
📌 트리
트리란 서로 다른 두 노드를 연결하는 길이 오직 하나인 그래프로, 정점과 간선을 이용하여 데이터의 배치 형태를 구조화한 자료구조이다.
트리는 배열, 스택, 큐 등의 선형구조와는 달리 비선형구조를 이루고 있다. 때문에, 자료의 저장보다는 자료를 탐색하고 표현하는 데에 초점을 둔다.
트리의 특징
- 트리는 부모와 자식 관계로 이루어진 계층적 관계이다.
- 트리에는 사이클이 존재하지 않는다.
- 트리는 반드시 하나의 루트를 갖고 있다.
- 모든 자식 노드는 오직 하나의 부모 노드를 갖는다.
트리와 관련한 용어
- 노드 : 트리를 이루고 있는 기본구성요소로, 각각의 노드는 데이터와 부모, 자식의 정보를 담고 있다.
- 간선(엣지, 링크) : 부모, 자식노드를 연결하는 선
- 루트노드 : 트리의 최상위 노드
- 브랜치노드 : 루트노드, 리프노드가 아닌 부모, 자식을 갖는 중간 노드
- 리프노드(단말, 터미널) : 자식을 갖지 않는 최하위 노드
- 부모노드 : 부속 트리를 갖는 노드
- 자식노드 : 부모에 속하는 노드
- 형제노드 : 같은 부모를 갖는 자식 노드들
- 깊이 : 루트에서 해당 노드까지의 간선의 수
- 높이 : 루트에서 최하위 노드까지 간선의 수
- 레벨 : 트리의 특정 깊이를 가지는 노드들의 집합
- 노드의 차수 : 해당 노드의 자식의 수
- 트리의 차수 : 가장 많은 자식을 갖는 노드의 차수
- 부분 트리 : 트리에서 일부분을 떼어낸 트리
트리 순회
1. 전위 순회
루트노드 - 왼쪽 자식 - 오른쪽 자식 순으로 순회한다.

2. 중위 순회
왼쪽 자식 - 루트 노드 - 오른쪽 자식 순으로 순회한다.

3. 후위 순회
왼쪽 자식 - 오른쪽 자식 - 루트 노드 순으로 순회한다.

트리 구현의 문제점
만일 하나의 노드가 다른 노드에 비해 과도하게 자식을 갖고 있는 불규칙한 트리의 경우, 노드를 구현하기 복잡해진다. 때문에 이진 트리가 많이 사용된다.
📌 이진 트리
모든 노드의 차수가 최대 2인 트리
이 때, 자식 노드가 없거나, 1개만 갖는 경우도 가능하다.
이진 트리의 종류
1. 편향 이진트리
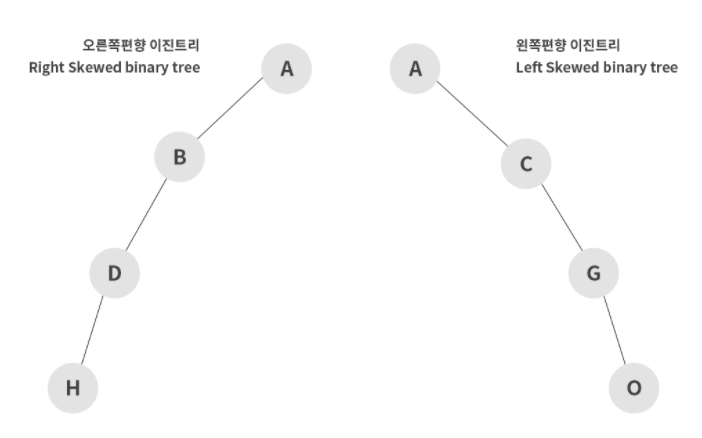
모든 노드가 왼쪽 자식 노드만을 갖고 있거나, 오른쪽 자식 노드만 갖고 있는 이진 트리를 의미한다.
이 경우에 마지막 레벨의 노드를 탐색하기 위해서는 모든 데이터를 탐색해야 하기 때문에 효율적이지 못하다.
