타이타닉 생존자 분석
1) 데이터 탐색적 분석 - EDA
- plotly_express install
pip install plotly_express데이터 읽기
import pandas as pd
titanic_url = 'https://raw.githubusercontent.com/PinkWink/ML_tutorial/master/dataset/titanic.xls'
titanic = pd.read_excel(titanic_url)
titanic.head()
생존 상황
- import
import matplotlib.pyplot as plt
import seaborn as sns코드 & 그래프
f, ax = plt.subplots(1, 2, figsize=(16, 8))
titanic['survived'].value_counts().plot.pie(ax=ax[0], autopct='%1.1f%%', shadow=True, explode=[0, 0.05])
ax[0].set_title('Pie plot - survived')
ax[0].set_ylabel('')
sns.countplot(x='survived', data=titanic, ax=ax[1])
ax[1].set_title('Count plot - survived')
plt.show()- 38.2%의 생존률
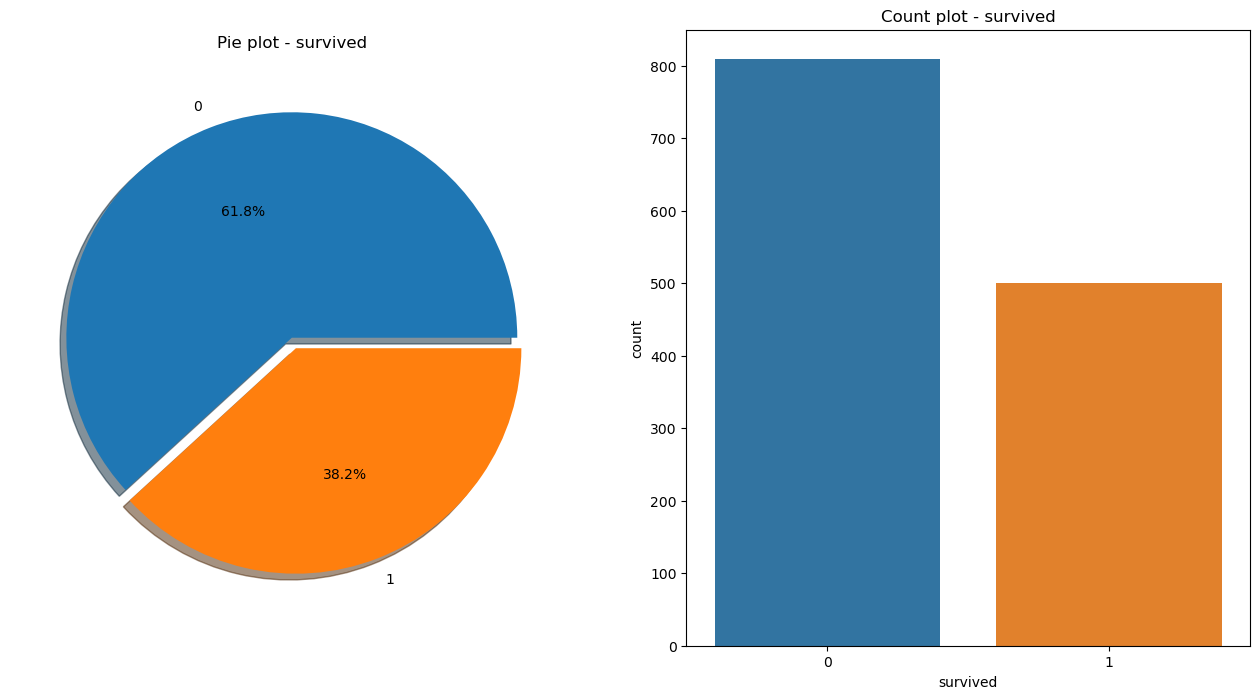
코드 설명
