
지그재그 세미나 4회
주제: 쉽게 이해하는 온톨로지 기술 실무 (그래프 모델의 선택과 온톨로지 구축 전략)
일시: 2026년 3월 11일 (수) 오후 7시
장소: GS타워 25층 (역삼역 인근) 오픈이노베이션 오픈홀
먼저, 우리는 왜 온톨로지를 구축하려고 하는것인가?
우리는 현재 저장의 시대에서 탐색, 연결, 해석, 재사용의 시대로 데이터의 주요 소비자와 환경이 변화하였다.
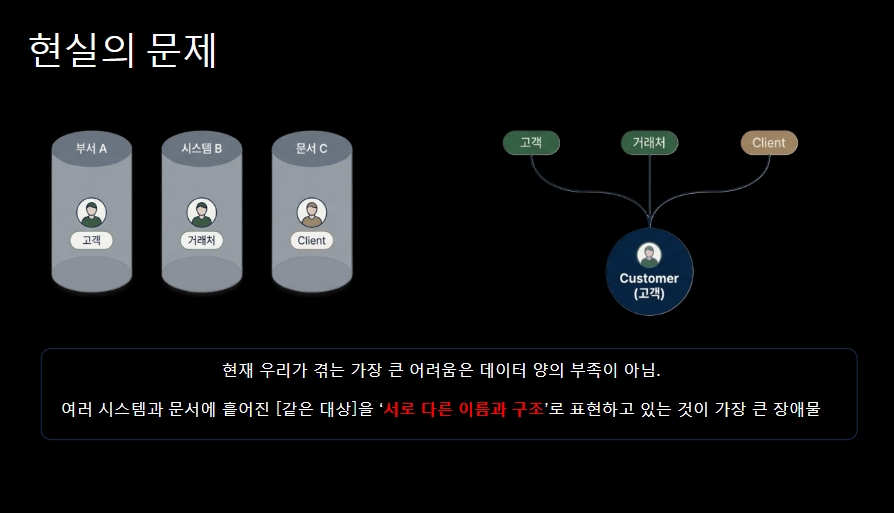
> 현재 우리가 겪는 가장 큰 어려움은 "
데이터 양의 부족"이 아니라 여러 시스템과 문서에 흩어진 "같은 대상"을 "서로 다른 이름과 구조"로 표현하고 있는 것이 가장 큰 장애물 이라는 의미이다.
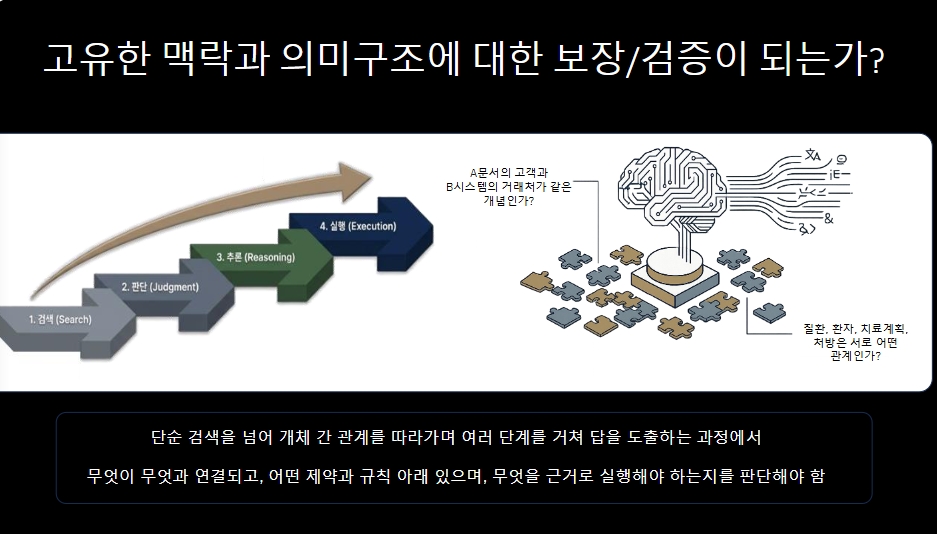
고유한 맥락과 의미구조에 대한 보장/ 검증이 되는가?
따라서 우리는 단순 검색을 넘어 개체 간 관계를 따라가며 여러 단계를거쳐 답을 도출하는 과정에서 무엇이 무엇과 연결되고, 어떤 제약과 규칙 아래에 있으며, 무엇을 근거로 실행해야 하는지를 판단해야 한다.
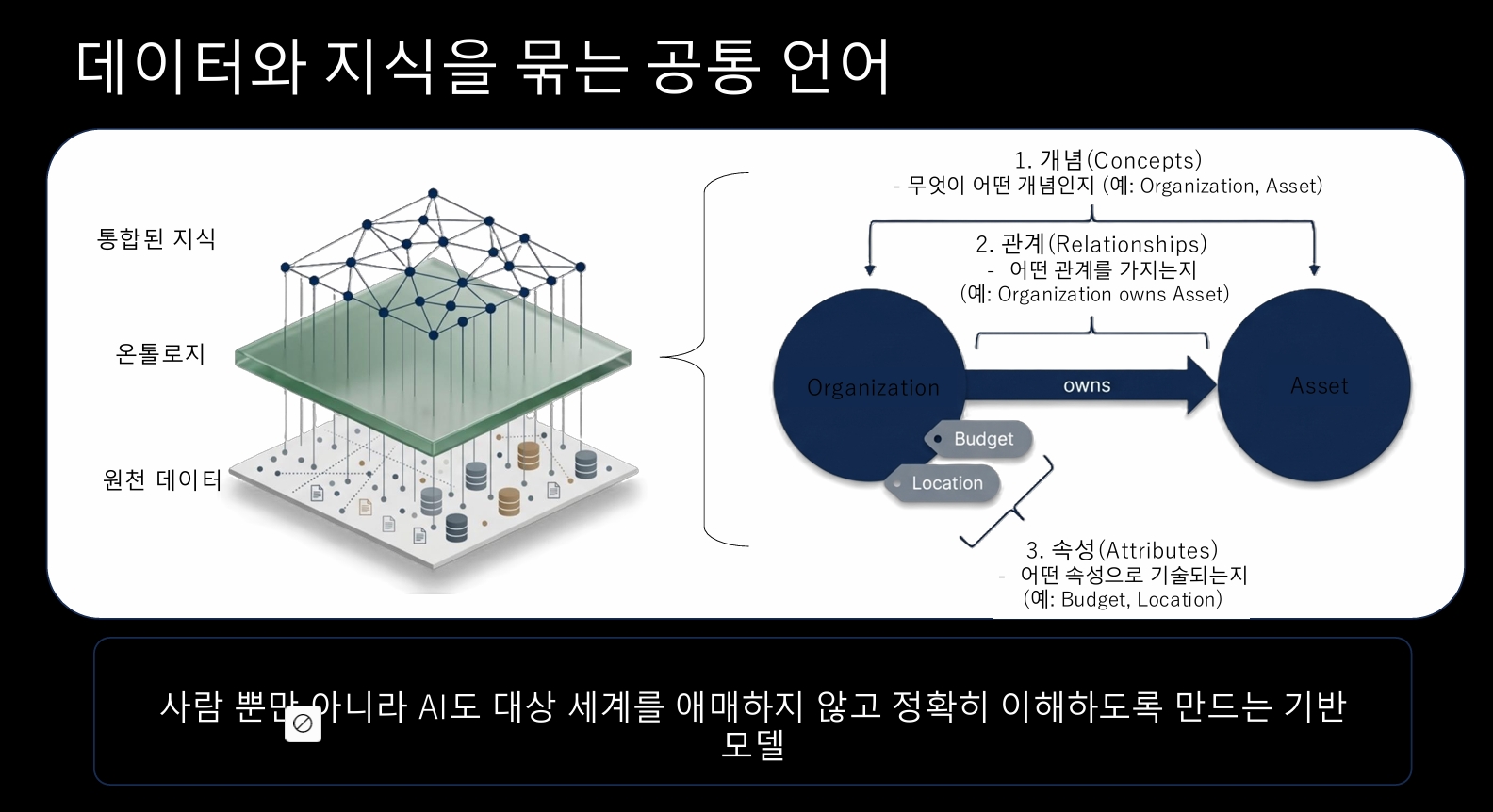
즉, 우리는 데이터와 지식을 묶는 공통의 언어가 필요하다.
