[Logical] Apache Kafka 주요 요소
- Topic과 Producer,Consumer (Pub,Sub이라고도 한다.)
+Apache Kafka Cluster: 아파치 카프카 클러스터라는 곳에서 토픽을 만든다.Topic: 카프카 내부에서 메세지가 저장되는 곳이라고 표현할수 있다. (논리적)Producer: 프로듀서는 메세지를 만들어서 토픽으로 보내주는 애플리케이션이다.Consumer: 컨슈머는 카프카 토픽 내에있는 메세지를폴링(Polling)하여 가져가서 활용하는 애플리케이션이다.Consumer Group: 최소 하나 이상의 컨슈머들은 컨슈머 그룹에 존재한다. 컨슈머 그룹내의 컨슈머들은 서로 협력(소통)하여 Topic에 있는 메세지를 가져와 분산 병렬 처리하는 구조로 이루어져있다.
-
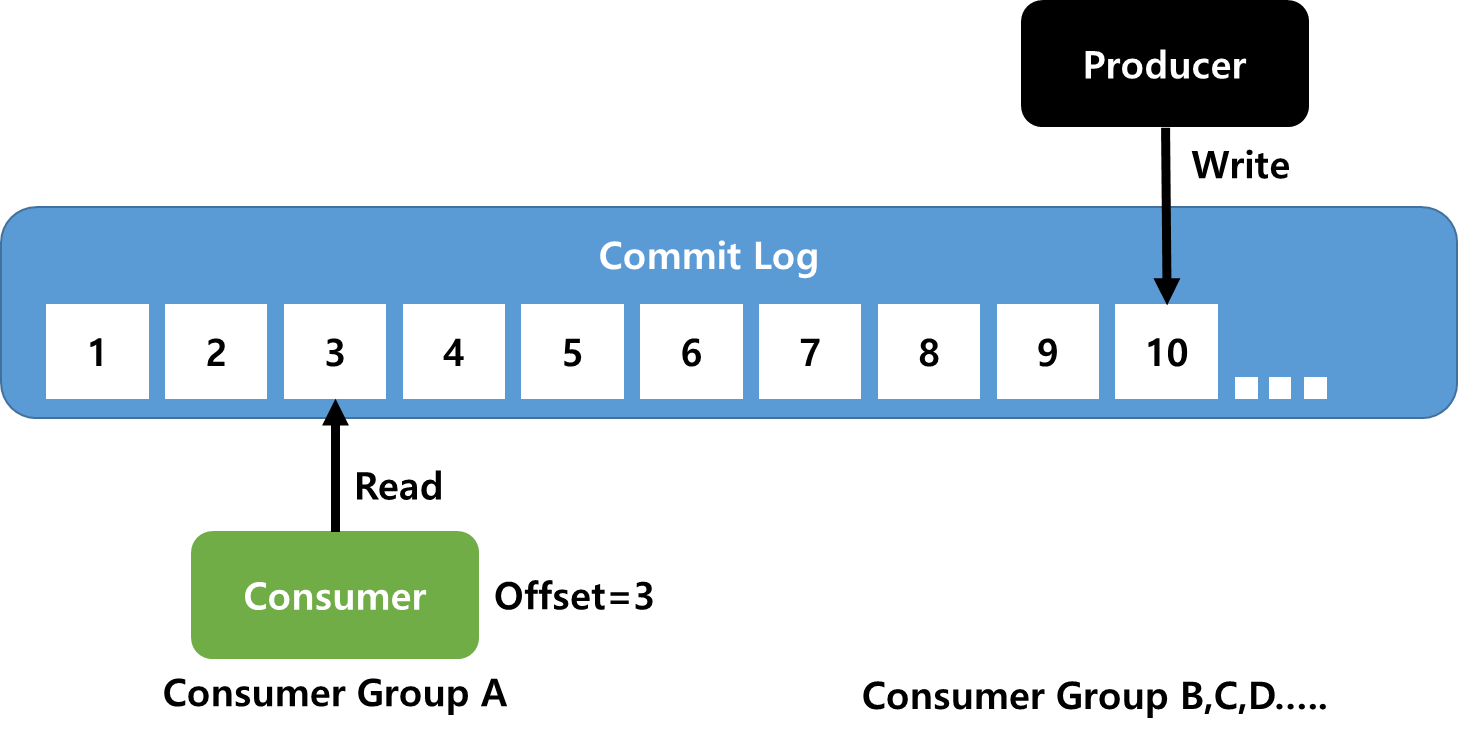
Producer와 Consumer 동작 원리
