
데이터 분석에 입문하는 사람들 대부분이 선택하는 가장 보편적이고 유명한 분석인 타이타닉 생존자 예측 분석이다.
일단 ❗️ 캐글에 들어가서 데이터셋(train.csv)을 다운로드 한다.
분석 목적은
: 타이타닉 호 탑승객 데이터를 활용하여 생존 여부(Survived)에 영향을 미친 주요 요인들을 파악하고, 이를 바탕으로 탑승자의 생존 여부를 예측할 수 있는 간단한 모델 구축 해보는 것으로
나는 일단 "로지스틱 회귀모델"을 택했다. 추가로 다음 포스팅에서 랜덤 포레스트 모델도 한번 구축 해볼 계획은 있다.
일단 로지스틱 회귀는 ,,
이진 분류 (생존 또는 비생존)로 sigmoid 함수를 사용하여 0~1 사이의 확률값을 생성한다.
각 변수의 영향력(계수)을 해석할 수 있고 매우 빠르고 가벼우며 과적합 위험은 낮은편이다. ❗️하지만 전처리 과정에서 NaN 처리, 범주형 인코딩이 필요하다. 그리고 선형적 경계만 가능하다는 한계점이 있다.❗️
그럼 시작해보쟈 ! ⸜( •ᴗ• )⸝*
Step 1. 파이썬 라이브러리 불러오기

일단 pandas 모듈, 시각화 모듈인 matplotlib, 그리고 seaborn 까지 임포트 해온다.
그리고 pd.resd_csv로 train.csv파일을 불러온다.
Step 2. 데이터 셋 불러오기
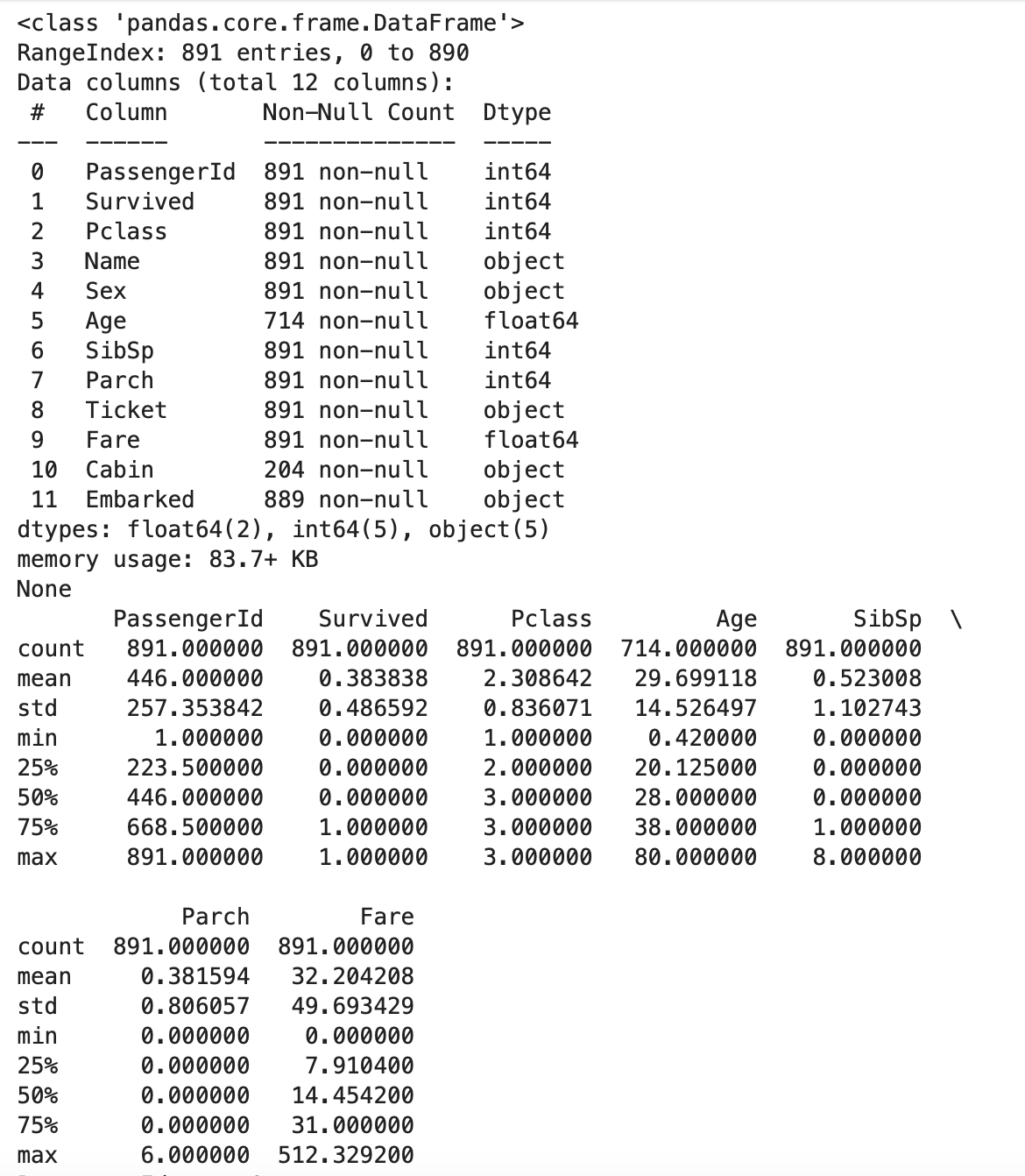
print(df.info())
print(df.describe())
print(df.isnull().sum())이 세 줄의 코드로 기본적인 데이터 구조를 파악한다.
df.info()로 기본적인 행열 개수와 열의 데이터 타입, 그리고 결측값(non-null)의 개수 또한 파악 할 수 있다.
df.describe()로는 각 열에 대한 요약 통계를 보여준다.
df.isnull().sum()을 통해 어떤 변수(요인)에 결측값 몇개 있는지도 확인한다.
