Abstract
버트는 최근 NLP 분야에서 큰 성공을 거두었고, unlabeled data에서 어떠한 언어적 특징을 학습할 수 있는가 연구하고 있는 분야의 몸집을 키웠다. 최근 분석 결과들은 모델의 확률 분포나 representations vector와 같은 산출물에만 초점이 맞춰져있는데, 이러한 연구들을 보완하고자 사전학습 모델의 attention 메카니즘을 분석하고 이를 버트에 적용하고자 한다. 버트의 attention head들은 구분자 토큰이나 구체적인 위치 정보, 전체적인 문장등에 대한 정보를 가지고 있고 그렇다 보니 같은 층의 레이어는 종종 같은 행동 패턴을 보이게된다. 이러한 head들이 문법적이나 언어적인 개념과 상응한다는 것을 보여줄 것이다. 예를 들어, 동사의 직접 목적어나 명사의 관형사, 전치사의 목적어나 참조 대상등을 관리하는 head들을 매우 높은 정확도로 찾아냈다. 마지막에는 attention-based probing classifier를 제안하고 이를 이용해 버트의 attention을 가지고 풍부한 문법 정보들을 보여줄 것이다.
1 Introduction
거대한 사전 학습 언어 모델은 supervised tasks에 finetuning될 때 매우 높은 성능을 냈다. 그러나 왜 이러한 성능을 내게 되었는지는 완벽히 이해하지 못했다. 매우 좋은 결과는 사전 학습이 모델에게 언어적인 구조에 대해 학습시켰기 때문이지만 구체적으로 어떤 특징을 학습시킨것일까?
최근에는 이 질문에 대한 연구가 이루어지고 있다. 엄밀히 선정한 input에 대한 output을 검사하거나 probing classifiers와 같은 방법을 통해 모델의 vector representations를 조사한다. 이러한 연구 방법들처럼 우리도 pre-trained model의 attention maps을 연구했다. attention은 매우 성공적인 신경망의 구성요소인데, 이는 자연스럽게 해석이 가능하다. 왜냐하면 attention weight 자체가 현재 단어의 representation을 계산할 때 특정한 단어에게 얼마나 높은 가중치를 줄것이냐는 명확한 의미가 있기 때문이다. 우리는 많은 tasks에서 굉장히 좋은 성능을 낸 BERT-large 모델의 144 attention heads를 분석했다.
우선, 일반적으로 버트의 attention이 어떻게 작동하는지 파악했다. 여기에는 공통적인 패턴이 존재했는데, 전체적인 문장이나 고정된 위치 offsets에 관여하고 있었다. 엄청나게 많은 버트의 attention들이, 모델에서 no-operation의 한 종류라고 여겨졌던 sep토큰에 집중하고 있었다. 일반적으로 같은 층의 head들은 이러한 유사 행동을 보이는 경향을 보였다.
다음으로는 언어학적인 현상에 대해 각각의 attention head를 조사했다. 특히 각각의 head들을 단어를 입력했을 때 가장 attend하고 있는 다른 단어를 출력하는, 학습이 필요없는 간단한 분류기로 간주했다. 그리고 나서 다양한 구문론적인 관계를 분류하는 head들의 능력을 평가했다. 모든 단일 head는 다수의 relations을 잘 다루지 못했지만, 특정 head는 특정 relation에 눈에 띄게 대응한다는 것을 알았다. 예를 들어 동사의 직접 목적어, 명사의 관형사, 전치사의 목적어, 소유격 대명사의 지칭 대상과 같은 관계를 담당하는 head를 75% 이상의 정확도로 찾아냈다. 또한 coreference resolution에 대해서도 비슷한 분석을 했는데, 버트의 head는 꽤 잘 작동했다. attention heads의 행동은 순전히 unlabeled data를 통한 자가 지도 학습으로 이루어진 것이지 snytax나 coreference에 대한 직접적인 지도가 없었다는 점에서 이러한 결과는 흥미롭다
Coreference resolution, 상호참조해결은 임의의 개체(entity)를 표현하는 다양한 명사구(멘션)들을 찾아 연결해주는 자연어처리 문제이다.
