🎯 Process
1. 데이터 확인하고 정리하기
2. 데이터 재배열하기
3. Google Maps
1. 데이터 확인하고 정리하기
1-1. 데이터 읽어오기
- thousands=','옵션
: ,(comma)가 포함된 숫자는 문자로 인식될 수 있으니, comma를 빼고 숫자를 읽으라는 옵션
- encoding 옵션
: 한글 깨짐 방지
import pandas as pd
import numpy as np
crime_raw_data = pd.read_csv('../data/02. crime_in_Seoul.csv',
thousands = ',',
encoding='euc-kr')
crime_raw_data.head(3)
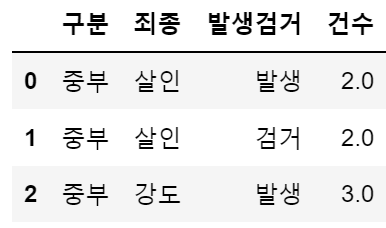
1-2. 데이터 파악하기
crime_raw_data.info()
crime_raw_data['죄종'].unique()
crime_raw_data= crime_raw_data[crime_raw_data['죄종'].notnull()]
2. 데이터 재배열하기 (Pandas pivot_table)
2-1. Pandas pivot_table
- 기존 DataFrame에서 새로운 기준으로 재정렬해줌
- 기준 index를 여러 개 지정할 수 있음
- values를 지정할 수 있음
- 이 외에도 columns, aggfuc, fill_value 등의 옵션이 있음
