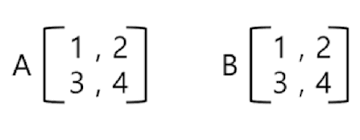
✖️ 행렬 곱셈
행렬 곱셈은 사회학부터 이학, 공학까지 학문을 가릴 것 없이 많이 사용되는 연산이다. 특히나 AI가 점점 모든 분야로 스며들고 있는 시대에, 딥러닝 계산에 핵심적인 요소가 바로 행렬 곱셈이다. 그렇다면 행렬 곱셈을 어떻게 빠르게 할까?
흔히들 행렬 곱셈을 구현하는 코드를 짜보라고 하면 다음과 같이 많이들 짤 것이다.
for i in range(n):
for j in range(n):
tmp = 0
for k in range(n):
tmp += A[i][k] * B[k][j]
C[i][j] = tmp누가 봐도 이해가 쉽다. 직관적인데다가 시간 복잡도를 계산해보면 O(n^3)으로 합리적으로 보인다.
그러나 더 좋은 방법이 존재한다...! 어떻게 하는 것일까. 지금부터 알아보자.
📚 사전지식1
우선 자바 코드가 실행되는 과정을 메모리 관점으로 살펴보자.
자바 소스가 컴파일을 거쳐 바이트 코드가 되었다고 가정하자.
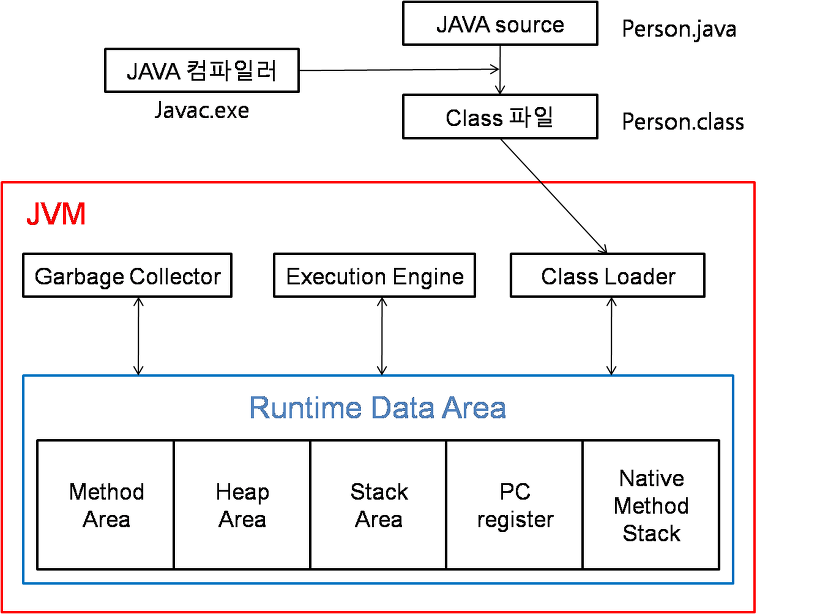
- 바이트 코드는 JVM의 class loader로 전달되고, 동적로딩 과정을 거쳐 필요한 클래스들을 load, link 과정을 통해 Runtime Data Area에 올린다. 이 때이 Runtime Data Area가 바로 JVM이 OS로부터 할당받은 메인메모리의 일부이다.
- 로컬 변수인 i,j,k는 Stack Area에 할당되고, array인 A,B,C 배열은 Heap Area에 할당된다.
- 반복문을 돌며 반복적으로 A배열, B배열, C배열에 접근하게 된다. 이때 A배열은 행 기준, B배열은 열 기준으로 접근한다.
📚 사전지식2
알고리즘에 대해 공부할 때에 가장 먼저 배우는 것이 Performance measure, 즉 복잡도 측정이다.
대부분의 경우 정확한 측정이 어렵기 때문에 대충 시간 복잡도 + 공간 복잡도로 퉁친다. 그러나 시간 복잡도 속에도 여러 요소가 있다.