- p, ax = plt.subplot(1, 2, figsize=(16, 8))
-> p = 1, ax = 2
-> 1행 2열(한 개의 행에 두 개의 그래프를 그리겠다!) - ax=ax[0]: 맨 왼쪽 열에 그래프 그리겠다
- autopct='1.1f%%': 숫자 표기 / 소숫점 1자리
성별에 따른 생존 상황
코드 & 그래프
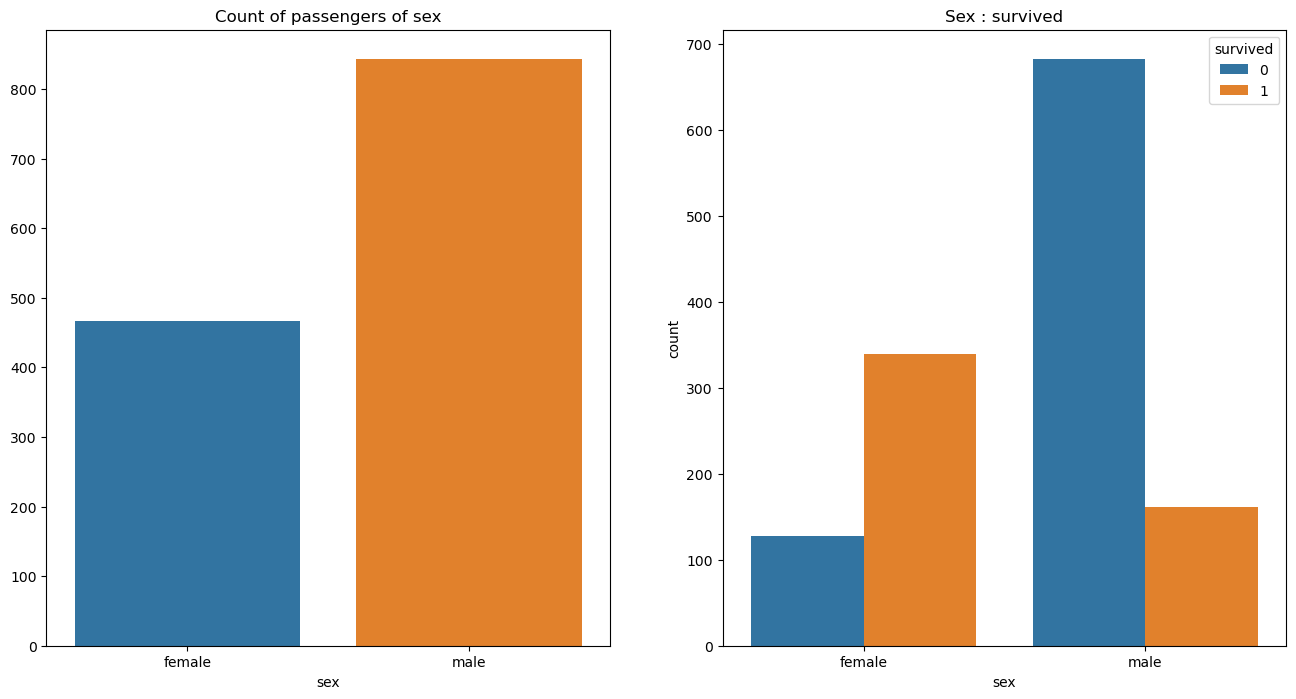
f, ax = plt.subplots(1, 2, figsize=(16, 8))
sns.countplot(x='sex', data=titanic, ax=ax[0])
ax[0].set_title('Count of passengers of sex')
ax[0].set_ylabel('')
sns.countplot(x='sex', data=titanic, hue='survived', ax=ax[1])
ax[1].set_title('Sex : survived')
plt.show()- 남성의 생존 가능성이 더 낮다
- 탑승자는 남성이 약 300명 더 많으나, 생존자는 훨씬 적음
경제력 대비 생존 상황
코드 & 그래프
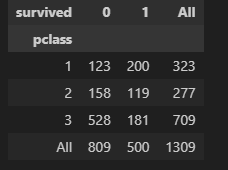
pd.crosstab(titanic['pclass'], titanic['survived'], margins=True)• 1등실의 생존가능성이 아주높다
• 그런데 여성의 생존률도 높다
• 그럼, 1등실에는 여성이 많이타고 있었을까?
