※ 전남대학교 박태준 교수님의 운영체제 강의를 듣고, 정리한 내용입니다.
페이지 테이블 관리는 쉬운 일이 아닙니다.
-
하나의 시스템에 여러 개의 프로세스가 존재
-
각 프로세스마다 페이지 테이블이 하나씩 존재하기 때문!
메모리 관리자는 특정 프로세스가 실행될 때 마다 해당 페이지 테이블을 참조하여 가상 주소를 물리 주소로 변환하는 작업을 반복해주어야 합니다.
-
페이지 테이블은 메모리 관리자가 자주 사용하는 자료 구조 → 빨리 접근해야 함
-
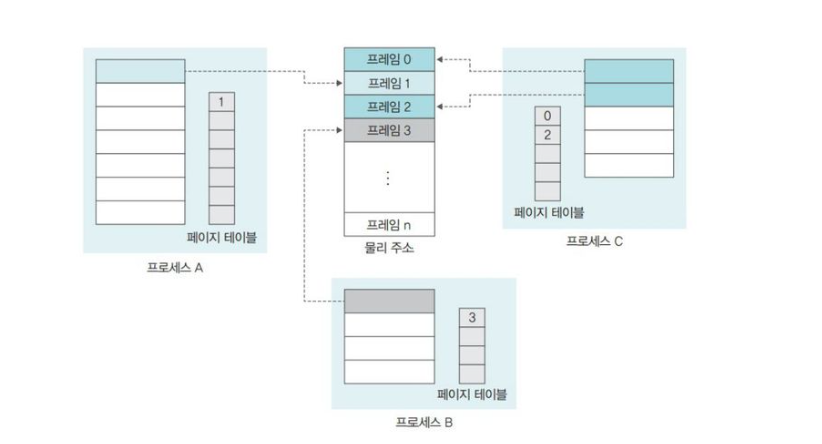
따라서 페이지 테이블은 물리 메모리 영역 중 운영체제 영역 ( 커널 ) 의 일부에 모아둠
여기서 발생하는 문제점은 다음과 같습니다.
-
1번의 메모리 엑세스를 위해 2번의 물리 메모리 엑세스가 필요함
- 페이지 테이블을 읽기 위해서 1번
- 진짜 데이터를 참조하기 위해서 1번
-
페이지 테이블의 낭비
- 대다수의 프로세스가 모든 메모리 공간을 다 쓰진 않기 때문에, 대부분의 페이지 테이블 항목은 비어있게 됨
-
페이지 테이블도 스왑 대상
- 프로세스만 스왑 영역으로 옮겨지는 것이 아니라 페이지 테이블의 일부도 스왑 영역으로 옮겨짐
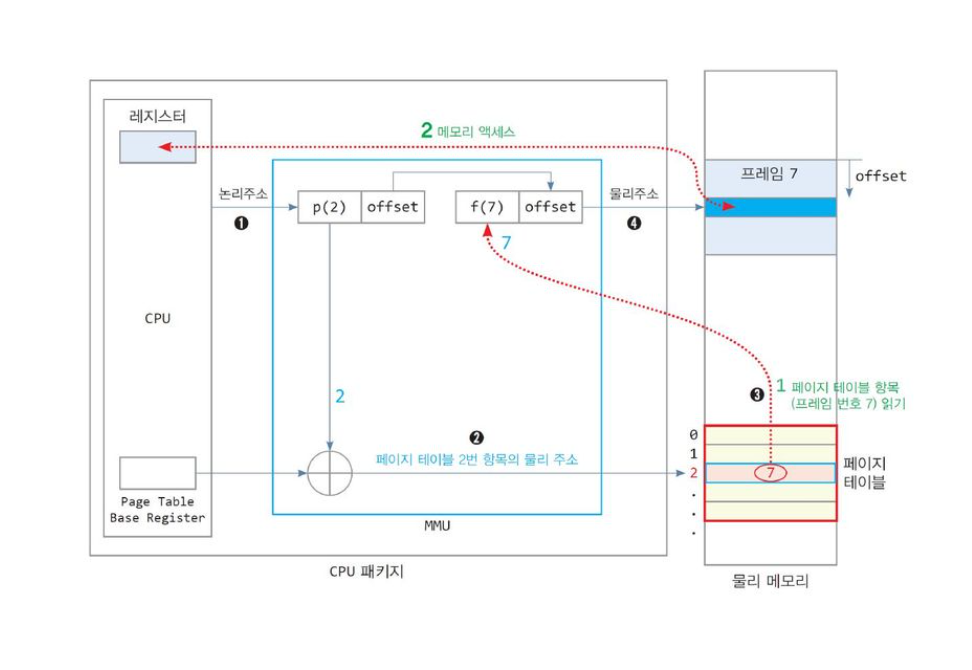
1. 메모리 2회 접근 문제
프로세스 주소 공간 → 물리 메모리의 프레임 ( 페이지 테이블 ) 에 접근 → 프레임 접근
비슷한 작업을 2번이나 반복하다보니, 이 문제를 해결하고자 캐싱을 도입하였습니다.
