Hancom Project
1.[AI] 1차 과제 추론 테스트 매트릭스 & 테스트케이스 및 학습 진행 현황

지연시간 메트릭스:TTFT (Time To First Token): 첫 토큰 생성까지의 시간자동완성 모델: < 100ms (실시간 코딩 지원)기타 모델: < 500ms (사용자 체감 품질)TBT (Time Between Tokens): 토큰 간 생성 시간목표
2.[AI] 파인튜닝 최종 코드(4차 학습 분리)
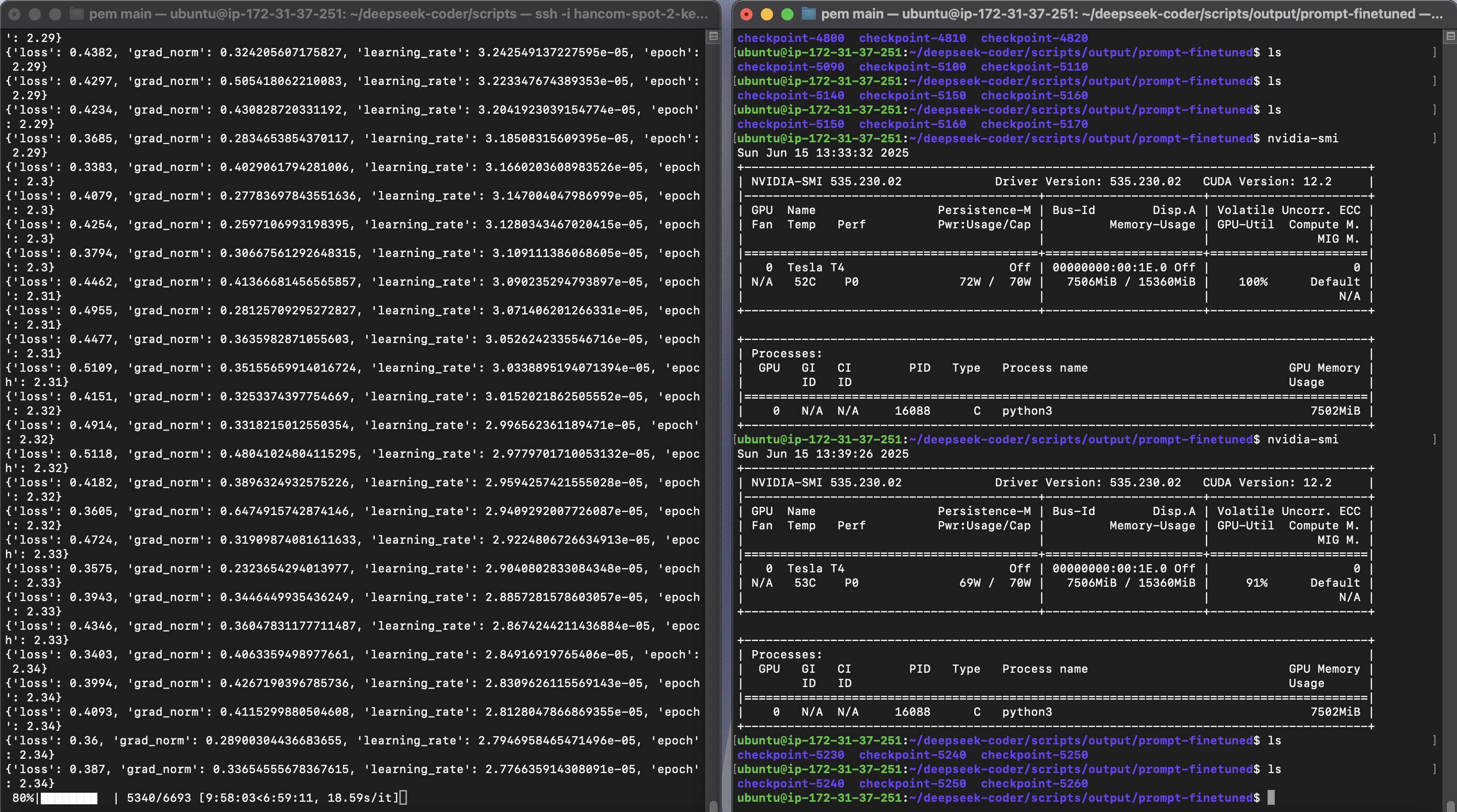
2차 학습 완료 기간까지 대기 중
3.[AI] 4차 모델 개별 Continual Learning + CapaBoost 설계 및 구현
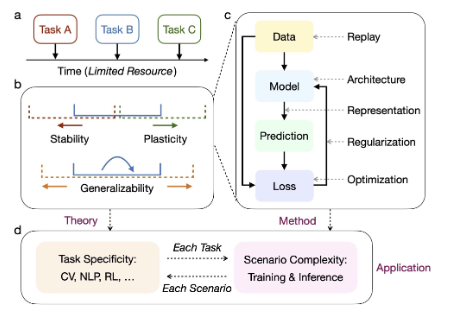
설계 목표: 각 차수별 final_model에 개별적으로 Continual Learning과 CapaBoost를 적용하여 모델 용량을 확장하면서 기존 지식을 보존하는 시스템 구축핵심 전략:1\. Task-Incremental Learning: 각 모델이 이미 특화된 태
4.[AI] 모델 병렬구조 구체화 초기 작업

