IM Sprint
IM Sprint 시리즈는, 코드 스테이츠의 웹 개발 심화 코스인 Immersive 코스에서 수강생들과 함께 이야기 나눌 주제에 대해 빠르게 학습하고 정리한 글이다.
1. Linked List
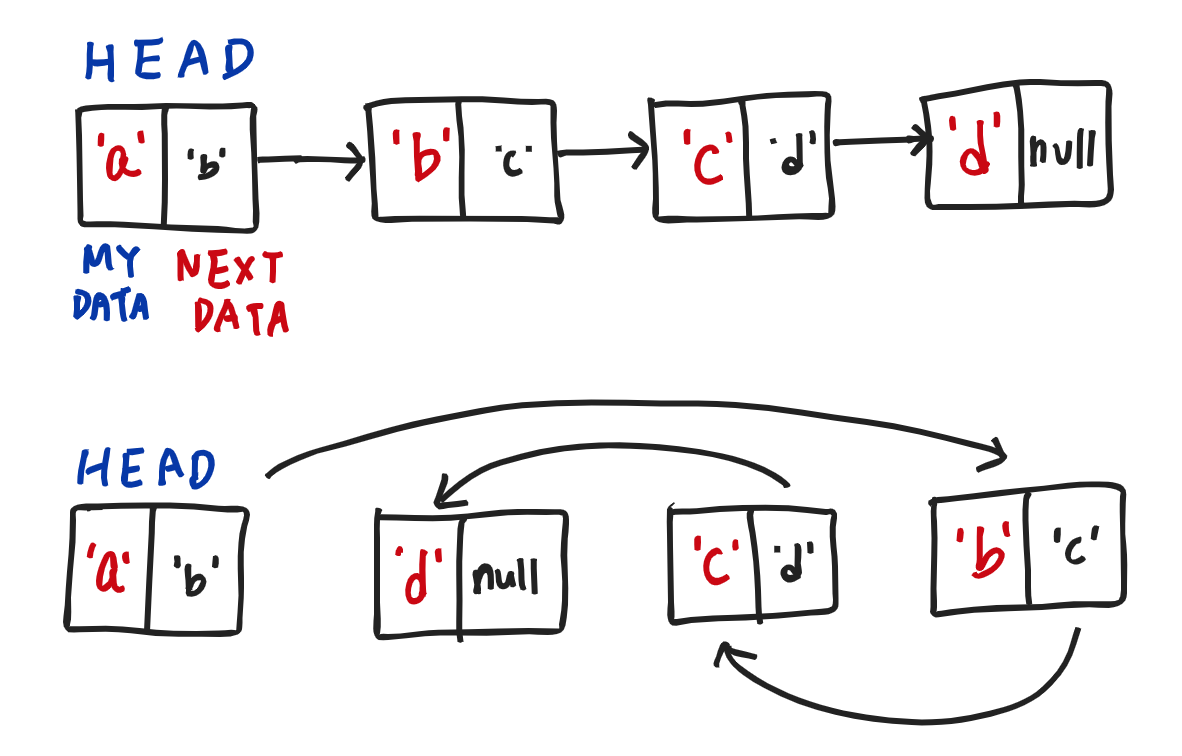
1. 데이터들이 선형적으로 이어져 있는 구조.
2. 하나의 노드는 데이터와 다음 노드가 위치한 주소를 가지고 있다.
3. 어떤 노드를 찾으려면, 무조건 HEAD에서 출발해야 한다.
4. HEAD에서 출발하여 HEAD의 데이터를 탐색 후, 찾는 데이터가 아니라면 HEAD가 가지고 있는 다음 노드 주소로 이동한다. 이동한 노드에서도 데이터를 탐색하고, 찾는 데이터가 아니라면 그 노드가 가지고 있는 다음 주소로 이동한다. 이 과정을 원하는 데이터를 찾을 때까지 반복한다.
장점
- 노드를 삽입하고 삭제하기 쉽다.
- 노드가 물리적으로 연속해서 저장되어 있을 필요가 없어서, 저장 효율이 좋다.
단점
- 검색 속도가 느리다.
Double linked list
양방향 링크드 리스트. 단방향 링크드 리스트와는 다르게, 자신의 앞과 뒤 노드가 위치한 주소를 모두 가지고 있다.
HEAD와 TAIL에서부터 검색할 수 있다.
Method
-
add()
노드 생성 시, 가장 마지막 노드가 어디인지 탐색 후 마지막 노드 다음에 새 노드를 만들어 붙인다.