2. 포화 이진트리
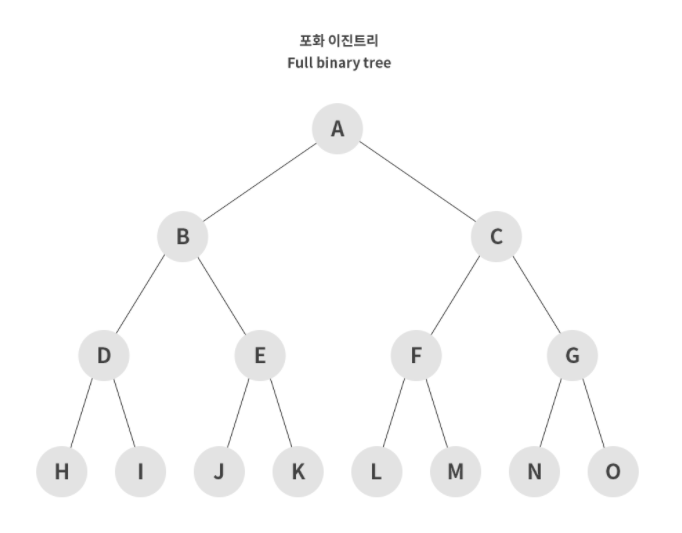
트리의 리프 노드를 제외한 모든 노드의 차수가 2인 이진 트리를 의미한다.
3. 완전 이진트리
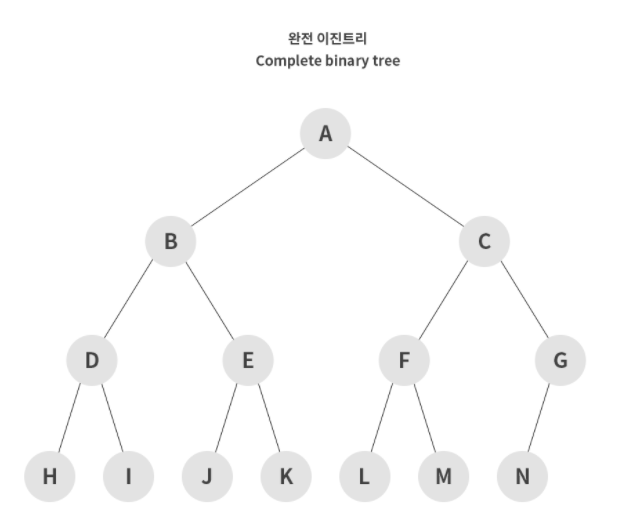
트리의 마지막 레벨을 제외한 모든 레벨의 노드가 완전히 채워져 있고, 마지막 레벨의 노드는 왼쪽에서부터 차례로 채워져 있는 이진 트리를 의미한다.
자료구조의 힙이 완전 이진트리에 해당한다.
📌 이진 탐색 트리(Binary Search Tree)
탐색을 위한 이진 트리 기반의 자료구조로, 효율적인 탐색과 삽입, 삭제가 가능하다.
이진 탐색 트리의 각 노드에는 중복되지 않는 키가 존재하고, 루트 노드의 왼쪽 서브트리에는 루트 노드보다 작은 키가, 오른쪽 서브트리에는 루트 노드보다 큰 키가 존재한다.
이 때, 이진 탐색 트리의 좌우 서브트리 역시 이진 탐색 트리이다.
