운영체제
1.[운영체제] 2. Introduction to Operating Systems
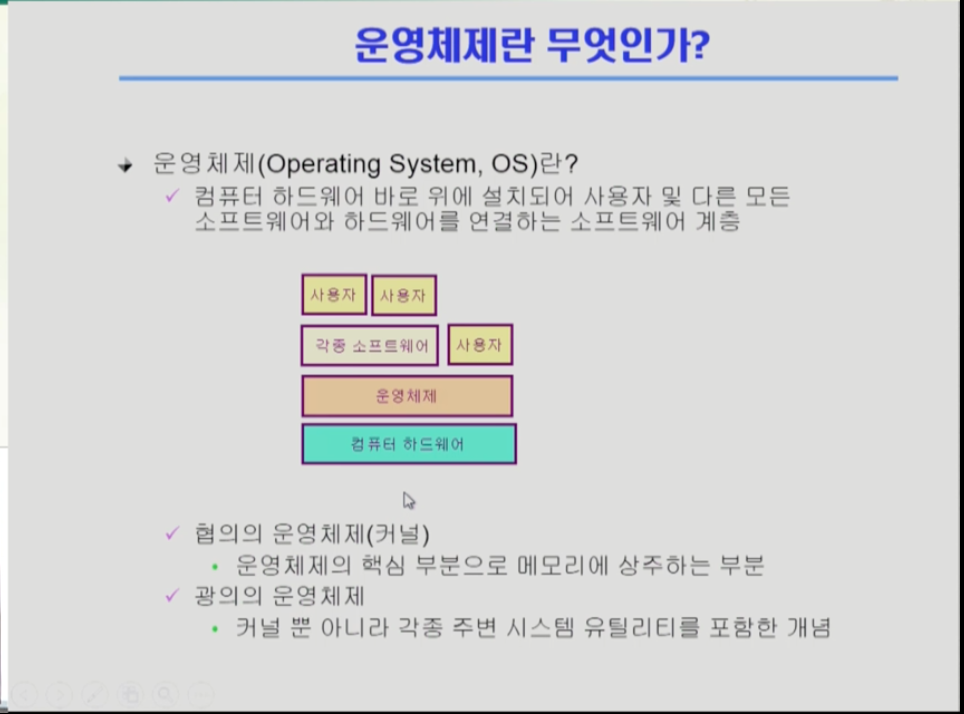
운영체제는 하드웨어 바로 위에서 사용자와 소프트웨어가 하드웨어에 접근하고자 할때 이를 연결하는 소프트웨어 계층이다.협의의 운영체제(커널)은 메모리에 상주하는 운영체제의 핵심이며, 광의의 운영체제는 커널 뿐 아니라 각종 주변 시스템 유틸리티를 포함한 개념이다. 보통 운영
2.[운영체제] 3. System Structure & Program Execution 1