TLB ( Translation Loock-aside Buffer )
논리 주소를 물리 주소로 바꾸는 과정에서 중간 과정인 페이지 테이블을 읽어오는 시간을 없애거나 줄이고자, 페이지 접근에 대한 캐시 ( TLB ) 를 두었습니다.
-
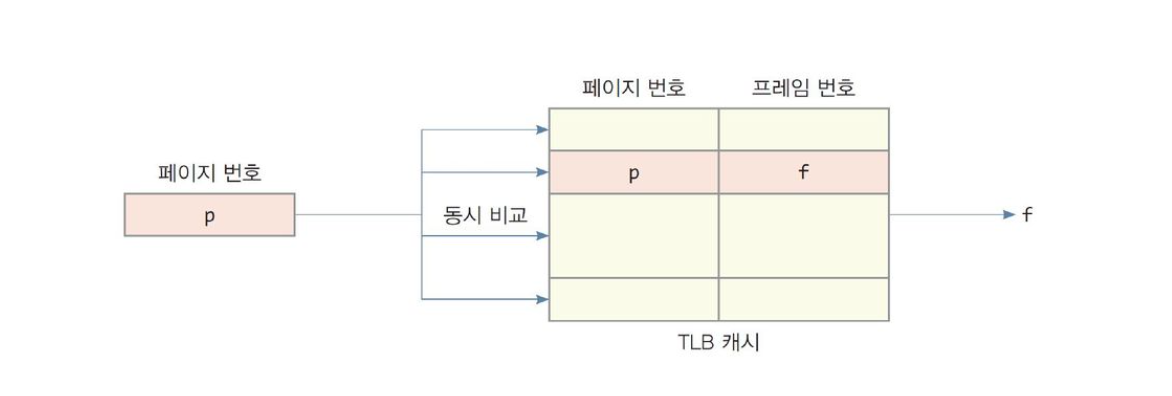
MMU 안에 위치하여, 최근에 접근한 페이지와 프레임 번호의 쌍을 항목으로 저장하는 캐시 메모리
-
[페이지 번호 p, 프레임 번호 f] 를 항목으로 저장 → 연관 매핑
-
Content-Addressable Memory ( CAM ) 또는 associative memory 라고 불림 ( 비싸다..!! )
TLB 메모리 엑세스
-
CPU 로부터 논리 주소 발생
-
논리 주소의 페이지 번호가 TLB 로 전달되고, 페이지 번호와 TLB 내 모든 항목을 동시에 비교
- TLB 에 페이지가 있는 경우, TLB Hit → TLB 에서 출력되는 프레임 번호와 Offest 값으로 물리 주소 완성
- TLB 에 페이지가 없는 경우, TLB Miss → TLB 는 Miss 신호 발생
- MMU 는 페이지 테이블로부터 프레임 번호를 읽어와서 물리 주소 완성
- 미스한 페이지에 [페이지번호, 프레임번호] 항목을 TLB 에 삽입
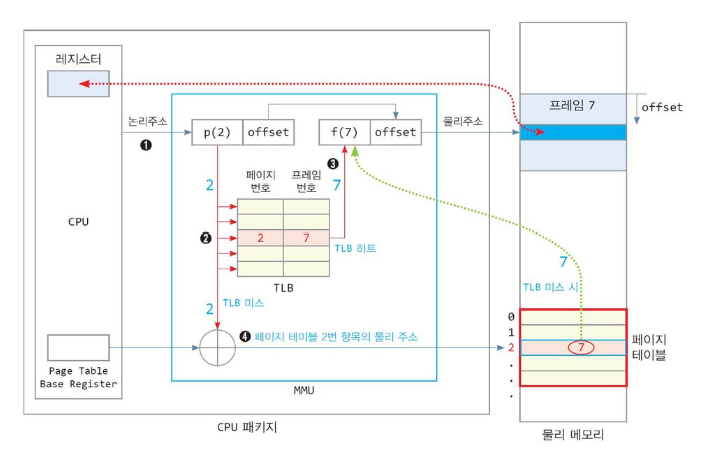
예제
TLB 의 간단한 예제를 하나 살펴보면..