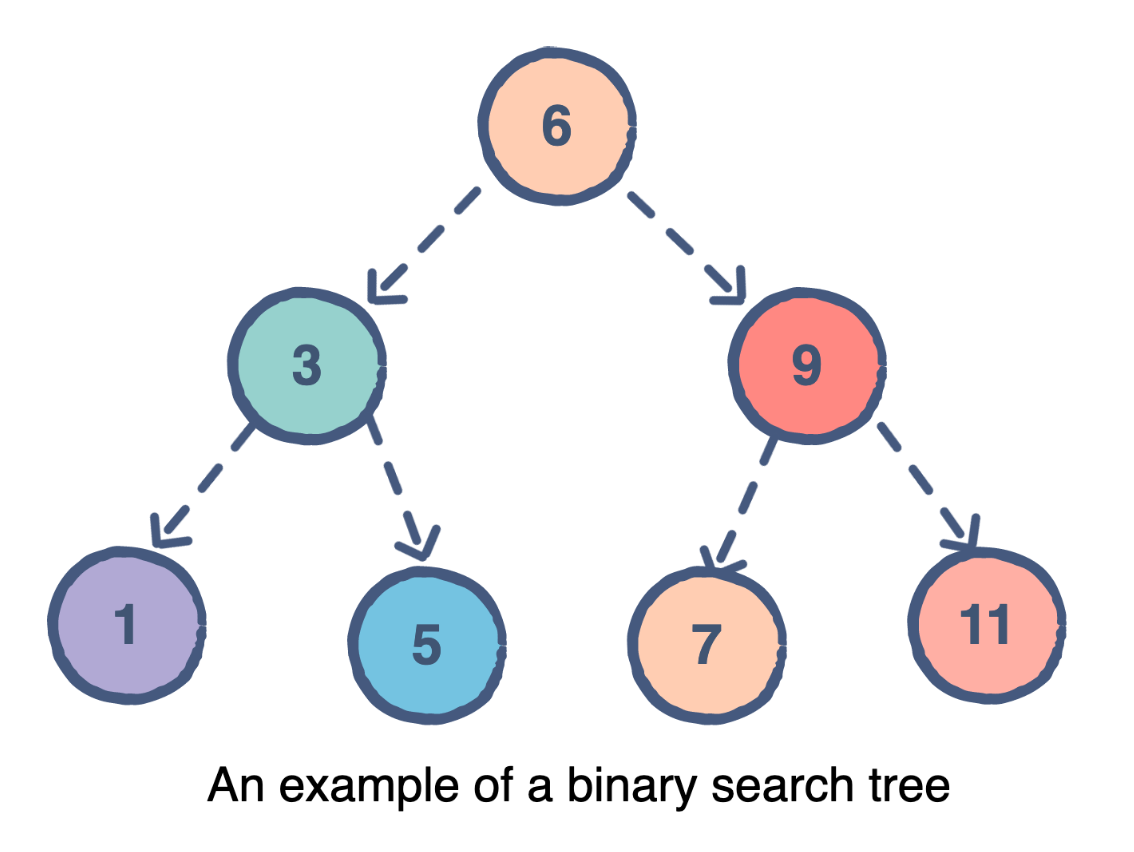
이진 탐색 트리 연산
1. 탐색
1. 찾고자 하는 값과 현재 노드의 키를 비교한다.
2. 찾고자 하는 값이 현재 노드보다 작다면 왼쪽 자식 노드로 이동하여 다시 1번부터 시작한다.
3. 찾고자 하는 값이 현재 노드보다 크다면 오른쪽 자식 노드로 이동하여 다시 1번부터 시작한다.
4. 찾고자 하는 키와 현재 노드의 키가 갖다면 탐색을 종료한다.이 때, 탐색의 최장 경로는 트리의 높이와 비례하기 때문에, 이진 탐색 트리 탐색 연산의 시간복잡도는 높이가 h일 때, O(h)이다.
구현
class Node:
def __init__(self, data):
self.data = data
self.left = None
self.right = None
class BST:
# 순환구조
def search_recursion(self, want_data):
if self.data == None: # 트리에 찾고자 하는 값이 없는 경우
return None
elif want_data == self.data: # 탐색하고자 하는 값을 찾은 경우
return self.data
elif want_data < self.data: # 현재 노드의 값이 탐색하고자 하는 값보다 작은 경우
self.left.search_recursion(want_data)
else: # 현재 노드의 값이 탐색하고자 하는 값보다 큰 경우
self.right.search_recursion(want_data)
# 반복구조
def search_iteration(self, want_data):
while self.data != None:
if want_data == self.data: # 원하는 값을 찾은 경우
return self.data
elif want_data < self.data: # 찾고자 하는 값이 현재 노드의 값보다 작은 경우
self.data = self.data.left
elif want_data > self.data: # 찾고자 하는 값이 현재 노드의 값보다 큰 경우
self.data = self.data.right
# 찾고자 하는 값이 없는 경우
return None2. 삽입
1. 삽입하고자 하는 노드를 탐색한다.
