Stanford 대학의 CS234(Reinforcement Learning) 수업을 듣고 정리한 포스트입니다.
Lecture 1에서는 우리가 앞으로 다룰 강화학습에 관하여 소개하고 있습니다. 강의영상과 강의자료는 각각 링크를 참고하시면 될 것 같습니다.
I. Overview of Reinforcement Learning
Reinforcement Learning?
Learn to make Good Sequences of Decisions.
강화학습은 "intelligent agent가 올바른 순서로 의사 결정을 내리는 방법을 어떻게 학습할 수 있는지"에 대하여 정말 근본적인 문제를 다룬다.
여기서 agent/intelligent agent는 일반적으로 인간이거나 생물일 수도 있고 아닐 수도 있다.
'Sequences of decisions'는 연속적인 결정을 내리는 것을 말하고, 'good'는 최적성의 개념을 의미한다. 최종적으로 강화학습에서 중요한 부분은 'Learn(학습)'이다. 그러나 agent는 자신의 결정이 어떻게 영향을 미칠지, 어떤 결정이 반드시 좋은 결과와 관련될 수 있는지를 모르며, 경험을 통해 정보를 획득하게 된다.
Fundamental challenge in artificial intelligence and machine learning is learning to make good decisions under uncertainty.
AI와 ML에서의 근본적인 도전은 불확실성 하에서 좋은 결정을 하도록 학습하는 것이다.
Intelligence in Primitive Creature

Princeton 대학의 심리학자이자 뇌과학 연구원인 Yael Niv의 연구에 따르면, 위 사진의 원시 생물은 일생동안 진화를 겪는다고 한다. Childhood 때는, 원시적인 뇌와 하나의 눈을 갖고 있으며, 수영하면서 돌아다니기도 하고 돌에 붙어있기도 한다. 조금 더 자라서 어른이 되면, 이 생명체는 자신의 뇌를 소화시키고 돌에 정착한다. 뇌가 있는 경우에는 지능이 있으므로 의사결정을 내리는 데 도움을 주며, 의사결정을 전부 내린 후에는 더 이상 뇌가 필요하지 않음을 보여준다.
이 원시 생물의 사례를 통해 Agent에게 지능이 필요한 이유와 뇌와 지능이 근본적으로 '의사결정을 내리는 것'과 연관있음을 알 수 있다.
Examples of RL
- Atari
강화학습에서의 패러다임 변화를 보여준 성공적인 사례로, Atari 벽돌깨기 게임에 강화학습을 접목시켜, 픽셀 자체를 입력 받고 어떻게 더 높은 점수를 얻을 수 있는지에 대하여 학습.
- Robotics
로봇에 강화학습을 적용한 사례로 object의 위치 좌표(x,y,z)를 입력받아, 물건을 집거나 옷을 개는 것과 같은 task를 해결할 수 있도록 학습.
- Educational games
인간의 잠재력을 증폭시킬 수 있도록 Educational game에 강화학습을 적용시킴. 분수와 같은 소재를 빠르고 효율적으로 배울 수 있음.
- Healthcare
진료 기록 데이터를 토대로 환자의 치료와 처방을 할 수 있도록 학습.
- Others
최근에는 NLP, Vision 등 여러 분야에도 강화학습을 적용시킬 수 있음.
The key aspects of RL
-
Optimization
최적화는 좋은 결정을 내리는 것을 목적으로 한다. -
Delayed Consequences
내린 결정이 좋은 결정인지 바로 알 수 없고, 시간이 지나야 알 수 있다. 다시 말하면, 즉각적인 피드백이 아닌 지연된 피드백을 받게 된다. 의사결정과 그에 따른 결과 사이의 인과관계를 알 수 없기 때문에 어렵다. -
Exploration
경험을 통해 학습하며, 데이터가 Censored하다는 특징을 갖는다. 결정에 따른 행동에 해당되는 보상만을 얻게 되며, 여러 선택지 중 하나를 택했다면, 다른 선택지를 골랐을 때의 경험은 할 수 없다. MIT와 Stanford 대학 중 Stanford를 선택했다면, MIT에서의 경험은 절대 이루어질 수 없다. -
Generalization
Policy(Decision Policy)란, 과거의 경험으로부터 행동을 결정하는 규칙을 말한다. 우리는 다음 사례를 통해 Policy가 왜 학습할 필요가 있는지, pre-program된 policy를 사용해서는 안되는지 알 수 있다.Atari 벽돌깨기 게임은 픽셀로부터, 다시 말해 이미지의 공간으로부터 다음에 무엇을 해야 하는지 학습하는 알고리즘을 갖고 있다. 이 프로그램을 if-then statement로 코드를 짠다면, 그 양은 엄청날 것이고 다루기 어려울 것이다. 따라서 우리에겐 어떤 형태로든 일반화가 필요하고 데이터로부터 직접적으로 학습하는 것이 높은 수준의 작업을 해내는 데 훨씬 도움된다. 이전에 학습하지 않은 새로운 상황과 마주치더라도, 지금까지 학습한 것을 토대로 agent가 문제를 풀어나갈 수 있게 된다.
