1. 구현해야 하는 것
-
A와 B, 두 스택으로 이루어진 자료구조와 주어진 명령어들을 사용하여 입력으로 들어온 수들을 정렬하는 프로그램
-
초기에 수들은 A에 입력된 순서대로 삽입되며 정렬된 후에는 A에 저장되어야 한다.
(작은 수가 top쪽에 존재해야 한다.) -
11개의 명령어를 이용하여 정렬하며 최소 한으로 사용해야 한다.
- sa : a의 상위 두 원소를 swap 한다.
- sb : a의 상위 두 원소를 swap 한다.
- ss : sa와 sb를 동시에 실행한다.
- pa : b의 top을 a에 삽입한다.
- pb : a의 top을 b에 삽입한다.
- ra : a를 shift up한다.
- rb : b를 shift up한다.
- rr : ra와 rb를 동시에 실행한다.
- rra : a를 shift down한다.
- rrb : b를 shift down한다.
- rrr : ra와 rb를 동시에 실행한다.
-
명령인자로 주어지는 수는 int형 범위 안의 수이며 이를 만족하지 않는 경우에는 Error를 출력해야 한다.
2. 구현
-
명령인자 전처리
-
atoi 함수를 이용하여 문자열에서 숫자를 추출
-
하나의 문자열내에서 white space를 건너뛰며 추출할 수 있는 숫자들을 추출한다.
-
white space와 숫자가 아닌 문자열이 존재하면 int형 외부의 숫자를 return하여 atoi를 호출한 함수에서 예외 처리를 추가로 해준다.
-
-
정렬
-
ramdom access가 가능한 배열 자료구조를 사용하는 것이 아니므로 일반적인 정렬 알고리즘과는 다른 새로운 알고리즘을 필요로 한다.
-
또한, 사용 할 수 있는 자료구조가 2개의 stack이지만 r명령어를 통해서 stack의 아래쪽 공간도 사용할 수 있다.
-
하지만 A의 아래쪽에는 정렬한 숫자들을 저장해 놓아야 하므로 실제로 정렬에 사용할 수 있는 공간은 3군데이다.