우리의 결과는 특정 헤드가 통사론의 특정 부분을 담당하고 있음을 보여준다. attention head의 syntactic ability를 전반적으로 더 많이 측정하기 위해, attention- maps를 input으로 받는 attention-based probing classifier를 제안한다. 이 분류기는 종속 구문 분석에서 77 UAS를 기록해 버트의 attention에 대해 충분한 syntax를 제공할 수 있다. 몇몇의 최근 연구는 성능을 높이고자 syntactic 정보를 모델과 통합하기도 한다. 그러나 우리는 이러한 종류의 syntax-aware attention 역시 이미 BERT가 학습하였고 그렇기에 좋은 성능으 낸다고 본다.
2 Background: Transformers and BERT
우리의 분석 방법은 attention mechanism을 사용하는 어떤 모델이라도 적용이 가능하지만 논문에서는 large Transformer, BERT를 사용한다. 트랜스포머는 여러 층으로 구성되어 있고, 각 층은 여러 attention heads를 가지고 있다. attention head는 n개의 token으로 구성된 시퀀스를 h개의 벡터 시퀀스로 대응해준다. 각각의 벡터 h는 query, key, value 벡터 q, k, v로 따로따로 선형변환된다. head는 query 벡터와 key 벡터 사이의 softmax-normalized dot product를 통해 모든 words 쌍 사이의 attention weight를 계산한다. 결과 o는 계산된 벡터들의 가중합이다.
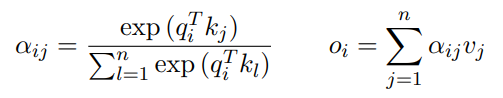
attention weights는 모든 각각의 토큰들이 현재 토큰을 기준으로 다음 representation을 생성할 때 얼마나 영향력을 끼치는 지에 대한 중요도로 간주할 수 있다.
버트는 33억개의 영문 텍스트 토큰을 두 가지 태스크를 통해 사전학습했다. 하나는 masking된 토큰을 알아내는 MLM이며, 다른 하나는 두 개의 시퀀스가 연속되는 시퀀스인지 판단하는 NSP이다. 모델을 추가적으로 지도 학습한 결과는 감정 분석이나 질의 응답과 같은 다양한 분야에서 강력한 성능을 냈다. 버트의 중요한 detail은 사용되는 input text의 전처리이다. special token CLS는 문장의 시작점에 추가되며, 또 다른 token SEP는 문장의 끝점에 추가된다. 만약 입력이 여러개의 문장으로 이루어져 있다면 (예를 들어, 독해 task에서는 분리되어 있는 질문과 지문으로 구성되어 있다) SEP 토큰은 이러한 문장들을 분리할 때도 사용한다. 다음 장에서는 이러한 special token들이 버트의 attention에 얼마나 중요한 역할을 하게 되는지 보여준다. 우리는 1개의 layer가 12개의 attentions heads를 가지고 있는 12개의 layer로 구성된 BERT-base를 사용하였다. <layer>-<head_number>는 특정 attention head를 나타내기 위한 용어로 사용하겠다.
3 Surface-Level Patterns in Attention
구체적인 언어 현상을 관찰하기 전에, 어떻게 버트의 attention이 작동하는지 surface-level의 패턴부터 분석해보려고 한다. 관찰되는 패턴들은 그림 1에서 볼 수 있다.

Setup
무작위로 1000개의 위키피디아 segments에 대해 BERT-base에서 attention을 뽑았다. 우리는 BERT를 pre-training시킬 때 사용하는 setup을 따랐는데, 각각의 segment는 최대 128개의 토큰으로 구성되어 있고 이 토큰들은 위키피디아의 이어지는 문단에서 뽑았다. (masking은 특별히 하지 않았다) 모델의 input은 [CLS]<문단1>[SEP]<문단2>[SEP] 의 포맷이다.
3.1 Relative Position
처음에는 이전 토큰이나 현재 토큰 또는 다음 토큰에 대해 버트의 attention이 얼마나 자주 관여하고 있는지 계산했는데, 대부분의 heads가 현재 토큰에는 그다지 관여하고 있지 않았다. 오히려, 이전 토큰이나 다음 토큰에 대해 강하게 관여하고 있었다. 특히 4개의 attention heads(layer 2, 4, 7, 8)는 이전 토큰에 평균 50% 이상의 attention을 보였고, 5개의 attention heads(layer 1, 2, 2, 3, 6)는 다음 토큰에 평균 50% 이상의 attention을 보였다.