선실 등급별 성별 상황
코드 & 그래프
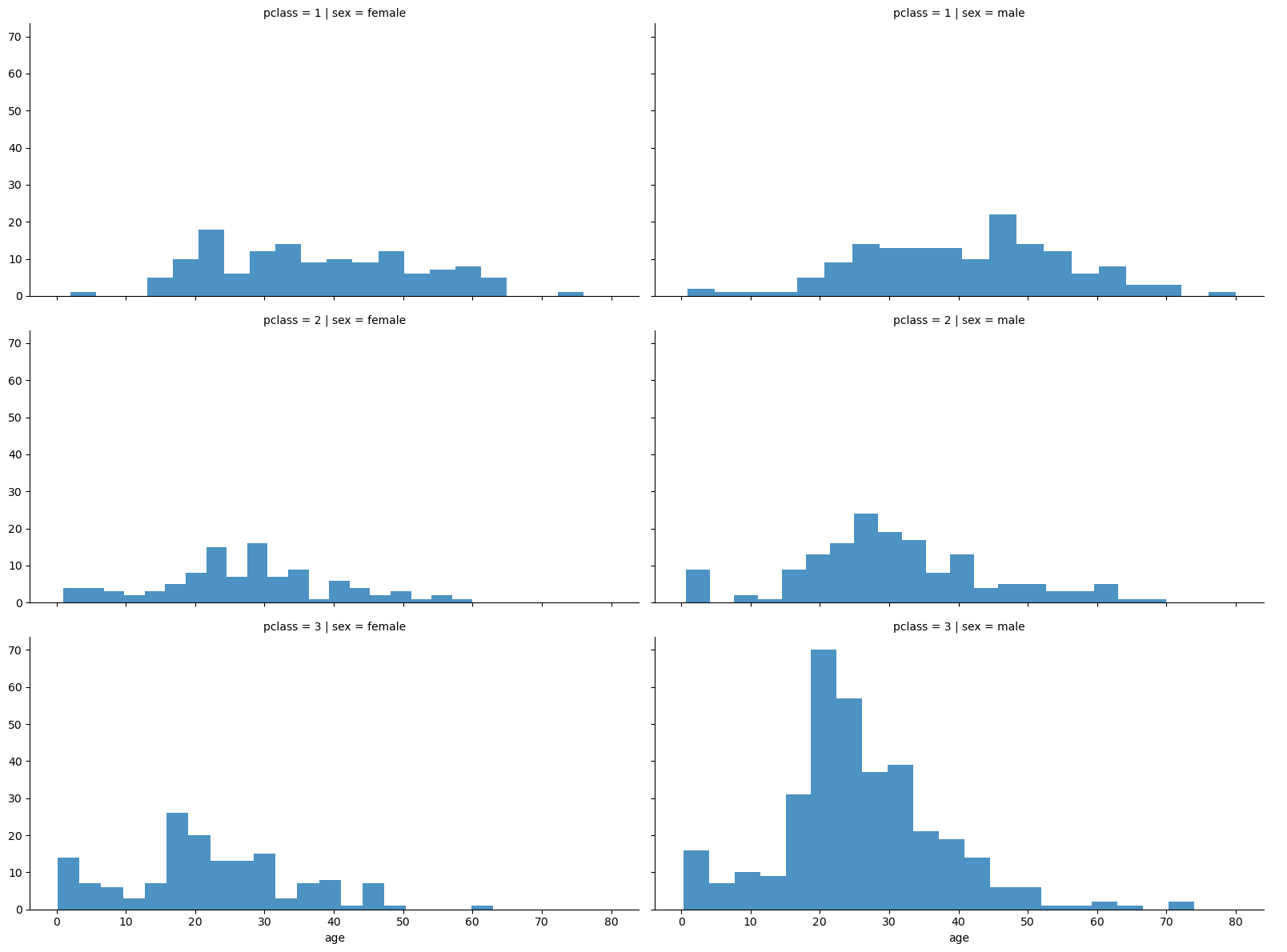
gird = sns.FacetGrid(titanic, row='pclass', col='sex', height=4, aspect=2)
gird.map(plt.hist, 'age', alpha=.8, bins=20)
gird.add_legend()- 3등실에는 10~30대 남성이 월등히 많았음
- 그래서 상대적으로 여성 생존률이 높아보였던 것으로 추정 됨
나이별 승객 현황
코드 & 그래프
- import
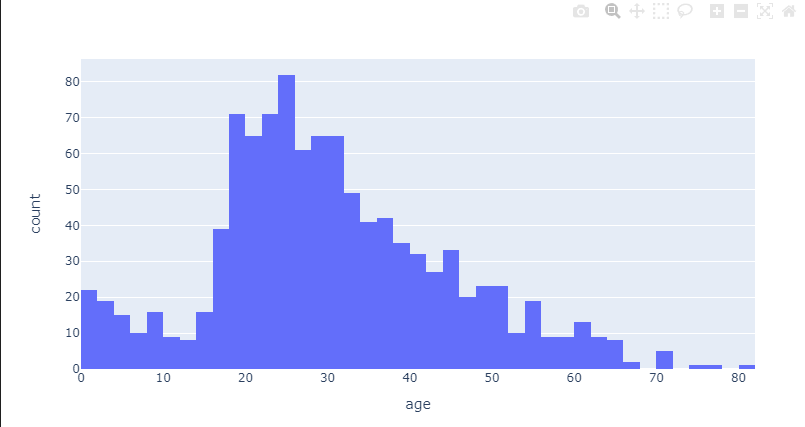
import plotly.express as pxfig = px.histogram(titanic, x="age")
fig.show()- 0~2세 아이들과 20~30대가 많았음
등실별 생존율 연령별로 관찰
코드 & 그래프
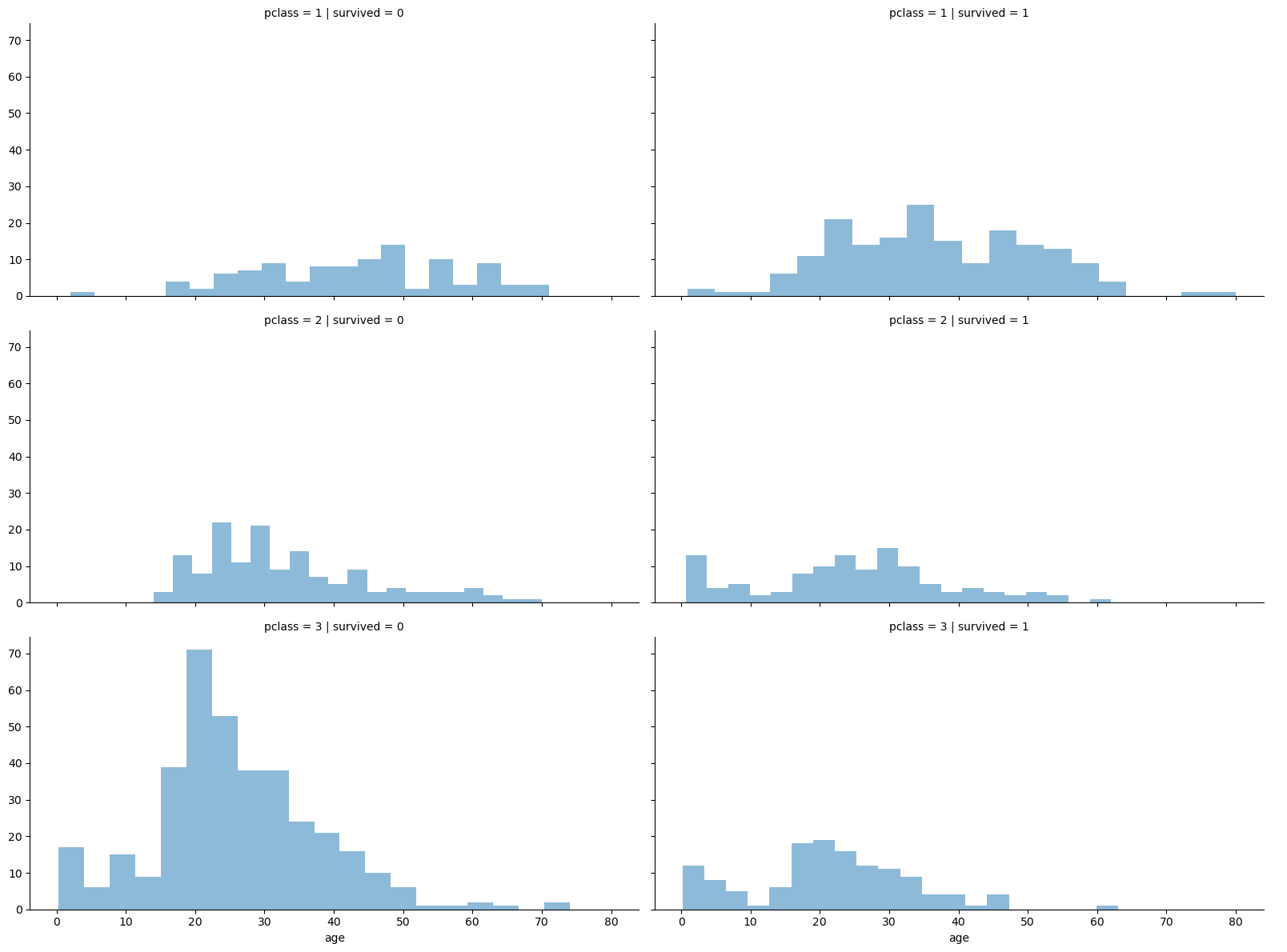
gird = sns.FacetGrid(titanic, col='survived', row='pclass', height=4, aspect=2)
gird.map(plt.hist, 'age', alpha=.5, bins=20)
gird.add_legend();- 3등실에서는 20~30대의 많은 사람들이 살아남지 못했음
- 나이를 5단계로 정리
titanic['age_cat'] = pd.cut(titanic['age'], bins=[0,7,15,30,60,100],
include_lowest=True,
labels=['baby', 'teen', 'young', 'adult', 'old'])
titanic.head()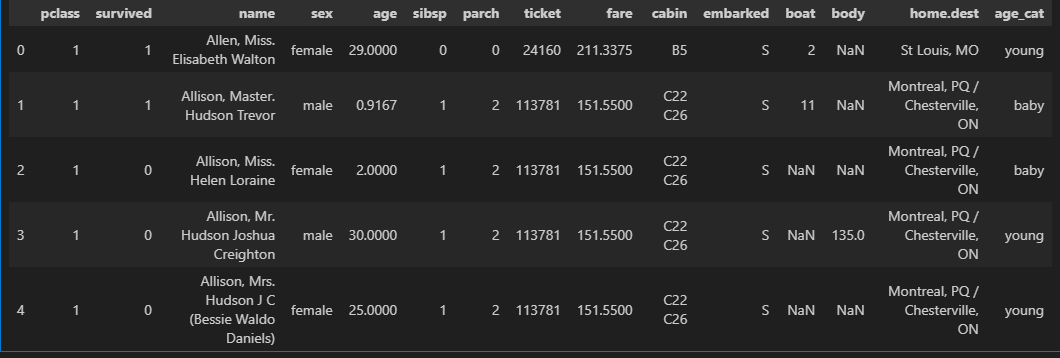
나이, 성별, 등급별 생존자 수 파악
코드 & 그래프
