비선형 분류
Decision Trees
비선형분류모델로 많이 사용되는 분류기 중 하나이며 데이터에 대한 분류 이유를 설명할 수 있다는 특징을 가지고 있다.
동일한 데이터 셋에 대해 여러 개의 다른 구조의 트리 모델을 학습시킬 수 있다.
헌트 알고리즘
의사결정나무 모델을 학습하는 알고리즘. (그리디한 알고리즘)
그리디한 알고리즘 이기 때문에 간단하게정리하면 leaf에 같은 class의 sample만 존재할때 까지 계속 분리 시키는 것이다.
균일한(homogeneous)한 클래스를 가질수록 모델의 성능이 좋아진다.
얼마나 균일한지 평가하기 위해 불순도(impurity)가 사용된다.
📌 불순도가 낮을 수록 균일한거임
불순도 측정
Gini Index
공식 :
ex)
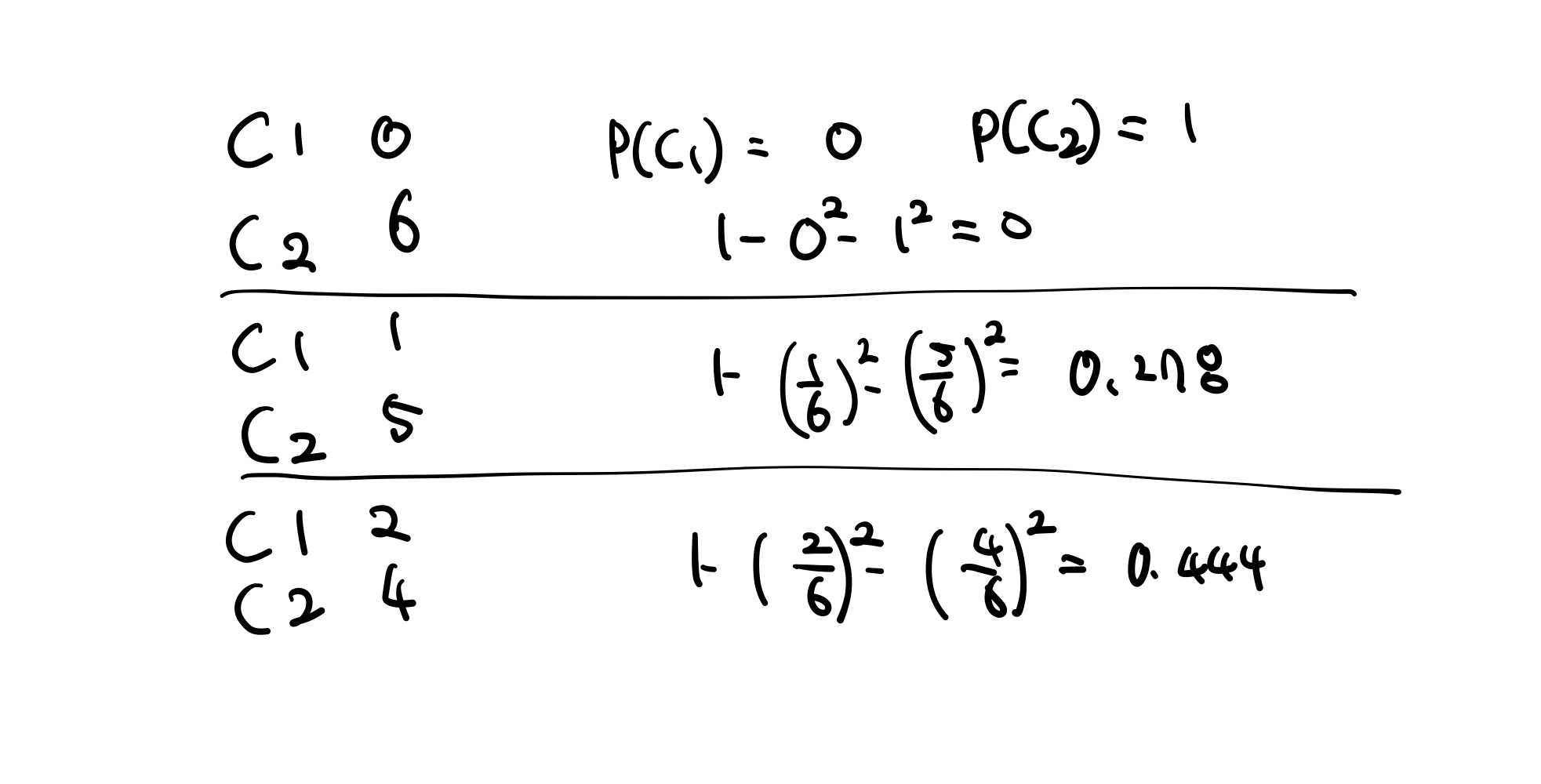
위 예시 처럼 불순도를 계산할 수 있는데 값이 작을수록 좋은거임
Entrophy
공식 :
ex)

📌 위의 예시들을 통해 노드에서 최대한 많이 분류하는 경우를 찾는게 좋은 것이라는 걸 알 수 있다.
