개요
엘리스트랙 2차 스터디는 기존 1차 스터디원 분들하고 마음이 잘 맞아서 다시 한 번 같은 멤버로 팀 프로젝트를 진행하기로 했고, 스터디 기간인 3주 동안 영단어장 서비스를 구현하기로했다.
우리는 현재 부트캠프 진도와 동일하게 프론트엔드는 리액트, 타입스크립트, SCSS를 사용하기로 했고, 백엔드는 Node.js, MongoDB를 활용하기로 했다.
이번 프로젝트는 경험이 중요한 만큼 모든 팀원이 풀스택으로 참여하기로 했고, 1,2차로 작업할 페이지를 나눠 1차에는 4명이 프론트엔드를, 3명이 백엔드를 진행하기로하였고 2차에는 파트를 스위치하여 진행하기로했다.
나는 1차에는 백엔드 파트를 담당하여 회원관련 api, 로그인관련 api, 단어 뜻 관련 api를 구현하기로했다.
이번 글에서는 깃과 api 문서를 통한 협업 방식과 팀프로젝트에서 1주차에 백엔드 파트를 맡으며 체화한 내용(3계층 아키텍쳐, 데이터 크롤링), 이슈에 대해 이야기해 보려한다.
📍 깃 협업 방법
프로젝트를 시작하자마자 스터디장 분께서 공용 레포지토리를 만들어주셨다. 우리는 FE, BE 레포를 따로 구분하고 해당 저장소를 각자 Fork해서 각자의 저장소에서 작업하고 풀리퀘스트(PR)를 통해 코드를 합치는 방식으로 작업하였다.
지난번 프로젝트 때 깃랩을 활용하여 팀 작업을 하긴 했지만 이렇게 FE, BE레포를 따로 구분하여 작업한 것도 처음이고 깃헙 사이트에서 코드를 머지하는 방법도 생소했어서 작업을 진행하기 전까지는 여러 의문이 들었었다.
🤔 1. FE, BE 레포를 따로 작업하면 api를 연결하는 작업과 테스트는 어떻게 진행될지?
- 같은 IP를 쓰고 있는 회사에서 작업을 한다면 백엔드 서버의 포트번호에 맞춰 api를 호출할 수 있다.
- 하지만 우리는 각자의 집에서 개발하기 때문에 FE는 BE 레포지토리를 포크하여 머지하고 각자의 로컬환경에서 테스트를 할 수 있다.
- 혹은 미리 배포용 서버에 배포하여 해당 서버로 API를 호출한다. => 실제 API를 사용하므로 실제 환경에 가까운 테스트가 가능하다.
🤔 2. 깃헙 PR을 이용하여 개인들이 작업한 코드를 머지하게 되면 어떻게 내 로컬 저장소로 풀을 받을 수 있을지?
- 풀 리퀘스트(PR)가 머지되면, 해당 변경 사항은 원격 저장소(공용 레포지토리)에 반영된다. 개인 로컬 저장소에서 최신 변경 사항을 받기 위해 git pull <원격저장소명> 명령어를 사용하여 pull을 받으면 된다.
PR 루틴
다음은 참고용으로 나의 PR루틴을 작성해보았다.
1) 로컬 작업 전 항상 공용 저장소에서 pull을 받아 작업환경을 업데이트한다.
git pull <공용 원격 저장소 명(upstream)> <브랜치명(develop)>2) 작업 후 작업한 내용들을 커밋하고 '개인 원격 저장소'에 push한다.
git add <스테이징 할 파일 혹은 폴더 경로>
git commit -m "<커밋 컨벤션에 맞춘 커밋 메세지>"
git push <개인 원격 저장소 명(origin)>3) 깃헙 사이트의 개인 원격저장소에서 pull request 버튼을 클릭한다.