RL VS Other AI and ML
-
AI Planning VS RL
AI Planning은 Optimization, Generalization, Delayed Consequences를 포함하지만, Exploration은 포함하지 않으며, 모든 결정이 World에 영향을 미칠 수 있다. 바둑을 예로 들면, 바둑의 규칙과 보상이 무엇인지 알려주기 때문에, World의 모델이 주어진다면 무엇을 해야 하는지 계산한다. -
Supervised ML VS RL
Supervised ML은 Optimization과 Generalization은 포함하지만, Exploration과 Delayed Consequences는 포함하지 않는다. Supervised ML에서는 데이터 셋이 주어지기 때문에 Exploration은 해당되지 않는다. 또한, Supervised ML(주로 Classification/Regression 문제)은 하나의 결정을 하게 되는데, 이 결정에 대한 결과(맞았는지/틀렸는지)가 즉각적으로 나오기 때문에 Delayed Consequences도 해당되지 않는다. -
Unsupervised ML VS RL
Supervised ML과 같이 Exploration과 Delayed Consequences를 제외한 나머지를 포함하고 있다. Supervised ML과 다르게 Unsupervised ML은 정답 label이 존재하지 않는다는 것이다. -
Imitation Learning VS RL
Imitation Learning은 강화학습과 비슷하지만 살짝 다르다. Optimization, Generalization, Delayed Consequences를 포함하지만, Exploration은 포함하고 있지 않다. RL은 intelligent agent가 world에서 직접 경험을 하여 스스로 결정/행동을 한다면, IL의 핵심은 다른 사람들의 경험으로부터 배운다는 점이다. 행동을 따라하고, 그에 따른 결과를 관찰하면서 어떻게 행동을 해야 하는지에 대해 학습한다. 단순히 모방하여 학습하는 것이기 때문에 직접 Exploration을 하지 않아도 된다.IL은 강화학습을 지도학습으로 축소한 것으로 볼 수 있다. 이 때문에 효율적인 부분도 많지만, 한계 또한 존재한다. 모방하지 못한 상황을 마주치게 되면 스스로 해결할 수 없다는 것이다. 원을 그리며 나는 헬리콥터의 궤도를 관찰하여 학습했다고 가정했을 때, agent가 원의 궤도를 그리며 나는 상황에만 처하게 된다면 괜찮을 수 있다. 그러나, 곡선을 그리며 날아야하는 상황과 같이, 학습하지 않은 새로운 상황을 접하게 되면, 이때 agent는 어떻게 해야 할지 모를 수 있다. 이러한 한계점은 IL과 RL을 결합한다면 해결할 수 있을 것으로 기대된다.
II. Course structure overview
- Stanford 대학 수업의 진행 방식(시험/과제 비중 등)에 대하여 다루고 있으므로 생략함
III. Introduction to Sequential Decision Making Under Uncertainty
Sequential Decision Making
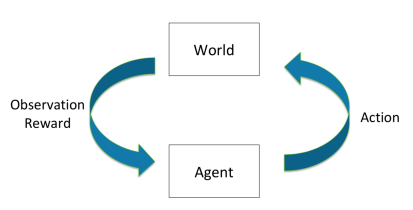
Agent/Intelligent Agent가 World의 상태에 영향을 주는 행동/결정을 하고, World는 그에 대하여 Observation을 한 후 보상을 주는 것을 반복하는 구조이다. (Interactive Closed-Loop Process)
핵심 목표(Goal)은 미래까지의 총 기대보상을 최대화하는 것으로, 즉각적인 보상과 장기적인 보상 사이의 균형과 높은 보상을 얻기 위한 전략적인 행동을 필요로 한다.