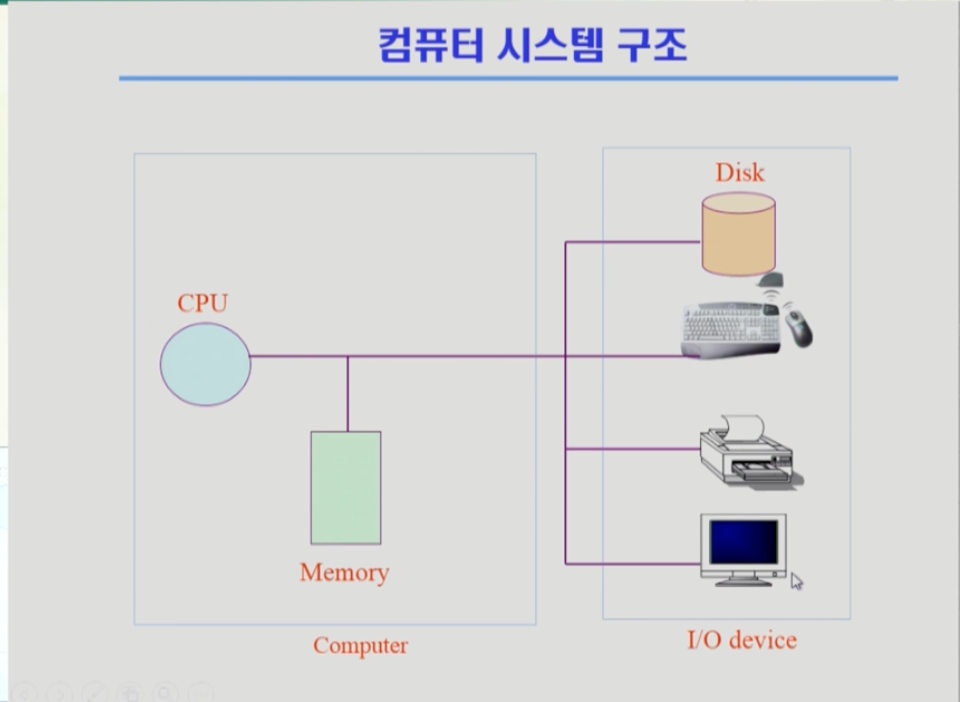
다음은 컴퓨터 시스템의 구조를 나타낸 그림이다. i/o 디바이스의 데이터가 컴퓨터로 넘어가면 인풋, 컴퓨터에서 i/o 디바이스로 가면 아웃풋이다.cpu는 매 클럭 사이클마다 메모리에서 지시를 하나씩 읽어 실행한다.인풋 디바이스에서 입력을 하여 컴퓨터로 들어가고 컴퓨터가
3.[운영체제] 4. System Structure & Program Execution 2
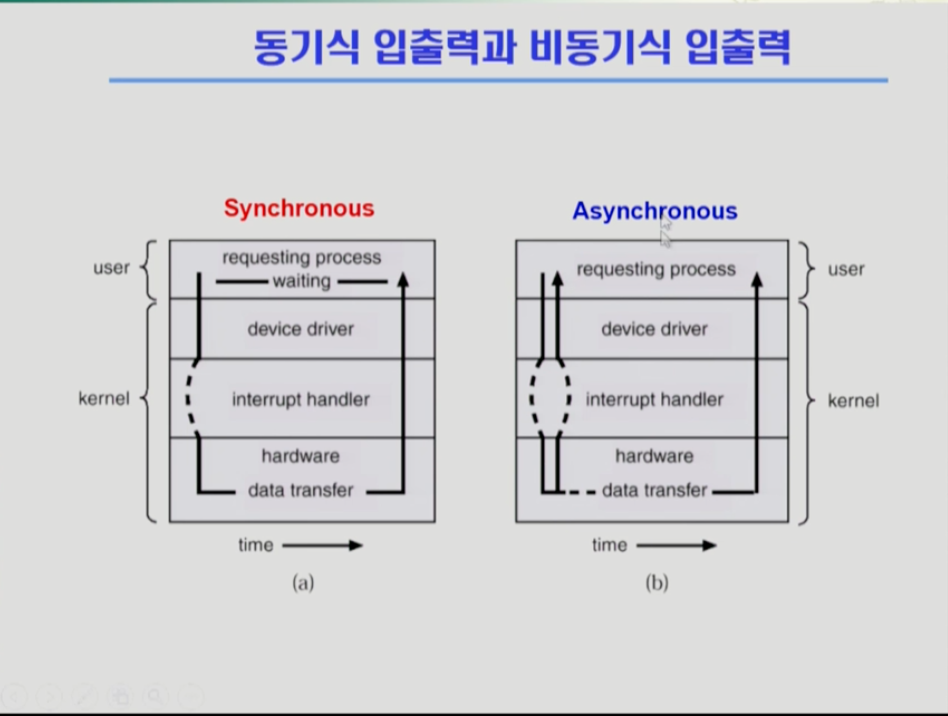
동기식 입출력과 비동기식 입출력동기식 입출력 : i/o 요청 후 실제로 무언가가 입출력 된 것을 확인하고 나서야 사용자 프로그램에 넘어가 그 다음 과정을 실행하는 것.i/o 가 끝날 때까지 cpu를 낭비시키는 방법을 쓰면 매 시점 i/o를 하나만 할 수 밖에 없다. 따