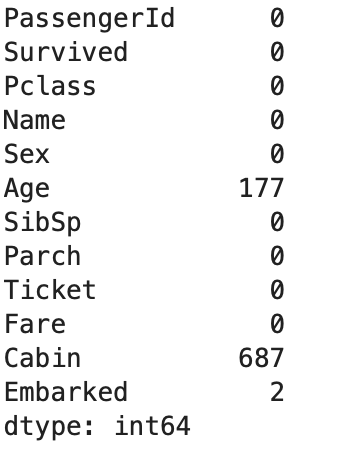
→ 결측치는 Age, Cabin에 각각 177, 687개씩 있고 Cabin은 너무 많아서 제거한다.
df.drop(columns=['Cabin'], inplace=True)Step 4. 데이터 전처리
df['Age'].fillna(df['Age'].mean())
df['Embarked'].fillna(df['Embarked'].mode()[0])→ Age 열에서 비어 있는 값(NaN)을 .fillna 함수를 이용해 평균(mean) 나이로 채우고, Embarked(탑승항)에서는 최빈값(mode) 탑승항으로 채운다.
Step 5. 탐색적 데이터 분석 (EDA)
1. 생존자 수 시각화
sns.countplot(x='Survived', data=df)
plt.title('Survival Count')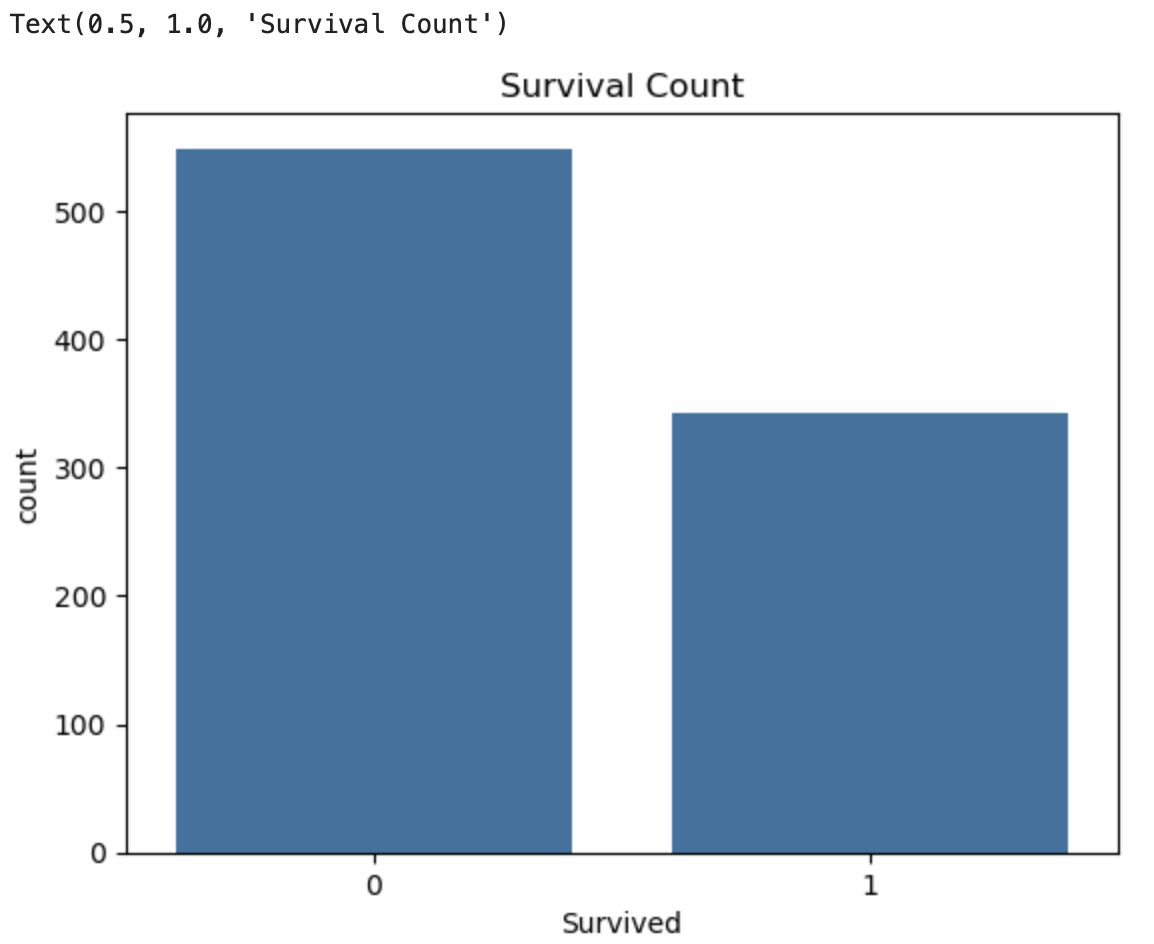