--> 온톨로지 구축은 있으면 좋은 지식표현 기술, 단순 RDF/OWL 문서를 AI, 데이터, 통합, 자동화를 동시에 성립시키는 기반이 되며, 사람과 AI가 대상 세계를 온전하게 이해하게 만드는 확실한 방법이다.

1. 시멘틱 웹과 온톨로지
- RDF/RDFS/OWL, 지식그래프, Property Graph
Semantic Web의 개념
"의미를 이해하는 웹"
웹이 인간의 두뇌를 닮기 위해서는 정보를 단지 축적하거나 연결하는 것만이 아닌, 그 의미까지 이해하고 기계가 처리할 수 있어야 한다.
Tim Berners-Lee : WWW의 창시자로서, 인터넷 상의 하이퍼미디어를 넘어 데이터의 의미까지 기계가 이해하고 처리할 수 있는 형태로 확장한 '시멘틱 웹' 개념과 아키택처를 제안함
-
기존 웹 (Web of Documents)
문서(Web page) 중심의 분산 네트워크, URL(Uniform Resource Locator)를 사용해 문서의 '위치'를 참조하고 하이퍼링크로 연결
-
시멘틱 웹 (Web of Data)
데이터(Data) 차원의 분산 네트워크, URI (Uniform Resource identifier)를 사용해 데이터/엔티티 자체를 전역적으로 식별하고 연결
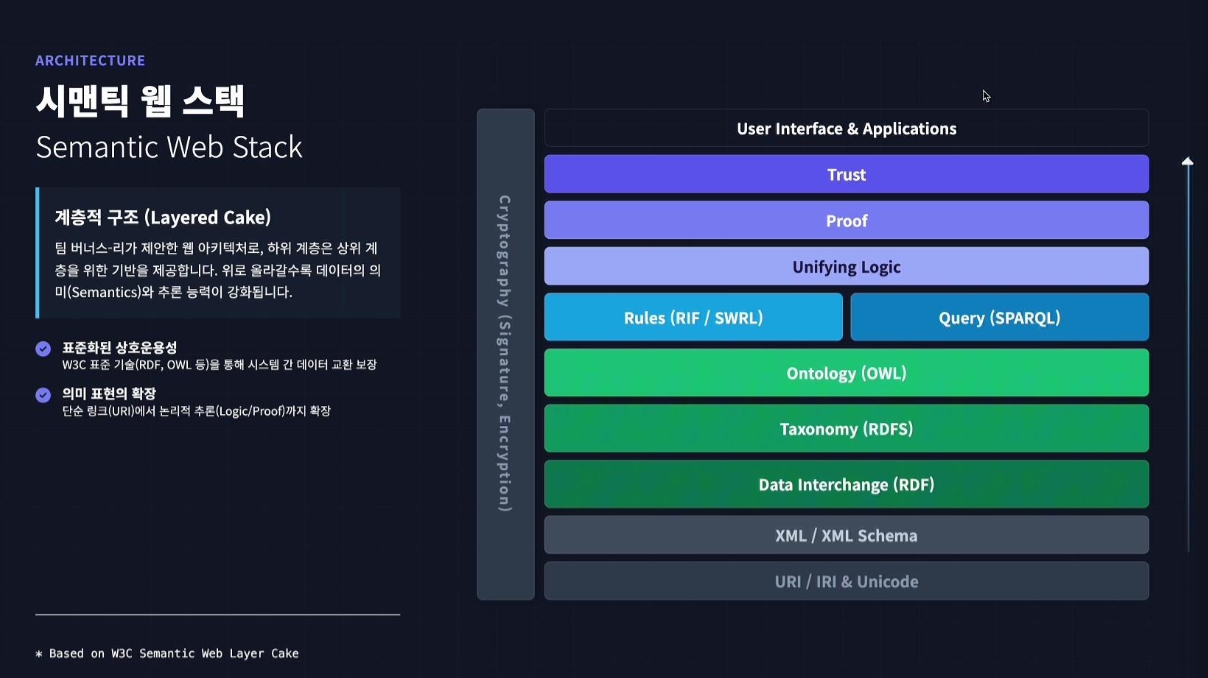
계층적 구조 (Layered Cake)
팀 버너스 리가 제안한 웹 아키텍처로, 하위 계층은 상위 계층을 위한 기반을 제공한다. 위로 올라갈수록 데이터의 의미(Semantics)와 추론 능력이 강화된다.