Examples of Sequential Decision Making
-
Web Advertising
- Agent : 웹사이트에 내보낼 웹 광고를 선택 (action)
- Observation : 고객이 웹페이지에서 보낸 시간과 고객의 광고 클릭 횟수
- Reward : 광고 클릭하면 +1
- Goal : 고객의 광고 클릭 횟수 최대화!
어떤 광고를 웹사이트에 게시하냐에 따라 고객의 클릭 횟수가 달라지게 된다.
-
Robot Unloading Dishwasher
- Agent : joint를 조작하여 접시를 닦음 (action)
- Observation : 주방의 카메라 이미지 등
- Reward : 남은 접시가 있을 시 -1, 없을 시 +1
- Goal : 카운터에 닦아야 할 접시가 없도록 유지!
-
Blood Pressure Control
- Agent : 환자에게 약 또는 운동을 처방
- Observation : 개인의 혈압 정보
- Reward : 혈압이 정상 범위에 들었을 경우 +1, 부작용 또는 정상 범위 벗어난 경우 -1
- Goal : 환자의 혈압을 정상 범위 안에 들도록!
-
Artificial Tutor
-
Agent : 덧셈과 뺄셈 같은 teaching activity를 고른다.
-
Observation : 학생이 문제를 푼 결과
-
Reward : 문제를 올바르게 풀었다면 +1, 그렇지 않으면 -1
-
Goal : 학생이 개념을 이해할 수 있도록 함.
Agent의 보상체계에 존재하는 허점을 이용하여 더 쉬운 보상을 많이 받게 되는 문제가 종종 발생한다. 이를 Reward Hacking이라 하며, 좋은 학습을 위해서는 정교하게 짜여진 보상체계를 필요로 한다.
-
Sequential Decision Process (Discrete Time)
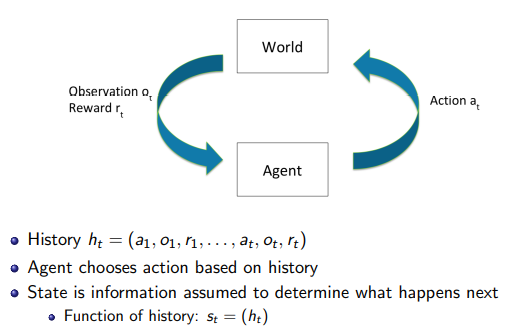
Time이 Discrete하다고 할 때, agent가 취하는 행동(action) 를 world의 관찰(observation) 과 보상(reward) 를 return하게 된다. 와 를 통해 agent는 새로운 행동을 취하게 된다.
이때, History는 agent가 취한 이전의 모든 action들과 지금까지 얻은 observation과 reward들의 집합으로, 과거의 History를 통해 새로운 action을 결정하게 된다.
a function of the history :
State는 결정을 내리기 위해 사용하는 정보로, History의 함수이다. State는 크게 world state와 agent state로 나눌 수 있다. world state는 현실 세계를 의미하며, agent는 현실 세계에서 발생하는 모든 일들을 알 수 없다. 사람을 예로 들면, 사람의 눈은 180도 정도의 각도에 해당하는 부분만을 볼 수 있지만, 뒤통수의 상황은 볼 수 없는 것과 비슷하다. 따라서, agent에게는 일부의 world state가 제공되며, 이를 agent state라고 부른다.
Markov Assumption
강화학습에서 자주 등장하는 정말 중요한 가정으로, state가 충분한 history의 정보를 가지고 있다면, 우리는 state만으로도 미래를 예측할 수 있음을 의미한다.
다음은 Markov를 수식으로 작성한 것이다.
현재 시점(t)의 state와 action으로 결정된 t+1의 state는 history와 action으로 결정된 state와 같다.
Markov는 일반적으로 모든 상황에서 성립할 수 있다. state에 모든 history가 담겨있다고 설정한다면, Markov는 성립한다. 그러나 모든 history를 state로서 사용하는 것은 쉽지 않기 때문에, 일반적으로 일부의 history만 state로 사용하여 문제를 해결한다.
Markov Decision Process (MDP)
Environment and world state =
agent state가 world state와 같으며, 이때의 state는 현재 observation으로 설정해도 된다.
Partial Observability (POMDP)
agent state가 world state와 같지 않으며, world state에 대한 history나 beliefs를 이전 action과 observation과 함께 종합한 후 의사결정을 내리는데 사용된다. Partial Observability와 비슷한 예로 포커를 들 수 있는데, 본인의 카드만 볼 수 있고 상대의 카드에 대해서는 버려진 패 이외에는 정보를 얻을 수 없으므로, 부분적인 정보만 알 수 있다는 점에서 유사하다.