☑️ 생존자 : 1, 사망자 : 0
2. 성별 생존/사망
sns.countplot(x='Sex', hue='Survived', data=df)
# hue = 색깔을 기준으로 그룹을 나누자
plt.title('Survival by Sex')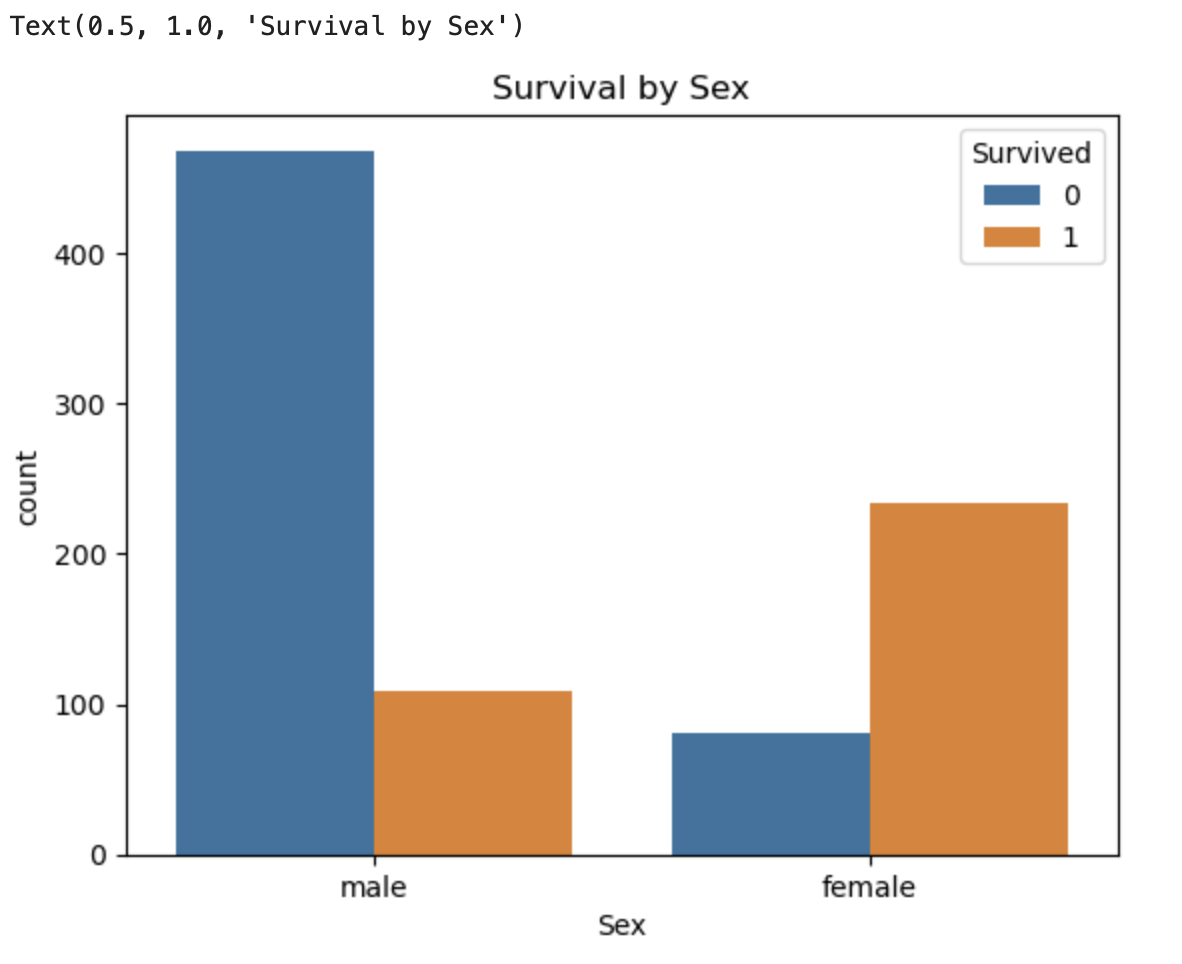
👉 여성 생존율이 남성보다 훨씬 높다.
3. 객실 등급별 생존/사망
sns.countplot(x='Pclass', hue='Survived', data=df)
plt.title('Survival by Pclass')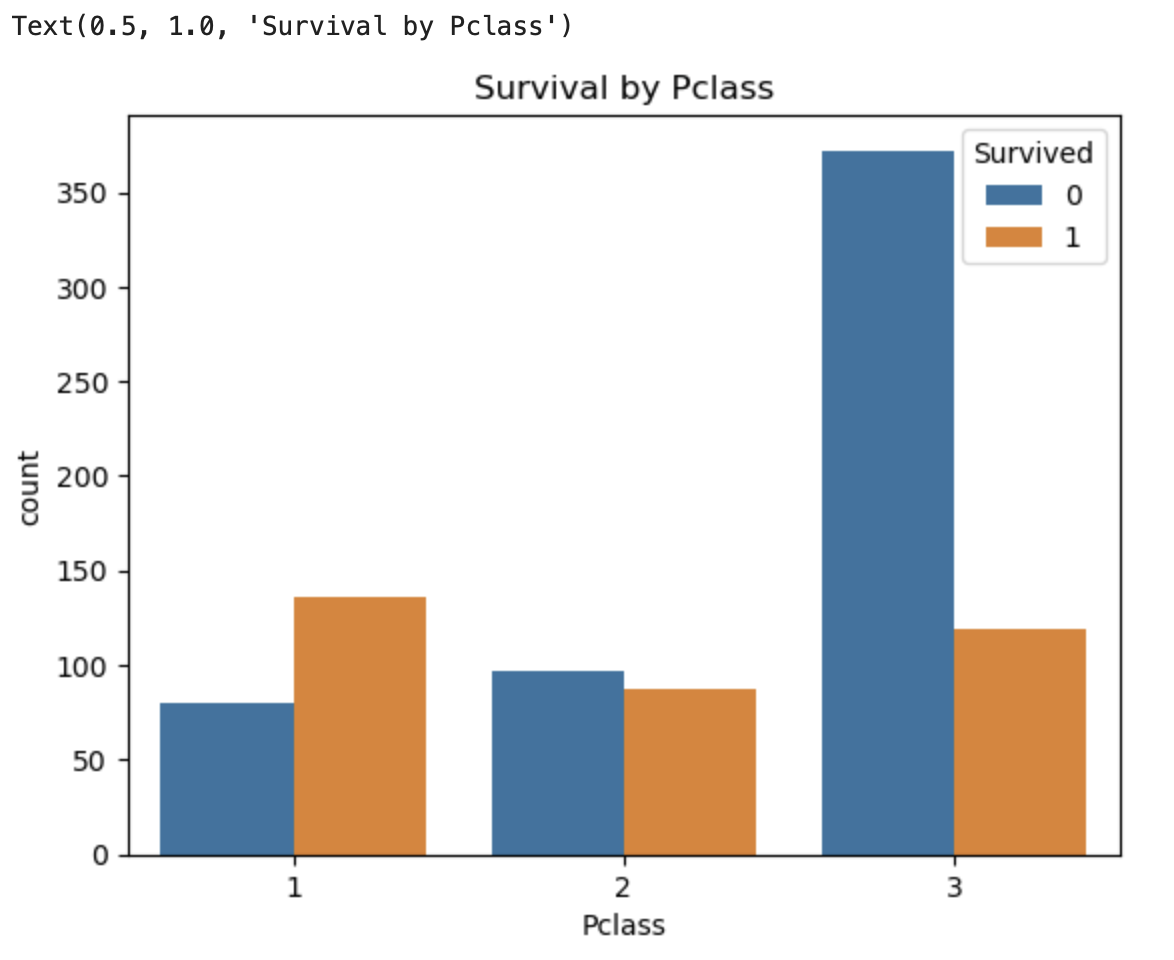
👉 1등석 승객일수록 생존 확률이 높다 / 3등석 승객의 사망자 비율이 월등히 높다.
4. 나이에 따른 생존/사망