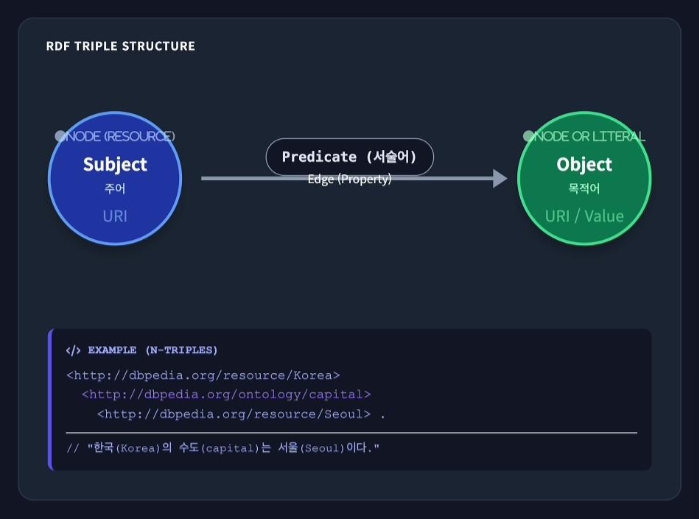
RDF (Resource Description Framework)
- 웹 자원 기술의 표준, 웹상에 존재하는 자원의 속성과 관계를 기술하기 위한 W3C 표준 데이터 모델
- 트리플 (Triple) 구조: 모든 정보는 주어 (Subject) - 서술어 (Predicate) - 목적어 (Object)의 3요소 (Triple) 형태로 표현됨
- 기계 해석 가능성: 그래프 구조로 연결된 데이터는 기계가 그 의미와 맥락을 파악하고 자동으로 처리/추론 할 수 있게함
RDF의 주요 구성 요소: 자원의 식별(Identifier), 값의 표현(Literal), 데이터셋 관리(Graphs)
식별자 (Identifiers)
-
URI (Uniform Resource Identifier)
웹상의 자원을 고유하게 식별하는 전역 식별자, UR의 개념을 확장하여, 문서 뿐만이 아니라 개념, 사물 등 모든 엔티티를 유일하게 지칭함, 다른 시스템에서도 동일한 대상을 식별/재사용 가능 -
Compact URI (CURIE)
긴 URI를 효율적으로 표현하기 위해 Name Space(접두어)를 사용하여 축약한 형태
값과 그래프 (Values & Structure)
-
Literal (리터럴)
자원의 속성 값(문자열, 숫자, 날짜 등)을 표현, 오직 Object(목적어) 위치에만 등장 가능 -
Multiple Graphs
여러개의 RDF 그래프를 하나의 데이터셋으로 관리, 출처(Provenance), 접근제어, 메타데이터 관리를 위해 사용 ex) Default graph: 이름 없는 기본 그래프, Named graph: IRI로 식별되는 그래프 (Quad 구조)
RDF 표현
기계와 사람이 읽을 수 있는 다양한 표현 방식
Turtle (Terse RDF Triple language): 가장널리 사용되는 인간 친화적 포맷, 중복을 줄이고 가독성을 높인 문법
N-Triples: 가장 단순한 형태, 한줄에 하나의 트리플을 온전한 URI로 표현, 파싱이 매우 빠름
JSON-LD: JSON 기반의 Linked Data 포맷, 웹 개발자에게 친숙하면 API 응답용으로 주로 사용
RDF/XML: 초기 표준 형식, XML의 복잡성으로 인해 현재는 가독성이 좋은 Trutle 등을 선호
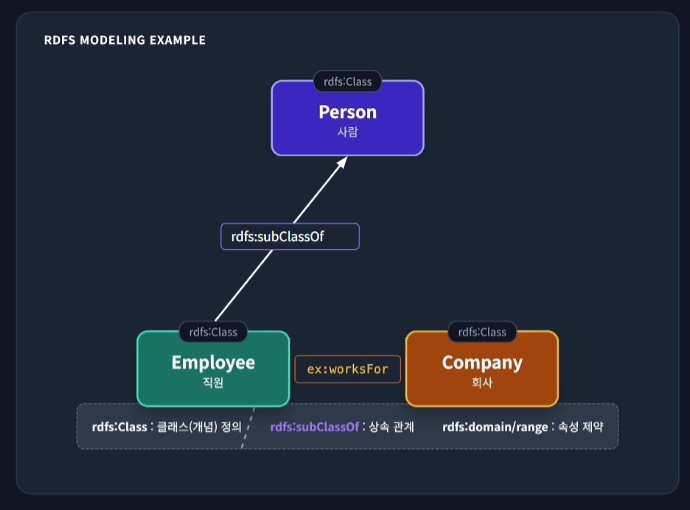
RDFS (RDF Schema)
어휘의 의미와 상하위 관계를 정의하는 시맨틱 웹의 분류체계
-
어휘 및 의미정의
단순 데이터 연결을 넘어, Class(개념)와 Property(속성)를 정의하여 데이터가 어떤 의미를 갖는지 기계에게 설명하는 사전역할을 함 -
분류 체계 (Taxonomy)
subClassOf(하위 클래스)와 subPropertyOf(하위 속성)를 사용하여 개념 간의 계층 구조와 상속 관계를 형성 -
관계의 제약 조건
속성이 연결돌 수 있는 주어의 타입(Domain)과 목적어의 타입(Range)를 지정하여 논리적 무결성을 보장하고 추론의 근거를 제공
- RDFS 추론 메커니즘
스키마 정보 (Domain, Range, SubClass)를 기반으로 새로운 사실을 도출하는 과정
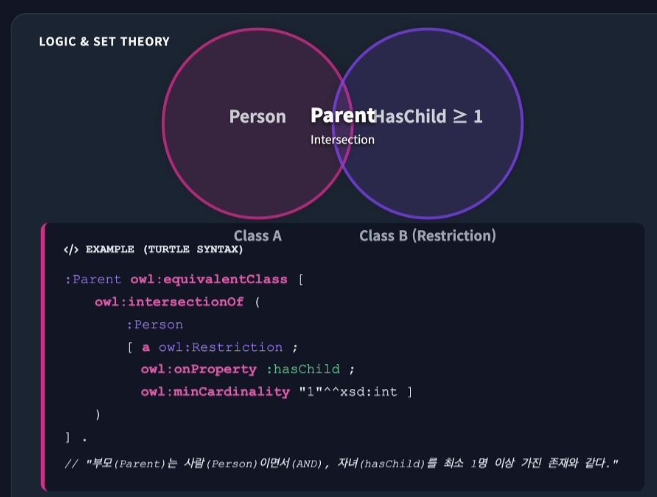
OWL
Web Ontology Language, 지식표현을 위한 상위 논리 모델링 계층
-
Description Logic 기반
RDFS 위에서 동작하며, 서술논리를 기반으로 하여 사물간의 복잡하고 풍부한 관계를 명확하게 정의하고 추론(Resoning)할 수 있는 언어 -
향상된 표현력
단순 계층 구조를 넘어 집합 연산(교집합, 합집합), 카디널리티(개수 제한), 속성 특성(대칭, 전이, 역관계) 등 정교한 제약조건을 표현할 수 있음 -
OWL 버전과 Profile
2004년 OWL에 이어 2009년 OWL2가 발표되었으며, 사용 목적과 연산 복잡도에 따라 EL, QL, RL 등 다양한 profile을 제공함
What is Ontology?