crime_satation = crime_raw_data.pivot_table(crime_raw_data,
index=['구분'],
columns=['죄종','발생검거'],
aggfunc=[np.sum]
)
crime_satation.head()
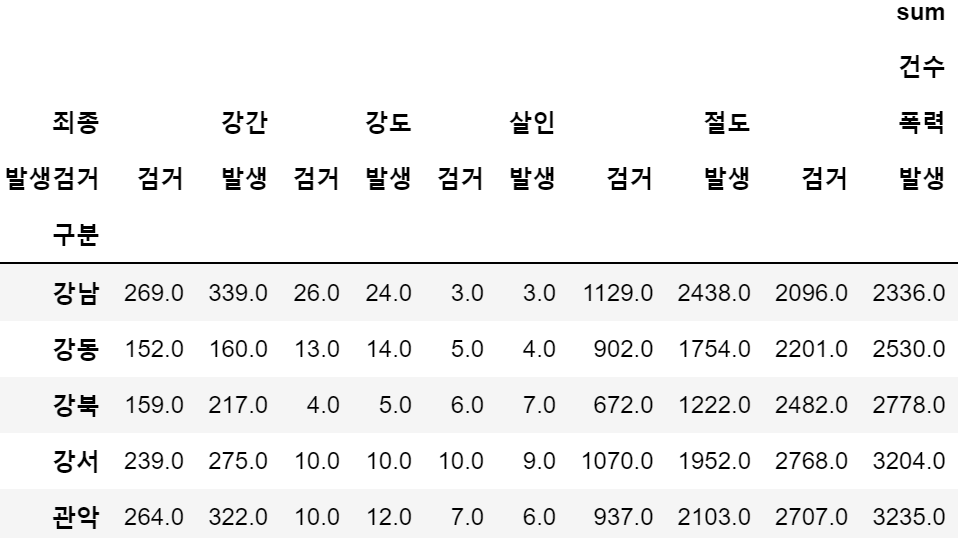
2-2. 다중 컬럼에서 특정 컬럼 제거하기
crime_satation.columns = crime_satation.columns.droplevel([0,1])
crime_satation.columns
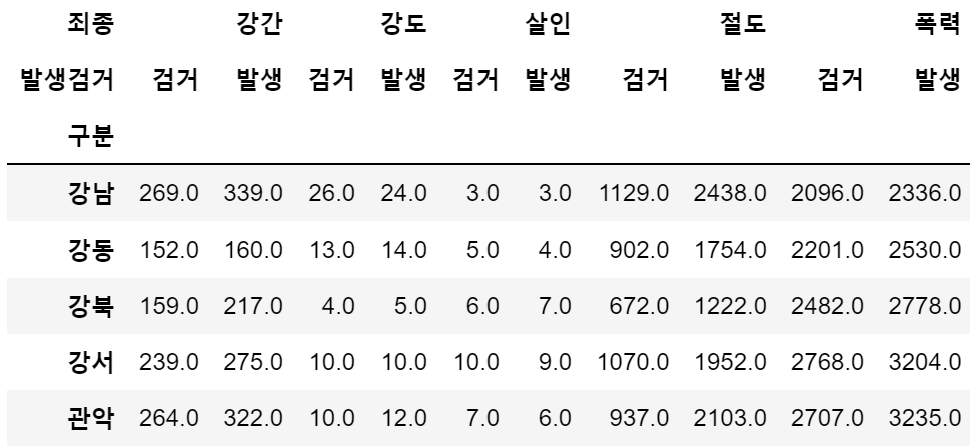
3. Google Maps
3-1. Google Maps API 설치
- conda install -c conda-forge googlemaps
- 이때 Google Map API Key도 필요
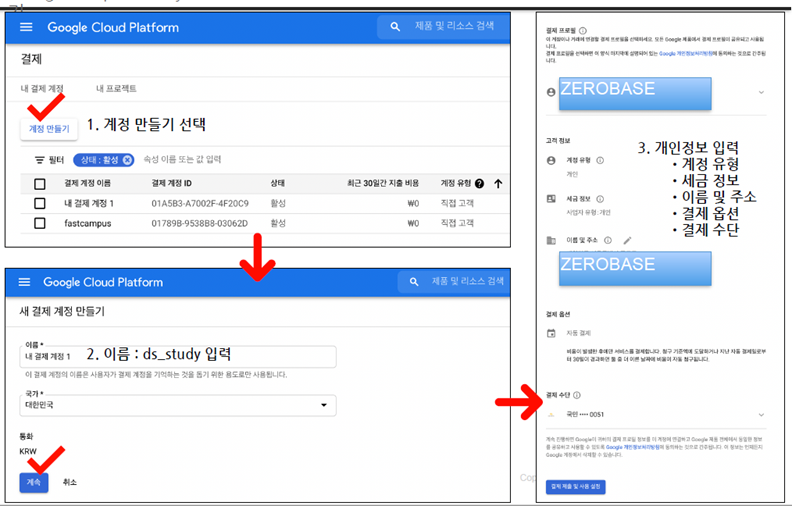
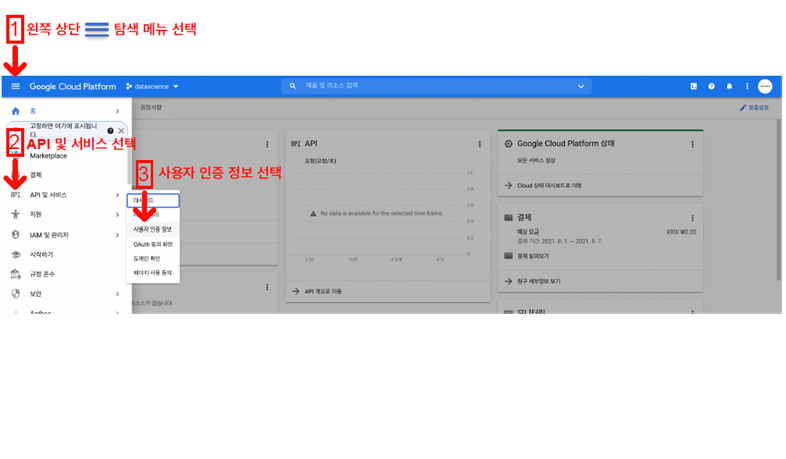
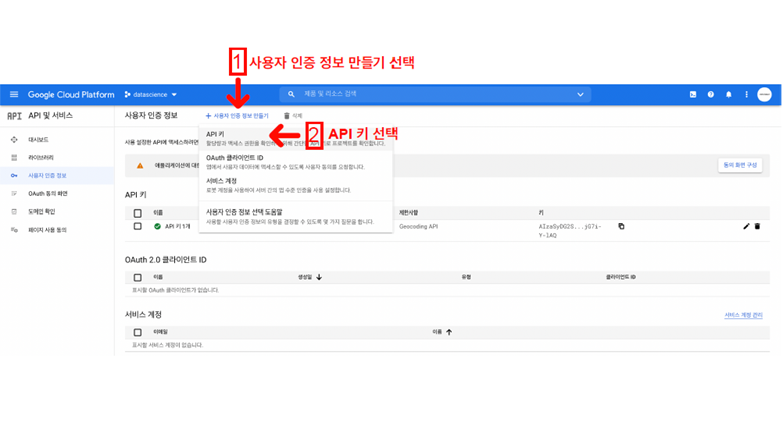
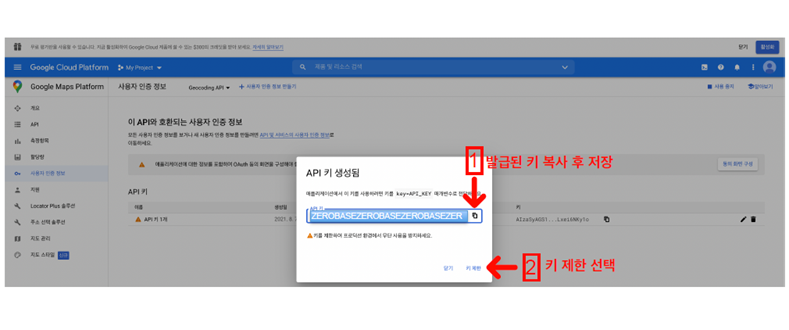
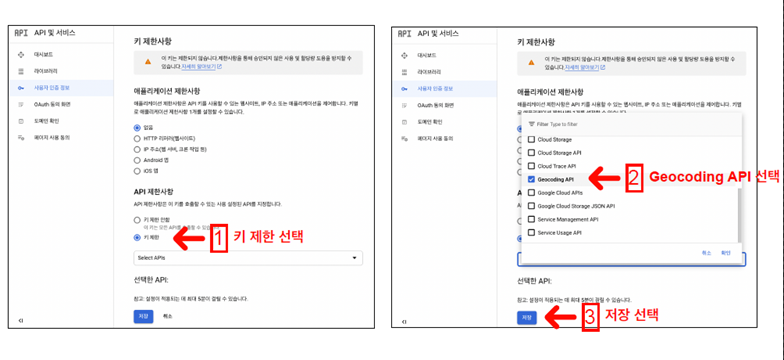
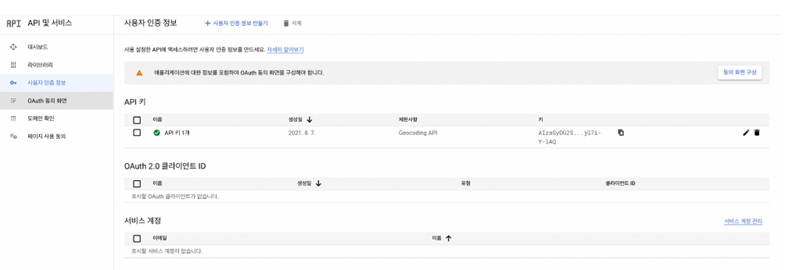
3-2. 주소와 위치정보 얻기