sns.histplot(data=df, x='Age', hue='Survived', bins=20, kde=True)
# kde : 곡선그래프 추가
plt.title('Age Distribution by Survival')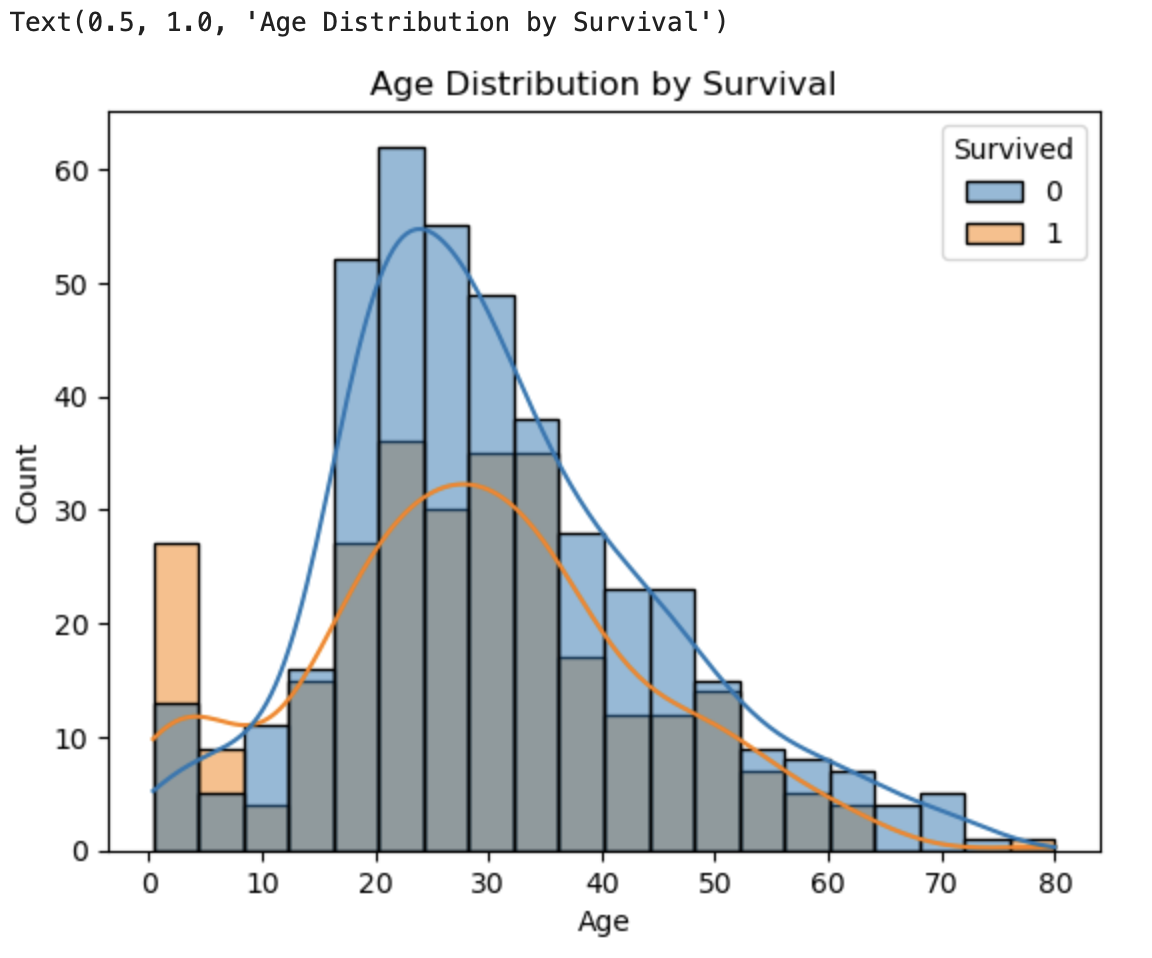
-
사망자(파란색)는 20~40대에서 집중
특히 20대 초반~30대 초반에서 많은 사망자 존재
KDE 곡선도 이 구간에서 가장 높게 나타남
→ 이 나이대가 탑승자 중 가장 많은 비중을 차지했을 가능성 -
생존자(주황색)는 유아(0~5세)에서 많음
생존자 중 0~5세 아이들 비율이 상대적으로 높음
막대그래프도 주황색 비율이 큼
이건 “어린아이를 먼저 구조했다”는 역사적 사실과도 부합함. -
노년층(60세 이상)은 전체적으로 적음
전체적으로 고령자는 수가 적고, 생존자도 매우 드물어 보임.
✅ 중간 연령층(20~40세)에서 생존자보다 사망자가 더 많음
