Crawling
데이터 3가지 종류
정형 비정형 반정형
정형 - 텍스트
비정형 - 이미지, 음성
반정형 - json형태
회사에선 크롤링 잘 안함 -> 최근에는 크롤링해 가면 서버 느려지니
회원가입 해서 api제공형태
BeautifulSoup 쓰는 회사 몇있다 함
<크롤링 설치 라이브러리>
- 라이브러리 설치
pip install beautifulsoup4
pip install selenium
pip install requests -> web 페이지 정보 가져오기pipy -> pip 관련 라이브러리 모음
- 호환성 확인
google -> "pypi beautifulsoup4"
굳이 이렇게 하는 이유? -> 버전 때문에
생성형 ai 쓰기 위한 파이썬 버전-> 3.11
citivitai.com-> 이미지 다운
https://civitai.com/
- 네이버 지식인
https://kin.naver.com/search/list.nhn?query=강아지&page=6
[강아지 검색결과 : 지식iN](https://kin.naver.com/search/list.nhn?
query=%EA%B0%95%EC%95%84%EC%A7%80&page=6)실제로는 fstring 사용해서 링크와 파라미터 넣는다.
https://kin.naver.com/search/list.nhn?query=%EA%B0%95%EC%95%84%EC%A7%80
->url 인코딩 해주는 이유? ->
(1) 웹에 접근방식
http: 암호화(X)
https: 암호화(O)
클라우드플레어 -> 터널
(2)인터넷주소
https://www.naver.com
https:www.naver.com
이 두개 차이?
그냥 멋있어서 보여서 넣은거 그차이일 뿐..
(3) ? 이후 => 파라미터
? 이후부터 변수
& 변수와 변수 사이를 분리
?query=강아지&page=6
query="강아지"
page=6
팔란티어 회사 전세계에서 온톨로지 제일 잘 함
ontology = 데이터란 무엇인가 부터 들어감
import csv
from re import search
import requests
from bs4 import BeautifulSoup
from urllib.parse import quote_plus
searchList = []
search = input('검색어를 입력하세요 : ')
print("search =", search)
url = f'https://kin.naver.com/search/list.nhn?query={quote_plus(search)}'
print('url =', url)
response = requests.get(url)
print(response)
print(response.text)
html = response.text # 응답 받은것중에 텍스트 파일(html)만 뽑는다.
soup = BeautifulSoup(html, 'html.parser')# 파싱하겠다.(필요한 정보만 뽑는것) 뷰티풀 수프 써서 해봤다 라고 답해야 함.
ul = soup.select_one('ul.basic1')# . 클래스를 의미 함
titles = ul.select('li > dl > dt > a')
for title in titles:
temp = []
temp.append(title.text)
temp.append(title.attrs['href'])
searchList.append(temp)
print(title.get_text())
else :
print(response.status_code)naver_crawl.py
import csv
from re import search
import requests
from bs4 import BeautifulSoup
from urllib.parse import quote_plus
searchList = []
search = input('검색어를 입력하세요 : ')
for i in range(1, 10):
url = f'https://kin.naver.com/search/list.nhn?query={quote_plus(search)}&page={i}'
response = requests.get(url)
if response.status_code == 200:
print( "============================ " + str(i) + " ============================" )
html = response.text
soup = BeautifulSoup(html, 'html.parser')
ul = soup.select_one('ul.basic1')
titles = ul.select('li > dl > dt > a')
for title in titles:
temp = []
temp.append(title.text)# 배열에다 배열을 넣을려면 append가 안됨 리스트 안에 리스트 넣는구조
temp.append(title.attrs['href'])
searchList.append(temp)
print(title.get_text())
else :
print(response.status_code)
### csv 파일로 저장
# newline = '' 한줄로 내리기
f = open(f'{search}.csv', 'w', encoding='cp949', newline='') # 인코딩 윈도우(?) 파일만든다.
csvWriter = csv.writer(f)# 파이썬에선 웹페이지를 pdf로 저장시키는 라이브러리 있어서 이래서 파이썬 쓴다. pip install pypdf
for i in searchList:# 반복문으로 돌려서 기록한다.