지식 표현을 위한 인공물로서의 온톨로지 개념
"An ontology is an explicit and formal specification of a shared conceptualization of a domain of interest" - Tom Gruber (1993)
- 철학(존재론): '존재의 본질'을 탐구하며 세상에 무엇이 존재하는가를 다룸
- 정보기술(IT): 특정 도메인의 지식 공유와 재사용을 위한 '설계된 인공물(Artifact)'
- 철학적 뿌리를 가지지만, IT에서는 기계가 처리가 가능한 명세에 초점
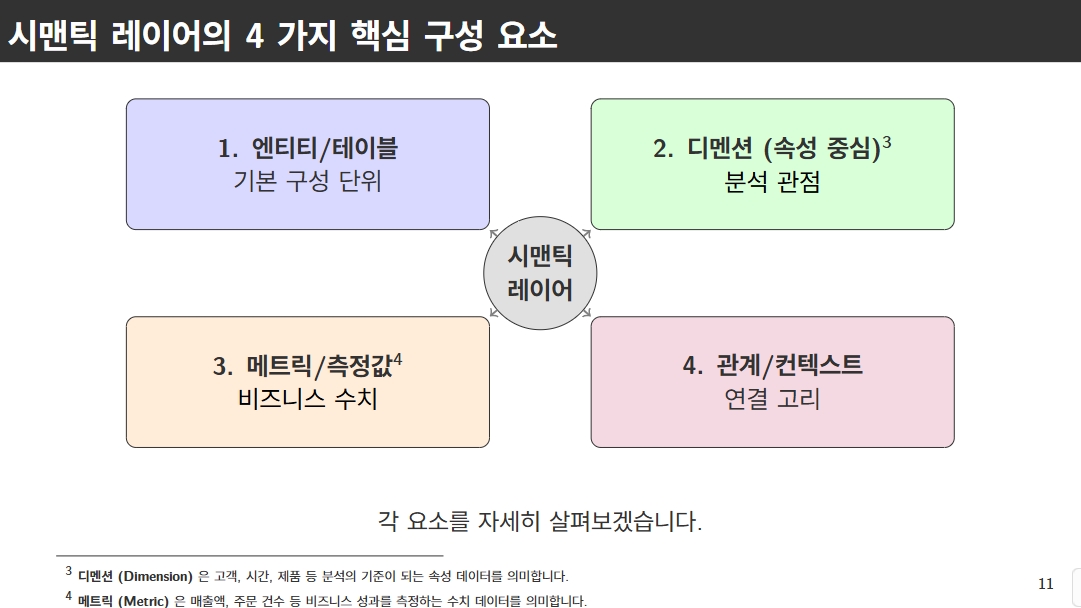
온톨로지의 구성요소
지식 표현을 위한 구성 요소
- 개념 (Concept): 특정 영역의 사물이나 현상에 대한 추상적 분류 (Class)
- 인스턴스: 개념에 속하는 구체적인 개별 실체 (Individual)
- 속성 (Property): 개념이 가지는 특성이나 데이터 값 (Attribute)
- 관계: 개념간의 상호작용 및 연결 구조 (Relation)
- 공리 (Axiom): 증명없이 참으로 간주되는 논리적 규칙
- 제약조건: 속성 값이나 관계에 대한 논리적 제한
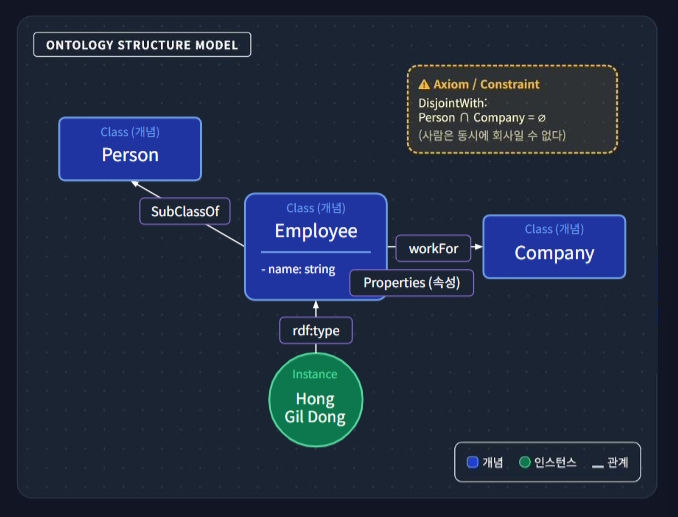
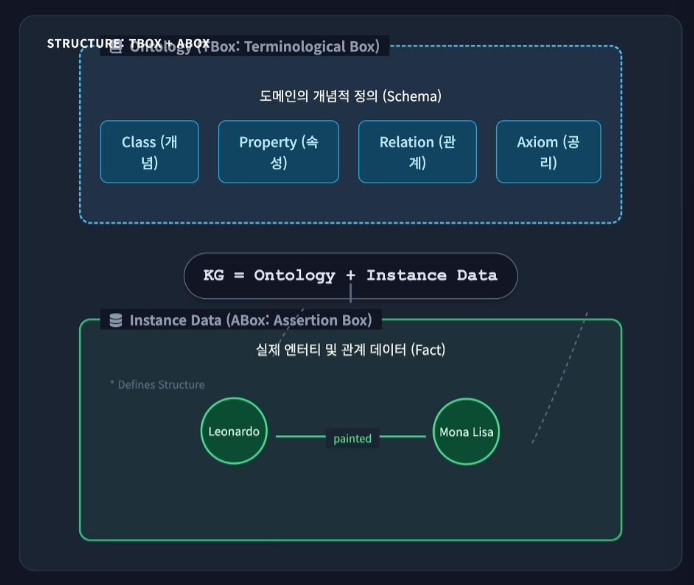
Knowledge Graph
의미모델과 데이터가 결합된 지식표현구조