반면, 아주 어린 연령층(0~5세)에서는 생존자가 상대적으로 많음
5. 그룹별 생존율 평균 비교
print(df.groupby('Sex')['Survived'].mean())
print(df.groupby('Pclass')['Survived'].mean())
print(df.groupby('Embarked')['Survived'].mean())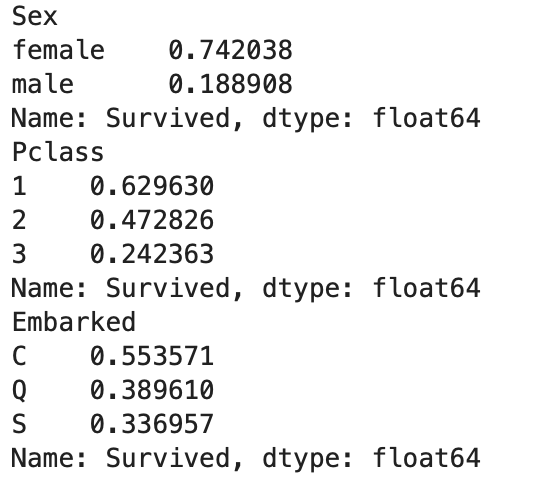
📉 생존 여부를 예측하는 로지스틱 회귀 모델
일단 먼저 모듈을 불러와보자
로지스틱 회귀 모델과, 변수 인코딩, train-test split에 쓰이는 모듈들이다.
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
df = pd.read_csv('train.csv') 그리고 머신러닝 모델은 문자열(텍스트) 데이터를 이해하지 못하기 때문에 그래서 숫자로 바꿔줘야 한다.