4.[운영체제] 5. Process1
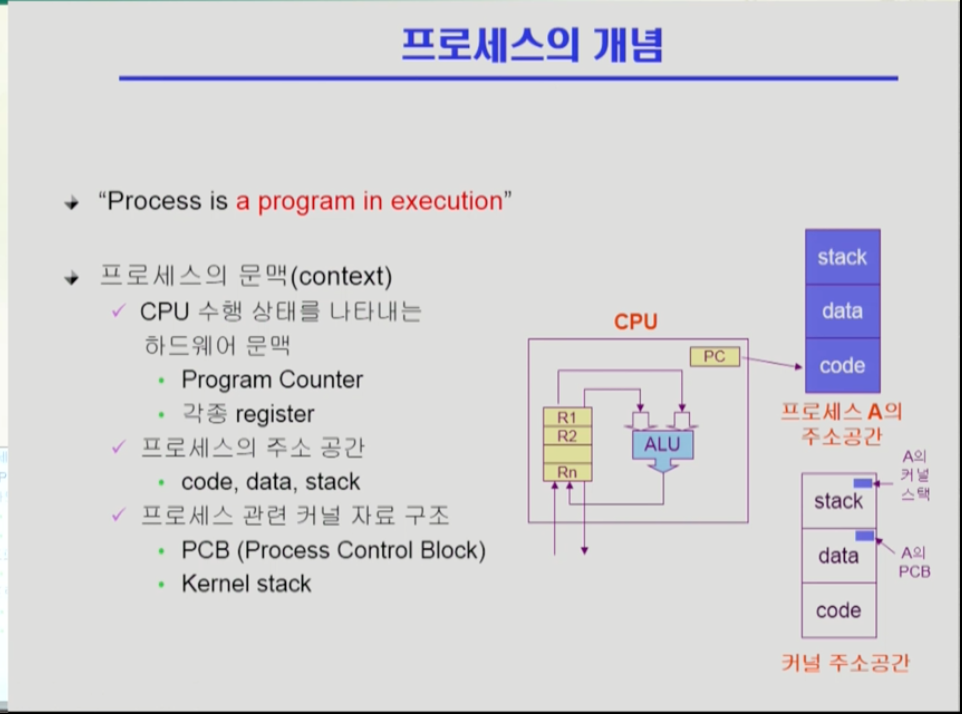
프로세스의 개념프로세스는 "실행 중인 프로그램"을 의미한다.프로세스의 문맥을 이해하는 것이 중요하다. 이는 특정 시점에서 프로세스가 어디까지 수행을 했는지를 규명하는 것이다. 프로그램의 현재 상태를 나타내는 모든 요소를 뜻한다.문맥을 나타내기 위해서는 프로그램 카운터(
5.[운영체제] 6. Process2
프로세스가 입출력 요청을 하면 프로세스는 이를 직접 수행하는 것이 아니라 운영체제에게 요청을 한다. 입출력 수행이 되는 동안 입출력을 요청한 프로세스가 아무 일도 안하고 기다리면 동기식 입출력, 반대로 입출력 요청 프로세스가 입출력 수행 시작하자마자 곧바로 CPU를 잡
6.[운영체제] 7. Process3