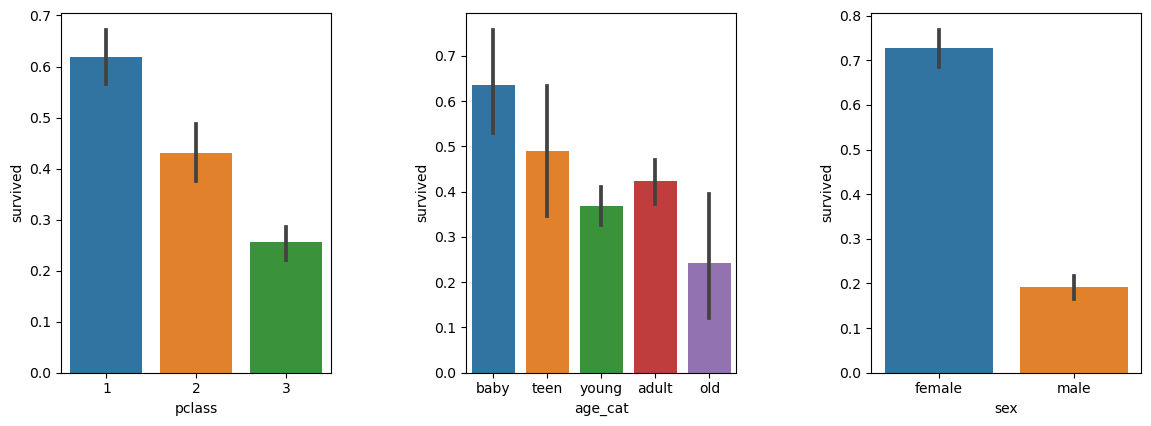
plt.figure(figsize=(12,4))
plt.subplot(131)
sns.barplot(x='pclass', y='survived', data=titanic)
plt.subplot(132)
sns.barplot(x='age_cat', y='survived', data=titanic)
plt.subplot(133)
sns.barplot(x='sex', y='survived', data=titanic)
plt.subplots_adjust(top=1, bottom=0.1, left=0.1, right=1, hspace=0.5, wspace=0.5)- 1등급일수록, 어릴수록, 여자일수록 생존률이 높음
남/여 나이별 생존 상황
코드 & 그래프
fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(14,6))
women = titanic[titanic['sex']=='female']
men = titanic[titanic['sex']=='male']
ax = sns.distplot(women[women['survived']==1]['age'], bins=20,
label = 'servived', ax = axes[0], kde=False)
ax = sns.distplot(women[women['survived']==0]['age'], bins=40,
label = 'not_servived', ax = axes[0], kde=False)
ax.legend(); ax.set_title('Female')
ax = sns.distplot(men[men['survived']==1]['age'], bins=18,
label = 'servived', ax = axes[1], kde=False)
