] = pd.DatetimeIndex(test['date']).day
train['month'] = pd.DatetimeIndex(train['date']).month
test['month'] = pd.DatetimeIndex(test['date']).month
train['year'] = pd.DatetimeIndex(train['date']).year
test['year'] = pd.DatetimeIndex(test['date']).year
train['weekday'] = pd.DatetimeIndex(train['date']).weekday
test['weekday'] = pd.DatetimeIndex(test['date']).weekday
train['season'] = train['month'].apply(month_to_season)
test['season'] = test['month'].apply(month_to_season)
train = pd.get_dummies(data = train, columns = ['season'], prefix = 'season')
train = pd.get_dummies(data = train, columns = ['month'], prefix = 'month')
train = pd.get_dummies(data = train, columns = ['year'], prefix = 'year')
test = pd.get_dummies(data = test, columns = ['season'], prefix = 'season')
test = pd.get_dummies(data = test, columns = ['month'], prefix = 'month')
test = pd.get_dummies(data = test, columns = ['year'], prefix = 'year')
train['year_2021'] = 0
test['year_2018'] = 0
test['year_2019'] = 0
test['year_2020'] = 0계절 변수를 추가했으니, 시각화해서 확인해보자. 코드는 앞서 결측치를 highlight할 때 만든 코드와 같은 방식이다.
plt.figure(figsize=(25, 10))
plt.plot(train['rental'])
for t in summer_timeline:
plt.axvspan(t[0], t[1], color='red', alpha=0.2)
for t in winter_timeline:
plt.axvspan(t[0], t[1], color='skyblue', alpha=0.5)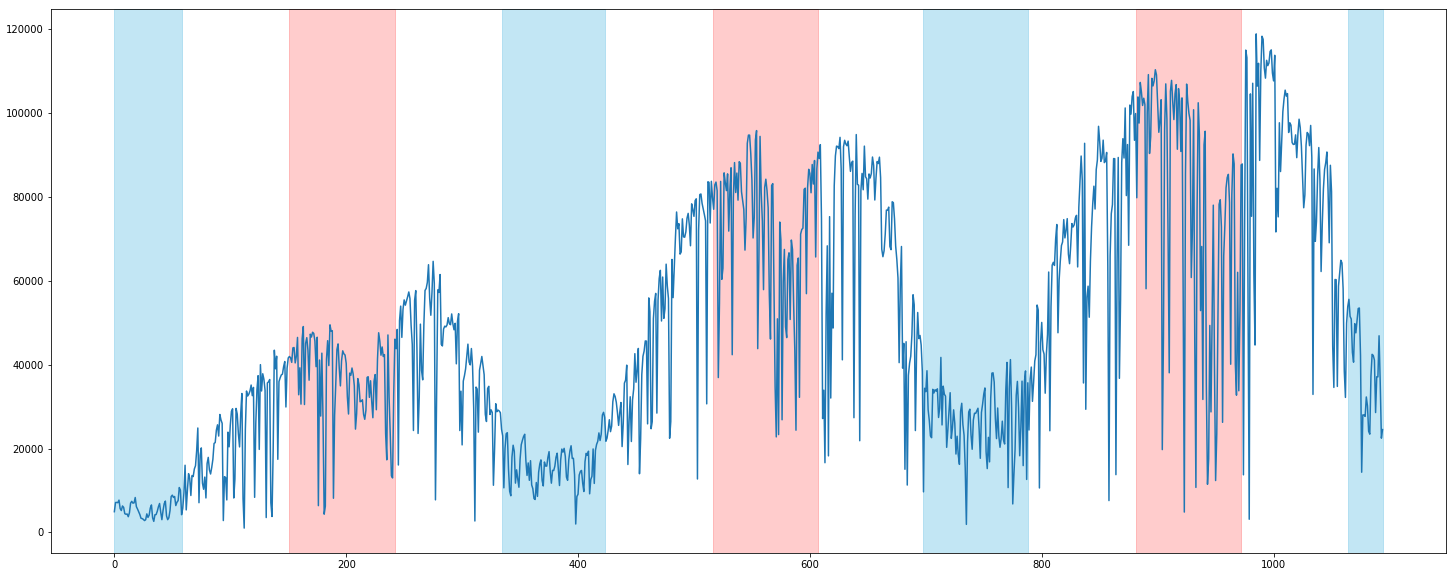
계절은 따릉이 대여량에 확실히 영향을 미치고 있다. 정확히는 온도일 것이다. 날씨가 포근하면 따릉이를 많이 타고, 너무 덥거나 추우면 따릉이를 잘 안탄다.
늦게 나온 것 같지만 사전 조사(domain knowledge)
데이터 분석을 할 때에 해당 domain에 대한 knowledge가 있다면 좋겠지만, 그렇지 않은 경우도 있다. 그럴 때에는 해당 domain에 대해 조사하면 큰 도움이 된다. 사실 도움이 된다기보다는, 어느 정도의 domain knowledge는 필수다.
- 자전거 이용 인구 1340만 명 - 그 중 330만 명은 매일 자전거 이용
- 연 1회 이상 이용하는 사람이 전체의 35.2%
- 월 1회 이상 이용자가 33.5%
- 주 1회 이상 이용자가 25.6%
- 매일 이용하는 사람이 8.3%
출처 : https://www.koti.re.kr/user/bbs/BD_selectBbs.do?q_bbsCode=1005&q_bbscttSn=20170309140233834
- 이용시간, 거리
절반 이상(56.4%)이 출퇴근 시간대에 집중
71%가 4km 이내 단거리 이용자
57%가 20분 이내 이용
- 계절, 날씨
또, 자전거 타기 좋은 계절인 봄‧가을철에 이용률이 가장 높은 가운데, 여름철에 비해 겨울철에 이용건수가 크게 줄어드는 양상을 보여 ‘더위’보다는 ‘추위’가 따릉이 이용에 더 영향을 주는 것으로 나타났다.
‘더위’보다 ‘추위’에 민감하고 비오는 출‧퇴근길엔 이용량 감소 봄~가을철에 비해 기온이 영하권으로 떨어지는 겨울철에 이용건수가 일 2만 건 이하로 크게 감소
특히 비 내리는 출‧퇴근시간대에 이용량이 급격히 감소
- 요일
주말에도 주중과 이용량에서 큰 차이를 보이지 않았다
출처 : 서울시 보도자료
위의 두 보도자료를 통해 귀중한 정보를 얻을 수 있었다.
- 주 이용층은 직장인 : 출퇴근 시에 사용
- 대부분 단거리 이동시 사용
- 더위보다는 추위가 더 큰 영향
- 요일별 이용량에 유의미한 차이는 없음

위 이미지처럼 익스트림한 라이딩을 즐기는 이용자보다는 평범한 직장인이 다수라는 것
이미지 출처 : 네이버 웹툰 윈드브레이커
다음 포스트에서는 모델링한 내용을 적어볼까 한다.