csvWriter.writerow(i)# 한줄씩
f.close() # 항상 닫아줘야 함크롤링결과
NAS
https://silverpencil.tistory.com/5
{
"Title":"Michael",
"Year":"2026",
"Rated":"PG-13",
"Released":"24 Apr 2026",
"Runtime":"127 min",
"Genre":"Biography, Drama, History",
"Director":"Antoine Fuqua",
"Writer":"John Logan",
"Actors":"Jaafar Jackson, Nia Long, Colman Domingo",
"Plot":"The early life of the famous musician Michael Jackson, known as the King of Pop.",
"Language":"English",
"Country":"United Kingdom, United States",
"Awards":"2 wins & 1 nomination total",
"Poster":"https://m.media-amazon.com/images/M/MV5BNzllNmRlN2EtMDQyOC00ODJjLTg4OWQtZDNmNGU3YzlkNjc1XkEyXkFqcGc@._V1_QL75_UX380_CR0,0,380,562_.jpg",
"Ratings1_Source":"Internet Movie Database",
"Ratings1_Value":"7.7/10",
"Ratings2_Source":"Metacritic",
"Ratings2_Value":"39/100",
"Metascore":"39",
"imdbRating":"7.7",
"imdbVotes":"54,397",
"imdbID":"tt11378946",
"Type":"movie",
"DVD":"N/A",
"BoxOffice":"$129,803,832",
"Production":"N/A",
"Website":"N/A",
"Response":"True"
}위 json 파일 형태의 테이블을 만드려고 하는데 아래와 같이 만들어줘.
- Django 의 models.py 에 들어가는 형태의 class 파일을 만들어줘.
- 테이블 명은 Movie로 테이블을 생성해줘.
from django.db import models
class Movie(models.Model):
title = models.CharField(max_length=255)
year = models.CharField(max_length=10)
rated = models.CharField(max_length=20, blank=True, null=True)
released = models.CharField(max_length=50, blank=True, null=True)
runtime = models.CharField(max_length=20, blank=True, null=True)
genre = models.CharField(max_length=255, blank=True, null=True)
director = models.CharField(max_length=255, blank=True, null=True)
writer = models.CharField(max_length=255, blank=True, null=True)
actors = models.TextField(blank=True, null=True)
plot = models.TextField(blank=True, null=True)
language = models.CharField(max_length=100, blank=True, null=True)
country = models.CharField(max_length=255, blank=True, null=True)
awards = models.CharField(max_length=255, blank=True, null=True)
poster = models.URLField(max_length=500, blank=True, null=True)
# Ratings
ratings1_source = models.CharField(max_length=100, blank=True, null=True)
ratings1_value = models.CharField(max_length=20, blank=True, null=True)
ratings2_source = models.CharField(max_length=100, blank=True, null=True)
ratings2_value = models.CharField(max_length=20, blank=True, null=True)
# Score fields
metascore = models.CharField(max_length=10, blank=True, null=True)
imdb_rating = models.CharField(max_length=10, blank=True, null=True)
imdb_votes = models.CharField(max_length=20, blank=True, null=True)
imdb_id = models.CharField(max_length=20, unique=True, blank=True, null=True)
# Metadata
type = models.CharField(max_length=20, blank=True, null=True)
dvd = models.CharField(max_length=50, blank=True, null=True)
box_office = models.CharField(max_length=50, blank=True, null=True)
production = models.CharField(max_length=255, blank=True, null=True)
website = models.URLField(max_length=500, blank=True, null=True)
response = models.BooleanField(default=True)
