<Django + Database 연동>
** 빠르게 프로토타입을 제작하는 프레임워크
- Gradio
- StreamLit
google - "gradio"
https://www.gradio.app/
pip install gradiochatbot.py
import gradio as gr
def load():
return [
{"role": "user", "content": "Can you show me some media?"},
{"role": "assistant", "content": "Here's an audio clip:"},
{"role": "assistant", "content": gr.Audio("https://github.com/gradio-app/gradio/raw/main/gradio/media_assets/audio/audio_sample.wav")},
{"role": "assistant", "content": "And here's a video:"},
{"role": "assistant", "content": gr.Video("https://github.com/gradio-app/gradio/raw/main/gradio/media_assets/videos/world.mp4")}
]
with gr.Blocks() as demo:
chatbot = gr.Chatbot()
button = gr.Button("Load audio and video")
button.click(load, None, chatbot)
demo.launch()에러나면 이 페이지로 접속
http://127.0.0.1:7860/
![[Pasted image 20260511103140.png]]
https://www.gradio.app/guides/creating-a-chatbot-fast
하나하나 살을 붙여서 개발 하는 형태
google -> "Streamlit"
https://streamlit.io/
영화 검색
- 프로젝트 실행
python manage.py runserver 0.0.0.0:포트 - 검색부분부터 이어서 하기
movie_qry_search에 그대로
def movie_qry_search(request):
print("func movie_qry_search")
qry = request.GET.get('qry', '')
print('qry =', qry)
# AI 프로그램, 데이터베이스 처리 되는 루틴
url = f"http://www.omdbapi.com/?s=movie&y=2026&apikey={apiKey}&page=1"
response = requests.get(url)
# 딕셔너리 변경 response.text
data = json.loads(response.text)
print(data)
# all_search 으로 이동
return render(request, "webcrawl/movie_search.html", data)리팩토링한 메서드문
def movie_qry_search(request):
print("func movie_qry_search")
qry = request.GET.get('qry', '')
print('qry =', qry)
# AI 프로그램, 데이터베이스 처리 되는 루틴
# url = f"http://www.omdbapi.com/?s=movie&y=2026&apikey={apiKey}&page=1"# 원본 지우지 말자는 차원에서
url = f"http://www.omdbapi.com/?apikey={apiKey}&s={qry}"
response = requests.get(url)
# 딕셔너리 변경 response.text
data = json.loads(response.text)
print(data)
# all_search 으로 이동
return render(request, "webcrawl/movie_search.html", data)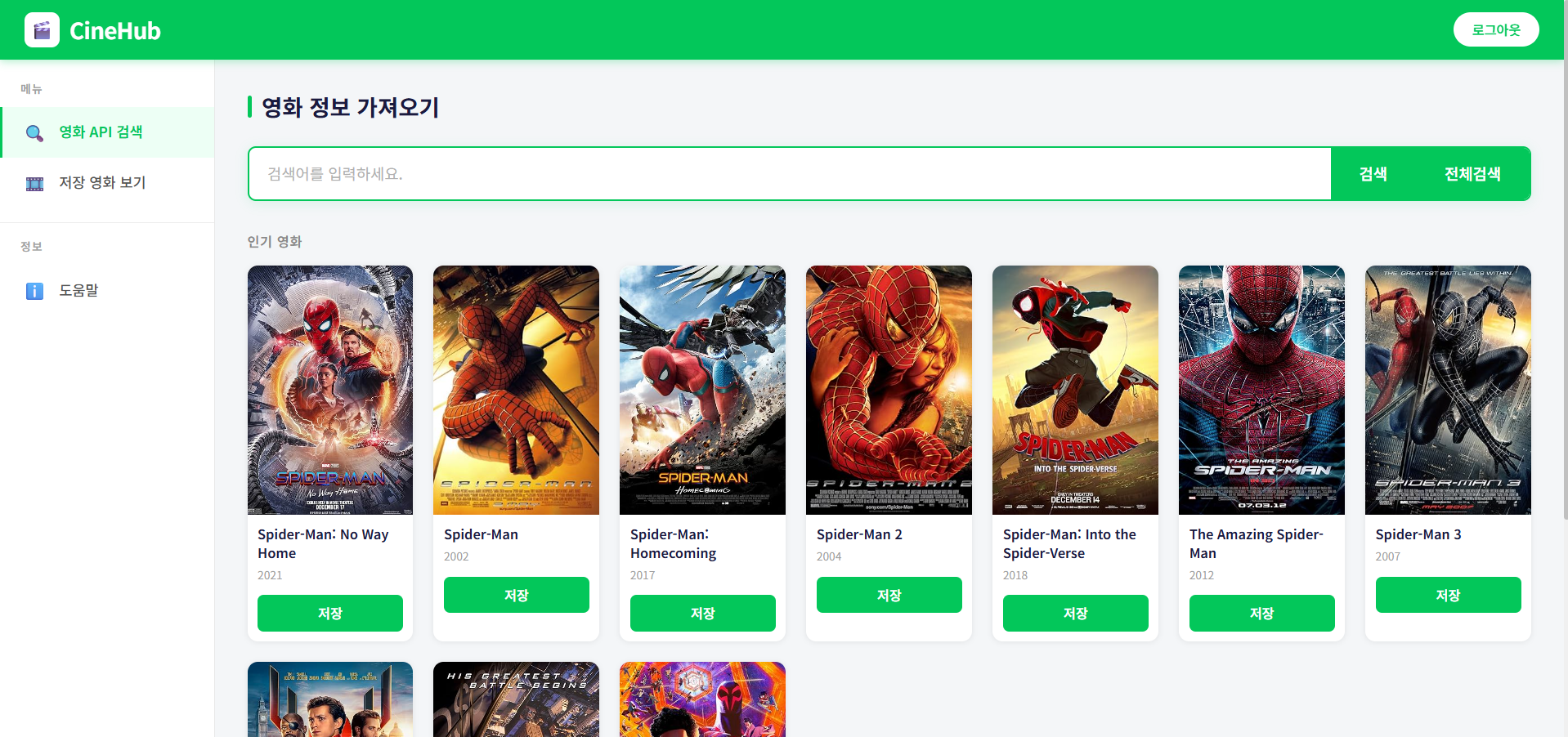
검색어까지 전달 할려면??