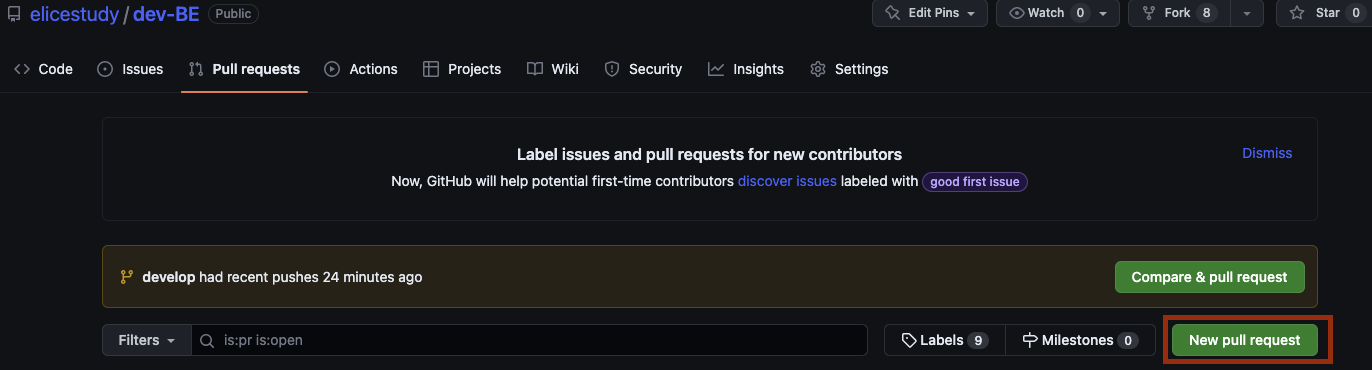
4) 머지할 '공용 저장소'의 레포지토리와 '개인 저장소'의 레포지토리를 알맞게 선택한 뒤 충돌 요소가 있는지 확인한 뒤 creat pull request 클릭
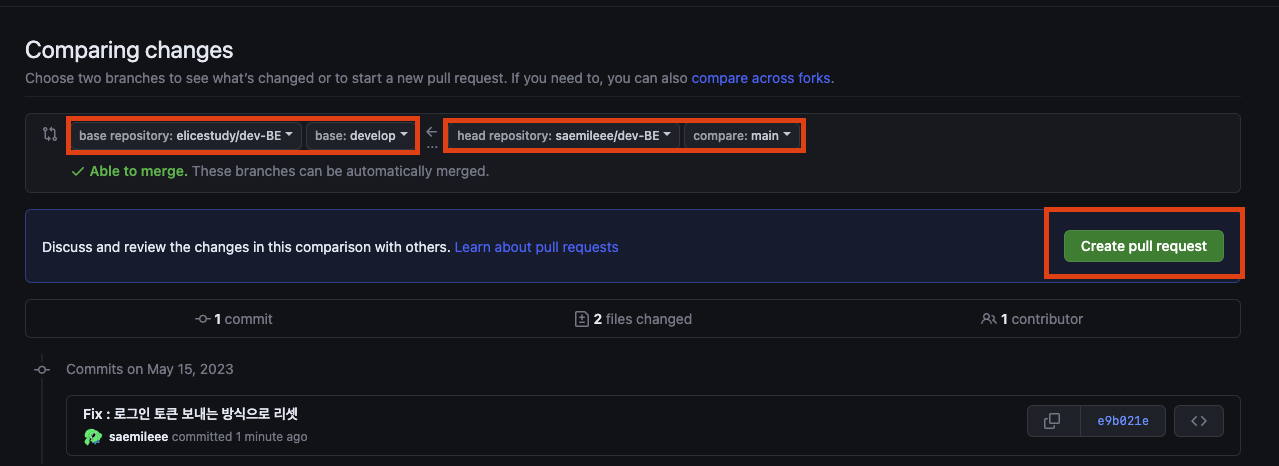
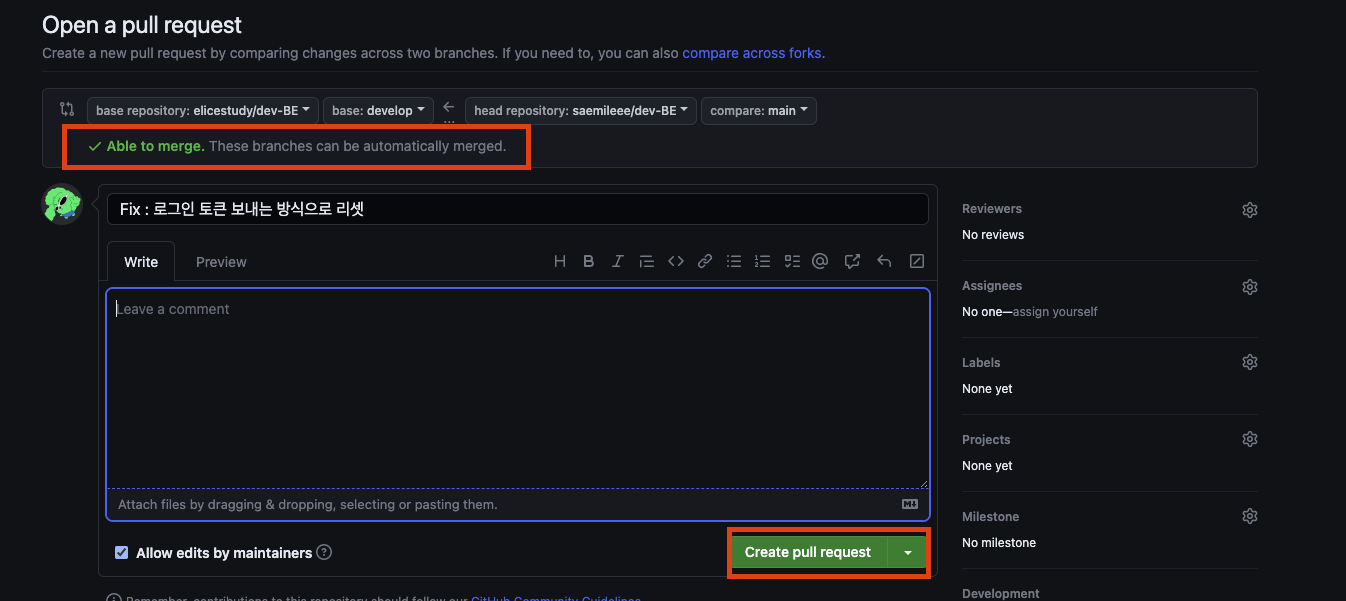
5) 충돌요소가 없으면 PR 메세지를 알맞게 작성한 뒤 creat pull request 클릭
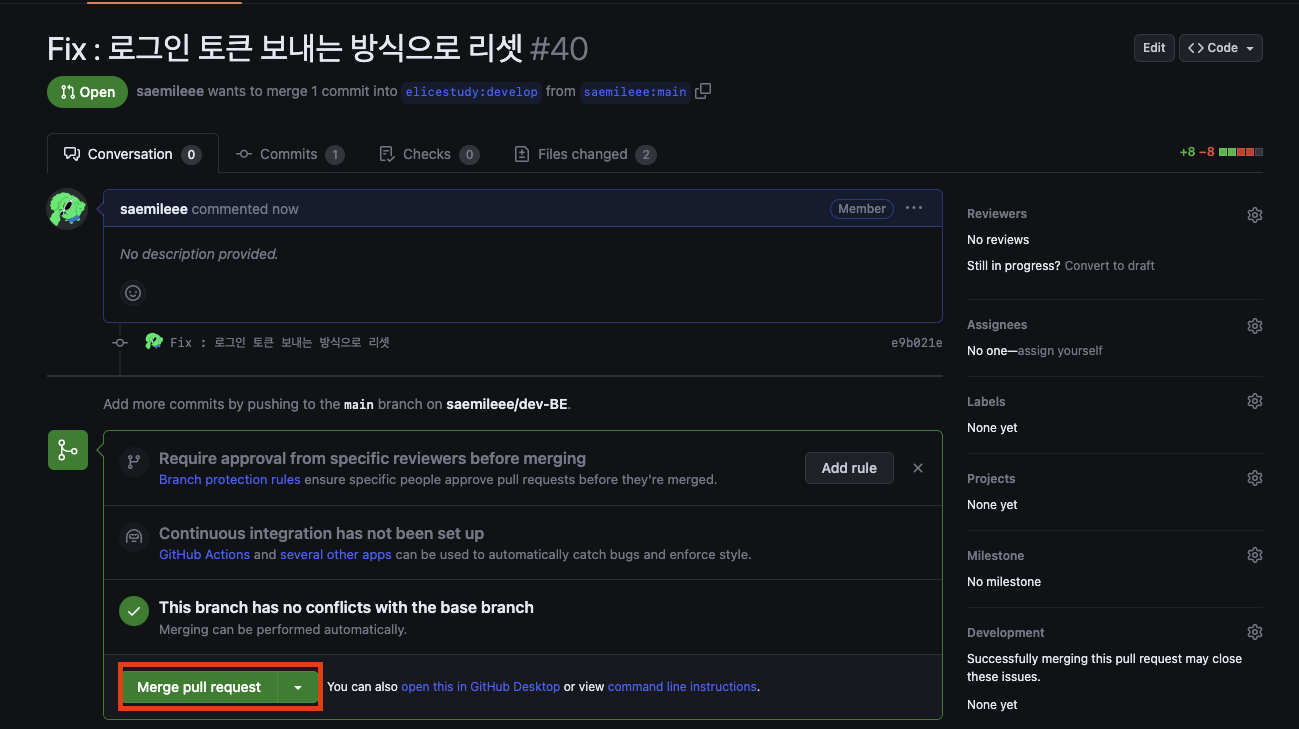
6) pr 생성 뒤 각자 팀의 머지 담당자가 확인 후 Merge pull request를 눌러 공용 레포로 풀을 받으면 끝!
- 충돌이 날 경우 깃 내에서 수정하거나 pr을 close하여 로컬에서 수정해서 다시 진행하면 된다.
🤔 3. 위와 같이 깃을 관리하는 방식이 많이 복잡하다는 생각이 드는데 이점이 무엇일지?