class Meta:
db_table = "movie"
def __str__(self):
return f"{self.title} ({self.year})"** 데이터베이스에 테이블 추가
python manage.py makemigrations
-> 에러있는지 없는지 확인해달라는 뜻
Migrations for 'webcrawl':
webcrawl\migrations\0001_initial.py
+ Create model Movie현재 에러가 없다는 뜻이다
(2) 생성
python manage.py migratemovie라는 테이블생성
오른쪽 표같은 아이콘 클릭함
postman
https://www.omdbapi.com/?i=tt3896198&apikey=ff49d469
____test 폴더내의
omdbapi_crawl.py
import requests
from datetime import datetime
API_KEY = "your_api_key"
BASE_URL = "https://www.omdbapi.com/"
# ── 방법 1: 현재 연도로 필터링 ──────────────────────────────
def get_by_current_year(keyword: str, media_type: str = "movie"):
current_year = datetime.now().year
params = {
"apikey": API_KEY,
"s": keyword,
"type": media_type,
"y": current_year,
"page": 1,
}
response = requests.get(BASE_URL, params=params)
data = response.json()
if data.get("Response") == "True":
return data["Search"] # 최대 10개
else:
print(f"오류: {data.get('Error')}")
return []
# ── 방법 2: 여러 연도 역순 순회하여 최신 10개 수집 ──────────
def get_latest_10(keyword: str = "the", media_type: str = "movie"):
current_year = datetime.now().year
results = []
for year in range(current_year, current_year - 4, -1): # 최근 4년 역순
if len(results) >= 10:
break
params = {
"apikey": API_KEY,
"s": keyword,
"type": media_type,
"y": year,
}
response = requests.get(BASE_URL, params=params)
data = response.json()
if data.get("Response") == "True":
results.extend(data["Search"])
return results[:10] # 상위 10개만 반환
# ── 방법 3: 클라이언트에서 연도 기준 정렬 ───────────────────
def get_sorted_by_year(keyword: str, media_type: str = "movie"):
params = {
"apikey": API_KEY,
"s": keyword,
"type": media_type,
}
response = requests.get(BASE_URL, params=params)
data = response.json()
if data.get("Response") != "True":
print(f"오류: {data.get('Error')}")
return []
# 연도 내림차순 정렬 후 10개 반환
sorted_results = sorted(
data["Search"],
key=lambda x: int(x["Year"].replace("–", "").strip()[:4]), # 시리즈 연도 처리
reverse=True,
)
return sorted_results[:10]
# ── 실행 예시 ────────────────────────────────────────────────
if __name__ == "__main__":
keyword = "spider"
print("=" * 40)
print("▶ 방법 1: 현재 연도 필터링")
for item in get_by_current_year(keyword):
print(f" [{item['Year']}] {item['Title']}")
print("=" * 40)
print("▶ 방법 2: 여러 연도 순회")
for item in get_latest_10(keyword):
print(f" [{item['Year']}] {item['Title']}")
print("=" * 40)
print("▶ 방법 3: 클라이언트 정렬")
for item in get_sorted_by_year(keyword):
print(f" [{item['Year']}] {item['Title']}")postman 입력결과
http://www.omdbapi.com/?s=movie&y=2026&apikey=[내 apikey]&page=2
"Search": [
{
"Title": "The Ron Movie: Hell and Uprise",
"Year": "2026",
"imdbID": "tt27629335",
"Type": "movie",
"Poster": "https://m.media-amazon.com/images/M/MV5BODZiMDJiZjAtZWQyZS00Yzg5LWJmNzAtYmQxZWIxNTkxNDE2XkEyXkFqcGdeQXVyMTYxNDQyMTIz._V1_SX300.jpg"
},
import requests
import requests
# api_key
apiKey = "ff49d469"
url = f"http://www.omdbapi.com/?s=movie&y=2026&apikey={apiKey}&page=1"
response = requests.get(url)
print(response.text)
실행결과 이렇게 불러온다.