딕셔너리를 활용해서 할려면?
def movie_qry_search(request):
print("func movie_qry_search")
qry = request.GET.get('qry', '')
print('qry =', qry)
# AI 프로그램, 데이터베이스 처리 되는 루틴
# url = f"http://www.omdbapi.com/?s=movie&y=2026&apikey={apiKey}&page=1"
url = f"http://www.omdbapi.com/?apikey={apiKey}&s={qry}"
response = requests.get(url)
# 딕셔너리 변경 response.text
data = json.loads(response.text)
print(data)
sendData = {# 검색창에 인자 불러오기
"searchKeyword" : qry,
"qryData" : data
}
# all_search 으로 이동
return render(request, "webcrawl/movie_search.html", sendData)
이번엔 데이터가 안불러오는데..
{% for data in qryData.Search %}
<div class="movie-card">
<div class="poster-wrap"><img src="{{data.Poster}}" alt="어벤져스: 엔드게임" onerror="this.parentElement.innerHTML=placeholderHTML()"></div>
<div class="card-body">
<div class="card-title">{{data.Title}}</div>
<div class="card-date">{{data.Year}}</div>
</div>
<button class="btn-save" style="" onclick="saveMovie({"id":"tt0816692b","title":"어벤져스: 엔드게임","year":"2019","poster":"https://m.media-amazon.com/images/M/MV5BMTc5MDE2ODcwNV5BMl5BanBnXkFtZTgwMzI2NzQ2NzM@._V1_SX300.jpg","date":"4월 26, 2019"}, this)">
저장
</button>
</div>
{% endfor %}전체보기도 변경해줘야 함
sendData 로 변경및 서치 키워드 ""로 표기
def movie_all_search(request):
print("func movie_all_search")
# AI 프로그램, 데이터베이스 처리 되는 루틴
url = f"http://www.omdbapi.com/?s=movie&y=2026&apikey={apiKey}&page=1"
response = requests.get(url)
# 딕셔너리 변경 response.text
data = json.loads(response.text)
print(data)
sendData = {
"searchKeyword" : "",
"qryData" : data
}저장 기능
독립적인 데이터로 저장 imdbID라던가
{'Title': 'Spider-Man', 'Year': '2002', 'imdbID': 'tt0145487', 'Type': 'movie', 'Poster': 'https://m.media-amazon.com/images/M/MV5BZWM0OWVmNTEtNWVkOS00MzgyLTkyMzgtMmE2ZTZiNjY4MmFiXkEyXkFqcGc@._V1_SX300.jpg'}, {'Title': 'Spider-Man: Homecoming', 'Year': '2017', 'imdbID': 'tt2250912', 'Type': 리스트->상세정보->기초정보
여기서 form문쓰면 틀어짐 그래서 자바스크립트 활용
form문 블록형 문법-> 반복문안에 form메서드 입히면 될거 같긴한데 (404떴음)
통상적으로는 이렇게는 잘 안쓴다 하심
form문 으로 넘기기, url으로 넘기기 방법있다.