스레드는 빠른 응답성(성능 향상)과 자원 절약의 장점이 있다.다중 스레드가 협력하여 처리율을 높인다.독립적인 연산들을 각 스레드가 여러대의 CPU에서 실행돼 처리해 병렬성을 높이고 결과가 빨리 나온다.스레드가 여러개 있으면 스레드는 cpu 수행과 관련된 정보를 (PC,
7.[운영체제] 8. Process Management 1

프로세스는 부모 프로세스가 자식 프로세스를 생성하는 구조다. 프로세스가 실행되려면 자원(CPU,메모리)이 있어야한다. 이를 운영체제로부터 받는다. 자원을 부모 프로세스와 공유할 수도, 하지 않을 수도 있다. 보통 공유하지 않는다. 부모와 자식이 공존하여 수행될 수도
8.[운영체제] 9. Process Management 2

자식 프로세스는 부모의 모든 자원을 공유하다가, 새로운 내용을 write하면 독립적인 자원을 갖게 된다(copy-on-write).새로운 프로세스를 생성하는 시스템 콜은 fork, 새로운 프로그램을 덮어씌우는 것이 exec 시스템 콜이다.fork를 사용해 사용자 프로그
9.[운영체제] 10. CPU Scheduling 1

다음과 같은 CPU 스케줄링 알고리즘이 있다.CPU 스케줄링은 다음과 같은 성능 척도가 있다.위의 두가지는 시스템 입장에서의 성능 척도(프로그램이 최대한 일을 많이 함), 나머지는 프로그램(고객) 입장에서의 성능 척도(CPU를 빨리 얻어 빨리 끝남)다.시스템 입장인 C
10.[운영체제] 11. CPU Scheduling 2 / Process Synchronization 1

멀티레벨 큐는 프로세스가 CPU를 얻기 위해 여러 줄을 설때, 줄마다 우선순위를 둔다. 맨위의 줄로 갈수록 우선순위가 높은 줄이다. CPU는 우선순위가 높은 줄에 먼저 CPU를 쓰게 해준다. 
공유데이터를 접근하는 코드가 크리티컬 섹션이다. 크리티컬 섹션의 동시접근을 막아야 하므로 엔트리 섹션을 넣어 lock을 걸어야 한다. 크리티컬 섹션이 끝나면 lock을 풀어 다른 프로세스가 크리티컬에 들어갈 수 있도록 해야한다.크리티컬 섹션 문제를 풀기 위해 만족시켜야
12.[운영체제] 13. Process Synchronization 2
추상화는 복잡한 자료, 모듈, 시스템 등으로부터 핵심적인 개념 또는 기능을 간추려 내는 것을 말한다. 즉 복잡한 것을 일반적인 것으로 단순화하는 것이다Semaphores는 앞의 방식들을 추상화시킨 것이다.Semaphore의 정수형 변수 S와 이에 대한 P,V라는 두 가
13.[운영체제] 14. Process Synchronization 3

\-Synchronization 환경에서 생기는 여러 가지 문제가 있다먼저 bounded buffer 문제다. 버퍼의 크기가 유한한 환경이다. 여러 가지 프로듀서-컨슈머 프로세스들이 존재한다. 프로듀서는 공유 버퍼에 데이터를 만들어 집어 넣는 역할을 한다. 주황색이 프
14.[운영체제] 15. Process Synchronization 4
식사하는 철학자 문제를 모니터 버전으로 구현한 코드다. 노란색 박스를 보면 각각의 철학자가 eat,think를 반복한다. 밥을 먹기 위해서는 젓가락을 잡는 pickup, 먹은 후에는 젓가락을 내려놓는 putdown을 수행하는데 젓가락이라는 공유 자원에 접근하기 위해
15.[운영체제] 16. Deadlock 1
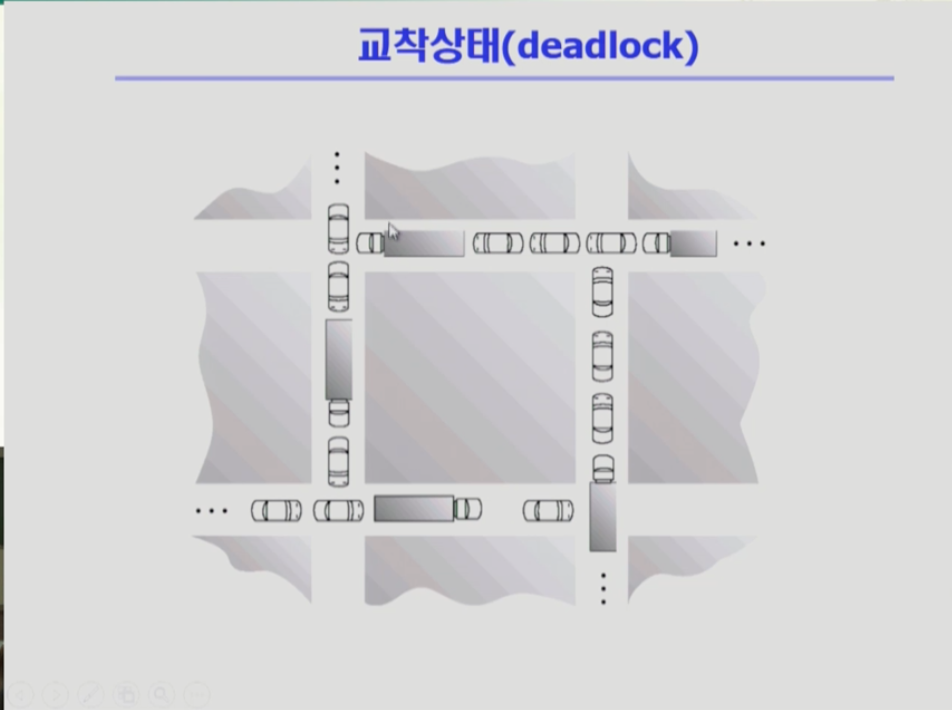
데드락은 우리말로 "교착상태"라 하여 그림과 같이 차가 막힌 상태처럼, 서로 자원을 내놓지 않고, 상대방이 가진 자원을 희생하기를 기다리는 것과 같다. 차들은 길목을 갖고 있고, 길을 원하는데 그 길은 다른 차들이 가지고 있고 그 차들도 양보하지 않은 채 다른 길을 원
16.[운영체제] 17. Deadlocks 2