가정
-
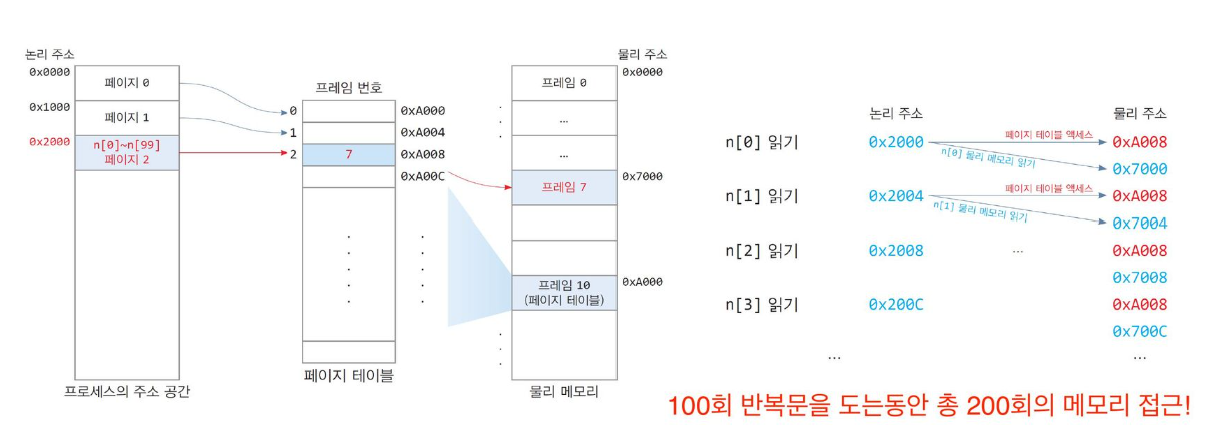
32bit CPU, 페이지는 4KB
-
배열 n[100] 의 논리 주소는 0x2000 ( 페이지 2 ) 부터 시작
-
배열 n[100] 의 물리 주소는 0x7000 ( 프레임 7 ) 부터 시작
-
배열 n[100] 의 크기는 400byte 이며 페이지 2 에 모두 들어있음
- 페이지 테이블 2번의 주소 : 0xA008
-
페이지 테이블은 물리 메모리 0xA000번지부터 시작
n[0] 을 읽었을 때
아직 TLB 에 들어있는 값이 없기 때문에, TLB Miss
→ MMU 는 페이지 테이블로부터 프레임 번호를 읽은 후 물리주소 완성
→ 미스한 페이지에 [페이지번호, 프레임번호] 항목을 TLB 에 삽입

n[1] 을 읽었을 때
TLB 엔 이제 [2, 7] 이라는 페이지번호와 프레임번호의 쌍이 존재
→ TLB Hit, TLB 에서 출력되는 프레임 번호와 Offset 으로 물리 주소 완성

TLB 성능
TLB 의 성능이 높이기 위해선 2가지 방법이 존재합니다.
- TLB 항목 늘리기 ( 대신 많이 비싸다.. )
- 페이지 크기 키우기
페이지 크기가 크다는 말은, 페이지 하나하나의 크기가 크기 때문에 전체 페이지의 갯수는 줄어든다 와 같은 뜻입니다.
그래서 페이지가 클수록 TLB 와의 갯수차이가 줄어드니, TLB 히트율은 올라가게 됩니다.
- TLB 항목이 10개일 때 페이지가 100개 일때와, 100000개일 때는 히트율이 많이 다름
물론 페이지 크기가 커질수록 내부 단편화가 증가하게 되므로 메모리 낭비가 심해집니다.
- 그래서 이 둘 사이엔 Trade - Off 존재, 선택의 문제
2. 페이지 테이블 메모리 낭비 문제
-
32비트 CPU 환경에서 프로세스당 페이지 테이블 크기
- 프로세스의 주소 공간 : 4GB / 4KB = 2^32 / 2^12 = 2^20 = 약 100만개의 페이지로 구성
- 프로세스당 페이지 테이블의 크기
- 한 항목이 4Byte 이면, 2^20 * 4byte = 4MB
-
10MB 의 메모리를 사용하는 프로세스가 있다고 하면
- 실제 활용되는 페이지 테이블 항목 수 : 10MB / 4KB = 2560개
- 실제 활용되는 페이지 테이블 비율 : 2560 / 2^20 = 10 / 2^12 = 약 0.0024
- 활용률이 매우 낮다..
이렇게 활용률이 낮은 문제점을 해결하기 위해 두가지 해결법을 도입하였습니다.