2. 트리에서 중복된 값을 갖는 노드는 존재하지 않으므로, 탐색에 실패한 자리가 노드를 삽입할 위치이다.
3. 해당 위치에 노드를 삽입한다.이진 탐색 트리의 삽입에는 탐색 과정을 거치기 때문에 시간 복잡도는 탐색 연산과 마찬가지로 높이가 h일 때 O(h)이다.
구현
class BST:
def insert_bst(self, data):
# 트리가 비었을 경우
if self.root == None:
self.root = Node(data)
else:
node = self.head
while True:
# 삽입하고자 하는 값이 현재 노드의 값보다 작은 경우
if data < node.data:
if not node.left:
node.left = Node(data)
break
else:
node = node.left
# 삽입하고자 하는 값이 현재 노드의 값보다 큰 경우
else:
if not node.right:
node.right = Node(data)
break
else:
node = node.right3. 삭제
삭제 연산의 경우, 탐색과 삽입 연산에 비해 까다롭다. 삭제하려는 노드의 자식의 개수에 따라 경우가 나뉘므로 총 3가지의 경우를 고려해야 한다.
1. 탐색을 통해 삭제하고자 하는 노드를 찾는다.
2. 해당 노드가 자식을 갖고 있지 않다면 삭제한다.
3. 자식을 하나만 갖고 있다면, 삭제하고자 하는 노드의 부모 노드와 자식 노드를 연결한 뒤 해당 노드를 삭제한다.
4. 자식이 둘일 경우에는 삭제하고자 하는 노드의 자식 노드 중 조건에 맞는 노드와 부모 노드를 연결한 뒤 삭제한다.
- 삭제하고자 하는 노드의 왼쪽 서브 트리 중 최댓값
- 삭제하고자 하는 노드의 오른쪽 서브 트리 중 최솟값삭제 연산도 마찬가지로 탐색 과정을 거치고, 복사 및 삭제 연산은 상수시간이므로 시간 복잡도는 결국 높이가 h일 때 O(h)이다.
구현
def delete_bst(self, data):
# 트리가 존재하지 않는 경우
if self.root == None:
return None
node = self.root
parent = self.root
check = False
while node:
# 삭제할 노드 탐색
if data == node.data:
check = True
break
elif data < node.data:
parent = node
node = node.left
else:
parent = node
node = node.right
# 트리에 삭제할 노드가 존재하지 않는다면 탐색 종료
if not check:
return False
# 자식이 없을 때
if node.left is None and node.right is None:
if data < parent.data:
parent.left = None
else:
parent.right = None
# 자식이 하나일 때
elif node.left and node.right is None:
if data < parent.data:
parent.left = node.left
else:
parent.right = node.left
elif node.left is None and node.right:
if data < parent.data:
parent.left = node.right
else:
parent.right = node.right
# 자식이 둘일 때
elif node.left and node.right:
current, child = node, node.right
# 삭제하고자 하는 값의 오른쪽 서브트리 중 최솟값 탐색
while child.left:
current, child = child, child.left
# 탐색한 최솟값을 삭제하고자 하는 노드의 위치에 삽입
node.data = child.data
# 최솟값의 오른쪽 자식 노드가 있다면 이를 최솟값의 부모와 연결
if current != node:
if child.right:
current.left = child.right
else:
current.left = None
else:
node.right = child.right--
참고 사이트
🙇🏻♂️ https://jinyes-tistory.tistory.com/13
🙇🏻♂️ https://suyeon96.tistory.com/30?category=403287
