분류의 개요
지도학습
레이블(Label), 명시적인 정답이 있는 데이터가 주어진 상태에서 학습하는 머신러닝 방식
지도학습 유형 중 분류
학습 데이터로 주어진 데이터의 피처와 레이블값(결정 값, 클래스 값)을 머신러닝 알고리즘으로 학습, 모델 생성 -> 생성된 모델에 새로운 데이터 값이 주어졌을 때 미지의 레이블 값 예측
분류 알고리즘 종류
- 베이즈 통계, 나이브 베이즈
- 로지스틱 회귀
- 결정 트리
- 서포트 벡터 머신
- 최소 근접 알고리즘
- 심층 연결 기반의 신경망
- 서로 다른 머신러닝 알고리즘 결합한 앙상블
결정 트리
ML 알고리즘 중 직관적으로 이해하기 쉬운 알고리즘
데이터에 있는 규칙을 학습을 통해 자동으로 찾아내 트리 기반의 분류 규칙을 만듦⚠️
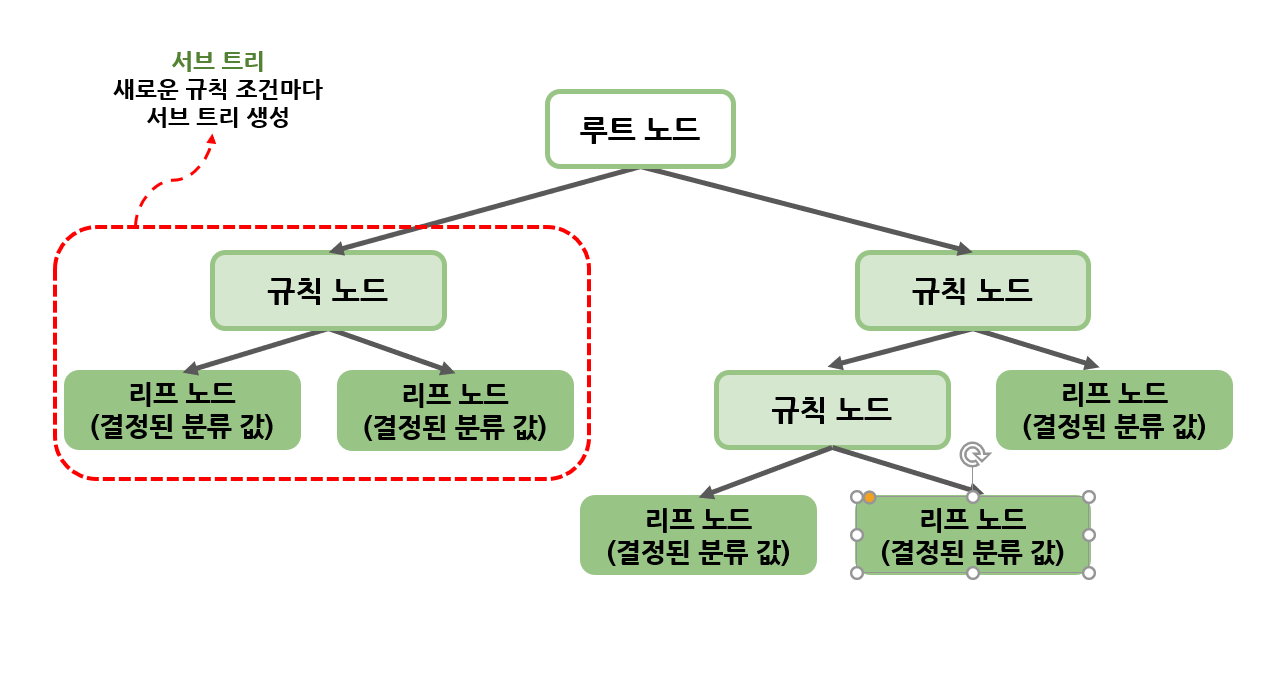
규칙 노드: 규칙 조건
리프 노드: 결정된 클래스 값
서브 트리: 새로운 규칙 조건마다 생성
이런 규칙이 있음 -> 분류 결정하는 방식 복잡 -> ⚠️ 과적합 문제
트리의 깊이가 깊어질수록 결정 트리의 예측 성능 저하될 문제
가능한 적은 노드로 높은 예측 정확도를 가지려면 데이터 분류할 때 푀대한 많은 데이터 세트가 해당 분류에 속할 수 있도록 결정 노드의 규칙 중요
결정 노드는 정보 균일도가 높은 데이터 세트를 먼저 선택할 수 있도록 규칙 조건 생성
정보의 균일도 측정 방법
-
정보 이득 지수: 서로 다른 값이 섞여 있으면 엔트로피 높고, 같은 값이 섞여 있으면 엔트로피 낮음
1-엔트로피 지수 = 정보 이득 지수 -
지니 계수: 경제학에서 불평등 지수를 나타낼 때
0 평등, 1 불평등
다양성이 낮을 수록 균일도 높음
결정 트리 모델의 특징
➕
균일도라는 룰을 기반
알고리즘이 쉽고 직관적
룰이 매우 명확
각 피처의 스케일링과 정규화 같은 전처리 작업 필요 없음
➖
과적합으로 정확도 떨어짐
서브트리를 계속 만들다 보면 깊이가 깊어지고 복잡해질 수 밖에 없음
유연하게 대처할 수 없이 예측 성능 떨어짐
결정 트리 파라미터
사이킷런에서 DecisionTreeClassifier와 DecisionTreeRegressor 클래스 제공
DecisionTreeClassifier 분류를 위한 클래스
DecisionTreeRegressor 회귀를 위한 클래스
파라미터
min_sample_split 노드를 분할하기 위한 회소한의 샘플 데이터 수, 과적합 제어
min_sample_leaf말단 노드가 되기 위한 최소한의 샘플 데이터 수
max_features 최적의 분할 위해 고려할 최대 피처 개수
max_depth트리의 최대 깊이 규정
max_leaf_nodes 말단 노드의 최대 개수
결정 트리 모델의 시각화
Graphviz 패키지 사용
파이썬으로 개발된 것이 아니기 때문에 Geaphviz를 설치한 뒤에 파이썬과 인터페이스 할 수 있는 파이썬 래퍼 모듈을 별도 설치