- 경찰서 이름에서 소속된 구이름 얻기
- 구이름과 위도 경도 정보를 저장할 준비
- 반복문을 이용해서 위 표의 NaN을 모두 채우기
- iterrows() 사용
import googlemaps
gmaps_key = GOOGLE_MAP_KEY입력
gmaps = googlemaps.Client(key=gmaps_key)
cnt = 0
for idx, rows in crime_satation.iterrows():
station_name = '서울'+idx+'경찰서'
print('##',station_name)
tmp = gmaps.geocode(station_name, language='ko')
if station_name =='서울관악경찰서':
tmp_gu = '서울시 관악구 관악로5길 33'
else:
tmp_gu = tmp[0].get('formatted_address')
print (tmp_gu)
lat = tmp[0].get('geometry')['location']['lat']
lng = tmp[0].get('geometry')['location']['lng']
crime_satation.loc[idx,'lat'] = lat
crime_satation.loc[idx,'lng'] = lng
crime_satation.loc[idx,'구별'] = tmp_gu.split()[2]
print(cnt)
cnt += 1
crime_satation.head(3)
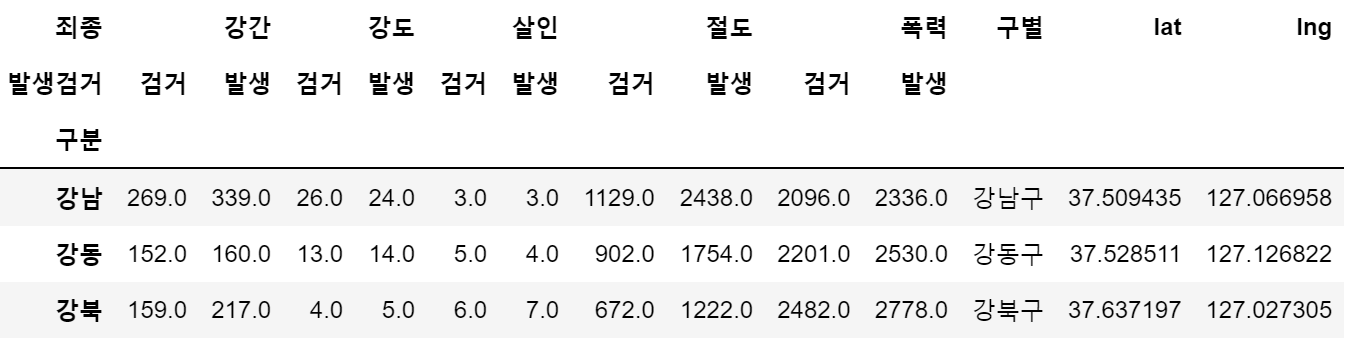
3-3. column명 재설정
tmp = [
crime_satation.columns.get_level_values(0)[n]+crime_satation.columns.get_level_values(1)[n] for n in range(0,len(crime_satation.columns.get_level_values(0)))
]
crime_satation.columns = tmp
4. 구별 데이터 정리
target = ["강간검거율",'강도검거율','살인검거율','절도검거율','폭력검거율']
num = ["강간검거",'강도검거','살인검거','절도검거','폭력검거']
den = ["강간발생",'강도발생','살인발생','절도발생','폭력발생']
crime_anal_gu[target] = crime_anal_gu[num].div(crime_anal_gu[den].values) *100
del crime_anal_gu['강간검거']
del crime_anal_gu['강도검거']
del crime_anal_gu['살인검거']
del crime_anal_gu['절도검거']
del crime_anal_gu['폭력검거']
crime_anal_gu[crime_anal_gu[target] > 100] = 100
crime_anal_gu.rename(columns={
