안녕하세요!
오늘은 Clustering 알고리즘 중 DBSCAN에 대해 공부한 것을 한번 기록해 보려고 합니다. 전에 데이터분석을 하며 사용해본적이 있지만, 조금 더 정확하게 알아보고자 Wikipedia를 참고하며 다시 기록해보겠습니다!
DBSCAN은 2014년에 데이터 마이닝 컨퍼런스인 ACM SIGKDD에서 Test of time award 를 수상함으로써 성능을 입증받은 알고리즘입니다! 복잡한 이름과는 달리 굉장히 직관적이고 쉬운 알고리즘인데요. 기본개념부터 차근차근 알아보고, 간단한 예제에 적용해보는 것을 목표로 하겠습니다!
Preliminary
DBSCAN을 설명하기 전에 필요한 개념부터 몇 가지 설명하고 가겠습니다.
먼저, 을 특정한 점에서 인접영역의 반지름을 지정하는 parameter라고 하겠습니다. 또한 를 Core를 구성하기 위한 최소한의 점의 갯수라고 합시다.(지금은 넘어가고 뒤에서 더 설명하겠습니다.)
-
Core point : 어떠한 점 에서 거리 내에 존재하는 점이 개 이상 있는 점.( 점 를 포함한 갯수입니다.)
-
directly reachable from : Core point인 로 부터 거리 내에 있는 점
-
reachable from : 부터 까지의 경로가 (이 directly reachble from ) 있는 경우, 는 reachble from 라고 한다.
-
Noise : 어떤점에 대해서도 reachable 이 아닌 점. (Core point 는 항상 reachable 이다.)
Density-Based Clustering
만약 점 가 Core point 이면 점 로부터 reachable 한 점들과 함께 클러스터를 만들게 됩니다. 그렇게 각각의 클러스터는 적어도 하나의 Core point 와 reachable 한 점들로 구성되게 됩니다. 여기서 Core point 가 아닌 점들은 더 이상 다른 점들과 연결하지 않기 때문에 클러스터의 "edge"가 됩니다. (클러스터의 가장 모퉁이 점들이 된다는 말입니다.)
위 그림은 Wikipedia에서 제공하는 그림으로 DBSCAN이 군집을 형성하는 모습을 잘 보여주고 있는데요!
-
A로 표현된 빨간 점들이 Core point.
-
B와 C는 각 Core point가 아니면서 Core point 들에 reachable 한 포인트로 "edge".
-
N은 어느것도아닌 Noise 가 됩니다.
즉, 빨간점들과 노란점들이 하나의 군집이 되는 것입니다.
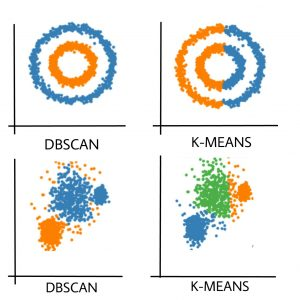
이러한 density-based clustering을 이용하기 때문에 비교적 자유로운 형태의 클러스터를 잘 잡아낼 수 있습니다. 다음의 그림은 DBSCAN을 찾아보면 많이 볼 수 있는 예제그림으로 여러 형태의 클러스터를 잘 잡아내는 것을 보여줍니다!

정리해보면 Core point 를 구성하는 반지름과 최소 점의갯수인 , 그리고 거리를 계산할 Distance measure만 주어지면 DBSCAN을 실행해 볼 수 있습니다.
DBSCAN은 신기하게도 기존의 클러스터링알고리즘과 달리 클러스터의 수를 결정해주지 않아도 된다는 장점이 있습니다. 하지만 개인적인 생각으로는 과 을 선택함에 따라 클러스터의 수가 바뀌기 때문에, 과 의 선택이 클러스터의 수의 선택을 대체하고 있다고 생각됩니다.
추가적으로, 다른 클러스터링 알고리즘들과 달리 Noise 를 찾아내기 때문에 Outlier detection 에도 쓰인다고 알고있습니다.
Example
DBSCAN을 iris data에 이용하는 아주 간단한 python 코드 입니다.
from sklearn.cluster import DBSCAN
from sklearn import datasets
import numpy as np
import matplotlib.pyplot as plt
iris = datasets.load_iris()
data = iris["data"]
labels = iris["target"]
DBSCAN_clust = DBSCAN(eps = 0.4, min_samples = 4)
DBSCAN_clust.fit(data)
fig, ax = plt.subplots(1, 2)
fig.set_size_inches((12, 4))
ax[0].scatter(data[:,2], data[:,3], c = labels)
ax[1].scatter(data[:,2], data[:,3], c = DBSCAN_clust.labels_)
우측 그림의 보라색점들은 Noise 인 점들입니다.
궁금하신 부분이나 틀린부분이 있다면 댓글부탁드립니다! 좋은하루 보내세요!