Commit Log: Consumer와 Producer가 Commit Log에 Read(읽기)/Write(쓰기)를 수행한다. 중요한점은 Consumer는 Producer가 어떤 토픽을 발행했는지, Producer는 Consumer가 어떤 토픽을 폴링했는지 모른다. 그저 각각의 속도로 Commit Log에 접근한다. 또한 다른 Consumer Group에 속해있는 Consumer들이 서로 아무런 관련이 없다.Offset: Consumer 마다 Offset을 설정한다. Offset이란 Consumer에서 메세지를 어디까지 읽었는지 저장하는 값이다. Offset=3이면, Offset 0,1,2는 메세지를 읽은 것으로 생각한다. 즉 현재 Offset은 3이고, 다음 읽을 메세지는 4이다.
-
Commit Log 데이터 스트럭쳐
- Commit Log는 추가만 가능하다. 변경은 불가능하다. 이벤트 데이터를 항상 Log 끝에 추가한다. 이 역시 변경되지 않는다. 계속 추가만 된다. 그 뜻은 Producer는 Commit Log의 젤 마지막(
LOG-END-OFFSET이라 부름)에 Write(쓰기)한다. Consumer Group에 Consumer가 Read(읽기)하고 Commit한 곳을CURRENT-OFFSET이라 부른다. 이 두개 OFFSET의 차이 (LOG-END-OFFSET과 CURRENT-OFFSET과)의 차이는Consumer Lag라 부른다. 한번 Write된 데이터(Message)는 변경이불가능(Emmutable)하다.
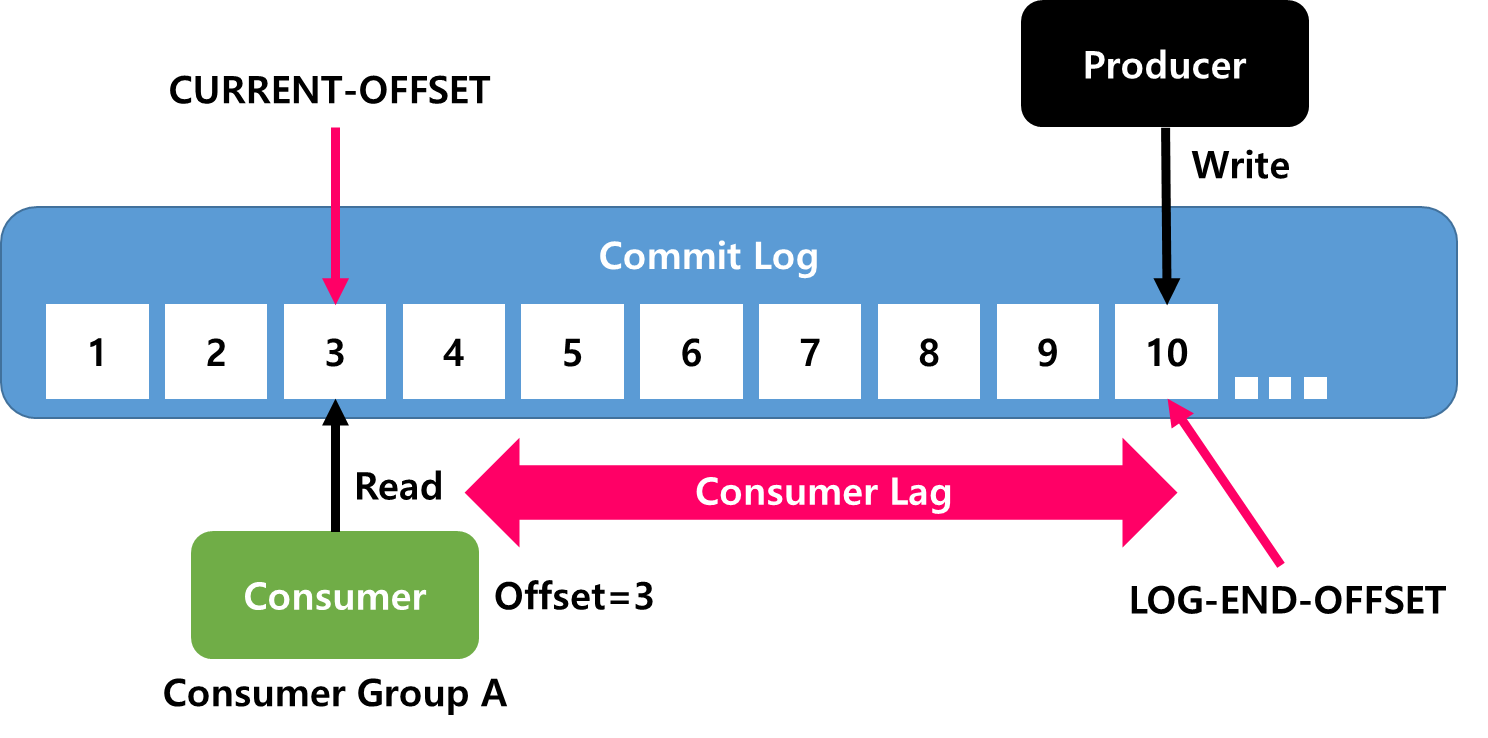
- Commit Log는 추가만 가능하다. 변경은 불가능하다. 이벤트 데이터를 항상 Log 끝에 추가한다. 이 역시 변경되지 않는다. 계속 추가만 된다. 그 뜻은 Producer는 Commit Log의 젤 마지막(
-
Topic, Partition, Segment
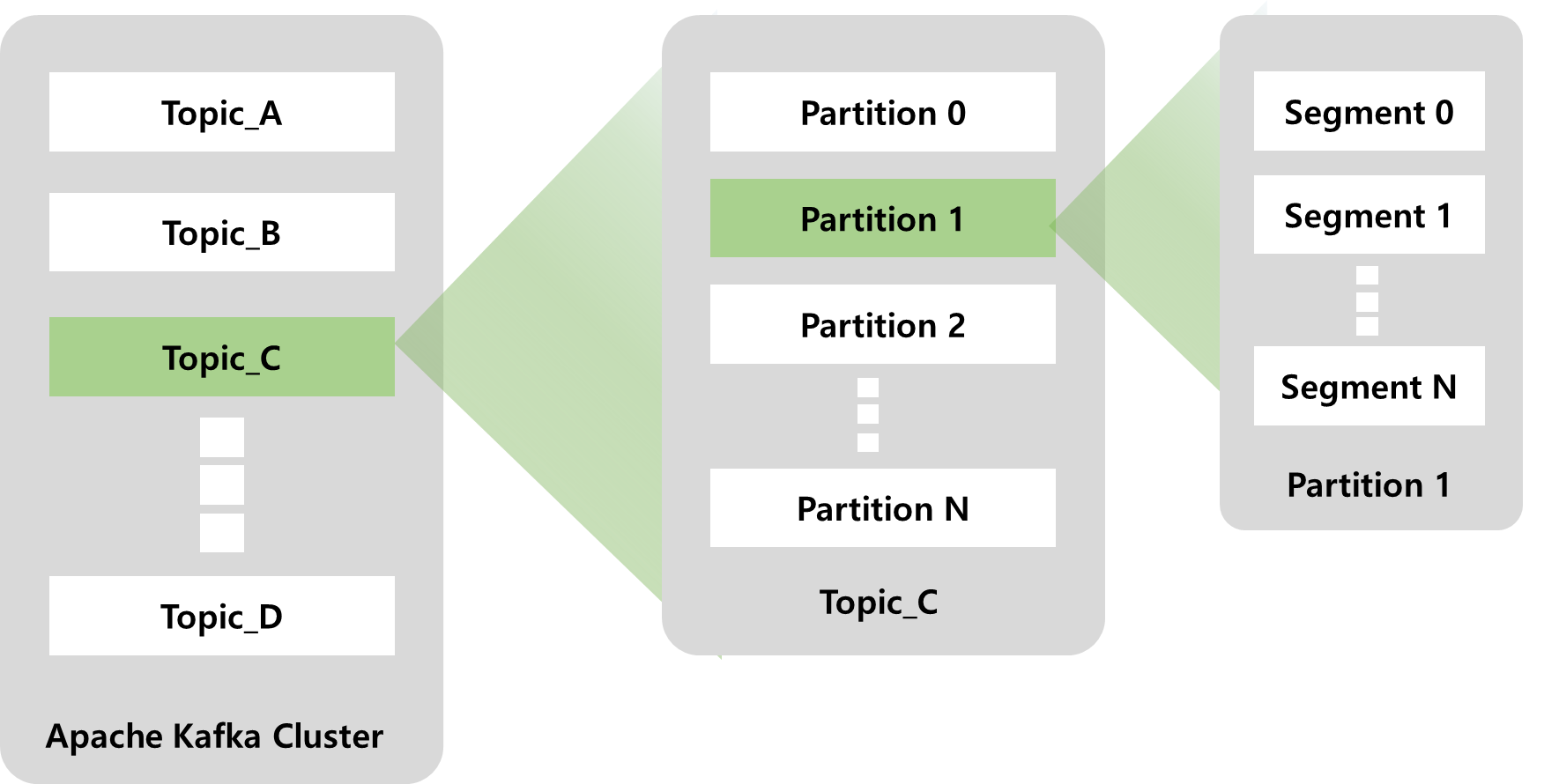
Partition: Topic 생성시에 Partition 개수를 지정한다(변경가능하나 운영시 변경권장X). Commit Log라고 생각하면 된다. Topic을 구성하는 컴포넌트 중 하나이다. 하나의 Topic은 한개 이상의 Partition으로 구성되어있다. 여러개의 Partition을 사용하는 이유는 병렬처리를 하기 위해서 인데 다수의 Partition을 사용해서 처리량을 높이기 위해 Multi형태의 Partition을 구성한다. Partition번호는 0부터 시작한다. Topic내 Partition은 서로 독립적이다. 따로 Write되고 Read된다. 그 뜻은 Partition 0 의 Offset 1과 Partition 1의 Offset 1과 다르다.Segment: Partition은 Segment라고 하는 실제 물리 파일 들로 구성되어있다. 즉 Partition 안에 한개 이상의 Segment들로 구성되어있다. 즉 실제 메세지 데이터가 저장되는 곳은 Segment이다. Segment File은 지정된 크기보다 커지거나 지정된 기간 보다 오래 사용하면 새로운 파일이 오픈되서 열리고 새로 열린 파일에서 메세지가 계속 추가되는 구조로 이루어져 있다.