- "male", "female" → 각각 0, 1로 바뀜
- "S", "C", "Q" → 0, 1, 2 등으로 바뀜
→ 이 과정을 인코딩(encoding) 이라고 한다.
# 범주형 변수 인코딩 (문자 -> 숫자)
df['Sex'] = LabelEncoder().fit_transform(df['Sex']) # female=0, male=1
df['Embarked'] = LabelEncoder().fit_transform(df['Embarked'])✅ 입력 데이터(X)에 NaN(결측값)이 있는지 먼저 확인해본다.
확인 결과 Age에 177개의 결측치 확인되었으므로, 평균 또는 최빈값으로 채워준다.
df[['Pclass', 'Sex', 'Age', 'Fare', 'Embarked']].isnull().sum()
df['Age'] = df['Age'].fillna(df['Age'].mean()) # 해결 -> 평균/최빈값으로 채우기이 데이터는 train.csv로 학습 데이터 이기 때문에 특징 x 와 목적변수(tageting variable) y로 나눈다.
X: 예측값 (승객 정보)
y: 정답 (생존 여부)
X = df[['Pclass', 'Sex', 'Age', 'Fare', 'Embarked']] # 예측에 사용할 입력 데이터
y = df['Survived'] # 정답 (0 or 1)데이터 중 80%는 학습에 쓰고, 20%는 모델 성능 평가(테스트)에 사용하는데, 이걸 train-test split 이라고 한다.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)이 과정이 끝났다면, 로지스틱 회귀 모델을 선택해주고 학습해준다.
👉🏻
fit()이 실행되면, 모델은 아래와 같은 과정을 한다:
1. X와 y의 관계를 찾기 위해 가중치(weight) 와 절편(bias) 를 찾음
2. 이때 오차(예측값과 실제값 차이)를 최소화하도록
경사하강법(gradient descent) 같은 방법으로 파라미터를 조정한다.
" 결과적으로 학습이 완료되면, 모델은 새로운 입력을 주면 생존할지 아닐지 예측할 수 있게 되는것이다.
model = LogisticRegression()
model.fit(X_train, y_train)마지막으로 모델의 정확도(Accuracy)를 출력해준다.
print("Test Accuracy:", model.score(X_test, y_test))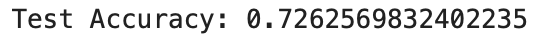
이건 타이타닉 생존 예측 모델이 테스트 데이터에서 약 72.6% 정확도로 예측했다는 뜻으로,
이정도면 기초 모델만으로도 꽤 좋은 성능 이다.
✏️ 간단히 정리한 로지스틱 회귀 모델 학습과정
모델을 만든다 → model = LogisticRegression()
학습시킨다 → model.fit(X_train, y_train)
예측한다 → model.predict(X_test)
평가한다 → model.score(X_test, y_test)
📈 혼동행렬(confusion matrix)로 시각화 하기
cm = confusion_matrix(y_test, y_pred)
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=["Dead", "Survived"])
disp.plot(cmap='Blues', values_format='d')
plt.title("Confusion Matrix")
plt.show()x축은 예측(y_pred), y축은 실제값(y_test)이다.
블루 계열로 칠했고, 숫자가 높을수록 짙게 표현했으며, 변수형은 정수 'd'로 했다.