- 스키마와 데이터의 결합: 단순한 node와 edge의 연결이 아니라, 도메인의 개념적 정의인 스키마(Schema/Ontology)와 그 정의에 기반한 실제 데이터(Instance)가 결합된 결과물
- 의미 기반 추론 가능: 의미(Semantics)의 공유와 일관성을 보장하며, 정의된 관계와 규칙을 바탕으로 새로운 사실을 도출하는 추론(Resoning) 및 탐색이 가능
- 구성의 필수 요소: 지식그래프는 스키마(필수)와 데이터(필수)가 모두 존재해야 하며, 이는 단순한 Graph DB와 구분되는 가장 큰 특징임
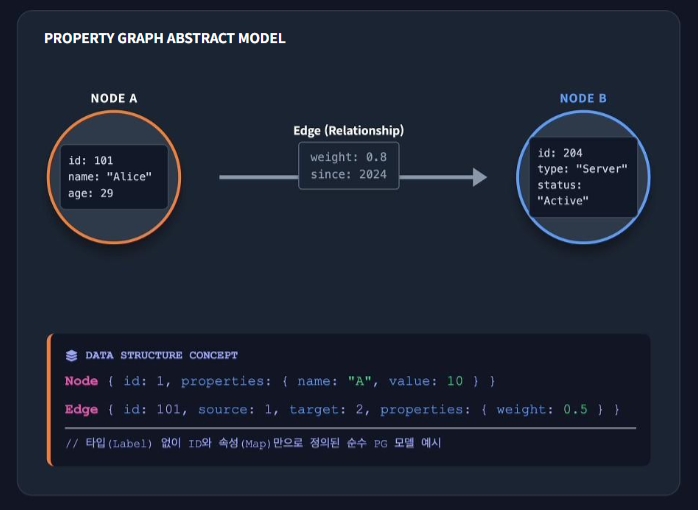
Property Graph (PG)
Node와 Edge 내부에 Key-Value 속성을 저장하는 구조 중심의 모델
- Key-Value 속성 중심: 노드와 엣지 자체가 내부 속성(Property)를 가질 수 있는 구조, 엔티티와 관계에 대한 상세 데이터를 직관적으로 저장하고 그래프 순회에 유리한 모델
- 구조 및 분석 중심: 개념적 타입 (label)은 필수 요소가 아니며, 관계의 의미보다 연결 구조와 데이터 분석에 최적화된 네트워크 모델
- 표준 퀴리 언어의 부재: RDF의 SPARQL과 같은 단일 글로벌 표준이 없으며 주로 Gremlin 쿼리 언어를 사용하여 데이터를 조회함
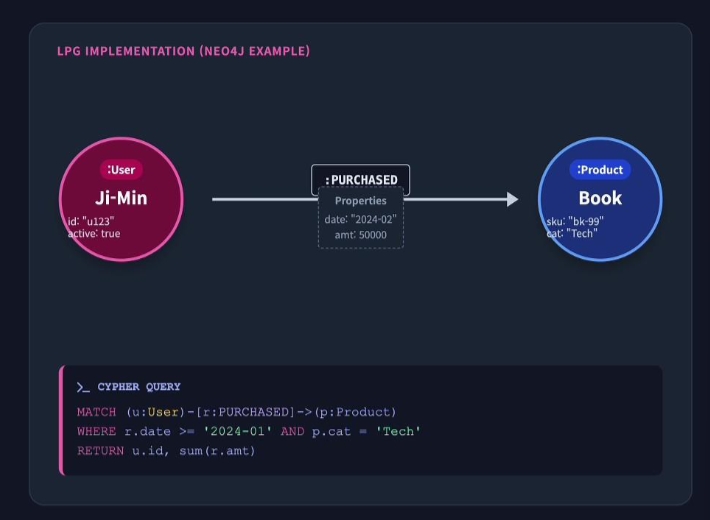
Labeled Property Graph (LPG)
Property Graph에 명시적 Label이 추가된 모델