{
"Search": [
{
"Title": "The Super Mario Galaxy Movie",
"Year": "2026",
"imdbID": "tt28650488",
"Type": "movie",
"Poster": "https://m.media-amazon.com/images/M/MV5BMDg5MjRkNWEtYmU1Mi00MTExLTk5MDQtY2RiMWVkZWNiOThjXkEyXkFqcGc@._V1_QL75_UX380_CR0,20,380,562_.jpg"
},
{
"Title": "Pizza Movie",
"Year": "2026",
"imdbID": "tt37209937",
"Type": "movie",
"Poster": "https://m.media-amazon.com/images/M/MV5BODQxYzE1NDQtOGQ2Zi00YWQ2LTgwMTktODM5YTk4ODI5MTYzXkEyXkFqcGc@._V1_QL75_UX380_CR0,0,380,562_.jpg"
},
{
"Title": "A Super Progressive Movie",
"Year": "2026",
"imdbID": "tt39045499",
"Type": "movie",
"Poster": "https://m.media-amazon.com/images/M/MV5BYjdiNDg2ZDAtMDljOS00ODU2LTlmNzUtYjZkZGI4ZjNiOTJmXkEyXkFqcGc@._V1_SX300.jpg"
},
{
"Title": "That Time I Got Reincarnated as a Slime the Movie: Tears of the Azure Sea",
"Year": "2026",
"imdbID": "tt38650409",
"Type": "movie",
"Poster": "https://m.media-amazon.com/images/M/MV5BYzdlYTUxMTgtNTAyYi00ZjcwLWIzOTctOTU0MTQzNjIwOTYyXkEyXkFqcGc@._V1_QL75_UY562_CR9,0,380,562_.jpg"
},
{
"Title": "Kidz Bop Live: The Concert Movie",
"Year": "2026",
"imdbID": "tt38789287",
"Type": "movie",
"Poster": "https://m.media-amazon.com/images/M/MV5BMTIwZDU1YWEtODdhMy00NzI3LTg1Y2UtNDRlMDlmNzZmMjIxXkEyXkFqcGc@._V1_SX300.jpg"
},
{
"Title": "Student Film: The Movie",
"Year": "2026",
"imdbID": "tt39524680",
"Type": "movie",
"Poster": "https://m.media-amazon.com/images/M/MV5BZWU1NTBjNWItOTViNi00ZDhiLWE2ZTQtMDdiYjhhMzkzZGI3XkEyXkFqcGc@._V1_SX300.jpg"
},
{
"Title": "The Christmas Rescue: A Big Movie",
"Year": "2026",
"imdbID": "tt39555288",
"Type": "movie",
"Poster": "https://m.media-amazon.com/images/M/MV5BZTExYTc4MGItMjM5Yi00NmMwLThlOTgtNmJjZjFiYjUzNmY3XkEyXkFqcGc@._V1_SX300.jpg"
},
{
"Title": "GoGo Dino the Movie: Insect World Adventure",
"Year": "2026",
"imdbID": "tt39636939",
"Type": "movie",
"Poster": "N/A"
},
{
"Title": "Minecraft Movie Edition",
"Year": "2026",
"imdbID": "tt39798962",
"Type": "movie",
"Poster": "https://m.media-amazon.com/images/M/MV5BODc5NjI3YWUtZmEyOC00NzRhLTlkNjktODcyYzM4ZjEyZWE2XkEyXkFqcGc@._V1_SX300.jpg"
},
{
"Title": "The Charlotte in Multilink World Movie",
"Year": "2026",
"imdbID": "tt23040026",
"Type": "movie",
"Poster": "https://m.media-amazon.com/images/M/MV5BNzc0MzRhNzQtMWMyNi00OTBiLTk3MTItY2Q1YmMyZDUwMmZjXkEyXkFqcGdeQXVyNzA0MzIxOTc@._V1_SX300.jpg"
}
],
"totalResults": "41",
"Response": "True"
}<영화정보 리스트>
http://www.omdbapi.com/?s=movie&y=2026&apikey=ff49d469&page=2
<영화 상세정보>
영화 정보 최근 10개
검색어 입력 창, 검색 버튼, 저장버튼
(디비에 저장 시키고 각 영화 카드밑에 하나씩)
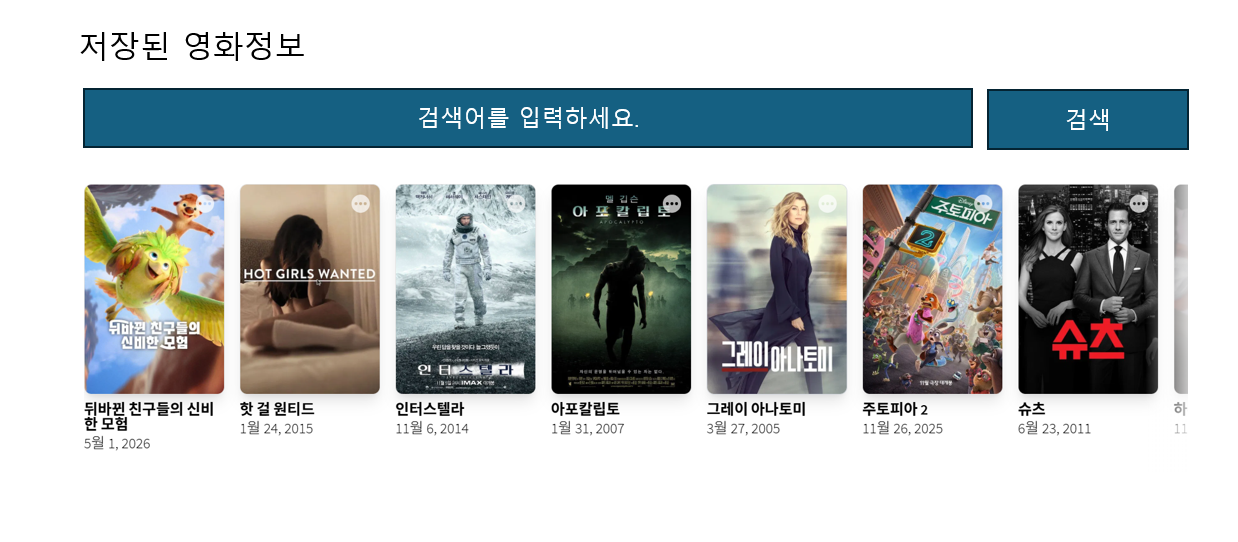
첨부파일과 비슷한 구조의 화면을 설계하려고 하는데 아래와 같이 작성해줘.