3.2 Attending to Separator Tokens
재미있는건, 적지 않은 수의 버트의 attention들이 고작 몇개의 토큰들에 집중하고 있었다는 것이다. 예를 들어, 버트의 layer 6-10은 SEP 토큰만 포커싱하고 있다. 이를 해석해보자면 대부분의 segments는 128개의 많은 토큰들로 이루어져 있고 SEP 토큰은 segment에서 2번 등장하므로 평균적으로 약 1/64 만큼의 attention을 받는다. 온점이나 반점은 the를 제외하면 가장 많이 등장하는 토큰이다. 반면에 SEP와 CLS토큰은 이들에 비해서 등장횟수는 적지만 늘 존재하고 절대 마스킹되지 않는다는 점에서 모델이 이러한 special token들을 다르게 처리하는 이유일지 모른다. 비슷한 규칙이 uncased BERT에서도 발생하는데, 이러한 패턴은 모델을 통해 얻은 output들 보다 special token들에 대해 주목하는 데에는 구조적인 이유가 있음을 시사한다.
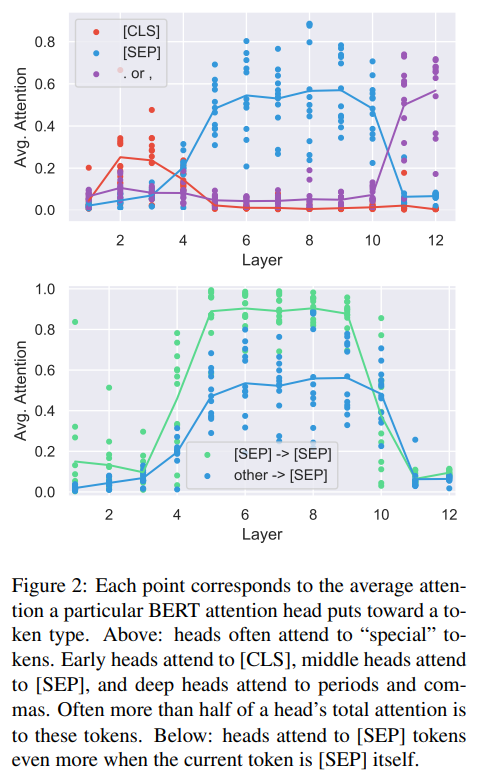
한가지 합리적인 설명은 SEP 토큰이 각 segment를 분리하므로, 특정 head가 SEP 토큰에 집중해서 다른 head들이 segment-level 단위의 정보에 집중할 수 있도록 한다는 것이다. 그치만 추후의 우리가 분석한 내용은 이러한 설명을 납득하지 못하게했는데 만약 이 설명이 맞다면, SEP 토큰을 담당하는 attention head들이 segment-level 단위의 정보를 생성하기 위해 SEP토큰에서 다시 전체적인 segment로 attend 해야한다. 하지만, 실제로는 대부분(90% 이상, 그림 2의 아래를 참고)의 SEP 토큰에 attend하고 있는 head들이 자기 자신을 다시 attend하거나 다른 SEP토큰을 attend하고 있었다. 게다가, 질적 연구 (그림 5에서 확인할 수 있다)는 구체적인 기능을 담당하고 있는 head가 해당 기능이 사용되지 않을 때는 SEP토큰을 참조하고 있는 것을 보여준다. 예를 들어서 head 8-10에서 direct object는 그들의 동사를 참조하게 되는데, 이 때 명사가 아닌 토큰들은 대개 SEP를 attend하고 있는다. 따라서, 해당 attention head의 기능으로 적용되지 않는 토큰들은 "no-operation"과 같은 느낌으로 사용될 때 sepcial token을 attend하는 것으로 추측한다.