Time complexity
시간 복잡도는 사실 다음과 같은 식으로 조금 더 구체화할 수 있다.
시간 복잡도 = 연산 횟수 + 외부 레코드 접근 횟수
여기서 외부 레코드 접근 횟수란 바로

이 과정에서 cache-memory-Disk 간의 데이터 이동 횟수를 뜻한다.
Disk는 용량 대비 가격이 싸고 비휘발성인 대신 읽기와 쓰기 속도가 느리다. 반면 CPU의 연산 속도를 비교불가하게 빠르다. 이런 병목현상 방지를 위해 우리는 Memory와 cache를 사용하게 된다. Memory와 cache 속도가 빠른 대신 용량이 비교적 작고, 컴퓨터 전원 공급이 멈추면, 동시에 모든 정보가 날아간다. 0,1의 데이터 쪼가리가 자기적 상태로 구분되기 때문이다.
그렇기에 데이터가 많은 disk에서 데이터가 상대적으로 적은 memory와 cache에 정보를 가져올 때 적당한 정보를 택해서 캐싱해와야한다.
이 때 '적당한 정보'를 택할때 운영체제는 공간적 지역성(Spatial locality)과 시간적 지역성(Temporal locality)을 고려해서 가져온다.
공간적 지역성 : 최근 접근한 데이터의 주변 공간에 다시 접근하는 경향성
시간적 지역성 : 최근 접근한 데이터에 다시 접근하는 경향성
여기서 공간적 지역성에 주목해보자.
같은 2차원 배열을 읽더라도 열별로 읽고 쓰는 것과 행별로 읽고 쓰는 것이 속도 차이가 발생하게 되는 것이다...!
🥊 개선된 행렬곱 코드
for k in range(n):
for i in range(n):
tmp = A[i][k]
for j in range(n):
C[i][j] += B[k][j] * tmp앞선 코드와는 다르게 A,B 배열에 접근하는 방식이 차이가 난다.
이제 이 코드를 kij loop, 앞선 코드를 ijk loop라고 하자.
kij에서는 ijk와 다르게
- A배열의 원소 하나를 tmp에 넣는다.
- B배열의 행 순서대로(j loop) 곱해주고 C배열에도 B배열과 마찬가지로 행 순서대로 누적 저장해준다.
- A배열의 같은 열의 다음 행 요소로 이동하거나(i loop), 마지막 행까지 도달하면 다음 열의 첫 행 요소로 이동한다(k loop).
- 마지막 요소까지 1~3을 반복한다.
kij 식으로 곱셈을 진행한다면 비용 한계에서 비롯한 유한한 캐시 사이즈를 공간적 지역성을 만족하면서 코드가 진행한다.
ijk loop 에서는 B배열에서 k loop으로 열을 뛰어넘는 과정에서 행 크기만큼의 캐싱이 반복된다. 이 때 바로 캐시의 낭비가 발생한다.
kij에서는 B배열에서 행으로 이동하기 때문에(j loop) 한 번 캐싱을 했을 때 최대한 활용하고 다음 열로 넘어간다.
만약 n의 크기가 충분히 커진다면 두 코드 간의 효율성 차이는 극대화될 것임이 분명해보인다.
구글링을 통해 알아본 바로는 worst case인 jki loop과 kij loop의 속도 차이가 n의 크기가 충분히 크다면 40배까지도 차이가 난다고 한다.(ijk 보다도 느린 jki loop)
📒 마치며
사실 행렬 곱셈은 슈트라센 알고리즘이나 위노그라드 알고리즘을 사용한다면, 캐싱에 대한 고려 없이도 시간 복잡도 자체를 O(n^2.8) 언저리로 낮추는 것이 가능하다.
그러나 이 포스팅에서 다룬 캐싱의 이해도 자체는 비단 행렬 곱셈 알고리즘에 국한 되는 것이 아니라 서버 개발 등의 분야에서도 고려되야 할 사항이 분명해보인다.
더 생각하는 개발자가 되기 위해서 오늘도 정진해야겠다.