- 각각의 레포에서 개발을 진행하므로, FE와 BE는 독립적으로 개발될 수 있다.
=> 코드베이스 관리와 변경내역, 이슈를 트래킹하기 쉬워진다.
🗒 api 명세서 작성
프론트엔드와 병렬적으로 그리고 레포를 따로 분리하여 작업을 하다보니 데이터 통신 관련 커뮤니케이션이 정말 중요했다. 프론트엔드가 필요한 데이터가 무엇인지 파악해야하고, 프론트엔드에서도 백엔드에 보내야할 데이터와 요청방식이 어떻게 될지 파악하는 것이 정말 중요하다.
지난 1차 프로젝트 (쇼핑몰 구현)에서 백엔드 쪽에서 작성해주신 api명세서를 보며 소통했을 때 정말 유용했다. 그래서 이번 프로젝트에서도 api 명세서를 활용하는 것을 제안하였고 지난번 사용했던 문서 기반으로 api 명세서를 작성하였다. (지난 프로젝트 팀장님께 정말 감사드립니다.)

위와 같이 명세서를 작성하여 소통하니 데이터를 주고 받을 때 필요한 값들과 응답을 한 눈에 파악할 수 있어 api 연결이 수월해 지는 것은 물론, 추가/수정이 되야할 부분도 빠르게 캐치하고 정확하게 피드백을 주고 받을 수 있었다.
🛠 3계층 구조
이전 네모로직 프로젝트에서도 3계층 구조에 따라 직접 코드를 구현 해 보았지만 그 때는 프로젝트를 빨리 구현해야한다는 생각과 첫 백엔드 작업이라 코드 작성에만 급급하여 3계층 구조와 데이터 흐름에 대한 이해도가 낮았다.
감사하게도 작업 전 스터디장 분께서 3계층 구조와 코드 구조에 대해 설명해주시고 예시코드를 보여주셔서 쉽게 프로젝트를 착수할 수 있었다. 습득한 내용에 따라 직접 구조화하고 코드를 작성하며 왜 3계층 구조로 작업을 해야하는지 체화할 수 있었다.
3계층 구조는 다음과 같이 구성된다.
- 프레젠테이션 계층 (Presentation Layer)
- 클라이언트와 상호작용을 담당한다. 이 계층에서는 주로 router와 middleware가 해당된다. 클라이언트의 요청을 받아들이고, 적절한 응답을 반환하는 역할을 한다.
