URL Shortener란
긴 URL을 더 짧고 간결한 형태로 변환해주는 서비스나 도구를 말합니다.
https://example.com/some/very/long/path/to/resource -> https://short.ly/abc123
긴 URL을 해시 알고리즘 등을 이용해 고유한 짧은 키로 변환합니다.
짧은 키는 데이터베이스에 매핑되어, 원래의 URL을 찾을 수 있습니다.
사용자가 Short URL을 클릭하면, 서버에서 데이터베이스를 조회해 원래 URL로 리다이렉션하게 해주면 됩니다.
구현 조건
- DAU: 1M
- Url Length:
www.salgu.com/<7 chars> - 1명의 유저는 매일 100개의 URL을 평균적으로 만듭니다.
데이터베이스의 용량은 어느정도 필요할까?
데이터 스키마의 구조부터 만들어보겠습니다.
| id | original_url | short_url | created_at |
|---|---|---|---|
id: 10chars = 10Byte
original_url: 2048chars = 2048Byte (2KB)
short_url: 7chars = 7Byte
created_at: 8Byte
byte단위는 개략적으로 추정하기 위해 제거해주면 약 row당 2KB의 용량을 차지한다고 볼 수 있습니다.
하루에 사용할 DB용량
20KB(row size) * 1M(DAU) * 100(create avg) = 200GB
일년에 사용할 DB용량
200GB * 365(일) = 75.6TB = 80TB
개략적으로 계산할 수 있습니다.
데이터의 갯수는 어느정도 쌓일까?
하루에 생성되는 row 수
100(1 man create avg) * 1M(DAU) = 1억 rows
일년에 생성되는 row 수
1억 rows(하루에 생성되는 row 수) * 365(1년) = 365억 rows = 400억 rows
개략적으로 계산할 수 있습니다.
어떤 데이터베이스를 사용해야 될까?
URL Shortener의 특성상 write는 한번 일어날때 해당 URL에 조회되는 트래픽이 훨씬 많은 특징을 가지고 있는 Read-heavy Service 입니다.
NoSQL vs RDS 비교
분산 데이터 저장:
NoSQL은 샤딩, 파티셔닝 등의 기능을 기본적으로 지원해 자동으로 데이터를 분산하고, 노드 추가 시 부하를 나눕니다.
RDB는 이러한 기능이 기본적으로 없거나, 추가적으로 설계해야 합니다.
쓰기 성능:
NoSQL은 고성능 병렬 쓰기와 장애 허용성을 지원하며, 데이터 볼륨 증가에 따라 자연스럽게 확장.
RDB는 트랜잭션과 인덱스 업데이트로 인해 쓰기 병목이 발생할 수 있습니다.
사용자가 short_url로 original_url을 조회하는 요청이 대부분,
NoSQL은 Key-Value 기반 데이터 모델로 최적화되어 있어, 이런 단일 키 조회 작업에서 읽기 속도가 매우 빠릅니다. ( O(1) 수준의 읽기/쓰기 성능 )
그러므로 NoSQL을 사용하는것이 유리합니다.
short_url 만드는 방식
SHA-256 해싱 + Base62 인코딩 두가지 방식을 사용하여 short_url을 만듭니다.
62의 7승으로 3.5Trillion 개의 조합 가능하고 3.5조 개의 해싱 값에서 매년 400억 개의 row가 생성된다고 가정하면, 사용 가능한 기간은 약 87.5년 동안 사용할 수 있습니다.
이 계산은 해싱 값이 고르게 분포되고 충돌이 없다는 가정 하에 이루어졌습니다.
충돌 처리나 삭제된 row 등을 고려하지 않은 단순 계산이므로, 실제 운영 환경에서는 약간의 오차가 있을 수 있습니다.
SHA-256은 URL을 고정된 256비트(32바이트) 길이의 해시 값으로 변환하는 암호화 해시 알고리즘입니다.
original_url을 암호화하여 64자리(16진수) 해시 값을 생성합니다.
SHA-256 해싱 예:
https://example.com/some/very/long/path/to/resource -> 4bf3b3c8d3d8fb80512203b14ddf760a915ad6821f91eac8342b839812fe4ff8
SHA-256 해시 값은 16진수(0-9, a-f)로 표현되며, 이를 Base62로 변환하여 단축 URL을 생성합니다.
Base62는 URL-safe 문자들로만 구성되어, 생성된 문자열을 안전하게 URL에서 사용할 수 있습니다.
그리고 상위 7자리를 선택하여 short_url 생성합니다.
4bf3b3c8d3d8fb80512203b14ddf760a915ad6821f91eac8342b839812fe4ff8 -> 4bf3b3c
short_url 충돌 방지
해싱 알고리즘 자체는 고유성을 보장하지만, 일부 경우 해시 충돌이 발생할 수 있습니다.
short_url 충돌 확인 쿼리 방법
생성된 short_url이 이미 사용 중인지 데이터베이스에서 확인하고 충돌 시 해시 값의 다음 N자리(예: 8번째 자리)를 추가로 사용하는 방식을 사용할 수 있습니다.