- html 파일로 제작하되, Tailwindcss, SweetAlert2을 사용해서 제작해줘.
- 디자인은 https://www.naver.com 을 참조해서 디자인을 작업해줘.
- 상단메뉴는 왼쪽에는 "로고", 오른쪽은 "로그아웃" 으로 구성해줘.
- 왼쪽메뉴는 "영화 API 검색", "저장 영화 보기"으로 구성해줘.
- 오른쪽 콘텐츠 부분에 첨부파일의 디자인 내용을 배치해줘.
html 연동
/webcrawl/views.py
** 서버 실행
python manage.py runserver
장고 = abc 데이터 값을 검색어 "abc"로 넣고 싶다.
urls.py movie_search.html 순
from django.urls import path
from . import views
urlpatterns = [
path('', views.movie_search, name='movie_search'),
]views.py
from django.shortcuts import render
# Create your views here.
from django.http import HttpResponse
def movie_search(request):
sendData = {
"searchKeyword" : "abc"
}
return render(request, "webcrawl/movie_search.html", sendData)
# return HttpResponse("안녕하세요. webcdrawl 페이지 입니다.") # Http 응답을 보낸다는 뜻movie_search.html
<!-- 검색창 -->
<div class="search-wrap">
<input
class="search-input"
id="search-input"
type="text"
placeholder="검색어를 입력하세요."
onkeydown="if(event.key==='Enter') doSearch()"
value="{{searchKeyword}}"
/>
<button class="btn-search" onclick="doSearch()">검색</button>
<button class="btn-search" onclick="">전체검색</button>
</div>"전체검색" -> Django views -> 프로그램 -> "html에 전송"