- 비즈니스 계층 (Business Layer)
- 애플리케이션의 비즈니스 로직을 처리한다. 데이터의 유효성 검사, 데이터 가공, 외부 서비스와의 연동 등이 이루어지는 계층이다. 우리 프로젝트에서는 service가 이 계층에 해당된다.
- 데이터 계층 (Data Layer)
- 데이터의 저장, 검색, 업데이트를 처리하는 계층이다. 주로 DB와 상호작용을 담당하며, 데이터 액세스를 위한 로직이 구현된다. 우리 프로젝트에서는 DAO가 이 계층에 해당된다.
- 스터디장분께서 설명 주실 때 router는 클라이언트나 방문객을 직접 대면하는 평사원, service는 평사원이 받아온 업무를 처리하고 조취를 취하는 대리, DAO는 조직 내에서 중요한 정보에 접근하는 권한과 역할을 갖고있는 과장이라고 비유했는데 이 비유가 찰떡이라 기억에 남는다 ㅎㅎ
user 관련 3계층 구조 및 코드 예시
(코드가 길어져 로그인한 유저의 데이터를 받아오는 것, 회원가입을 위해 유저 데이터를 포스트 하는 로직만 올려보겠습니다.)
- 유저 라우터
//user-router.js
const { Router } = require('express');
const { userService } = require('../services/user-service');
const verifyToken = require('../middlewares/auth-handler');
const userRouter = Router();
userRouter.get('/me', verifyToken, async (req, res, next) => {
try {
const { userEmail } = req.user;
const user = await userService.getUserByEmail(userEmail);
res.status(200).json(user);
} catch (err) {
next(err);
}
});
userRouter.post('/', async (req, res, next) => {
try {
const userInfo = req.body;
const user = await userService.createUser(userInfo);
res.status(200).json(user);
} catch (err) {
next(err);
}
});
...
module.exports = { userRouter };
- 유저 로그인 검증 미들웨어
//auth-handler.js (미들웨어)
const jwt = require('jsonwebtoken');
const secretKey = process.env.SECRET_KEY || null;
function verifyToken(req, res, next) {
const token =
req.headers.authorization && req.headers.authorization.split(' ')[1];
if (!token) {
return res.status(401).json({ message: '인증 실패: 토큰이 없습니다.' });
}
try {
const decoded = jwt.verify(token, secretKey);
req.user = decoded;
next();
} catch (err) {
return res
.status(401)
.json({ message: '인증 실패: 토큰이 유효하지 않습니다.' });
}
}
module.exports = verifyToken;- 유저 서비스
//user-service.js
const bcrypt = require('bcrypt');
const { userDAO } = require('../db/dao/user-dao');
const { hashedPassword } = require('../utils/hashing');
const {
validateEmail,
validatePassword,
validateNickname,
} = require('../utils/validator');
class UserService {
async getUserByEmail(userEmail) {
try {
const user = await userDAO.findUserByEmail(userEmail);
if (!user) {
throw new Error(`이메일이 ${userEmail}인 유저가 존재하지 않습니다.`);
}
return { userEmail, nickname: user.nickname };
} catch (err) {
throw new Error('유저 조회에 실패했습니다.');
}
}
async createUser(userInfo) {
const { userEmail, nickname, password } = userInfo;
if (!userEmail) {
throw new Error('이메일이 빈 값입니다.');
}
if (!nickname) {
throw new Error('닉네임이 빈 값입니다.');
}
if (!password) {
throw new Error('패스워드가 빈 값입니다.');
}
const existingUser = await userDAO.findUserByEmail(userEmail);
if (existingUser) {
const error = new Error('이미 존재하는 이메일입니다.');
error.status = 409;
throw error;
}
try {
validateEmail(userEmail);
validateNickname(nickname);
validatePassword(password);
const hashedPwd = await hashedPassword(password);
const user = await userDAO.createUser({
userEmail,
nickname,
password: hashedPwd,
});
return { userEmail: user.userEmail, nickname: user.nickname };
} catch (err) {
throw new Error(err);
}
}
...
const userService = new UserService();
module.exports = { userService };- 유저 DAO
///user-dao.js
const { UserModel } = require('../schemas/user-schema');
class UserDAO {
async findUserByEmail(userEmail) {
const user = await UserModel.findOne({ userEmail });
return user;
}
async createUser(userInfo) {
const user = await UserModel.create(userInfo);
return user;
}
...