새 노드에는 데이터값이, 새 노드의 하나 전 노드에는 새 노드의 주소값을 입력한다. -
remove()
노드 삭제 시, 삭제하려는 노드의 하나 전 노드가 가진 '다음 노드를 가르키는 주소값'을, 삭제하려는 노드의 다음 노드가 위치한 주소로 바꾼다.
Property
- data
노드가 가진 데이터. - pointer
노드의 다음 노드가 위치한 곳을 나타내는 주소. - head
가장 앞에 위치한 노드. - tail
가장 끝에 위치한 노드.
2. Graph
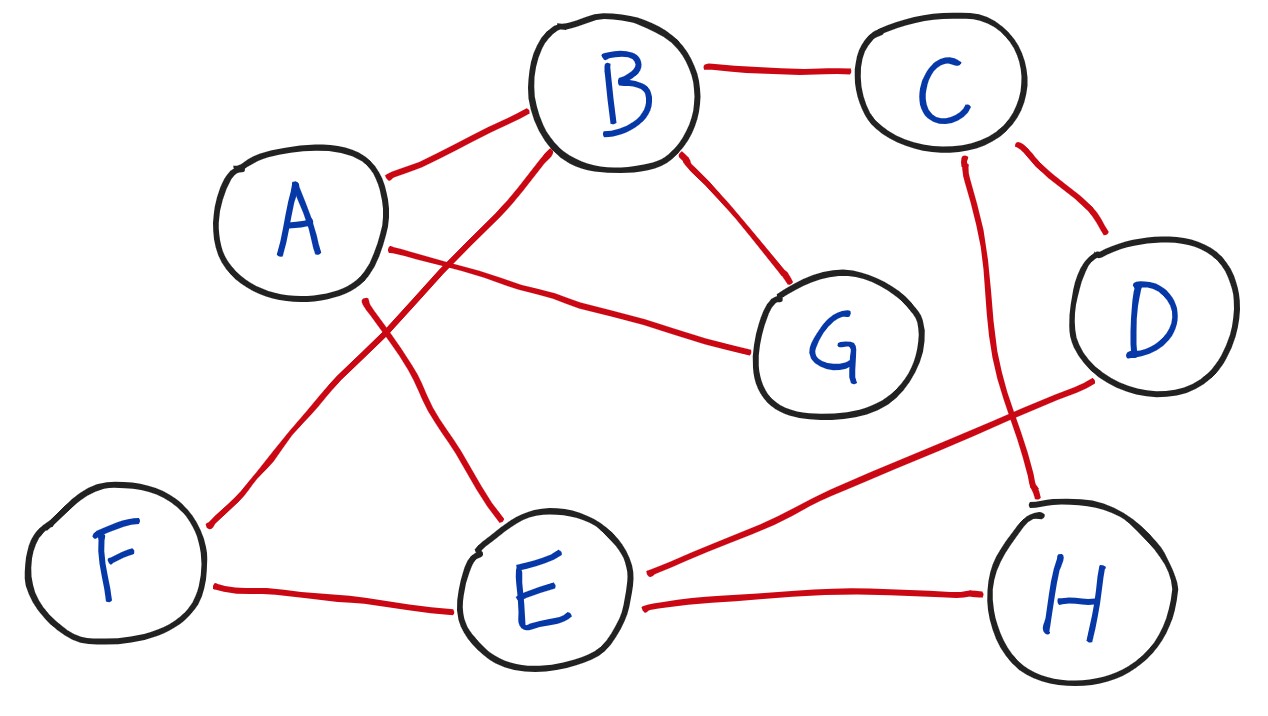
- 노드에 따라 다른 노드의 위치 정보를 가지고 있기도, 가지고 있지 않기도 한 구조.
- 그래프 구조를 탐색하는 방법에는 깊이 우선 탐색 Depth First Search / 넓이 우선 탐색법 Breath First Search 이 있다.
- 두 노드가 서로 양방향으로 이어진 경우와 단방향으로만 이어진 경우가 있다.
- 실제 생활에서 그래프 구조와 유사한 구조는 소셜 네트워크, 지하철 등.