'강간발생': '강간',
'살인발생': '살인',
'절도발생': '절도',
'폭력발생': '폭력',
'강도발생': '강도'},
inplace=True
)
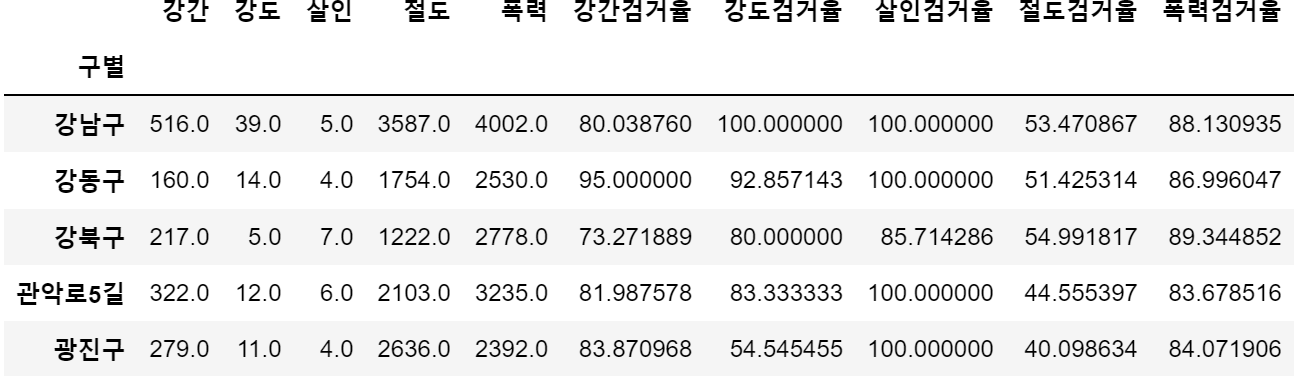
5. 데이터 정규화
col=['살인','강도','폭력','절도','강간']
crime_anal_norm = crime_anal_gu[col] / crime_anal_gu[col].max()
col2 = ['강간검거율','강도검거율','폭력검거율','절도검거율','살인검거율']
crime_anal_norm[col2] = crime_anal_gu[col2]
col = ['강간','강도','살인','절도','폭력']
crime_anal_norm['범죄'] = np.mean(crime_anal_norm[col], axis=1)
6. 시각화
6-1. 모듈 import
import matplotlib.pyplot as plt
import seaborn as sns
from matplotlib import rc
plt.rcParams['axes.unicode_minus'] = False
get_ipython().run_line_magic('matplotlib', 'inline')
rc('font', family='Malgun Gothic')
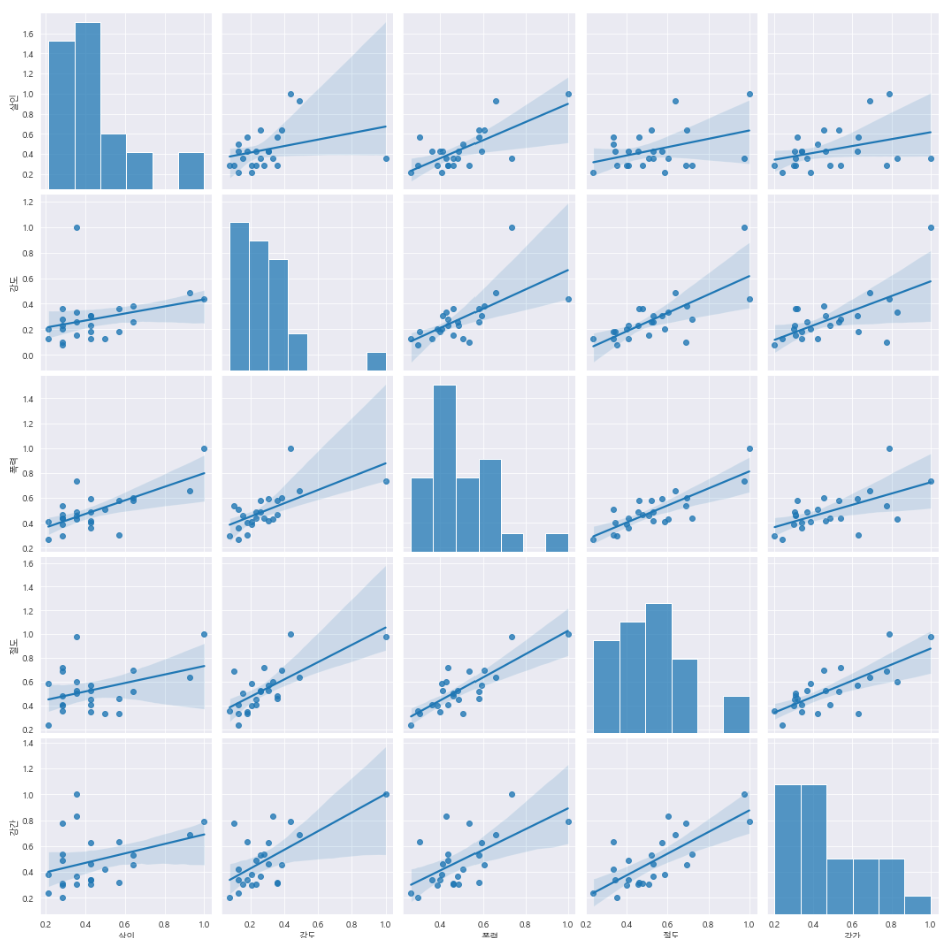