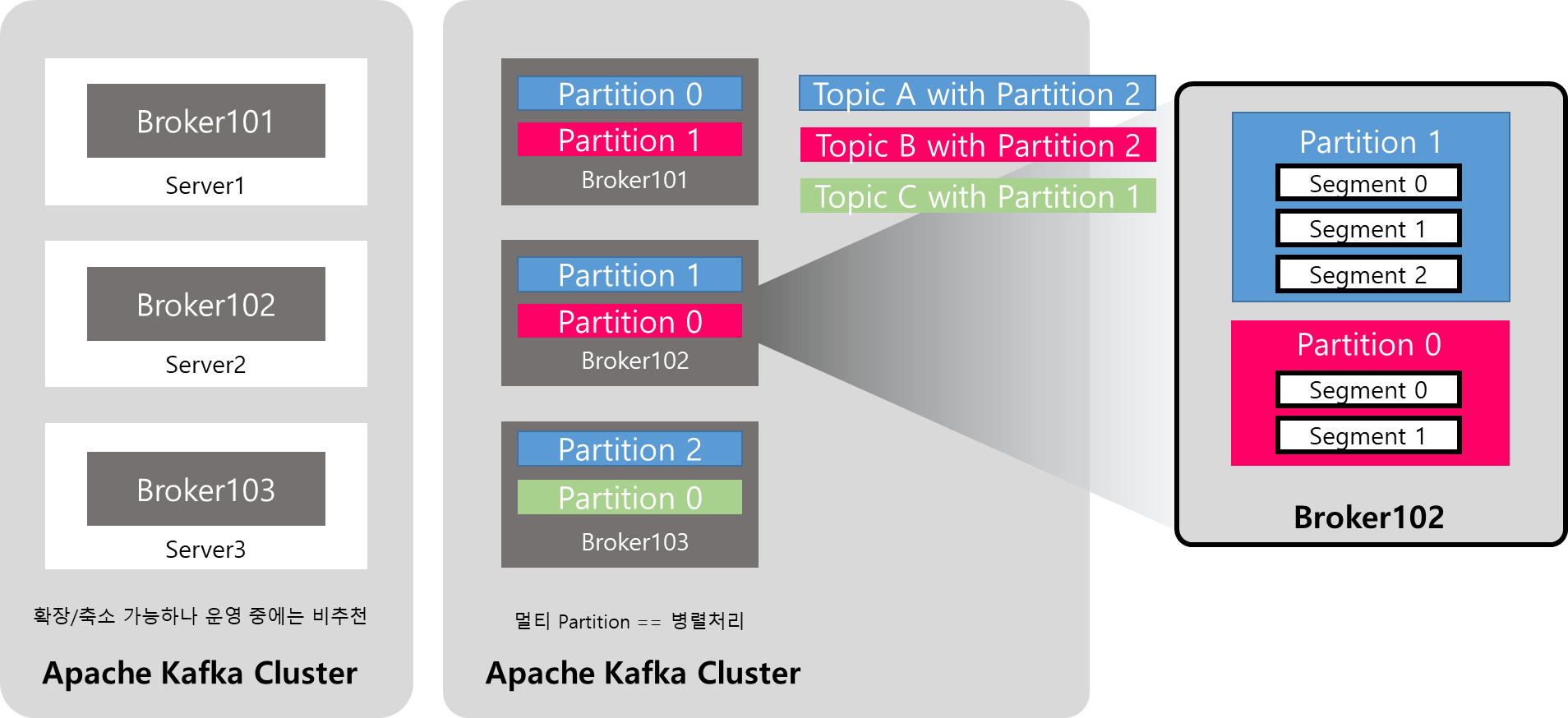
[Physical] Apache Kafka 주요 요소
- Physical 관점의 Topic, Partition, Segment
- 아파치 카프카 클러스터는 여러개의 브로커들로 구성되어있다. 이부분에서 확장과 축소가 가능하다.
- 토픽을 만드는데 3개의 파티션을 만든다면 이 3개가 각 브로커에 분산된다. 분산되는 방식은 브로커 클러스터 내에서 최적화하여 최적의 곳에 위치시킨다.
- 파티션0번 1번..N번 안에는 세그먼트들이 0번부터~N번까지 만들어져있다.
Rolling Strategy: 세그먼트 파일은 분리를 시켜 만드는데 하나의 시스템내에 10기가 파일로 할수는 없으니 세그먼트 파일은 용량을 정하거나 시간을 가지고 파일을 분리시켜 Rolling 하는 구조이다.예) log.segment.byte(default 1GB), log.roll.hours(default 168 hours)

IT업계에서 노설 이라는 이름이 보이면 그건 무조건 나.