Method
- addEdge()
노드와 다른 노드를 연결시킨다. - removeEdge()
노드와 다른 노드 사이의 연결을 해제한다. - hasPathDFS()
깊이 우선 탐색법. - hasPathBFS()
넓이 우선 탐색법
Property
- data
각 노드가 가진 데이터. - edge
다른 노드와 이어져 있는지 여부, 혹은 이어져있는 노드의 목록 - id
각 데이터가 가지고 있는 고유한 이름
3. Tree
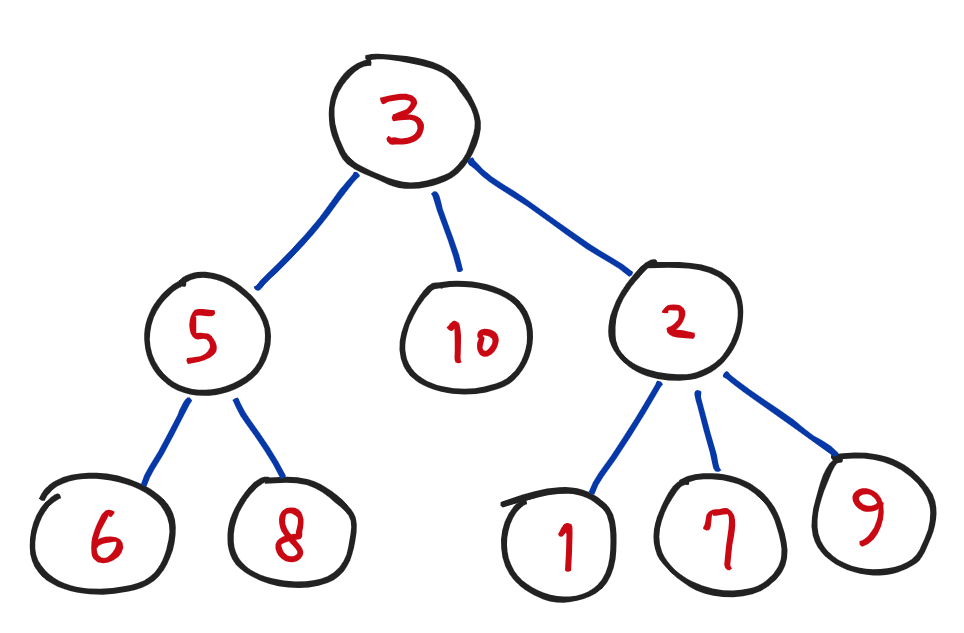
1. 맨 위에 하나의 노드가 있고, 그 노드를 부모 노드로 삼는 자식 노드, 그 노드들이 또 다른 자식 노드들을 가진 구조.
2. 자식 노드끼리는 이어져 있지 않다.
