배깅
같은 알고리즘으로 여러 개의 분류기를 만들어서 보팅으로 최종 결정하는 알고리즘
랜덤 포레스트
배깅의 대표적인 알고리즘
앙상블 알고리즘 중 비교적 빠른 수행 속도
다양한 영역에서 높은 예측 성능
기반 알고리즘은 결정 트리, 쉽고 직관적인 장점을 살림
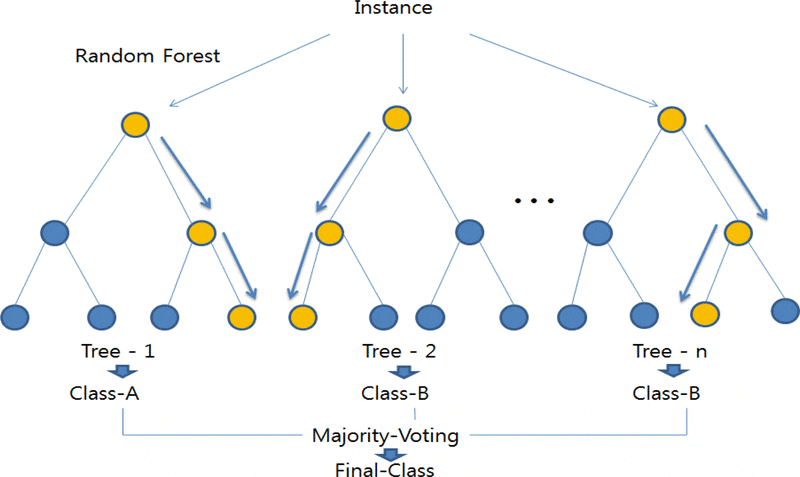
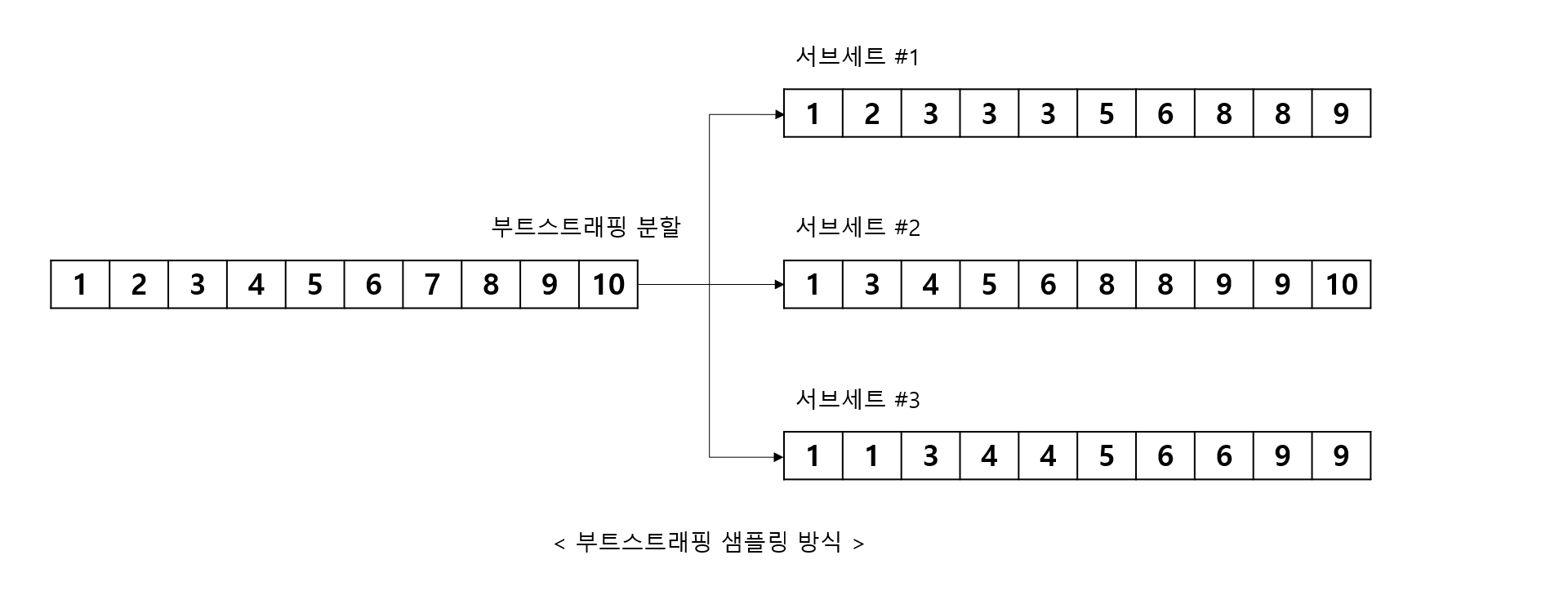
개별적인 분류기의 기반 알고리즘은 결정 트리지만, 개별 트리가 학습하는 데이터 세트는 전체 데이터에서 일부 중첩되게 샘플링된 데이터 세트 -> 부트스트래핑 분할 방식
RandomForestClassifier클래스로 랜덤 포레스트 분류 지원
할 때마다 동일한 예측 결과 출력을 위해 random_state를 0 으로 설정
get_human_dataset()을 이용해 학습/테스터용 DataFrame을 가져옴
💻실습
def get_new_feature_name_df(old_feature_name_df):
feature_dup_df = pd.DataFrame(data=old_feature_name_df.groupby('column_name').cumcount(),
columns=['dup_cnt'])
feature_dup_df = feature_dup_df.reset_index()
new_feature_name_df = pd.merge(old_feature_name_df.reset_index(), feature_dup_df, how='outer')
new_feature_name_df['column_name'] = new_feature_name_df[['column_name', 'dup_cnt']].apply(lambda x : x[0]+'_'+str(x[1])
if x[1] >0 else x[0] , axis=1)
new_feature_name_df = new_feature_name_df.drop(['index'], axis=1)
return new_feature_name_dfimport pandas as pd
def get_human_dataset( ):