ax = sns.distplot(men[men['survived']==0]['age'], bins=40,
label = 'not_servived', ax = axes[1], kde=False)
ax.legend(); ax = ax.set_title('Male')- 여성이 남성에 비해 상대적으로 살아남은 사람이 많음
- 남성 중에서는 0~10세 사이의 아이들은 살아남은 사람이 많음
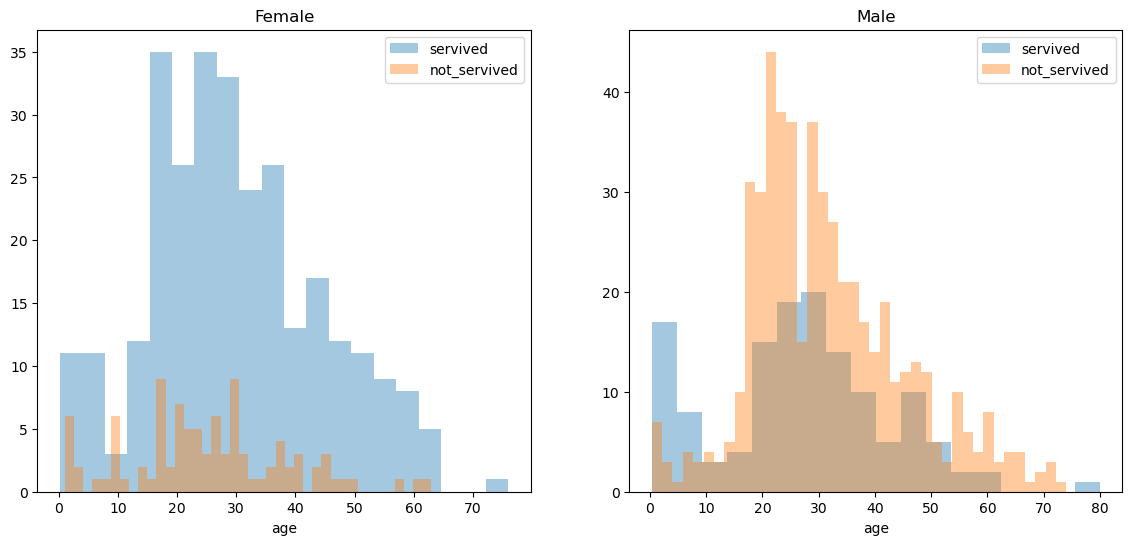
- 코드설명
- bins=n: 숫자가 높을수록 자료를 쪼개서 그림
- kde=T/F: 중간의 선 그래프 추가/제외
이름으로 신분 나누기
- 이름 데이터 살펴보기
for idx, dataset in titanic.iterrows():
print(dataset['name'])
- 정규식을 이용하여 문장 사이의 신분에 대한 정보만 추출 및 titanic에 추가
import re
title = []
for idx, dataset in titanic.iterrows():
tmp = dataset['name']
title.append(re.search('\,\s\w+(\s\w+)?\.', tmp).group()[2:-1])
titanic['title'] = title
titanic.head()
- 이름 범주화 작업
pd.crosstab(titanic['title'], titanic['sex'])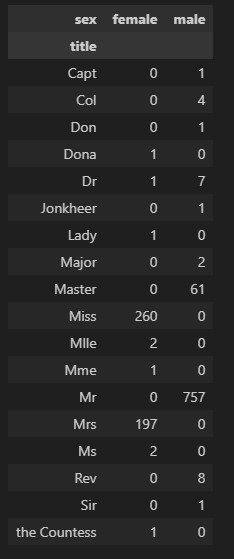
titanic['title'] = titanic['title'].replace('Mlle', 'Miss')
titanic['title'] = titanic['title'].replace('Ms', 'Miss')
titanic['title'] = titanic['title'].replace('Mme', 'Mrs')