Types of Sequential Decision Processes
-
Bandits
과거의 결정들이 state와 전혀 관계가 없고, 현재의 observation만으로 결정을 내리게 된다. 이전의 결정이 미래의 결정에 영향을 주지 않기 때문에, 현재의 observation이 state가 된다.
어느 한 고객이 광고를 클릭한 사건은 다른 고객이 광고를 클릭하는 사건에 전혀 영향을 주지 못하는 것이 Bandits의 예시이다. -
MDPs and POMDPs
MDP와 POMDP는 Bandits와 다르게, 현재의 action이 이후의 state와 action에 영향을 주므로 이를 고려하여 state 범위를 설정해야 한다. 따라서, Bandits와 같이 현재의 observation만으로 결정을 내린다면 정보가 부족할 수 있다.
-
How the world changes
- Deterministic
어떤 action을 취했을 때, observation, state, reward 모두 한 가지만 존재하게 되는 경우를 의미한다. Robotics와 Controls에서 흔한 사례이다. - Stochastic
어떤 action을 취했을 때, 확률적으로 결과가 나오게 된다. 현실 세계의 문제들과 유사하며, 복잡하고 잠재변수들도 많기 때문에, 똑같은 action을 취하더라도 이에 따라 나올 수 있는 결과는 다를 수도 있다.
- Deterministic
RL Algorithm Components
- Model
agent의 action에 따라 World가 어떻게 변화하는지에 대한 예측 모델이다.- Transition Model
다음 state를 예측하는 모델 - Reward Model
즉각적인 보상을 예측하는 모델
- Transition Model
- Policy
agent가 어떤 action을 취할지 결정하는 것으로, state를 입력했을 때 action을 출력한다.- Deterministic Policy
입력된 state에 따라, 하나의 action이 출력된다. - Stochastic Policy
입력된 state에 따라, 여러 action 중 특정 a를 선택할 확률을 계산한다.
- Deterministic Policy
- Value
특정 policy 하에서 기대되는 보상의 discounted sum. 현재의 보상만이 아닌, 미래의 보상까지 모두 합산한 값이다.
Value Function은 현재의 상태가 얼마나 좋은지 혹은 얼마나 나쁜지를 알려주는 함수이다. 이때, gamma는 0부터 1 사이의 값을 가지는 Discount Factor이며, 미래의 보상에 대한 비중을 나타낸다. gamma가 0일 때는, 즉각적인 보상만 고려함을 뜻하고, 0이 아닌 경우는 미래의 보상에 대해서도 고려함을 의미한다.
Types of RL Agents
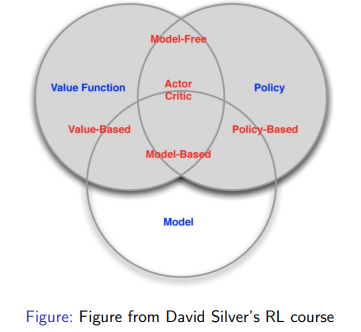
- Model Based
World에 대해 직접적으로 표현한다. 모델은 명시되어 있지만 정책함수와 가치함수는 있을 수도 있고 없을 수도 있다. (모델 안에 정책/가치 함수가 포함된다면 없을 수 있음)
- Model Free
가치함수와 정책함수는 명시되어 있지만, 모델은 그렇지 않다. 추가적인 연산 없이 value와 policy를 알 수 있다.
Exploration and Exploitation
과거의 경험으로 좋아 보이는 것과 미래에 좋을 것 같은 것 사이에서 균형을 맞추는 것을 어렵기 때문에, 우리는 dilemma에 빠지게 된다.
Exploration은 우리가 한 번도 경험해보지 못한 일에 도전하거나, 지금까지는 안좋아 보였지만 미래에는 좋을 것 같은 일에 도전하는 것을 말한다. 반면에, Exploitation은 과거의 경험을 바탕으로 좋을 것으로 기대되는 일을 도전하는 것이다.
Driving으로 예를 들면, 이전 경험에서 나오는 가장 빠른 루트로 목적지에 가는 방법은 Exploitation, 얼마나 시간이 걸릴 지 모르는 새로운 루트로 길을 찾아 가는 것은 Exploration이다.
이렇게 Lecture 1에 대한 정리가 끝났습니다! Introduction인데도 불구하고 엄청 양이 많네요,,🙄 다음에는 Lecture 2. Given the Model of the World로 찾아뵙겠습니다. :)