- PG 구현 모델 (Implementation): 추상적인 Property Graph 개념을 실제 시스템에서 사용할 수 있도록 구체화한 모델, Neo4j, TigerGraph, Azure, Cosos DB등 대부분의 상용 그래프 DB가 채택하고 있으며, 실무에서 가장 많이 사용됨
- 명시적 타입 시스템: PG와 달리, Node Label (개념 타입)과 Edge Type (관계유형)이 구조 수준에서 명시적으로 필수화되어 있음. 이를 통해 효율적인 인덱싱과 탐색이 가능
- 퀴리 언어 지원: Cypher, GQL, GSQL 등 종속성이 강한 쿼리 언어가 사용됨, 비록 공식 글로벌 표준은 아니지만, 실무에서 널리 쓰이는 사실상의 표준 (De facto) 역할을 함
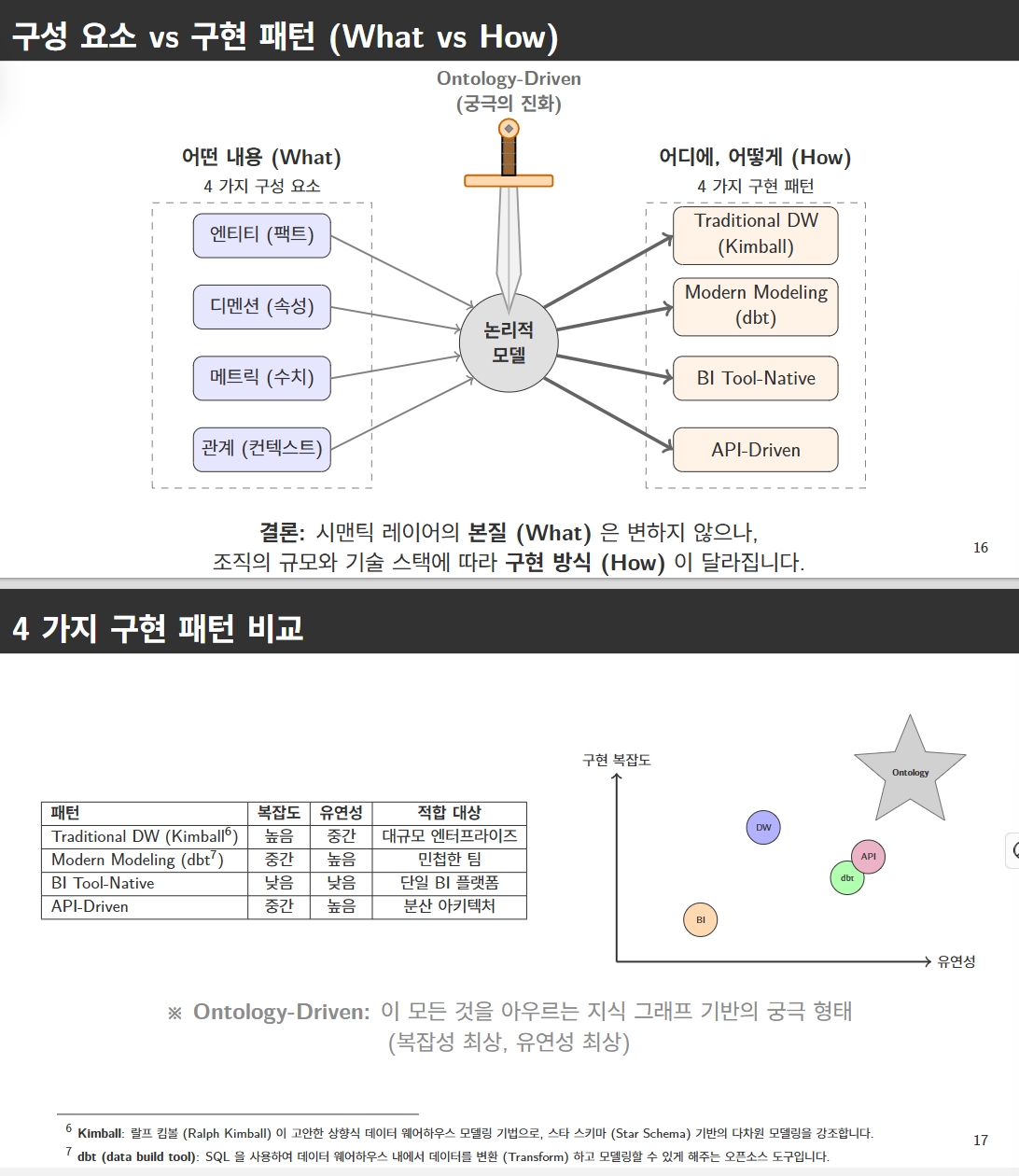
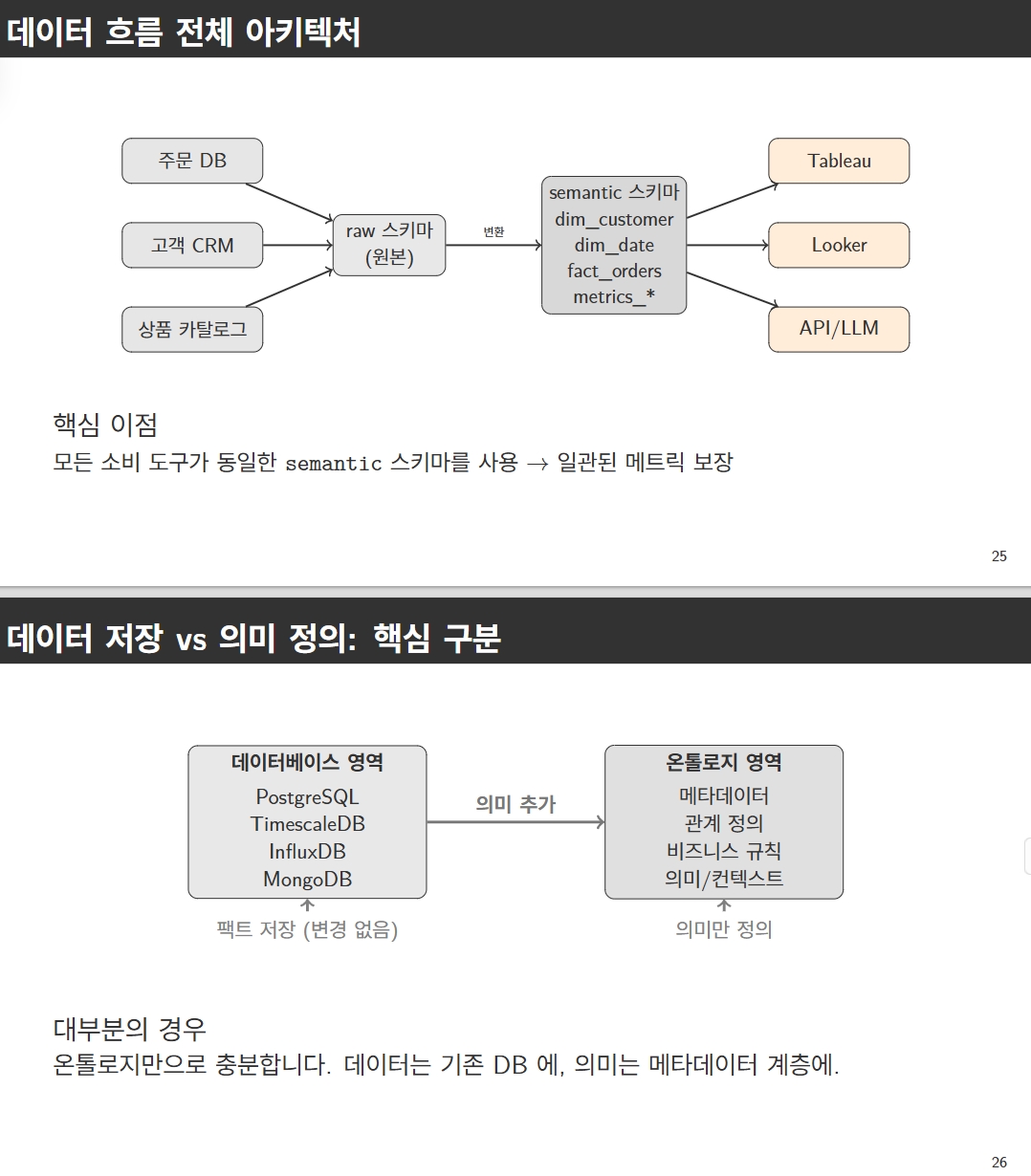
RDF vs PG vs LPQ 비교분석

2. Semantic Layer
Data governance의 문제점
- 분산된 메트릭 정의: 팀별로 다른 "매출"의 정의, 불일치하는 계산로직
- 비효율적인 업무 반복: 매번 동일한 지표 추출을 위해 쿼리 새로 작성, 핵심 업무 (인사이트 도출)보다 데이터 조달에 시간 낭비
영향
- 도구 간 사일로화: BI 도구별 파편화 및 단절, 일관된 정보 소스 없음, 일관된 정보 소스 없음
- 데이터 품질 악화: 데이터 파이프라인 전체로 오류 확산, 일관된 지표 통제 불가
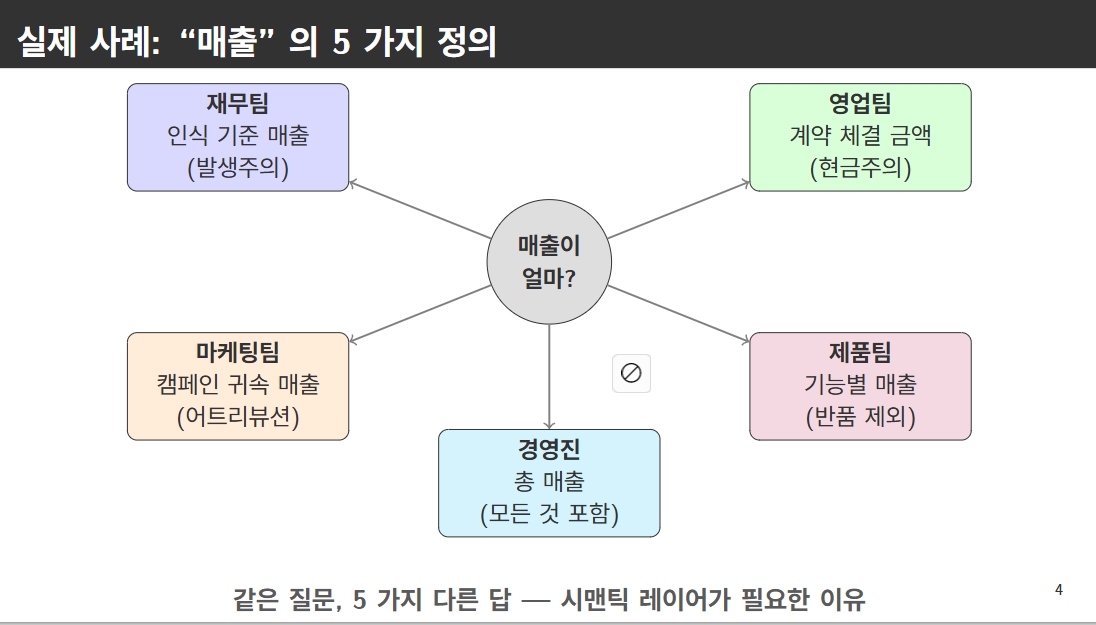
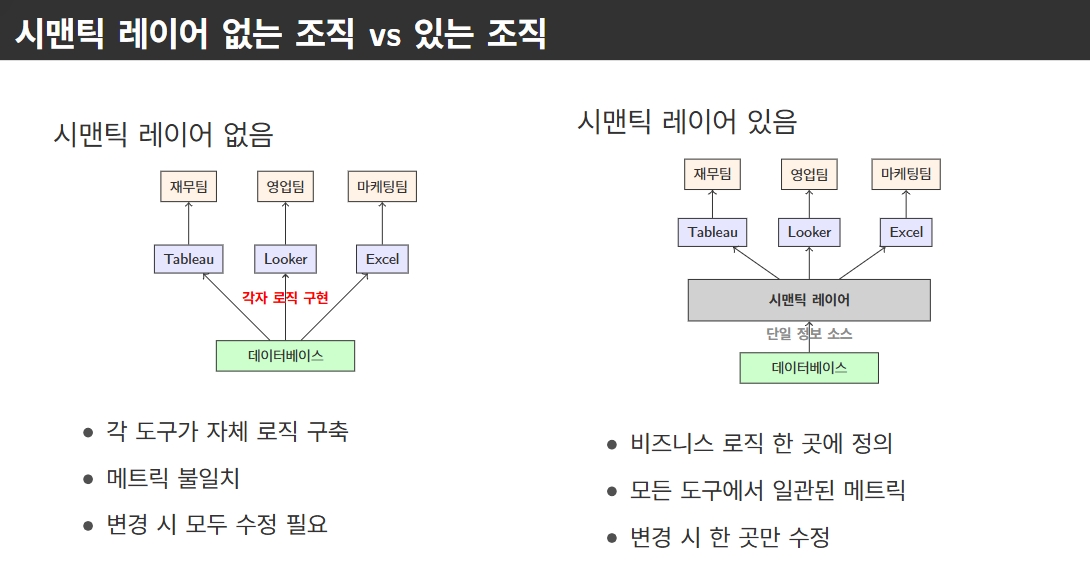
Semantic layer의 정의