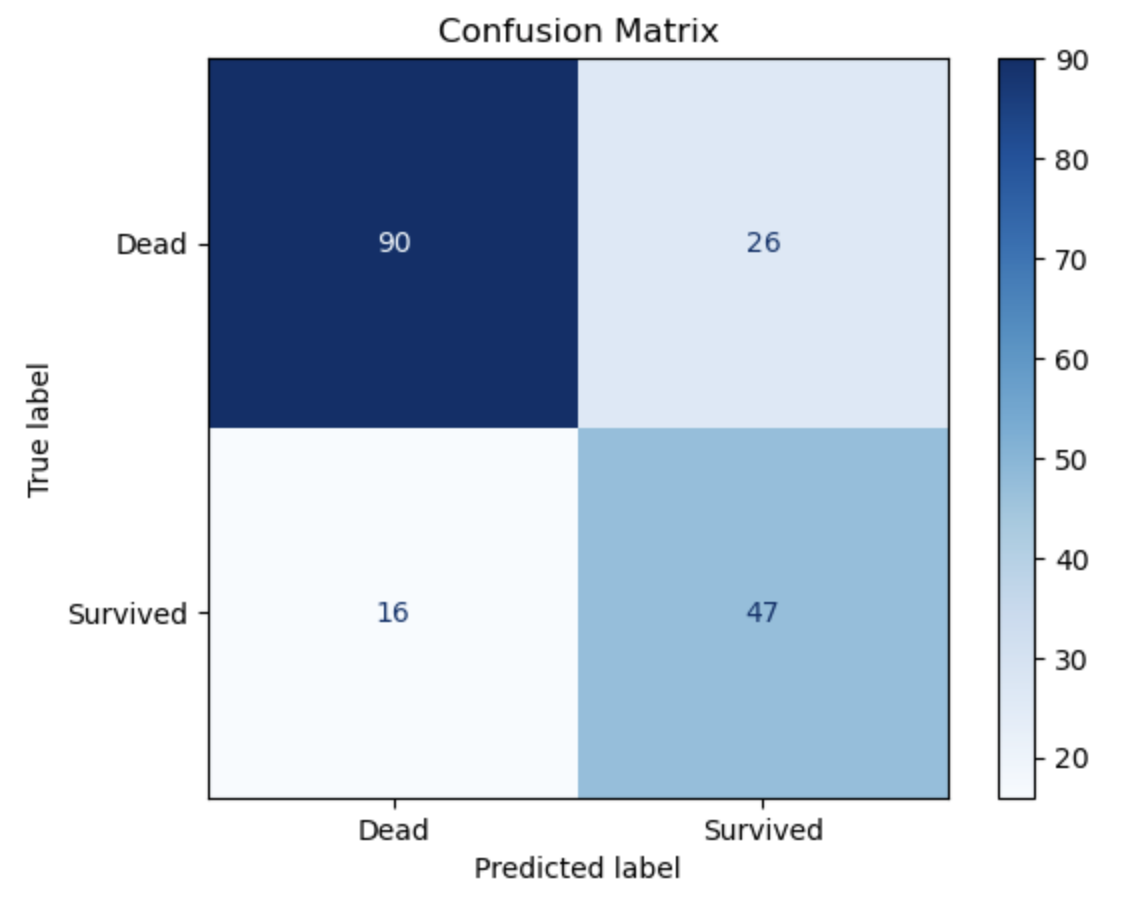
| 예측 = Dead (0) | 예측 = Survived (1) | |
|---|---|---|
| 실제 = Dead (0) | 90 (TP) | 26 (FN) |
| 실제 = Survived (1) | 16 (FP) | 47 (TN) |
TP = 진짜 죽은 사람을 죽었다고 맞춘 것 : 90 ⭕️
FN = 진짜 죽은 사람을 살았다고 틀린 것 : 26 ❌
FP = 진짜 산 사람을 죽었다고 틀린 것 : 16 ❌
TN = 진짜 산 사람을 살았다고 맞춘 것 : 47 ⭕️
이로써, 모델 평가를 해보자면,,
사망자는 꽤 잘 맞춤
실제 사망자: 116명 (90 + 26) 중
모델이 90명 맞춤 → 약 77.6% 맞춤
→ 즉, 죽을 사람은 잘 예측함
BUT, 생존자는 절반 정도만 맞춤
실제 생존자: 63명 (47 + 16) 중
모델이 47명 맞춤 → 약 74.6% 맞춤
→ 조금 놓치는 생존자 있음 (16명 오판)
이라고 평가 할 수 있겠다.
이렇게 아주 간단?하지는 않았고,, 초보?적이지도 않았던 ㅠㅠ 타이타닉 분석을 마쳤다. 다음 글에는 랜덤 포레스트 모델 학습 관련 짧은 포스팅을 써 볼 생각이다. 그리고 분석을 하며 썼던 코드에 관한 자세한 설명들 또한 따로 포스팅해서 정리해보면 좀 더 익숙해지는데 도움이 될것 같다.
이렇게 나의 첫 velog를 마치겠다 ! 🍀