지난 내용과 같이 데드락을 처리할 수 있는 네 가지 방법이 있다.프로세스의 자원 요청을 받아들였을 때 데드락의 가능성이 있으면 자원을 할당하지 않는 것이 데드락 어보이던스 였다.항상 safe한(현재 가용 가능한 자원으로도 프로세스 자원 요청 처리를 끝낼 수 있음)상태를
17.[운영체제] 18. Memory Management 1

메모리는 주소를 통해 접근할 수 있다. 이 주소는 논리적 주소와 물리적 주소로 나뉜다.이미 프로그램이 실행되면 독자적인 주소공간이 형성되는데, 프로그램마다 가지는 독립적 주소 공간을 논리적 주소라 한다.물리적 주소는 메모리에 실제 올라가는 위치를 나타낸다.프로그램이 물
18.[운영체제] 19. Memory Management 2

페이징 기법은 메모리 관리기법 중 하나이다. 프로그램을 구성하는 논리적 메모리를 동일한 페이지로 잘려서 각각이 물리적 메모리 주소의 어느 위치든 올라갈 수 있다. 페이징 기법에서 주소변환을 위해 페이지 테이블이라는 것이 사용된다. 각각의 논리적 페이지들이 물리적 메모리
19.[운영체제] 20. Memory Management 3

주소공간이 더 커지면 페이지 테이블을 2단계가 아닌 그 이상의 단계로도 쓸 수 있다.하지만 페이지 테이블이 여러개 만들어지면 주소변환을 위해 메모리에 여러번 접근해야 한다. 시간 오버헤드가 걸릴 수 있다.그러나 대부분의 주소변환이 TLB에 있는 캐싱 정보를 통해 직접
20.[운영체제] 21. Memory Management 4
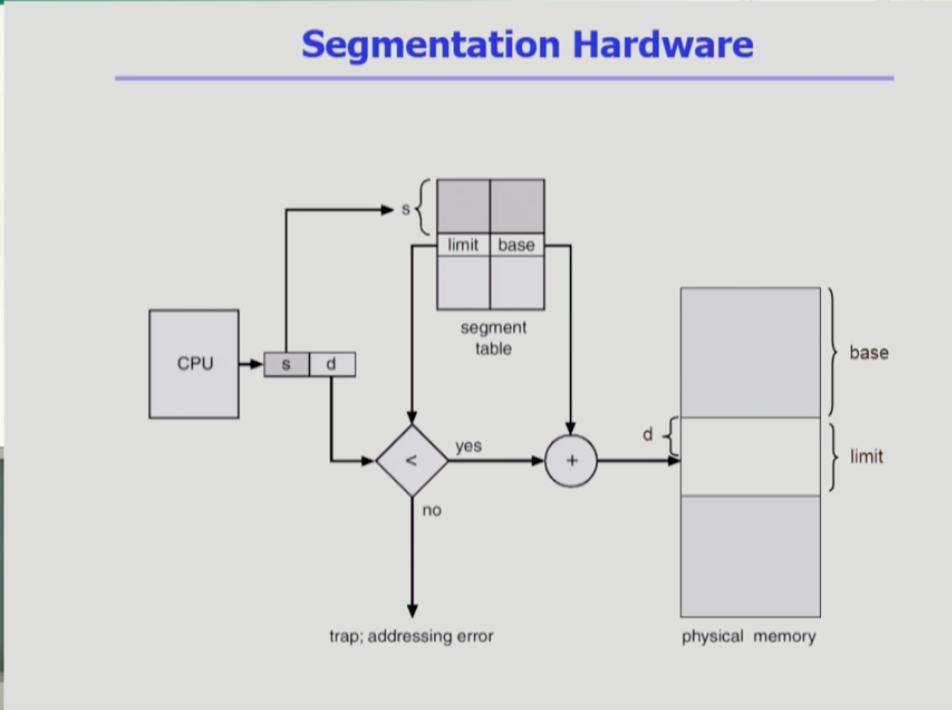
세그먼트 테이블은 엔트리 갯수가 세그먼트의 갯수와 같다.세그먼트는 크기가 균일하지 않으므로 세그먼트의 길이가 얼마인지를 세그먼트 테이블 엔트리가 limit에 담고 있다. 이는 페이징 기법과의 차이다. offset 값이 limit 보다 작아야만 합당한 메모리 참조이다.요
21.[운영체제] 22. Virtual Memory 1