}
const userDAO = new UserDAO();
module.exports = { userDAO };이렇게 역할을 분리하고 계층화하여 코드를 작성하게되면 각각의 구성 요소들은 독립적으로 작동하여 변경사항이 발생하여도 다른 요소에 미치는 영향을 최소화할 수 있다. 따라서 코드의 가독성과 유지보수, 재사용성이 높아진다.
🪄 데이터 크롤링
초기 기획 단계에서 사용자가 외우고 싶은 단어를 입력하면 api를 통해 해당 단어의 뜻을 불러오는 기능을 단어 추가 페이지의 핵심 기능으로 기획하였었다.
나는 당연히 사전 api는 쉽게 구할 수 있을 것이라고 생각했는데 찾아보니 대부분 저작권의 이유로 오픈 된 한/영, 영/한 사전 api를 구하기 어려웠다. api가 있더라도 한/영, 영/영 사전과 같이 단방향 언어사전 밖에 없었고, 단어를 입력하면 동음이의어가 있는 것과 상관 없이 한개의 단어 뜻만 나오는 번역 api밖에 없었다.
이를 어쩐담.. 설정한 단어마다 각각 다른 api를 연결해야하나.. 어떻게하나 고민하다가 사전 데이터를 크롤링하는 블로그 글을 보게되었고, 이에 아이디어를 얻어 JS로 데이터 크롤링을 도전해보기로 했다.
cheerio, axios 라이브러리
cheerio : Node.js 환경에서 HTML 파싱과 조작을 도와주는 라이브러리이다. jQuerey와 유사한 API를 제공한다. 주로 웹 페이지의 DOM 요소를 선택하고 데이터를 추출하는데 사용된다.
axios : HTTP 요청을 만들고 처리하는 JS 라이브러리이다. 서버와 데이터를 주고받는데 필요한 HTTP 요청을 손쉽게 생성하고 처리할 수 있다.
axios를 통해 크롤링 할 사이트와 통신하고 cheerio를 통해 데이터를 추출했다.
코드 예시
(해당 사이트의 크롤링 정책상 구체적인 도메인주소와 DOM요소는 대체하였습니다.)
const axios = require('axios');
const cheerio = require('cheerio');
//wordMeaningService
class MeaningService {
async getWordMeanings(lang, word) {
if (!lang) {
const error = new Error('언어가 입력되지 않았습니다.');
error.status = 400;
throw error;
}
if (!['en', 'ko'].includes(lang)) {
const error = new Error('올바르지 않은 언어입니다.');
error.status = 400;
throw error;
}
if (lang === 'en') {
//크롤링 하고자 하는 사이트
const response = await axios.get(
`https://크롤링하고자하는 사이트의 도메인/경로?word=${word}`,
);
const html = response.data;
const $ = cheerio.load(html);
// 검색 결과에서 단어 뜻 부분 추출 (크롤링하고자 하는 사이트의 html 구조를 보고 원하는 요소를 선택)
const meanings = $('.meanings_container > .list_search > li')
.map((index, element) => {
// 뜻 내용
const desc = $(element).find('.txt_search').text().trim();
return `${desc}`;
})
.get();
if (meanings.length === 0) {
const error = new Error('해당 단어의 뜻을 찾을 수 없습니다.');
error.status = 204;
throw error;
}
return meanings;
}
}
}
const meaningService = new MeaningService();
module.exports = { meaningService };클라이언트단에서 lang과 찾고자 하는 word를 string으로 받아와 알맞은 페이지를 찾아 쿼리스트링으로 넣어 axios로 get요청을 보낸 뒤 cheerio 문법으로 원하는 DOM요소를 찾아 단어의 뜻들을 배열로 추출하였다.