기존 팩트 데이터는 그대로 유지하되, 그 위에 온토로지, 메타데이터, 관계 정의를 포함하는 의미 계층을 덧씌우는 것
- 특성
기존 fact data는 변경하지 않고, 위에 의미 계층을 추가 (온톨로지, 메타데이터), 여러 계층으로 구성 가능, 유기적으로 성장 (자동), 인위적으로 관리 (수동)

시맨틱 레이어는 고정된 한 계층이 아니라, 여러 계층의 집합이며 시간에 따라 성장한다.
시맨틱 레이어의 성장방식
1. 유기적 성장 (자동)
- 데이터 패턴 학습
- 고객이 자주 사는 제품 조합 발견
- 자동으로 "상품 번들" 관계 추가
- 비즈니스 규칙의 진화: 초기 매출 = 주문금액, 6개월 후: 매출 = 주문금액 - 반품
2. 인위적 관리 (수동)
- 새로운 팀 온보딩 시 계층 추가: 마케팅 메트릭 계층, 캠페인 메타데이터
- 규제 준수 계층 추가: 개인정보보호 규칙, 감사 (audit) 메타데이터
- 불필요한 계층 제거/통합
아래는 시맨틱레이어의 잘못된 설명이다.
- 시맨틱 레이어는 고정된 한 계층
- 한번 설계하면 끝
- 변하지 않는 구조
- 모든 데이터를 RDF로 변환해야함
올바른 이해는 아래와 같다.
- 시맨틱 레이어는 여러 계층의 집합이다.
- 시간에 따라 성장하고 진화한다.
- 조직의 필요에 따라 유연하게 관리 및 조정한다.
- 필요시 추가/삭제가 가능하다.
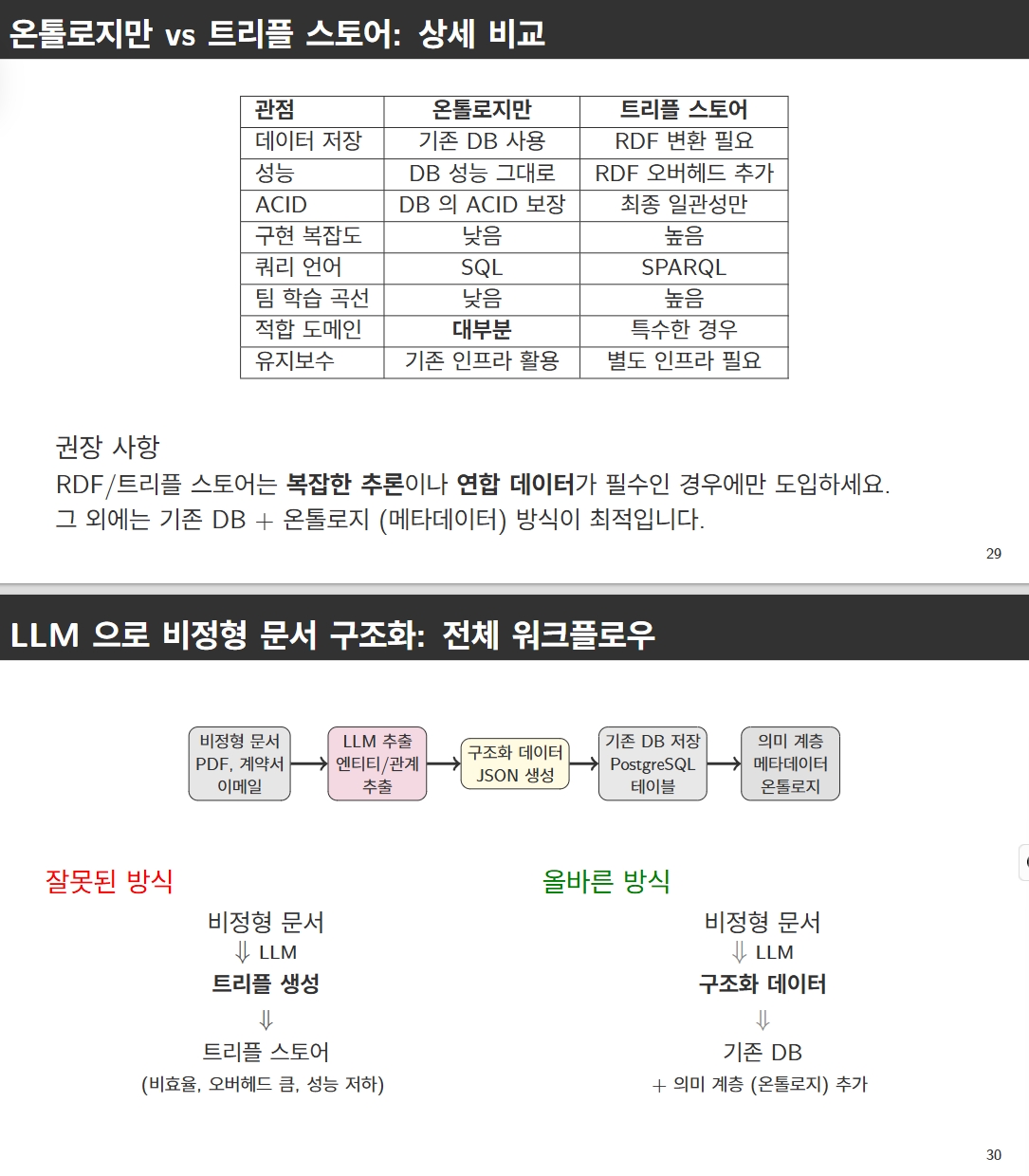
데이터 마트는 물리적 데이터 복사본이지만, 시맨틱 레이어는 추상화 계층이다. 데이터를 복제하지 않고 의미만 정의한다.
