이 글은 널널한 개발자 TV 님의 강의영상을 보고 작성한 글입니다.
1. 초창기 웹 서비스 구조
문서를 다루는 프로그램인 경우,
프로그램을 개발할 때 세 가지 요소가 있는데,
1. 자료구조(문서)
2. UI
3. 제어 체계
이렇게 나누는 것은 "유지 보수 편의성" 때문에 나눈다.
HTTP는 1.0, 1.1, 2.0, 현재 3.0 까지 나왔다.
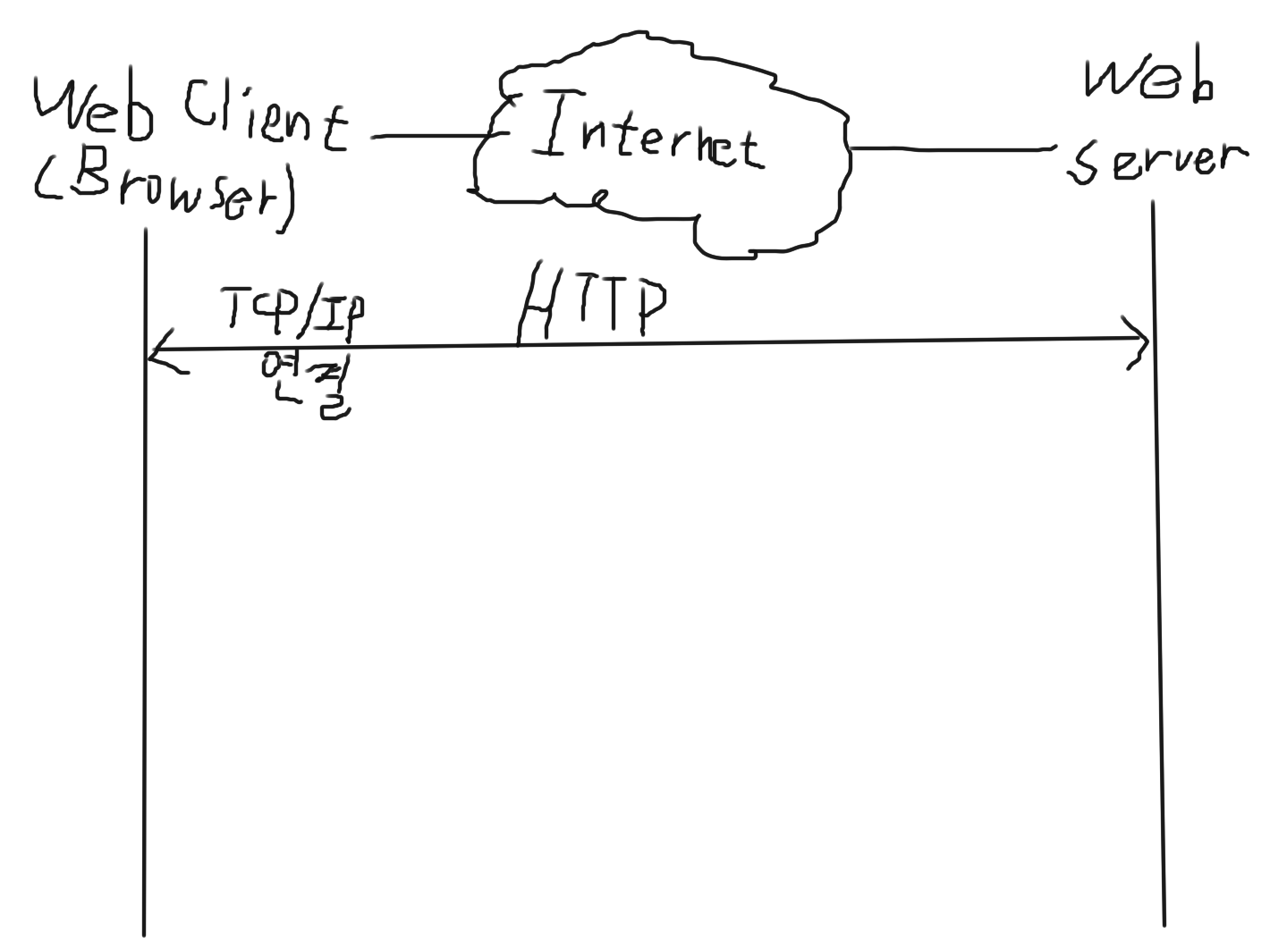
초기 웹 서비스 같은 경우 (HTTP 1.1)
웹을 이루는 구성요소는
웹의 "클라이언트"(브라우저)'
웹의 "서버"
이렇게 존재한다.
처음 웹 설계를 할 때,
전제가 http는 TCP/IP 통신을 전제로 했다.
TCP/IP 연결이 되어 있다고 이 전제를 깔고 간다.
HTTP 통신 프로토콜의 특징 중 하나가 "State less" 이다.
TCP/IP 연결은, 이 "연결"에 따라 오는 개념이 "상태"이다.
위에서 언급한 것 처럼, HTTP 통신 프로토콜은 "State less" 이므로 상태가 없다.
이 상태가 없는 것은, 뭔가 문제를 일으킬 수 있다고 한다.
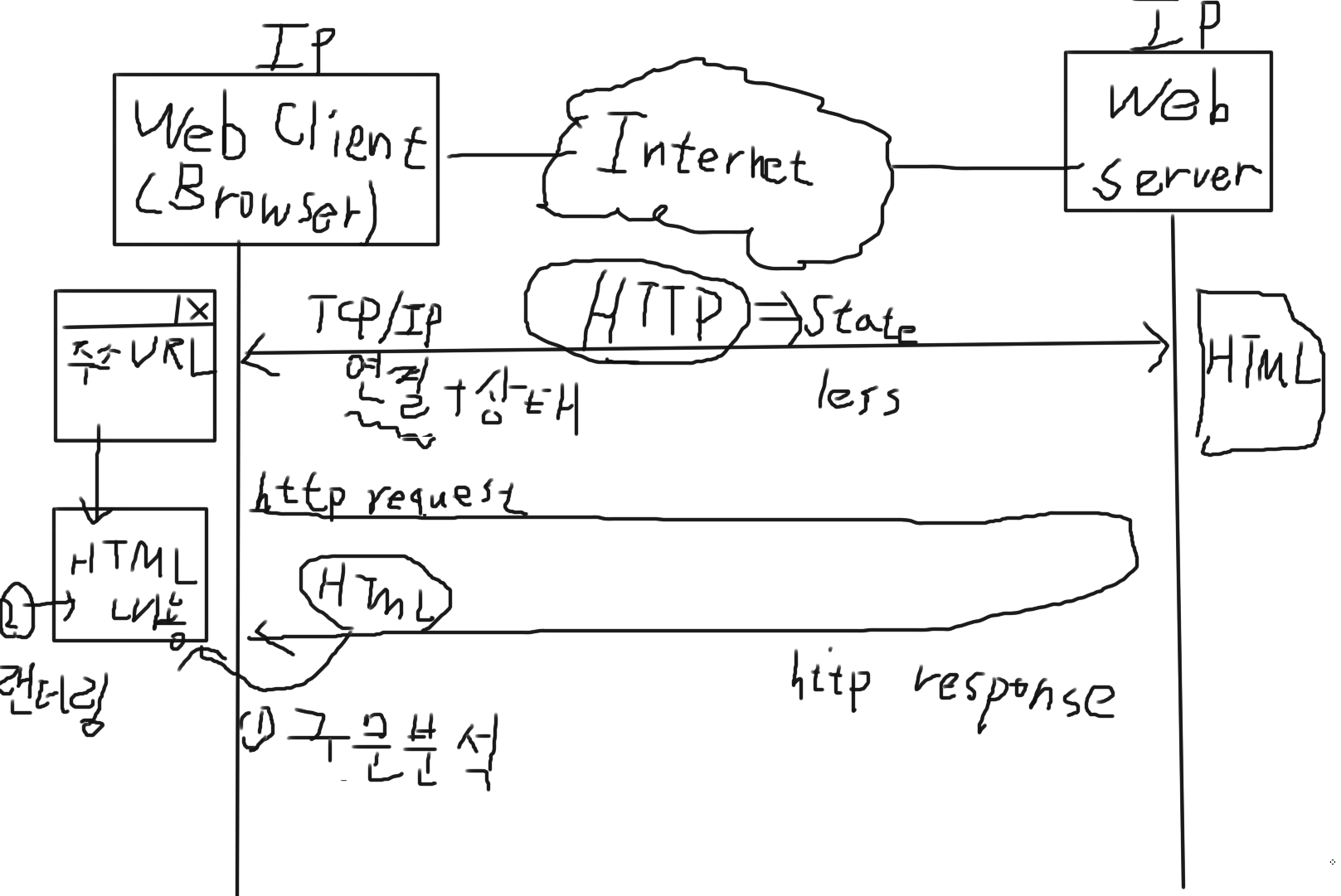
Web Server에 HTML 문서가 있다고 가정하고
브라우저(Web Client)에 프로그램이 있다고 하면, 주소가 있다.
그 주소가 URL인데, Uniform "Resource" Location.
Web Server에 있는 HTML 문서를 Resource 라고 본다.
Web Client, Server들은 각각의 고유 IP 주소가 있을 것이다.
이 IP 주소 들을 알고, TCP/IP 연결을 한 다음에, HTML 문서 리소스를 연결을 한다.
이때부터 HTTP 프로토콜이 작동을 시작한다.
HTTP 프로토콜이 작동을 하면, http request 를 하고 http response를 한다.
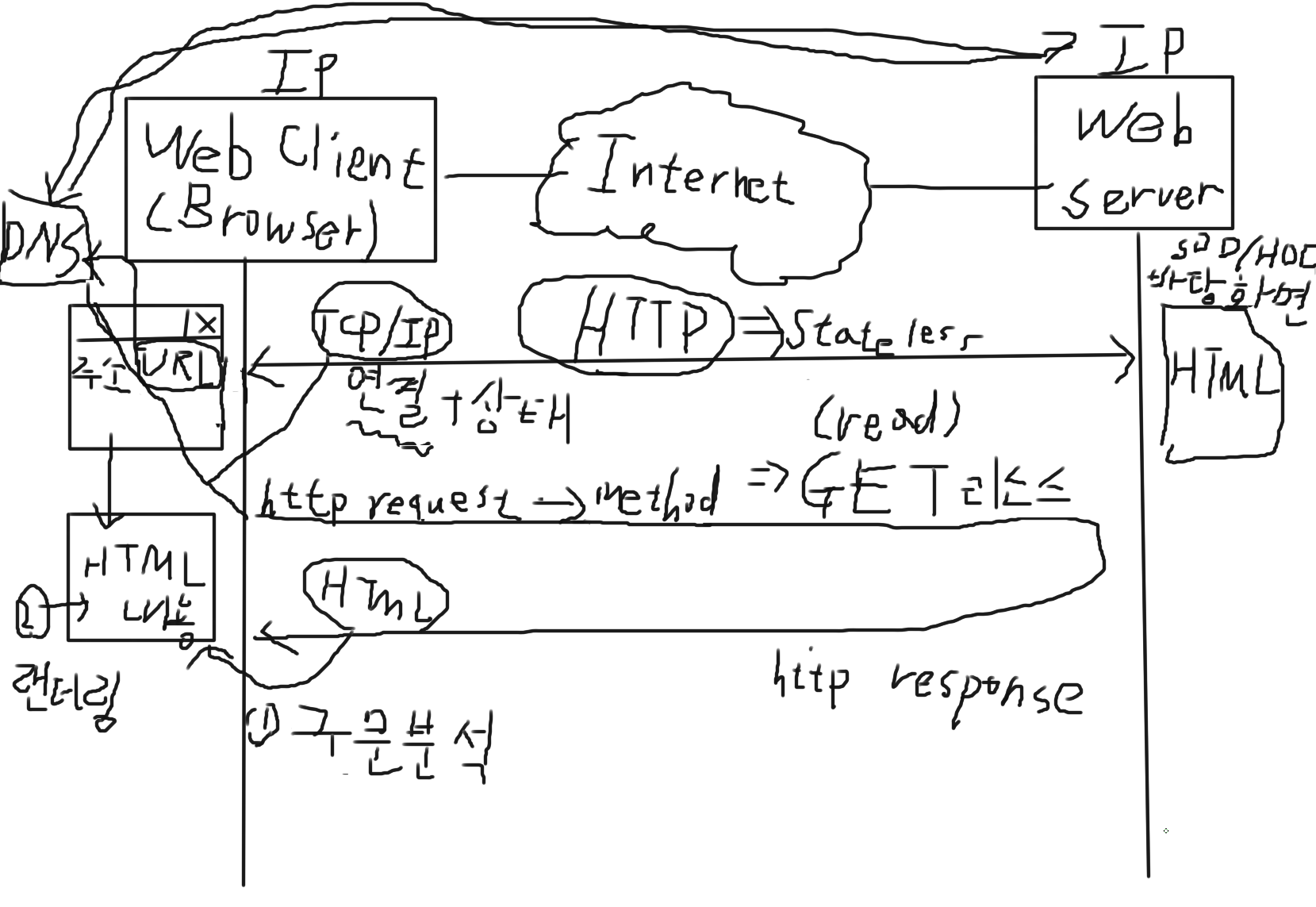
자자 정리하면
1. 크롬이나 파이어폭스 이런 브라우저에서
2. URL 을 입력을 한다.
3. 그러면 DNS server에서 연결하고자 하는 Web Server의 IP 주소를 클라이언트한테 알려준다.
4. 그 후 서로의 IP 주소가 TCP/IP 연결이 된다.
5. 그 때, HTTP 프로토콜이 작동을 시작하는데,
6. 클라이언트에서는 http request를 하고,
7. 서버에서는 http response를 한다.
8. 근데 그때, 클라이언트에서는 http request를 할 때, 여러 방법이 있는데,
9. 그 중 하나가, GET 리소스이다.
10. Web Server에 있는 HTML 문서(리소스)를 GET 하는데,
11. 그대로 가져오는 것이 아닌 read를 해서 가져온다.
12. 이 때, Web Server의 HTML 문서는 뭐, HDD, SDD, 바탕화면 등 어떤 경로에 있겠다.
13. 그거를 읽어들여와서 Web Server는 http response를 한다.
이렇게 이해함
14. 그래서 서버에서 보낸 HTML을 클라이언트는 받고, 구문 분석(영어로 파싱)을 한다.
15. 구문 분석(파싱)을 할 때, 파서라고 프로그램 구성요소가 한다.
16. 분석된 결과를 가지고, 자료구조를 생성을 한다.
17. 이 자료구조는 비선형 트리 구조로 되어있다.
18. 이렇게 분석 끝났고, 자료구조 생성까지 했으면,
19. 랜더링을 한다. 즉, 화면에 보여준다.
중요한 것은 꺾이지 않는 마음
이 아니라,
구문분석을 할 때의 파서와
랜더링을 할 때의 엔진이 중요하다.
여기까지가 초기의 웹 이였다.
Reference
https://www.youtube.com/@nullnull_not_eq_null (널널한 개발자님 URL)
https://www.youtube.com/watch?v=4Sfned8HLzk&list=PLXvgR_grOs1BFH-TuqFsfHqbh-gpMbFoy&index=10 (강의 영상)

보안 공부를 하는 학생입니다.