- 역 페이지 테이블 ( IPT, Inverted Page Table )
- 멀티 레벨 페이지 테이블 ( multi-level page table )
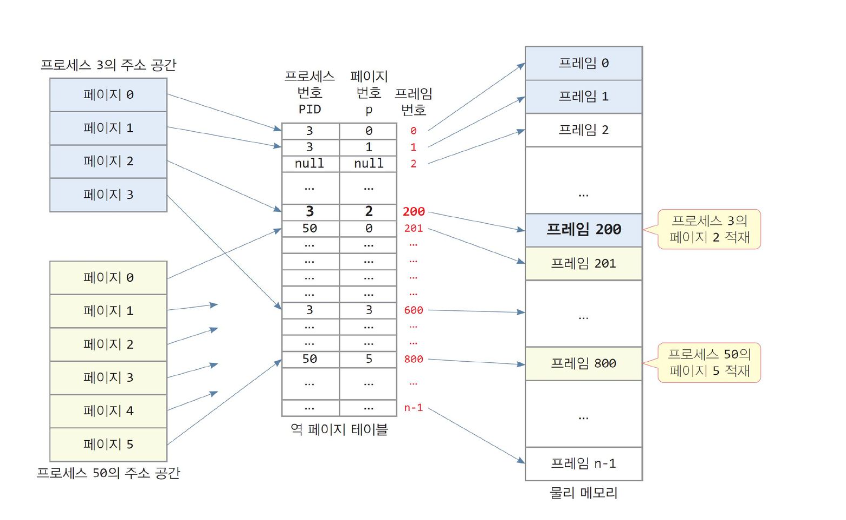
역 페이지 테이블 ( IPT, Inverted Page Table )
-
물리 메모리의 프레임 번호를 기준으로 테이블 작성
- 시스템에 하나의 역 페이지 테이블만 둠 ( 역 페이지 테이블 항목의 수 = 물리 메모리의 프레임 개수 )
- 역 페이지 테이블의 인덱스 : 프레임 번호
- 역 페이지 테이블 항목 : [프로세스번호( PID ), 페이지 번호 ( P )]
-
역 페이지 테이블을 사용한 주소 변환
- VA = <PID, Page num, Offset>
- 논리 주소 → ( 프로세스 번호, 페이지 번호 ) 로 역 페이지 테이블 검색
- 일치하는 항목을 발견하면 항목 번호가 바로 프레임 번호
- 프레임 번호와 오프셋을 연결하면 물리 주소가 됨