포스트맨으로 받아온 결과
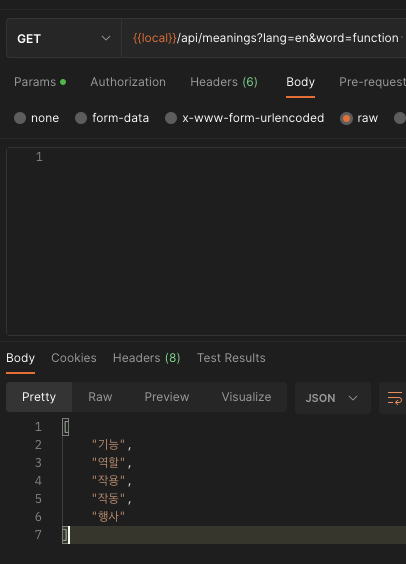
크롤링 api는 FE? BE? 어디서 관리해야하지?
데이터 크롤링을 성공한 후 해당 API를 프론트에서 바로 연결할 것인지, 백엔드에서 관리할 것인지에 대한 고민이 생겼다. 나는 axios로 get 요청을 보내 반환 된 값을 사용하기 때문에 프론트에서 바로 연결하면 되지 않을까? 생각을 했다. 하지만 일반적으로 크로스 도메인 이슈, 보안상의 이유로 크롤링 api는 백엔드에서 관리하는 거라고 한다.
크로스 도메인 이슈 : 웹 브라우저에서 보안상의 이유로 다른 도메인 간에 자바스크립트를 통한 요청이 차단되는 현상. 이러한 이슈를 해결하기 위해서는 JSONP, CORS등의 방법을 사용하여 해결할 수 있다. 또는 서버 사이드에서 프록시를 사용하여 다른 도메인의 데이터를 가져 오는 것도 가능
📡 GET 요청 시 Body에 데이터를 담을 수 없다.
단어 크롤링 시 프론트에서 해석을 원하는 언어 lang와 해당 단어 word를 매개변수로 서비스 함수를 호출해야한다. 그래서 처음에는 /api/meanings/:word로 요청을 보낼 때, 바디에 {word:"단어"}를 받는 방식으로 api를 구현했는데 막상 통신하려고 보니 GET요청을 쓸 때는 바디에 데이터를 담을 수 없었다...ㅎㅎ 정말 너무 어이없는 실수이지만 충분히 간과할만한 실수였다.
그래서 /api/meanings?lang=en&word=function과 같이 쿼리스트링으로 언어와 단어를 받아오는 것으로 수정했다.
💭 느낀점
나 이제 깃 좀 쓸 줄 아는 듯..?
지난 프로젝트에서는 개인 원격 저장소를 따로 두지 않고 바로바로 공용 원격 저장소에 푸시하고 머지하였는데 이번 프로젝트에서 레포를 따로 관리하고 공용/개인 원격저장소를 따로 두고 작업하니 처음엔 복잡했지만 안정성이 높은 것 같아 추후 더 큰 프로젝트를 할 때 굉장히 유용할 것 같다는 생각이 든다. 그리고 약간의 충돌도 겪어보고, 깃 명령어 쓰는 것, 커밋 컨벤션을 지키는 것도 어느정도 익숙해진 것 같아 이제는 더이상 깃이 두렵지 않다 ㅎㅎ
큰 그림을 볼 수 있을 듯..?
프론트엔드 위주로 공부해왔고 백엔드 파트를 담당한 것은 처음이라 살짝 막막했다. 그치만 스터디원 분들의 도움과 피드백으로 3계층 아키텍쳐도 구현해보고, 무사히 api도 만들어보니 전체적인 데이터의 흐름이 잡히고 서비스를 구현하거나 기획함에 있어 전반적인 그림을 그릴 수 있게 된 것 같다. 다음 프론트엔드 작업 시에도 백엔드와 어떻게 통신하고 어떤 api가 필요할지 작업 전에 미리 디테일하게 구상해볼 수 있을 것 같다.
다음 포스팅에서는 이번 프로젝트에서 로그인 api를 구현하며 체화한(삽질한) 내용들에 대해 포스팅해 보려 한다.