-
이를 이용하여 특정 범위 내의 수들을 세 덩어리로 나누어가며 정렬하는 방식을 고민해보았다.
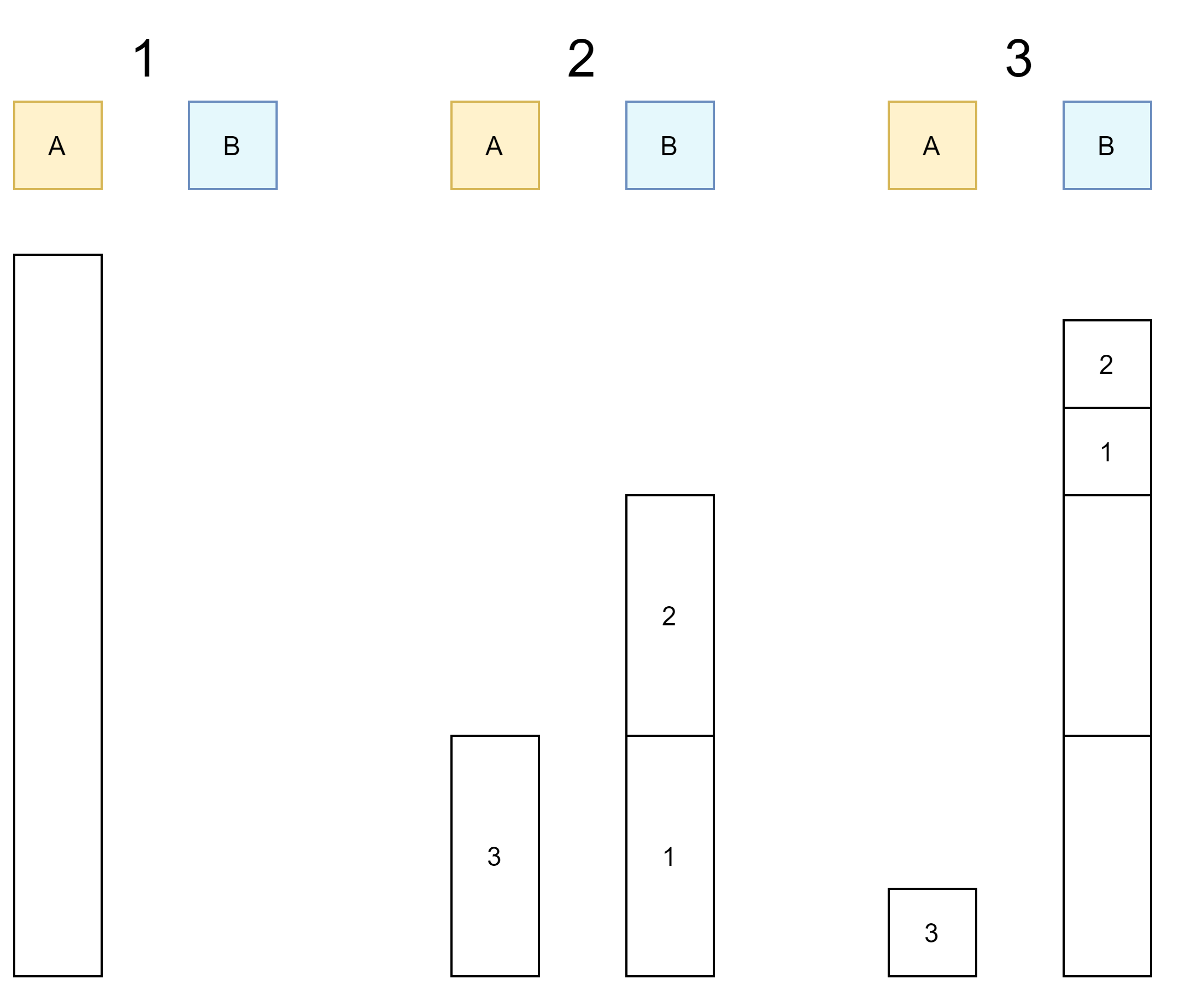
-
1번 그림은 초기 상태이며 2번은 A의 수 덩어리를 크기 순으로 3분할하여 가장 큰 덩어리만 A에 남겨놓고 나머지는 B로 옮긴 모습이다.
-
덩어리의 번호가 크면 큰 숫자를 포함하고 있으며 덩어리 내부의 수들은 아직 정렬되지 않은 상태이다. (3번 덩어리의 임의의 수 > 2번 덩어리의 임의의 수 > 1번 덩어리의 임의의 수)
-
3번 그림은 2번 그림의 3번 덩어리를 3분할 하여 같은 작업을 반복한 것이다.

-
4번 그림도 마찬가지 작업을 한 상태이며 3번 덩어리가 더 이상 쪼개지지 않는 상태, 즉 정렬된 상태라고 가정해보자.
-
5번 그림은 A가 정렬된 상태이므로 B에 존재하는 가장 위 덩어리(4번 그림의 2번 덩어리)를 3분할 하여 가장 큰 덩어리는 A에 나머지는 B에 다시 넣은 상태이다.
-
6번 그림은 5번 그림에서 A의 가장 위 덩어리를 다시 분할하여 가장 큰 덩어리를 A에 넣고 나머지는 B에 넣은 모습이며 정렬이 완료될 때까지 4, 5, 6번 그림의 과정을 반복하게 된다.
-
-
정렬의 구체적 구현 방법
-
덩어리를 세개로 나눌 때는 2개의 pivot값 f와 s를 정해서 f보다 작은 덩어리, f보다 크고 s보다 작은 덩어리, s보다 큰 덩어리 세 개로 나눈다.