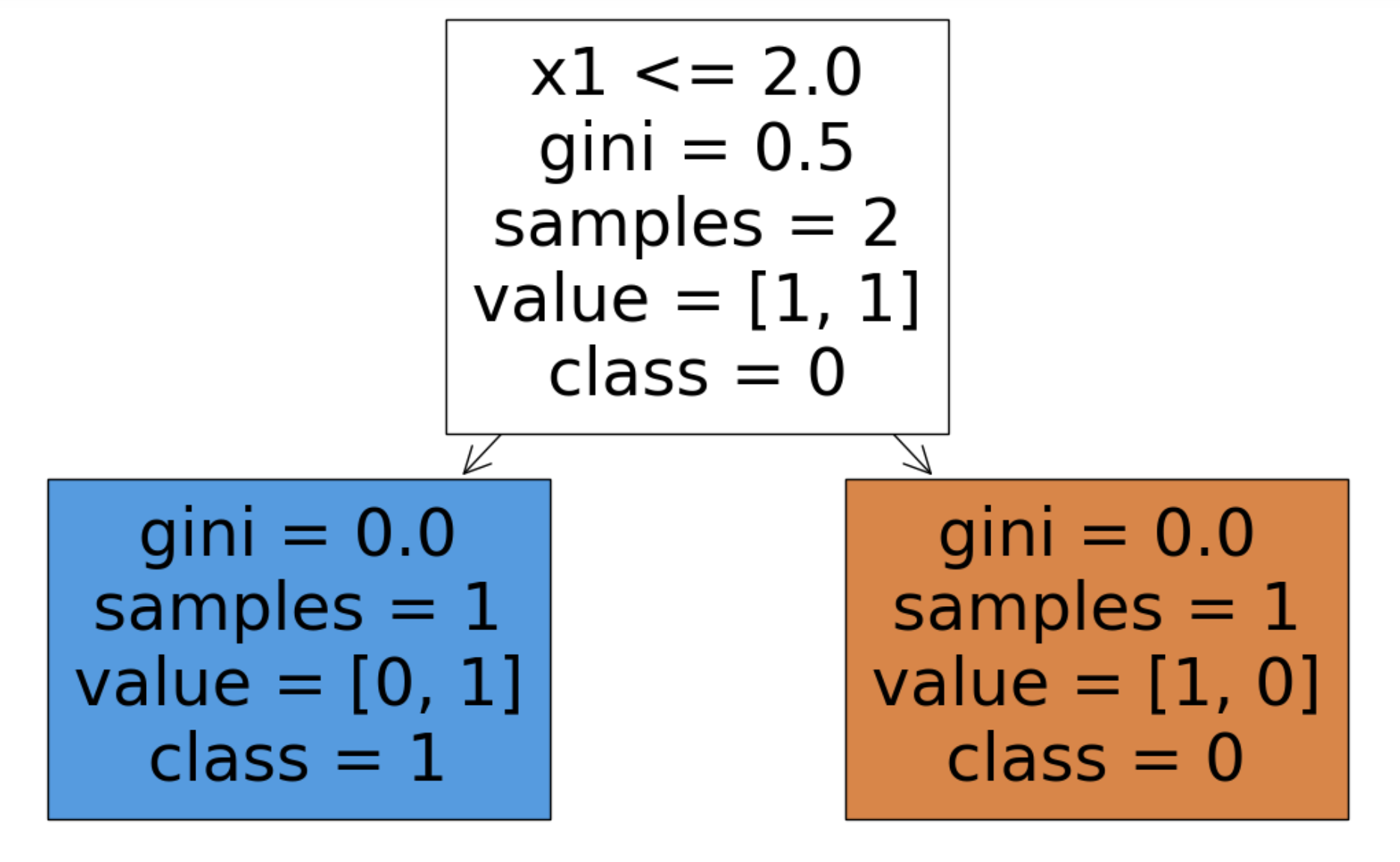
예시
import matplotlib.pyplot as plt
from sklearn import tree
x = [[3, 0], [1, 1]] # feature -> x1, x2
y = [0, 1]
clf = tree.DecisionTreeClassifier()
clf = clf.fit(x, y)
fig = plt.figure(figsize=(15, 8))
_ = tree.plot_tree(clf,
feature_names=['x1', 'x2'],
class_names=['0', '1'],
filled=True)
결과
x1을 기준으로 2보다 작으면 왼쪽 크면 오른쪽으로 분류한 걸 볼 수 있다