초기에 작업된 코드라 현재 진행 상황에서는 많이 변경됐음.
5.Machine Translation LLM Model Search Part1
현재 DeepSeek Coder 6.7B Instruct 모델은 영어와 중국어 중심으로 훈련되어 있어, 한국어 프롬프트에 대한 이해도가 현저히 제한적입니다. 모델은 87개 프로그래밍 언어를 지원하지만, 자연어 처리 능력은 주로 영어에 최적화되어 있습니다. 이러한 한계를
6.Machine Translation LLM Model Search Part2
24GB VRAM 환경에서 DeepSeek Coder 6.7B Instruct와 동시에 운영할 수 있으면서 파이썬 도메인 지식과 한/영 번역 능력을 모두 갖춘 최적의 모델들을 분석했습니다.DeepSeek Coder 6.7B는 FP16 정밀도로 약 13-14GB VRAM
7.[AI] Continual Learning 기술 스택 정리
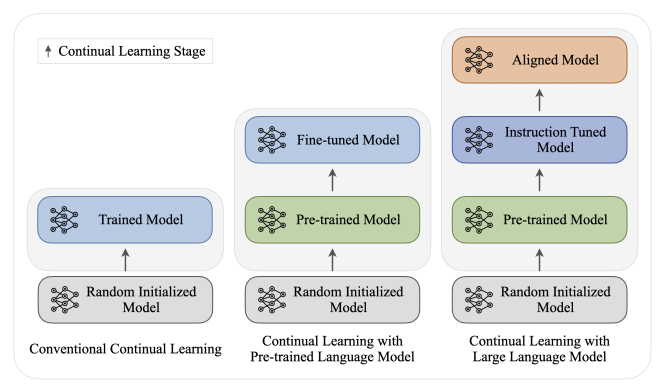
역할: 지속학습 전체 파이프라인의 핵심 컨트롤러.기능:베이스 모델 및 파인튜닝된 모델의 가중치 로드새로운 태스크(데이터셋)마다 학습/평가 루프 관리EWC, MER, Replay Buffer 등 다양한 지속학습 전략을 선택적으로 적용체크포인트 저장/복원, 학습률 스케줄링
8.원본 모델과 양자화 모델의 속도/메모리 비교 지표 확인 + 자동화 진행과정
DeepSeek Coder 6.7B Instruct: Memory Usage vs Inference Speed on A10G 24GB GPUDeepSeek Coder 6.7B Instruct: Memory Usage vs Inference Speed on A10G 24
9.Spring AI Prompt Engineering Patterns
Spring AI의 Prompt Engineering Patterns 문서는 자바(Spring) 기반의 LLM 활용 API 예제를 담고 있지만, 실제로 제시된 프롬프트 엔지니어링 패턴은 LLM(OpenAI, Anthropic 등) 공통의 기본 추상화입니다.주요 기법(
10.Fine-tuning + Continual Learning 동시 진행 분석 결과

총 VRAM: 23,028 MiB (22.5 GB)현재 사용중: 10,546 MiB (10.3 GB) 사용 가능: 12,482 MiB (12.2 GB)사용률: 45.8%기본 컴포넌트:DeepSeek-Coder 6.7B (4-bit 양자화): ~3,500 MiBLoRA
11.LoRA + PEFT
DeepSeek Coder 6.7B Instruct 모델은 67억 개의 파라미터를 가진 대규모 언어 모델이다. 이 모델을 FP16 정밀도로 로드할 경우 약 13.4GB의 VRAM이 필요하며, 전체 파인튜닝을 수행하려면 훨씬 더 많은 메모리가 필요하다.4-bit 양자화의
12.DeepSpeed
모델 및 하드웨어 사양:모델: DeepSeek-Coder-6.7B-InstructGPU: AWS EC2 A10G 22GBCPU: AMD EPYC 7R32 (4 cores 사용)추정 인스턴스: G5.xlarge (4 vCPU, 16GB RAM)학습 설정: 4-bit QL