-
이전 파트 그림의 1->2, 2->3, 3->4에서 사용되는 방법
-
파랑색 부분을 3개의 빨간색 부분으로 나눈 후 이동시켜 주는 과정을 보여준다.
-
3번과 1번을 삽입할 때는 1개의 명령어 사용(각각 ra, pb)으로 가능하지만 2번 같은경우는 B에 삽입하기 위해 3개의 명령어(pb와 rb, rrb)를 사용해야 한다.
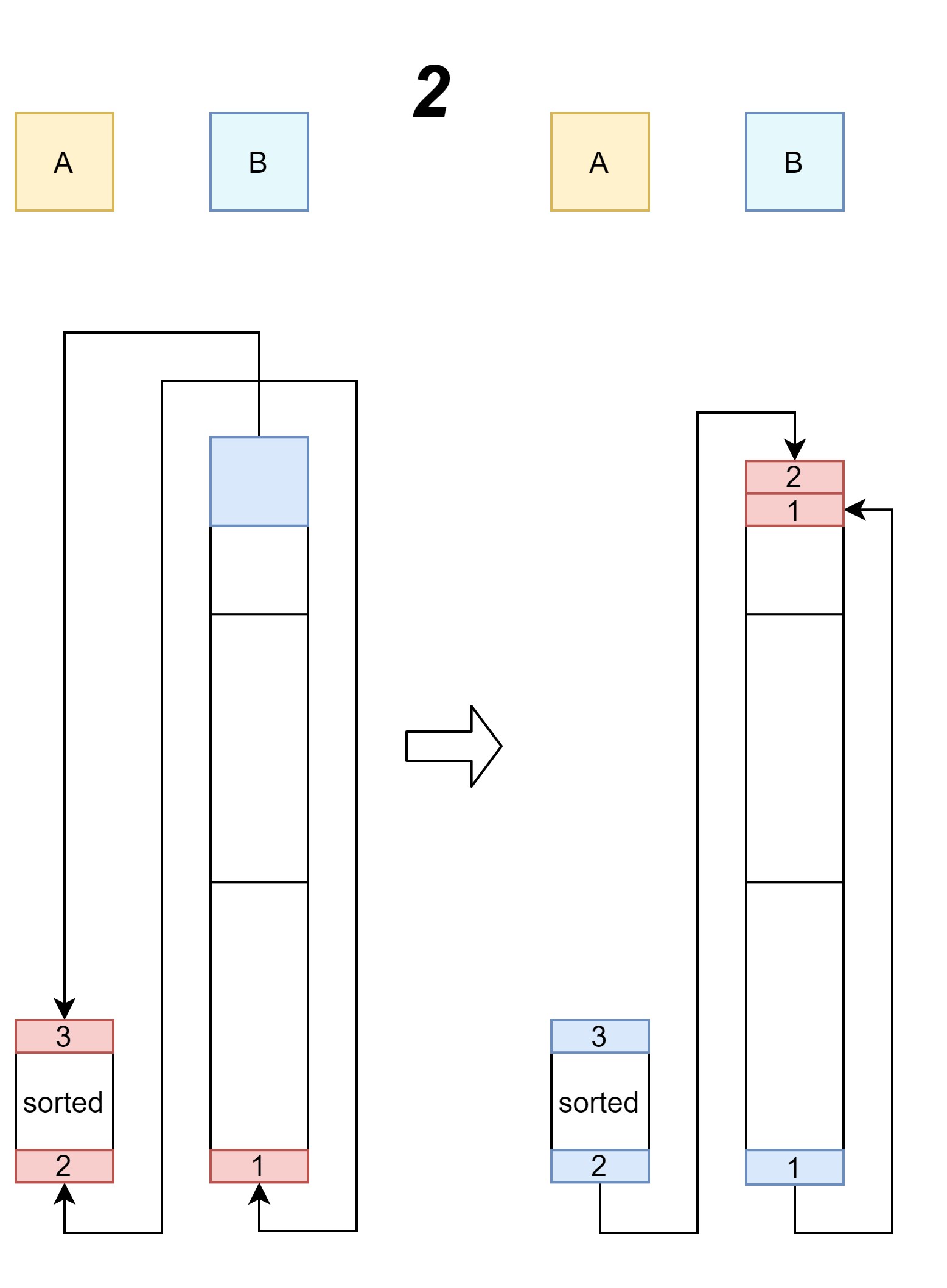
-
4->5 과정에서 사용되는 방법
-
정렬된 부분이 stack의 한 쪽을 막고 있어서 정렬을 위한 명령어의 개수가 상대적으로 많다.
-
3번 덩어리는 1개의 명령어(pa), 2번 덩어리는 4개의 명령어(pa, ra, rra, pb), 1번덩어리는 2개의 명령어(rb, rrb)를 사용해야 한다.