버츄얼 메모리에 대해 알아보겠다.버츄얼 메모리 기법은 전적으로 운영체제가 관리한다.디멘드 페이징은 요청이 있으면 페이지를 메모리에 올리는 것이다.이 경우 필요한 것만 메모리에 올리므로 i/o 양이 상당히 줄어들고, 메모리 사용량이 감소하며, 응답 시간이 빠르고, 더 많
22.[운영체제] 23. Virtual Memory 2

캐슁은 한정된 빠른 공간(=캐쉬)에 요청된 데이터를 저장해 놓으면 다음에 똑같은 데이터 요청이 오면 캐쉬로부터 서비스를 하는 것이다. 페이징 기법 뿐만 아닌 여러가지 컴퓨터 시스템 환경에서 사용된다.캐쉬는 캐쉬 안의 데이터중 어떤 것을 쫓아낼지를 결정하는 알고리즘에 있
23.[운영체제] 24. File Systems 1
파일 시스템에 대해서 이야기하겠다 메모리는 주소를 통해서 접근하지만, 파일은 이름을 통해서 접근한다. 관련 정보를 이름으로 저장하는 것이다. 비휘발성의 보조기억장치에 저장된다 운영장치는 다양한 저장 장치를 서로 다른 파일로 관리함 파일에서 정의되는 연산은 생성, 삭
24.[운영체제] 25. File System Implementations 1

파일 시스템의 임플리멘테이션(구현)디스크에 파일의 데이터를 저장하는 세 가지 방법이 있다.디스크에 파일을 저장할 때 동일한 크기의 섹터 단위로 나누어 저장한다. 각각의 저장 단위를 논리적 블록 이라 부른다. 임의의 파일을 동일한 크기의 블럭으로 나누어 저장하는 방법이
25.[운영체제] 26. File System Implementations 2

기존에는 파일을 오픈 후 시스템 콜을 해서 운영체제가 해당하는 파일이 버퍼 캐시에 있으면 전달하고 없으면 디스크 파일 시스템에서 읽어와 사용자 프로그램에 전달하는 구조다. 그럼 사용자 프로그램은 내용을 카피해서 전달한다. 혹은 메모리 맵 아이오 시스템 콜을 하면 자신의
26.[운영체제] 27. Disk Management & Scheduling 1

디스크 관리와 스케줄링이다디스크를 관리하는 최소단위는 섹터다디스크 외부에서는 논리적 블록 단위로 디스크를 바라본다. 이 블록이 섹터에 매핑 되어 들어간다. 컴퓨터 호스트의 내부에서는 디스크를 접근할때 논리적 블록 단위로 저장하고, 이 주소는 1차원 배열에서 배열의 몇
27.[운영체제] 28. Disk Management & Scheduling 2

스왑 스페이스 관리에 대한 것이다.보조기억장치, 즉 디스크를 사용하는 두 가지 이유는 모두 메모리의 제약 때문이다. 메모리의 휘발성 때문에 파일 시스템처럼 연속적으로 메모리를 유지해야 하는 경우 비휘발성의 디스크를 사용하고, 두 번째는 물리적 메모리 공간의 한정 때문에