all_serach/ api 전체검색 전송
urls.py
from django.urls import path
from . import views
urlpatterns = [
path('', views.movie_search, name='movie_search'),
path('all_search/', views.movie_all_search, name='movie_all_search'),
]views.py
from django.shortcuts import render
# Create your views here.
from django.http import HttpResponse
import requests
import json
apiKey = "ff49d469"
def movie_search(request):
sendData = {
"searchKeyword" : "abc"
}
return render(request, "webcrawl/movie_search.html", sendData)
# return HttpResponse("안녕하세요. webcdrawl 페이지 입니다.") # Http 응답을 보낸다는 뜻
def movie_all_search(request):
print("func movie_all_search")
# AI 프로그램, 데이터베이스 처리 되는 루틴
url = f"https://www.omdbapi.com/?s=movie&y=2026&apikey={apiKey}"
response = requests.get(url)
# 딕셔너리 변경 response.text
data = json.loads(response.text)
print(data)
return HttpResponse("func movie_all_search")movie_search.html
<a href="/webcrawl/all_search/" class="btn-search">전체검색</a>Django Template Language
{% for item in item_list %} <p>{{ item }}</p> {% endfor %}all_Search 할경우 어벤져스 10개가 나오게 됨
{% for data in Search %}
<div class="movie-card">
<div class="poster-wrap"><img src="https://m.media-amazon.com/images/M/MV5BMTc5MDE2ODcwNV5BMl5BanBnXkFtZTgwMzI2NzQ2NzM@._V1_SX300.jpg" alt="어벤져스: 엔드게임" onerror="this.parentElement.innerHTML=placeholderHTML()"></div>
<div class="card-body">
<div class="card-title">어벤져스: 엔드게임</div>
<div class="card-date">4월 26, 2019</div>
</div>
<button class="btn-save" style="" onclick="saveMovie({"id":"tt0816692b","title":"어벤져스: 엔드게임","year":"2019","poster":"https://m.media-amazon.com/images/M/MV5BMTc5MDE2ODcwNV5BMl5BanBnXkFtZTgwMzI2NzQ2NzM@._V1_SX300.jpg","date":"4월 26, 2019"}, this)">
저장
</button>
</div>
{% endfor %}title도 제대로 나오게 수정
{% for data in Search %}
<div class="movie-card">
<div class="poster-wrap"><img src="{{data.Poster}}" alt="어벤져스: 엔드게임" onerror="this.parentElement.innerHTML=placeholderHTML()"></div>
<div class="card-body">
<div class="card-title">{{data.Title}}</div>
<div class="card-date">4월 26, 2019</div>
</div>
<button class="btn-save" style="" onclick="saveMovie({"id":"tt0816692b","title":"어벤져스: 엔드게임","year":"2019","poster":"https://m.media-amazon.com/images/M/MV5BMTc5MDE2ODcwNV5BMl5BanBnXkFtZTgwMzI2NzQ2NzM@._V1_SX300.jpg","date":"4월 26, 2019"}, this)">
저장
</button>
</div>
{% endfor %}날짜도 제대로 되게 수정
{% for data in Search %}
<div class="movie-card">
<div class="poster-wrap"><img src="{{data.Poster}}" alt="어벤져스: 엔드게임" onerror="this.parentElement.innerHTML=placeholderHTML()"></div>
<div class="card-body">
<div class="card-title">{{data.Title}}</div>
<div class="card-date">{{data.Year}}</div>
</div>
<button class="btn-save" style="" onclick="saveMovie({"id":"tt0816692b","title":"어벤져스: 엔드게임","year":"2019","poster":"https://m.media-amazon.com/images/M/MV5BMTc5MDE2ODcwNV5BMl5BanBnXkFtZTgwMzI2NzQ2NzM@._V1_SX300.jpg","date":"4월 26, 2019"}, this)">
저장
</button>
</div>
{% endfor %}
"검색" -> "form" ->
전달된 값을 받을때
request.GET.get('query', 'default_value')
request.POST.get('query', 'default_value')
<!-- 검색창 -->
<form action="/webcrawl/qry_search/" method="get" >
<div class="search-wrap">
<input
class="search-input"
id="search-input"
type="text"
placeholder="검색어를 입력하세요."
onkeydown="if(event.key==='Enter') doSearch()"
value="{{searchKeyword}}"
/>
<button class="btn-search" onclick="doSearch()">검색</button>
<a href="/webcrawl/all_search/" class="btn-search">전체검색</a>
</div>
</form>form으로 감싸면 입력된 값을 보낸다.
버튼타입 변경등
<!-- 검색창 -->
<form action="/webcrawl/qry_search/" method="get" >
<div class="search-wrap">
<input
name="qry"
class="search-input"
id="search-input"
type="text"
placeholder="검색어를 입력하세요."
onkeydown="if(event.key==='Enter') doSearch()"
value="{{searchKeyword}}"
/>
<button type="submit" class="btn-search">검색</button>
<a href="/webcrawl/all_search/" class="btn-search">전체검색</a>
</div>
</form>post 방식 변경
csrf 에러가 뜸
csrf 란? -> CSRF(Cross-Site Request Forgery, 사이트 간 요청 위조)는 인증된 사용자가 자신의 의지와 무관하게 공격자가 의도한 행동(비밀번호 변경, 송금, 데이터 수정/삭제 등)을 웹 애플리케이션에 요청하게 만드는 보안 취약점입니다.
왜 갑자기 post로 바꾸니 에러가 뜰까?
-> post는 데이터 기록 get은 기록안한다.
데이터의 기록을 방지하기 위해 뜬다고 한다.