4. Binary Search Tree
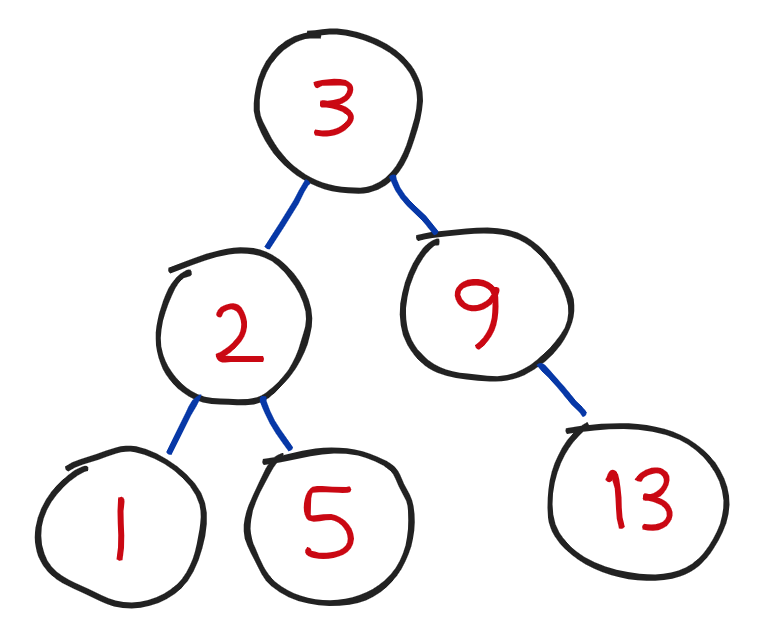
1. Binary tree는 하나의 노드가 자식 노드를 2개까지만 가진 구조이다.
2. Binary Tree인 구조가, 부모 노드보다 작은 값을 왼쪽 자식 노드에, 큰 값을 오른쪽 노드에 가진 구조라면 이를 Binary Search Tree라고 부른다.
Method
- find(원하는 숫자)
만약 첫 노드의 숫자가 원하는 숫자보다 크다면 왼쪽 노드로 이동. 반대의 경우 오른쪽 노드로 이동. 이동하여 계속 반복(이부분에서 재귀적으로 사용)한다. - insert(넣으려는 숫자)
넣으려는 숫자가 첫 노드의 숫자보다 크면 오른쪽 / 작으면 왼쪽으로 이동. 그 곳이 비었으면 그곳에 저장. 비지 않았다면, 거기에 위치한 노드의 숫자와 비교. 크다면 오른쪽 / 작으면 왼쪽으로 이동하여 계속 반복(이부분에서 재귀적으로 사용)한다. - print() :
왼쪽 → 중심노드 → 오른쪽 순으로 검색하는 경우. (in-order)
트리가 가진 모든 데이터를 보여준다. 왼쪽에 데이터가 있다면 왼쪽 역시 재귀적으로 함수를 호출해서 print()실행. 모든 프린팅이 끝나면, 중간에 위치한 데이터를 보여주고 오른쪽으로 이동해서 재귀적으로 print함수를 호출한다.
5. Hash Table
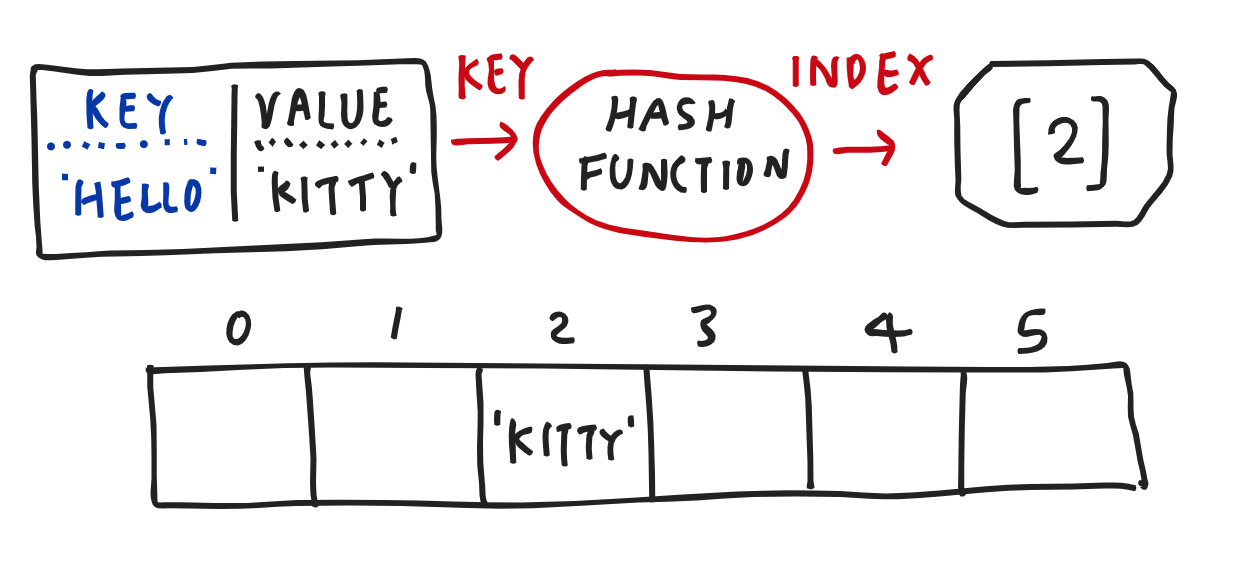
- 가장 유용하게 많이 쓰인다.
- 키와 값을 가지고 있다. key / value
- string → hash code(hash function) → index 순으로 값을 변경하여 넣을 곳을 파악한다.
- hash function은 a라는 string을 넣었을 때 항상 같은 인덱스값을 반환해야한다.
- 3번을 행할 때 서로 다른 string이 같은 index값을 가지는 경우가 나타날 수 있다. → collision/chaining
- 4번의 경우 만약 이미 존재하는 index값이 결과로 나오면, 링크드 리스트처럼 해당 index에 다른 장소의 주소값을 저장시킨다 → 인덱스 마다 링크드 리스트가 존재하는 구조로 생각할 수 있다.
- 그다음에 해당 값을 찾을때는, 중복된 인덱스에 가서 값을 찾고 없는 경우에 저장된 주소를 따라 가서 그곳에서 데이터를 찾아본다.
- 만약 정해진 크기의 배열 안이 가득 찼다면, 더 이상 값을 받지 않는다.
Method
- hashFunction('string')
'string'을 받아 약속된 index값을 반환하는 함수 - find()
어떤 key를 입력했을 때 값을 찾아 반환하는 함수. hashFunction을 이용하여 인덱스 값을 얻는다. - input()
어떤 key와 value를 입력했을 때 해시 테이블에 저장하는 함수. hashFunction을 이용하여 인덱스 값을 얻는다.