Rare_f = ['Dona', 'Lady','the Countess']
Rare_m = ['Capt', 'Col','Don', 'Major', 'Rev', 'Sir', 'Dr', 'Master','Jonkheer']
for each in Rare_f:
titanic['title'] = titanic['title'].replace(each, 'Rare_f')
for each in Rare_m:
titanic['title'] = titanic['title'].replace(each, 'Rare_m')- 계급별 생존률 확인
titanic[['title','survived']].groupby(['title'], as_index=False).mean()- 평민남 -> 귀족남 -> 평민녀 -> 귀족녀 순으로 생존률이 높음
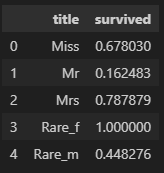
2) 생존자 예측 - 머신러닝
데이터 정리
- 성별을 숫자로 바꾸기
# 성별 값 확인
titanic['sex'].unique()
# 성별을 0, 1로 바꿔주기
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
le.fit(titanic['sex'])
titanic['gender'] = le.transform(titanic['sex'])
titanic.head()-
labelEncoeder는 값을 인코딩할 수 있게 바꿔주는 함수
-
성별을 fit(학습) 시켜준 다음 transform 하면 0, 1값으로 변경 됨
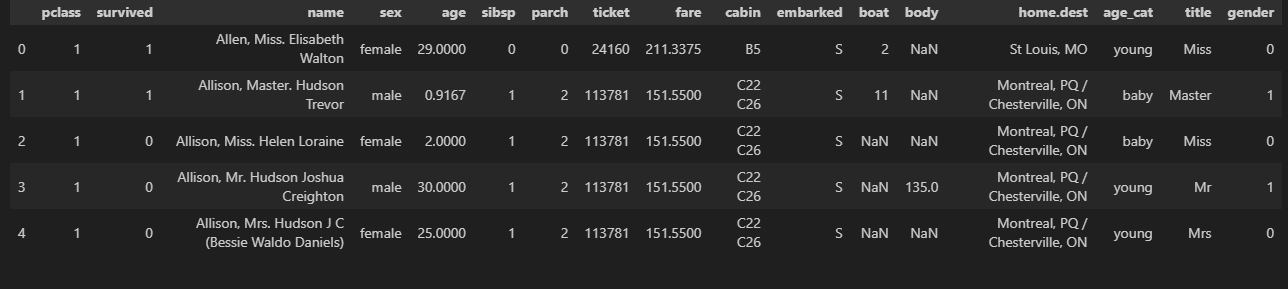
-
결측값 제거
titanic = titanic[titanic['age'].notnull()]
titanic = titanic[titanic['fare'].notnull()]- train / test 값 분리
from sklearn.model_selection import train_test_split
X = titanic[['pclass', 'age', 'sibsp', 'parch', 'fare', 'gender']]
y = titanic['survived']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=13)- 모델 학습
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
dt = DecisionTreeClassifier(max_depth=4, random_state=13)
dt.fit(X_train, y_train)
pred = dt.predict(X_test)
print(accuracy_score(y_test, pred))
정확도
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
dt = DecisionTreeClassifier(max_depth=4, random_state=13)
dt.fit(X_train, y_train)
pred = dt.predict(X_test)
print(accuracy_score(y_test, pred))-> 0.7655502392344498
생존률 예측 - 디카프리오
import numpy as np
dicaprio = np.array([[3, 18, 0, 0, 5, 1]])
print('Decaprio : ', dt.predict_proba(dicaprio)[0,1])-> Decaprio : 0.16728624535315986
생존률 예측 - 윈슬렛
winslet = np.array([[1, 16, 1, 1, 100, 0]])
print('winslet : ', dt.predict_proba(winslet)[0,1])-> winslet : 1.0

안녕하세요