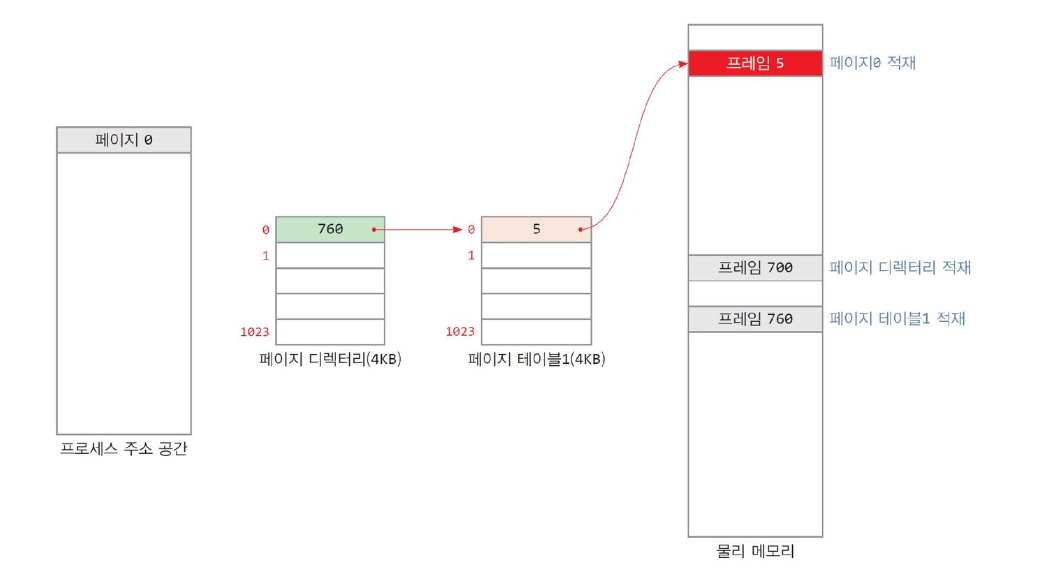
Multi-level page table ( Hierarchical Paging )
-
페이지 테이블을 여러 작은 페이지 테이블들로 나누고 여러 레벨로 구성 ( 계층화 )
- 현재 사용 중인 페이지들에 대해서만 페이지 테이블을 만드는 방식
- 기존 테이블의 낭비를 줄임
two - level 로 멀티레벨 페이지 테이블을 구성하는 경우
- 프로세스의 0 번 페이지 적재 → 페이지 테이블 1 적재, 디렉토리와 연결
- 프로세스에 페이지 1 추가 → 테이블1 에 항목 추가
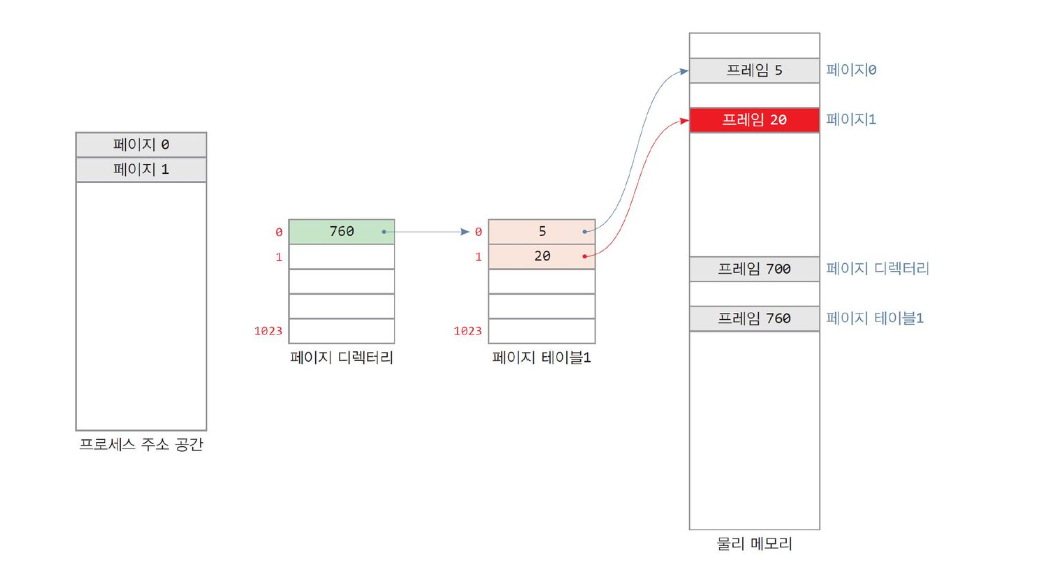
- 프로세스에 페이지 1204 추가 ( 테이블 크기 초과 )
- 페이지 테이블 2 추가 생성
- 디렉토리에 항목 추가
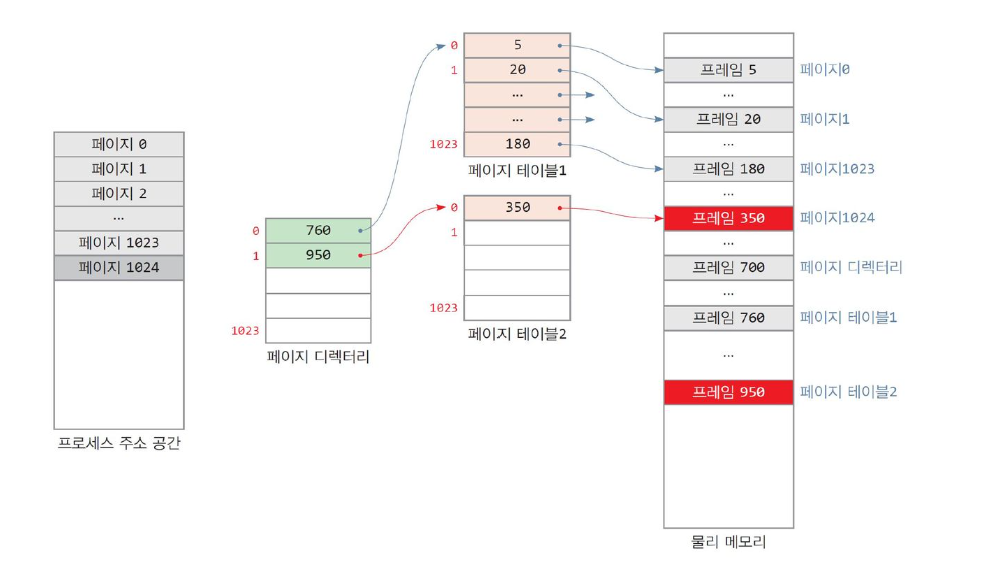
위의 예제처럼 계층화를 통해 페이지 테이블로 인한 메모리 소모를 확연히 줄일 수 있습니다.