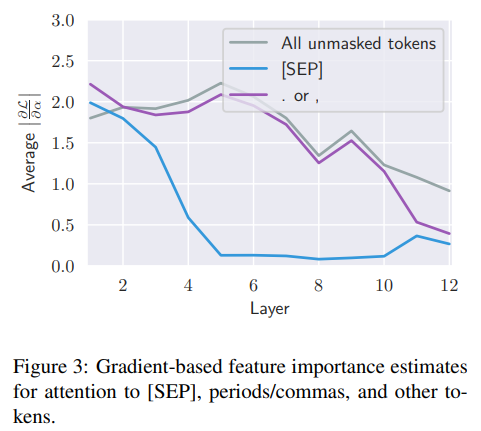
이러한 가설에 대한 추가적인 분석을 위해 우리는 gradient-based measures of feature importance을 적용했다. 특히, BERT의 MLM task의 loss 기울기를 각각의 attention weight의 관점에서 계산했다. 이러한 기울기 값은 토큰에 대한 attention을 얼마나 많이 변화시켜야 버트의 결과가 바뀌게 되는지를 직관적으로 이해할 수 있게한다. 이러한 결과는 그림 3에 있는데, SEP 토큰에 더 많이 attend 하게되는 layer 5부터 이후를 보면 attention에 대한 미분값이 굉장히 작은 것을 볼 수 있다. 이러한 결과는 SEP 토큰에 더 많이 attend하든 또는 적게하든 버트의 output에는 충분한 변화를 주지 못함을 시사한다. 또한 이러한 분석은 SEP 토큰이 no-op으로도 사용된다는 가설을 뒷받침하기도 한다.
3.3 Focused vs Broad Attention
마지막으로, 우리는 attention head가 특정 몇개의 단어에 집중하는지 아니면 전반적으로 많은 단어에 집중하는지를 분석했다. 이를 위해, 각각의 head의 평균 엔트로피를 계산했다. (그림 4를 보세용!) 우리는 몇개의 attention head들, 특히 lower layers에 있는 head들이 매우 넓은 attention을 가지고 있음을 발견했다. 이러한 high-entropy attention heads는 일반적으로 아무리 많아야 10%의 attention을 단일 word에 두었다. 이 heads의 output은 마치 문장의 bag-of-vectors representation처럼 보였다.
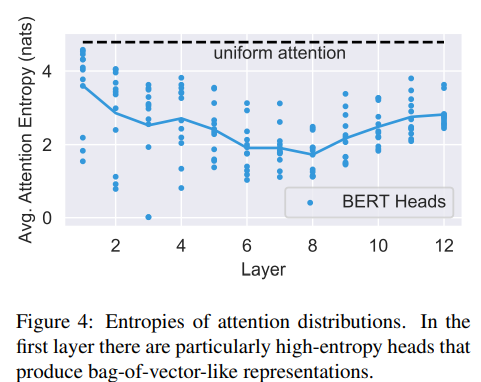
또한, CLS 토큰으로 부터의 엔트로피를 전 attention head에 걸쳐 측정했다. 대부분의 layer에서 CLS 토큰의 평균 엔트로피는 그림 4에서 보여지는 것과 매우 유사했다. 마지막 layer에서는 CLS 토큰으로부터 얻어지는 entropy가 매우 컸다. 이는 곧 매우 넓은 attention을 가지고 있음을 의미한다. 이러한 결과는 CLS 토큰에 대한 representation이 사전학습시 NSP task의 input으로 사용된다는 점에서 이해할 수 있는데, 왜냐하면 CLS 토큰의 representation이 전반적으로 attend 하면서 마지막 layer의 전체적인 input의 representation을 집계하기 때문이다.
4 Probing Individual Attention Heads
다음으로, 모델이 학습한 언어적인 특징이 무엇인지에 대해 조사하기 위해 우리는 개별적인 attention head를 조사했다. 특히, dependency parsing과 같은 task의 labeled datasets에 대한 attention heads를 평가했다.
4.1 Method
우리는 word-level로 head를 분석하려고 했는데, 버트가 여러 token으로 이루어진 byte-pair tokenization을 이용하고 있었다. 그래서, token-token attentions map을 word-word 방식으로 바꾸었다. 여러 token에서 분리된 token의 경우 처음 tokens의 attention weight의 평균값을 적용했다. 이러한 변형은 각각의 단어로부터 얻어지는 attention의 총합을 1로 만들어준다. 이러한 attention head와 word들을 가지고 특정 token이 attend 하든 또는 attend를 받는 가장 attention weight가 큰 word를 모델의 예측으로 찾아내려고 했다.