하지만 트래픽이 많아질수록 충돌 확인 요청이 병목을 초래할 수 있습니다.
해당 방식에서 NoSQL의 수평적 확장성과 분산 특성 때문에 충돌 확인 쿼리는 모든 샤드를 확인해야 하므로, 시스템 부하가 증가합니다.
Count를 Increment하여 0~3.5 Trillion 범위의 숫자를 생성하고 이를 인코딩하는 방법
각 요청마다 카운터를 1씩 증가시켜 카운터 값을 생성합니다.
카운터 값을 Base62 등으로 인코딩하여 short_url을 생성합니다.
카운터는 순차적으로 증가하기 때문에, 고유한 값만 생성되고 충돌 방지 로직이 불필요하므로 성능이 향상됩니다.
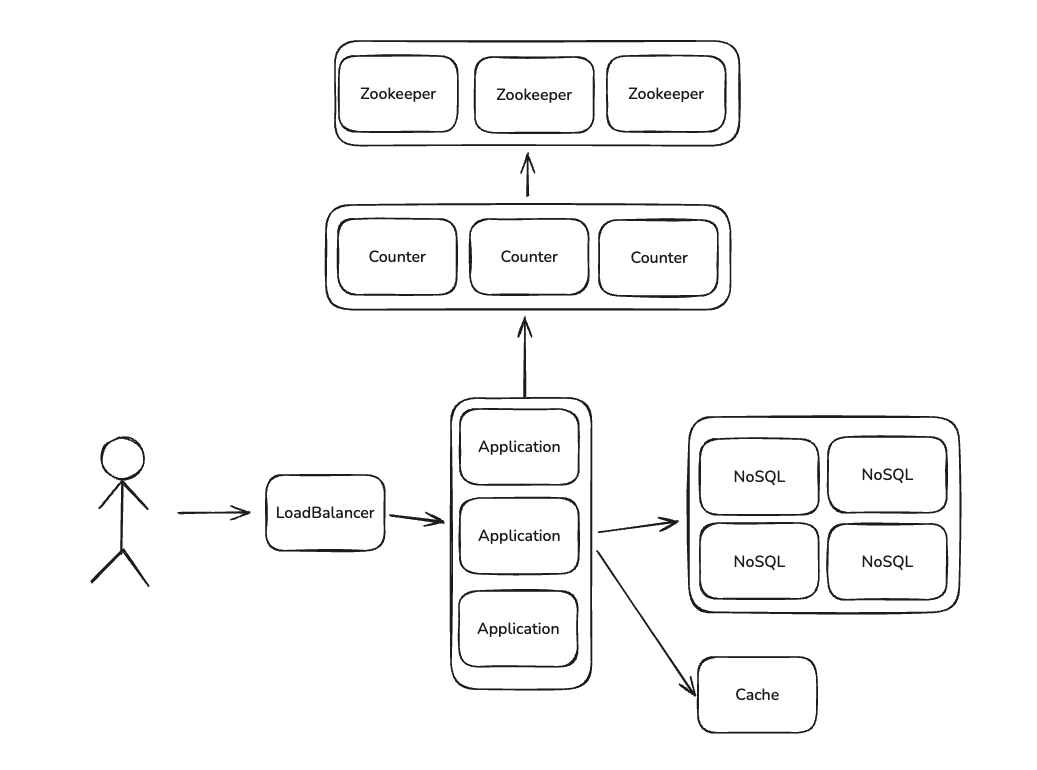
Counter 서비스 구축
Counter 서비스 분리
카운터가 필요한 서비스가 분산된 환경이라면 카운터는 중앙 집중화된 서비스로 분리해야되고
카운터를 호출하는 서비스가 단일 서버 환경에서는 문제가 없으나, 분산된 애플리케이션이 동일한 카운터 값을 동시에 요청하면, 중복된 값이 할당될 가능성이 있습니다.
전역 카운터 값을 동기화하기 위해 락(lock)을 사용하면됩니다.
Counter는 SPOF(single point of failure)?
분산 애플리케이션에서 모든 요청이 카운트 관리 서비스로 집중됩니다.
트래픽이 증가하여 카운트 서비스의 처리 용량이 한계에 도달하여 병목이 발생할 수 있습니다.
이때 Zookeeper를 활용하여 0~3.5 Trillion 범위를 버킷으로 정의합니다.
Zookeeper는 각 버킷을 특정 노드에 할당하고 여러 카운터 서비스가 동일한 카운터 값을 동시에 접근하지 못하도록 보장합니다.
Counter 서비스가 버킷 범위 내의 값을 모두 소진하면, Zookeeper에 새로운 버킷 범위를 요청합니다.
이렇게 사용하게 된다면 Counter 서비스의 확장성과 고유성을 확보할 수 있습니다.
Reference:
