★ [학습목표]
공공데이터를 import 할때 요령을 반복학습한다.
1. 자료 Pre-processing (엑셀에서 데이터의 형태를 1차 Review)
1) Header는 한 줄로 병합한다.
※ Excel의 left(), concat() 함수를 활용하여 Header 변형 방법
- 원본 데이터 (각셀의 정보가 아래와 같을때 ...)
A1: "Apple"
A2: "Banana"
A3: "Cherry"
- 특정 문자 추출 및 병합
B1: =LEFT(A1, 2) // A1 셀에서 처음 두 문자 ("Ap") 추출
B2: =LEFT(A2, 2) // A2 셀에서 처음 두 문자 ("Ba") 추출
B3: =LEFT(A3, 2) // A3 셀에서 처음 두 문자 ("Ch") 추출
C1: =CONCAT(B1, B2, B3) // B1, B2, B3 셀의 결과 병합 ("ApBaCh")
수식이 포함된 엑셀 수식은 값 붙여넣기로 수식 적용을 없애서 전처리를 마무리한다.
※ 원본데이터는 수정/변경을 하지않기에, 복사본은 다른 Sheet에 저장하여 불러 쓴다.
-
변경전
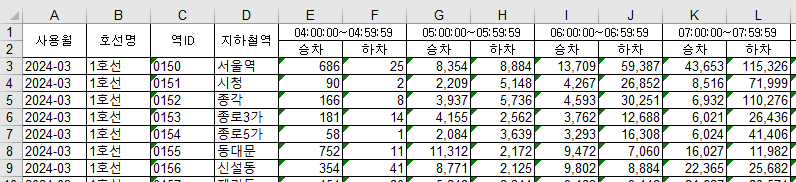
-
변경후 (Header는 데이터 분석을 위해 1줄로 변경)
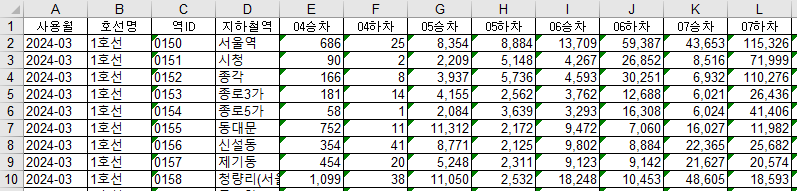
2) name.csv 로 저장한다.
2. 엑셀 -> CSV 저장한다.
- 저장할 때는 "쉽표로 분히.csv" 지정
- 한글 포함여부에 따라 "CP949"로 file을 encoding 하는 것을 추천
data <- read.csv("subway_time.csv", fileEncoding = "CP949")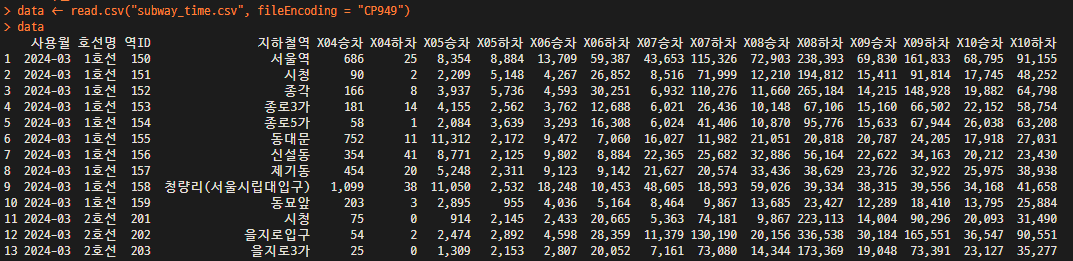
3. 엑셀 내용 중 일부 지정 구간을 클립보드 읽기
- 방대한 데이터의 일부를 읽어와서 확인할 때 유용한 기능
df <- read.csv('clipboard', header = TRUE, sep = '\t') #header를 포함할 경우 TRUE
head(df)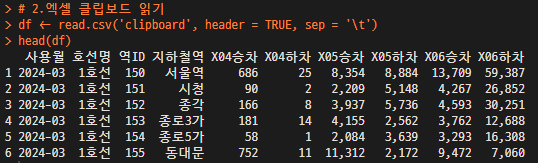
4.엑셀 파일을 읽어올 수도 있음.(기본은 CP9494)
library(readxl)
df1 <- read_excel("2024년 03월 교통카드 통계자료.xls",sheet = "지하철 유무임별 이용현황")
df2 <- read_excel("2024년 03월 교통카드 통계자료.xls",sheet = "지하철 시간대별 이용현황")
head(df1)
head(df2)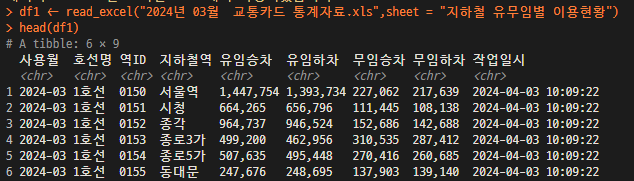
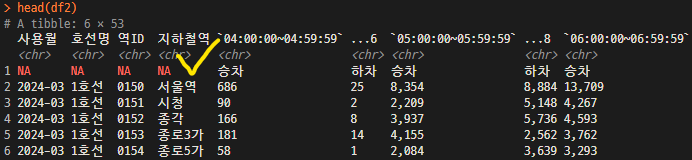
※ sheet"지하철 시간대별 이용현황"의 NA는 header가 2줄이라서 생긴 문제임.