4.2 Dependency Syntax
Setup
우리는 Stanford Dependencies로 annotate된 Penn Tree bank 중 하나인 월 스트리트 저널의 일부분을 버트에 적용하여 attention map을 추출했다. 각각의 attention head의 예측의 두 방향을 모두 평가했다. 이 방향은 head word의 dependent에 대한 attention과 dependent의 head word에 대한 attention이다. 몇가지 dependency 관계는 다른 head word를 예측할 때 비교적 더 간단했는데 예를 들어 명사의 관형사의 attention 경우 종종 이전에 바로 존재했던 word에 해당했다. 비교하는 것이 목적이기 때문에, 우리는 simple fixed-offset baseline으로 부터 얻어진 결과를 보여주려고 한다. 예를 들어, a fixed offset of -2 라는 뜻은 dependent의 왼쪽 2칸에 있는 어떤 단어는 항상 head word로 간주된다는 뜻이다.
Result
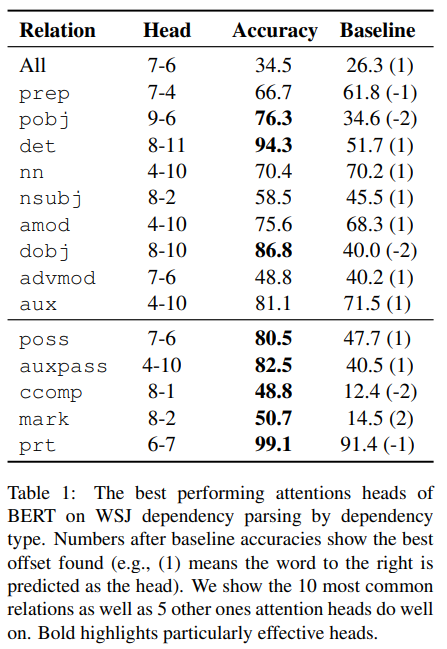
표 1은 전체 관계에서는 잘하는 single head가 없음을 보여준다. 전체 관계에서 최고 성능을 낸 single head의 점수는 34.5 UAS로, 기존 baseline의 26.3 UAS 보다 그다지 높은 점수는 아니다. 이러한 결과는 syntax에 대해 개별적인 attention heads를 평가한 Raganato and Tiedemann (2018)의 결과와 비슷하다.
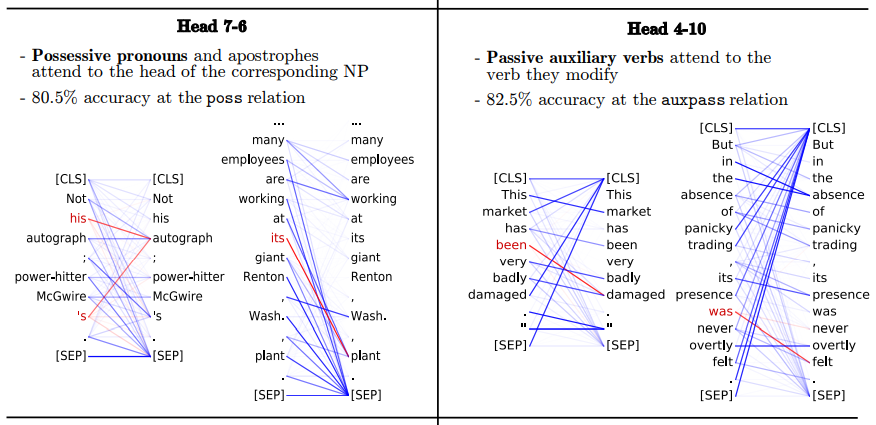
반면에, 특정 head는 특정 dependency relation을 다루고 있고, 때때로 매우 높은 정확도와 baseline과 비교해 매우 높은 점수를 얻기도 했다. 각각의 dependent는 반드시 하나의 head를 가지는 반면에, 각 head는 여러개의 dependent를 가질 수 있으므로, pobj를 제외하고는 테이블 1에 있는 모든 관계가 dependent가 head word에 attentd 하고 있었다. 또 기존의 annotation과는 다른 결과가 나올 수도 있다. 예를 들어 head 7-6는 's를 poss 관계의 dependent로 보았지만, 기존 표준 annotation은's의 보어를 dependent로 정의했다. 이러한 차이는 버트가 단순히 인간이 정의한 틀 안에서가 아닌, self-supervised 학습에 의해 얻은 결과를 가지고 학습한다는 것을 보여준다.