-
5->6 과정에서 사용되는 방법
-
구체적 구현 방법 1번과 유사하나 정렬된 부분이 A의 아래 부분을 차지하고 있어서 3번 덩어리를 stack의 위로 옮겨주는 과정이 한 번 추가가 된다.
-
프로그램은 A에 정렬되지 않은 원소가 남아 있지 않을때까지 1번 정렬 방법을 반복하다가 2번과 3번을 반복하는 구조로 구현된다.

-
3가지 정렬 방식은 하나의 함수 안에서 flag를 통해 구분되어 실행되며 각각의 정렬은 11개의 명령어를 구현한 3개의 ins함수를 통해 구현된다.
-
각각의 ins함수는 push, pop함수를 이용해 구현되며 일반 stack의 push, pop과는 다르게 parameter값을 통해서 들어오는 flag에 따라 stack의 아래로도 삽입, 삭제가 가능하도록 linkedlist를 이용해 구현하였다.
-
3. 최적화
- 이러한 방법으로 구현하면 프로젝트가 요구하는 원소 3개 정렬에 명령어 3개 이하 5개 정렬에 12개 이하 100개의 원소 정렬에 700개 이하 500개 정렬에 5500개 이하인 제한조건을 모두 통과 할 수 없다.
- 따라서 추가적인 최적화 방안이 필요하다.
-
pivot 값 최적화
- 정렬해야하는 부분의 원소들을 복사 후 정렬하여 원소의 개수가 동일한 세 덩어리로 나눌수 있는 pivot값을 찾아준다. (정확히 말하면 pivot값도 덩어리에 포함된다.)

- 프로젝트에서 요구하는 제한 조건이 시간이 아닌 명령어 개수이기에 이러한 방법이 가능하다.
- 정렬해야하는 부분의 원소들을 복사 후 정렬하여 원소의 개수가 동일한 세 덩어리로 나눌수 있는 pivot값을 찾아준다. (정확히 말하면 pivot값도 덩어리에 포함된다.)
-
명령어 합치기
-
sa, sb와 같은 명령어 들은 ss라는 하나의 명령어로도 수행 가능하다. 따라서 정렬을 마친후 명령어들을 합쳐주는 과정을 통해서 명령어의 개수를 줄여준다.
-
또한 위와 같은 구현을 하게되면 rb, pb, rrb, sb 명령어가 순서대로 반복되는 경향이 있다. 이는 pb 명령어 하나로 대체 가능하므로 명령어의 개수를 크게 줄여 줄 수 있다.

- rb, pb, rrb, sb의 수행결과

- pb의 수행결과
- 두 결과가 동일하다.
-
-
덩어리의 원소가 3개 이하일 때 명령어 줄이기
- 1개일 때 : A stack에 존재하면 아무것도 하지 않고, B stack에 존재하면 A로 옮겨준다.
- 2개일 때 : A stack에 존재하면 s_ins를 이용하여 순서만 정렬해주며 B stack에 존재하면 A로 옮겨주는 명령어도 사용
- 3개일 때 : 3개의 원소 중 크기가 큰 것의 위치에 따라 5개이내의 명령어로 구현가능하며 1번 정렬방식 사용중일때(sorted부분이 A stack을 막고 있지 않을때)는 3개 이내로 가능하다.
(r, rr명령어가 사용가능하기 때문)
4. 마무리
- push_swap을 통해서 어떻게 구현할 것인지 생각하고 이를 구체화 한 후 최적화하는 프로그램의 제작 과정을 간략하게 경험해 볼 수 있었다고 생각한다. 위에 작성한 내용에 더해서 메모리 누수를 체크하고 malloc guard를 추가하는 작업이 있지만 따로 작성하지 않겠다.
- 지금까지 작성해 본 코드중에서는 가장 크기가 큰 코드이다. 여러 에러사항(seg, bus error 등등)이 발생하지 않고 성공적으로 마무리 할 수 있어서 좋았다.