6-2. 상관관계 확인
sns.pairplot(data=crime_anal_norm,
vars=['살인','강도','폭력','절도','강간'],
kind='reg',
height=3
)
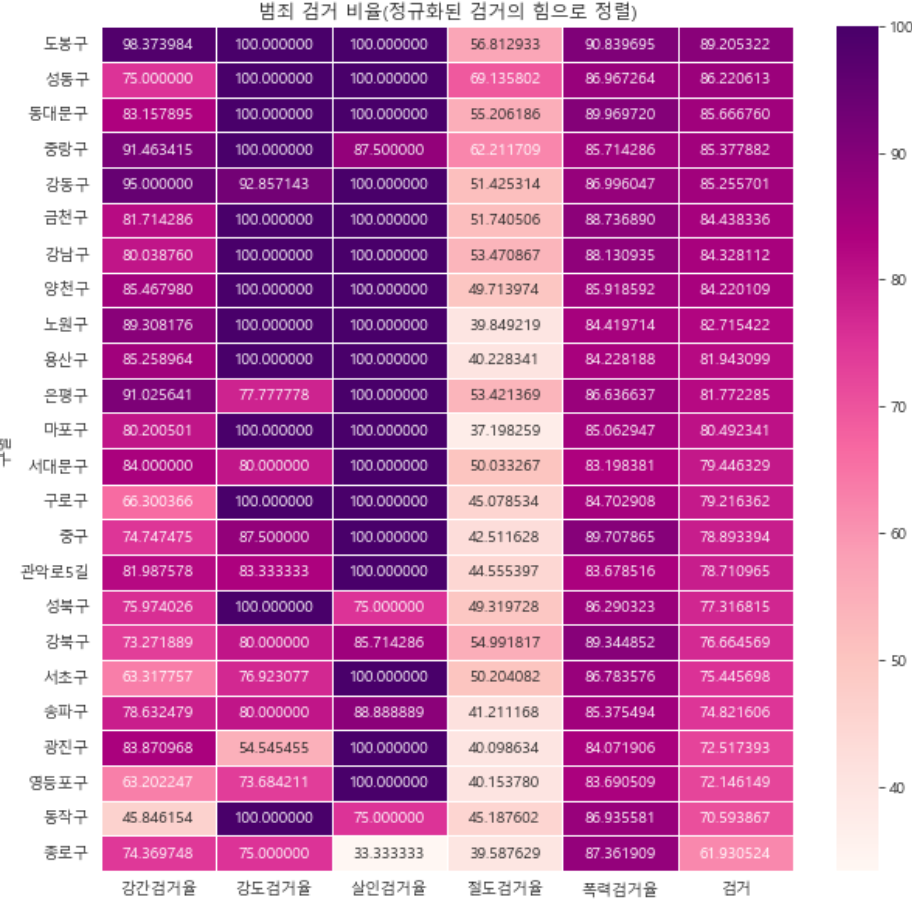
6-3. heatmap
def drawGraph():
target_col=['강간검거율','강도검거율','살인검거율','절도검거율','폭력검거율','검거']
crime_anal_norm_sort = crime_anal_norm.sort_values(by='검거', ascending=False)
plt.figure(figsize=(10,10))
sns.heatmap(
data=crime_anal_norm_sort[target_col],
annot=True,
fmt='f',
linewidths=0.5,
cmap='RdPu'
)
plt.title('범죄 검거 비율(정규화된 검거의 힘으로 정렬)')
plt.show()
drawGraph()
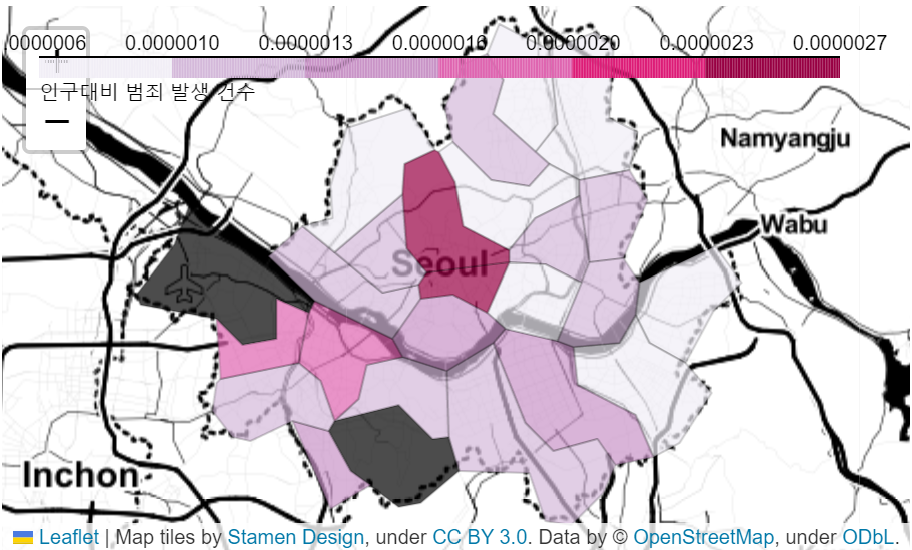
7. 지도 시각화 Folium
import folium
import pandas as pd
import json
geo_path = '../data/02. skorea_municipalities_geo_simple.json'
geo_str = json.load(open(geo_path, encoding='utf-8'))
my_map = folium.Map(
location=[37.5502,126.982],
zoom_start=11,
tiles='Stamen Toner'
)
folium.Choropleth(
geo_data=geo_str,
data = crime_anal_norm['범죄'],
columns=[crime_anal_norm.index, crime_anal_norm['범죄']],
key_on='feature.id',
fill_color='PuRd',
fill_opacity=0.7,
line_opacity=0.2,
legend_name="정규화된 5대 범죄 발생 건수"
).add_to(my_map)
my_map
추가>> conda 명령
- pip를 사용하면 conda환경에서 dependency 관리가 정확하지 않을 수 있다.
- 명령어
* conda list: 설치된 모듈 list
- conda install module_name: 모듈 설치
- conda uninstall module_name: 모듈 제거
- conda install -c channel_anme module_name
- !! 그러나 모든 모듈이 conda로 설치되는 것은 아니다.
➰마무리
- 내용은 어렵지만 한 눈에 들어오는 시각화 데이터라 흥미로웠다.
- 한 번에 너무 많은 내용을 배워서 내가 다 소화할지 의문이다.
- 여러 번 반복해야겠다.