RDF가 필요한 경우 vs 불필요한 경우
RDF가 적합 (특수한 경우)
- 복잡한 의미 추론: OWL 온톨로지 자동 추론, 복잡한 관계 쿼리
- 극도로 불규칙한 스키마: 각 엔티티가 다른 속성, RDF의 유연성 필요
- 연합 데이터: 여러 조직 간 데이터 공유, 표준 온톨로지 기반 통합
RDF 피해야 할 경우
- 고주파 시계열 데이터: 0.1초 센서 데이터, 1 데이터 = 3 트리플 (오버헤드)
- ACID 필수 금융거래: RDF는 최종 일관성만 보장, 프랜잭션 무결성 불가
- 밀리초 응답 시스템: 주문 처리, 실시간 API, RDF 쿼리 지연 높음
Semantic Layer 핵심 요약
- 기존 DB는 그대로, 위에 의미계층 추가
- 시맨틱 레이어는 성장하고 진화하는 구조
- 대부분의 경우 RDF/트리플 스토어 불필요
- LLM으로 비정형 문서 구조화 가능

Acknowledgement
본 포스팅은 지그재그 세미나 4회에서 제공된 pdf 발표자료를 기반으로 작성되었다. 원본 자료와 발표자 정보가 궁금하다면, 아래 Reference에 지그재그 hompage 링크를 올려두었으니 참고하길 바란다. 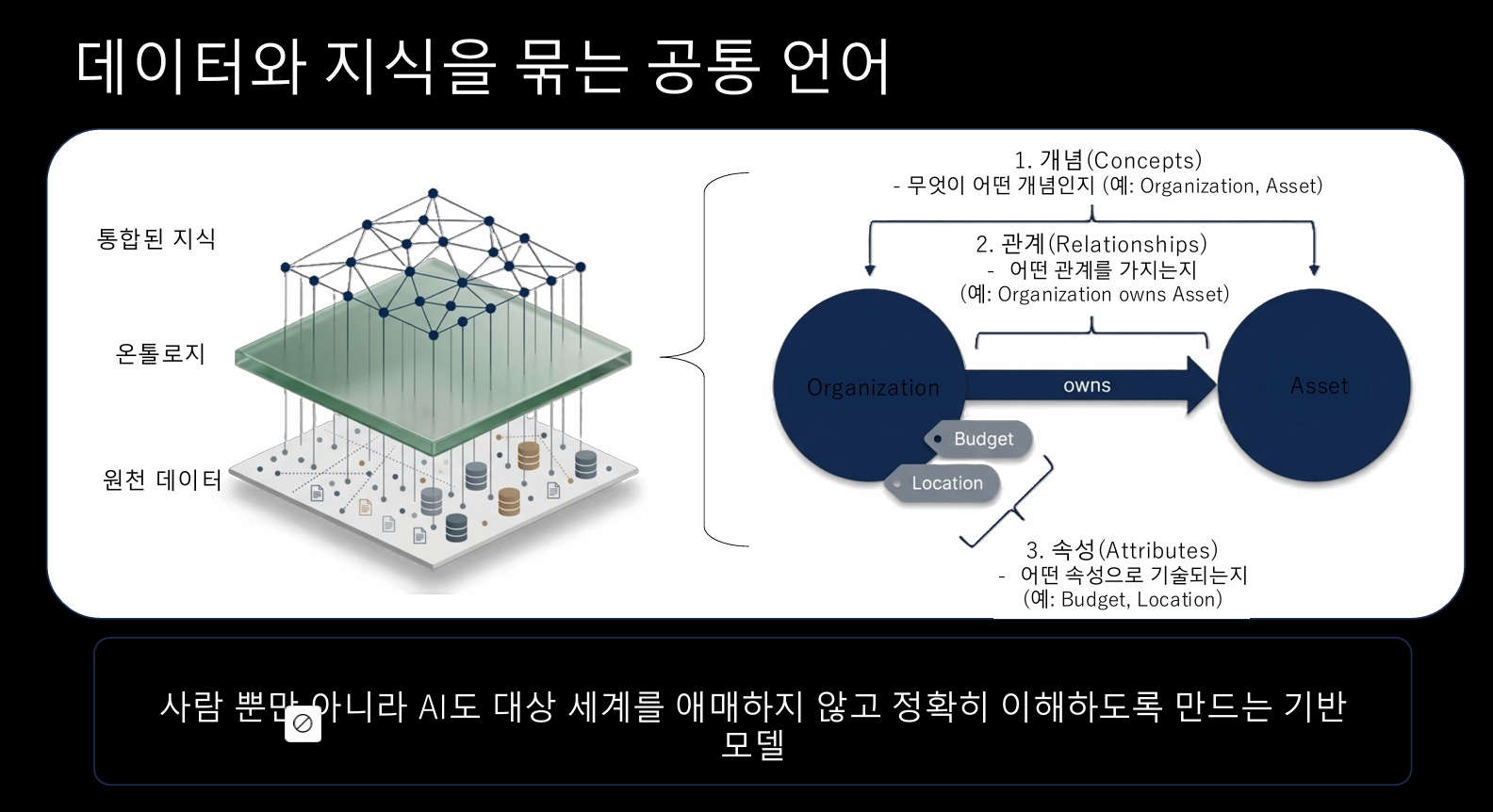
Reference
https://slashpage.com/zigzag/4w67rj24gqx4jm5yq8ep
https://joyhong.tistory.com
https://github.com/LangChain-OpenTutorial/LangChain-OpenTutorial/blob/main/19-Cookbook/03-GraphDB/05-TitanicQASystem.ipynb
SPARQL in 11 minutes (youtube)
https://github.com/gazgiz