그림 5는 몇가지 attention behavior의 예시를 보여준다. 모델이 학습한 attention weight와 인간이 정의한 통사 관계의 유사성은 놀랍지만, attention head마다 특히 좋은 성능을 내는 관계가 따로 있다. 간단한 베이스라인 코드보다 버트가 약간만 성능이 좋아지므로 개별적인 어텐션 헤드가 전체적인 dependency structure를 파악한다고 말할 수는 없다. attention이 잘 파악할 수 있는 관계가 다른 언어에서도 동일한지 아닌지를 분석해보면 우리의 분석을 확장할 수 있는 재미있는 추후 연구가 될 것이다.
4.3 Coreference Resolution
지금까지의 BERT attention head는 syntax의 측면에서만 설명되었는데 이제는 더욱 어려운 semantic의 측면에서 coreference resolution(이하 co-res.)을 다뤄보고자 한다. coreference links는 대개는 syntactic dependencies보다 훨씬 길며 최신 기술로도 parsing에 비해 좋지 않은 성능을 낸다.
Setup
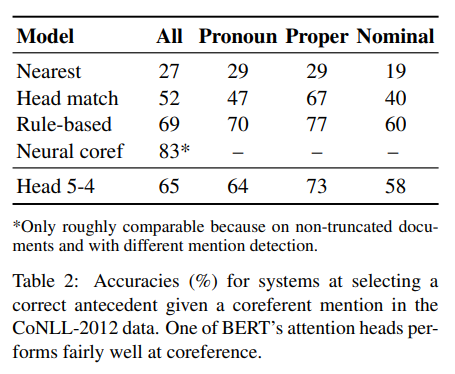
CoNLL-2012 dataset을 사용하여 co-res.에 대한 attention head를 평가한다. 특히 antecedent selection accuracy 라는 평가방식으로 계산한다. 이는, coreference mention 중의 주요 단어가 이러한 mention들의 선행자중 하나의 head에 얼마나 많은 비중으로 attend 하는지 계산하는 방법이다. 우리는 antecedent를 뽑는데에 3가지 베이스라인 방법과 비교했다.
Coreference Mention
- 아래의 글에서 파란 글씨로 보이는 것이 coref. mention들이다.
이미지링크

Antecedent
- 위 글의 첫줄에서 his는 referent, Obama는 antecedent, 선행자이다.
- 가장 가까운 다른 mention 고르기
- 똑같은 same head word를 가지고 있는 가장 가까운 mention 고르기
- Rule-based에 의해 고르기. 다음의 우선순의 조건을 먼저 만족하는 가장 가까운 mention 고르기 (1) full string match (2) head word match (3) number/gender/person match (4) all other mention
우리는 또한 Wiseman et al. (2015)의 최신 neural coreference system의 성능을 공유한다.
Result
결과는 표 2에서 볼 수 있다. BERT의 어텐션 헤드는 좋은 품질의 성능을 냈다. 베이스라인 보다 10개 이상의 정확도 점수를 높였고 rule-based systemp에 가까운 성능을 보였다. 특히 명사같은 mention에서 좋은 성능을 냈는데 아마도 그림 5의 우측 하단에서 보는 바와 같이 동의어들 사이의 미세한 관계를 잡을 수 있었기 때문인 것 같다.
5 Probing Attention Head Combinations
개별적인 어텐션 헤드는 syntax의 특정 부분을 담당하고 있기 때문에 전체적인 모델의 지식은 여러 어텐션 헤드에 퍼져있다. 통합적인 능력을 평가하기 위해서 우리는 새로운 attention-based의 그룹 probing classifiers를 제안한다. 이 분류기들은 dependency parsing을 담당하며, 분류를 위해 버트의 어텐션 output은 고정한다. 이는, 몇개의 파라미터만 조금 훈련시키고 역전파 과정은 거치지 않을 것이라는 뜻이다.
probing classifiers는 기본적으로 graph-based dependency parser이다. 입력 단어가 죽어지면 classifier는 입력 단어와 같은 head에 존재하는 각각의 다른 단어들이 동일한 의미를 지니는지 나타내는 확률 분포를 반환한다.
Attention-Only Probe.
우리는 첫번째 조사는 attention weights의 간단한 선형 결합을 학습하는 것이다.