# 각 데이터 파일들은 공백으로 분리되어 있으므로 read_csv에서 공백 문자를 sep으로 할당.
feature_name_df = pd.read_csv('./human_activity/features.txt',sep='\s+',
header=None,names=['column_index','column_name'])
# 중복된 피처명을 수정하는 get_new_feature_name_df()를 이용, 신규 피처명 DataFrame생성.
new_feature_name_df = get_new_feature_name_df(feature_name_df)
# DataFrame에 피처명을 컬럼으로 부여하기 위해 리스트 객체로 다시 변환
feature_name = new_feature_name_df.iloc[:, 1].values.tolist()
# 학습 피처 데이터 셋과 테스트 피처 데이터을 DataFrame으로 로딩. 컬럼명은 feature_name 적용
X_train = pd.read_csv('./human_activity/train/X_train.txt',sep='\s+', names=feature_name )
X_test = pd.read_csv('./human_activity/test/X_test.txt',sep='\s+', names=feature_name)
# 학습 레이블과 테스트 레이블 데이터을 DataFrame으로 로딩하고 컬럼명은 action으로 부여
y_train = pd.read_csv('./human_activity/train/y_train.txt',sep='\s+',header=None,names=['action'])
y_test = pd.read_csv('./human_activity/test/y_test.txt',sep='\s+',header=None,names=['action'])
# 로드된 학습/테스트용 DataFrame을 모두 반환
return X_train, X_test, y_train, y_test
X_train, X_test, y_train, y_test = get_human_dataset()from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
import pandas as pd
import warnings
warnings.filterwarnings('ignore')
# 결정 트리에서 사용한 get_human_dataset( )을 이용해 학습/테스트용 DataFrame 반환
X_train, X_test, y_train, y_test = get_human_dataset()
# 랜덤 포레스트 학습 및 별도의 테스트 셋으로 예측 성능 평가
rf_clf = RandomForestClassifier(random_state=0)
rf_clf.fit(X_train , y_train)
pred = rf_clf.predict(X_test)
accuracy = accuracy_score(y_test , pred)
print('랜덤 포레스트 정확도: {0:.4f}'.format(accuracy))from sklearn.model_selection import GridSearchCV
params = {
'n_estimators':[100],
'max_depth' : [6, 8, 10, 12],
'min_samples_leaf' : [8, 12, 18 ],
'min_samples_split' : [8, 16, 20]
}
# RandomForestClassifier 객체 생성 후 GridSearchCV 수행
rf_clf = RandomForestClassifier(random_state=0, n_jobs=-1)
grid_cv = GridSearchCV(rf_clf , param_grid=params , cv=2, n_jobs=-1 )
grid_cv.fit(X_train , y_train)
print('최적 하이퍼 파라미터:\n', grid_cv.best_params_)
print('최고 예측 정확도: {0:.4f}'.format(grid_cv.best_score_))랜덤 포레스트 정확도: 0.9108
사용자 행동 인식 데이터 세트에 대해 91.08%의 정확도
랜덤 포레스트 하이퍼 파라미터 및 튜닝
트리기반의 앙상블 알고리즘은 파라미터가 너무 많고
튜닝을 위한 시간이 많이 소모됨
다만, 랜덤포레스트에선 결정 트리에서 사용되는 하이퍼 파라미터와 같은 파라미터가 대부분이라 좀 빠른 편
n_estimators 랜덤 포레스트에서 결정 트리의 개수, 결정 기본값 10개
max_features 결정 트리에 사용된 것과 동일. but 기본 max_features는 None이 아니라 auto
트리를 분할하는 피처를 참조할 때 전체 피처가 아니라 전체 피처 개수만큼 참조
GridSearchCV를 이용해 튜닝
from sklearn.model_selection import GridSearchCV
params = {
'n_estimators':[100],
'max_depth' : [6, 8, 10, 12],
'min_samples_leaf' : [8, 12, 18 ],
'min_samples_split' : [8, 16, 20]
}
# RandomForestClassifier 객체 생성 후 GridSearchCV 수행
rf_clf = RandomForestClassifier(random_state=0, n_jobs=-1)
grid_cv = GridSearchCV(rf_clf , param_grid=params , cv=2, n_jobs=-1 )
grid_cv.fit(X_train , y_train)
print('최적 하이퍼 파라미터:\n', grid_cv.best_params_)
print('최고 예측 정확도: {0:.4f}'.format(grid_cv.best_score_))최적 하이퍼 파라미터:
{'max_depth': 6, 'min_samples_leaf': 8, 'min_samples_split': 8, 'n_estimators': 100}
최고 예측 정확도: 0.9451
rf_clf1 = RandomForestClassifier(n_estimators=300, max_depth=10, min_samples_leaf=8, \
min_samples_split=8, random_state=0)
rf_clf1.fit(X_train , y_train)
pred = rf_clf1.predict(X_test)
print('예측 정확도: {0:.4f}'.format(accuracy_score(y_test , pred)))예측 정확도: 0.9165