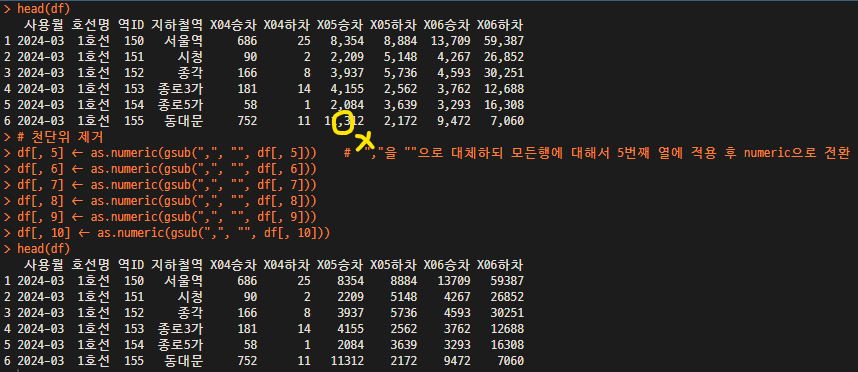
5. 숫자 형식에 포함된 ","를 제거
str(df)
# 천단위 제거
df[, 5] <- as.numeric(gsub(",", "", df[, 5]))
# ","을 ""으로 대체하되 모든행에 대해서 5번째 열에 적용 후 numeric으로 전환
df[, 6] <- as.numeric(gsub(",", "", df[, 6]))
df[, 7] <- as.numeric(gsub(",", "", df[, 7]))
df[, 8] <- as.numeric(gsub(",", "", df[, 8]))
df[, 9] <- as.numeric(gsub(",", "", df[, 9]))
df[, 10] <- as.numeric(gsub(",", "", df[, 10]))
head(df)
- gsub(pattern, replacement, x) 문법
text <- "abc-def-ghi"
result <- gsub("-", "", text)
print(result)
- 같은 형식으로 for문으로 적용도 가능
for(i in c(5,6,7,8,9,10)){
df[, i] <- as.numeric(gsub(",", "", df[, i]))
}- 같은 형식으로 for문 2번째 형식으로 적용도 가능
for(i in 5:10){
df[, i] <- as.numeric(gsub(",", "", df[, i]))
}6. 정리된 데이터를 갖고, 데이터 필터링 개시 (본격 데이터 분석)
-
무임 승/하차 : 만 65세 이상
-
유무임 승차 비율 : 소수점 처리
-
유임 승차 비율 높은 역
-
무임 승차 비율 높은 역
-
유임 하차 비율 높은 역
-
무임 하차 비율 높은 역
-
출근 시간대(7시~9시) 승/하차 인원 최대역
-
퇴근 시간대(18시~20시) 승/하차 인원 최대역
-
심야 시간대(23시~1시) 승/하차 인원 최대역
-
특정역 최대 승/하차 시간대
- 최대값 위치 : which.max(df[행,])
- 최대값 컬럼명 : names(which.max(df[행,]))
- 최대값 인덱스 : as.vector(which.max(df[행,]))
- 최대값 : df[행,which.max(df[행,])]
다음 게시글로...