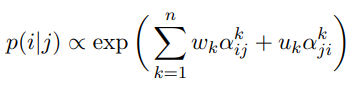
는 단어 i가 단어 j의 syntactic head일 확률이고, 는 단어 i에서 단어 j로의 head k로 부터 생성되는 attention weight이다. n은 head 개수를 의미한다. 어텐션은 양방향이기 때문에, candidate head에서 dependent head 뿐만 아니라 반대로도 고려한다. vector w와 u는 표준 지도 학습 방식으로 학습된다.
Attention-and-Words Probe.
특정 헤드가 특정 syntactic relations를 관할하기 때문에 probing classifiers는 입력 단어로부터 정보를 얻어 활용할 수 있을 것이다. 특히, GloVe 기반 어텐션 head의 가중치를 모델에 사용하였다. 이는 직관적으로 dependent 'the'와 candidate 'cat'에 대해서 probing classifier는 대부분의 weight을 determiner relation를 관장하는 head 8-11에 할당해야 한다. attention-and-words probing classifer는 word i와 word j와의 관계에 대한 확률을 다음과 같이 정의한다.
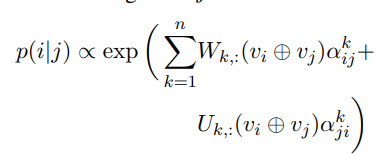
v는 GloVe 임베딩을 ⊕는 concat을 의미한다. GloVe 임베딩은 학습 시 고정되기 때문에 W와 U만 학습되며 내적연산은 특정 head에 적용되는 word-sensitive weight를 만든다.
Results
Stanford dependencies가 annotating한 Penn Treebank dev set에 기반한 방법론으로 평가했다. 다음과 같은 3개의 베이스라인과 비교했다.
- head가 항상 dependent의 오른쪽에 있는 right-branching baseline
- dependent와 candidate의 GloVe 임베딩을 입력으로 받는 simpe one-hidden-layer network
- 우리의 attention-and-words probe. 이 때 bert의 word/positional embedding을 사용하지만, 이들은 모두 랜덤 초기화되어 있다. 이러한 baseline들은 다른 probing tasks에서 좋은 성능을 보여준다.
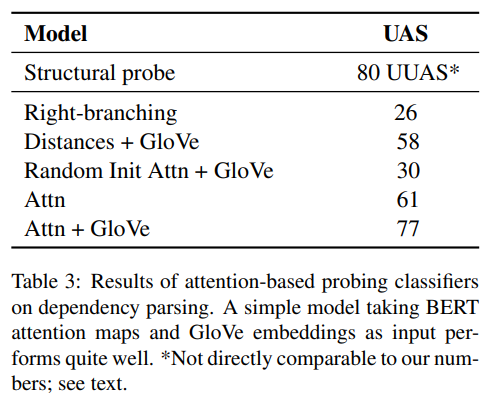
결과는 표 3을 보면 되는데, Attn + GloVe가 매우 성능이 좋았다. 이는 버트의 attention map이 영어 syntax의 표현을 엄청나게 잘한다는 것을 시사한다.
철저한 비교는 될 수 없지만, Hewitt and Manning (2019)의 structural probe의 결과를 보고자 한다. 이들은 버트의 중간단인 attention이 아닌 버트의 마지막 단 representations만을 사용했다. 또, bert의 single layer만을 사용했고 directed aprse trees가 아닌 undirected한 tree를 얻었다. 그리고 tree structure를 직접적으로 예측하기 보다는 두 단어 사이의 syntactic distance를 예측하는 방향으로 학습되었다. 그럼에도 불가하고 우리의 attn + glove probing classifier의 점수와 해당 모델의 점수가 비슷한 이유는 bert's vector representations이 attention map에서 얻을 수 있는 정보 이상으로는 존재하지 않음을 시사한다.
전반적으로, 개별 또는 다중 attention head를 분석한 결과는 버트는 몇몇 syntax 특징을 지도학습의 부산물로서 학습하게 된다는 것이다. agreement task나 internal vector representation에 대한 다른 연구 역시 버트의 prediction을 검사하면서 비슷한 결론을 냈다. 전형적으로 syntax-aware model은 architecture design을 통해 개발되어 오거나 휴리스틱한 treebanks를 통한 직접적인 지도학습으로 개발되어 왔다. 우리의 연구 결과는 발전하고 있는 연구의 한 부분이 되었으며, 언어 모델링과 같은 충분한 pre-training task로 부터 간접적인 supervision이 모델이 언어의 계층적 구조를 이해할 수 있도록 함을 시사한다.