자바스크립트 활용하면 문제점?->호환성, 특정 서비스에서 안되는 문제
장고에서는->파라미터 값 url에 집어 넣을수 있음
면접 -> 생성형 ai 썼는지->클로드 소넷 4.6버전으로 무조건 했다 해라 그게 제일 많이 쓴다.
*테스트
http:localhost:8000/webcrawl/save_data
File "C:\Users\User\anaconda3\envs\p311_crawling\Lib\site-packages\django\urls\resolvers.py", line 277, in _route_to_regex
raise ImproperlyConfigured(
django.core.exceptions.ImproperlyConfigured: URL route 'save_data/<imdbId:str>/' uses invalid converter 'imdbId'.
imdbId 파라미터가 안들어와서 이러에러가 뜨는거임
http:localhost:8000/webcrawl/save_data/1234
(1) 경로에 파라미터 전달
http:localhost:8000/webcrawl/save_data/1234
(2) urls.py에 파라미터값에 변수명
(3) 함수에도 파라미터 변수명이 동일
메서드에 파라미터 imdbId 추가
def movie_save(request, imdbId):
print("movie_save")
print("imdbId =", imdbId)
return HttpResponse("movie_save")
로그 결과:
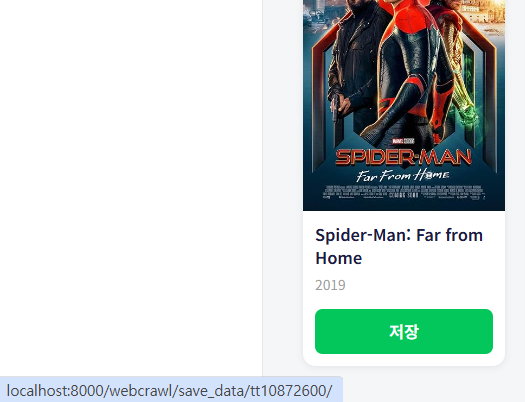
버튼도 a태그로 수정및 data.imdbID값 매핑
<a href="{% url 'movie_save' data.imdbID %}" class="btn-save">
저장
</a>이렇게 버튼마다 값 다름
{'Title': 'Spider-Man', 'Year': '2002', 'Rated': 'PG-13', 'Released': '03 May 2002', 'Runtime': '121 min', 'Genre': 'Action, Adventure, Sci-Fi', 'Director': 'Sam Raimi', 'Writer': 'Stan Lee, Steve Ditko, David Koepp', 'Actors': 'Tobey Maguire, Kirsten Dunst, Willem Dafoe', 'Plot': 'After being bitten by a genetically-modified spider, a shy teenager gains spider-like abilities that he uses to fight injustice as a masked superhero and face a vengeful enemy.', 'Language': 'English', 'Country': 'United States', 'Awards': 'Nominated for 2 Oscars. 17 wins & 65 nominations total', 'Poster': 'https://m.media-amazon.com/images/M/MV5BZWM0OWVmNTEtNWVkOS00MzgyLTkyMzgtMmE2ZTZiNjY4MmFiXkEyXkFqcGc@._V1_SX300.jpg', 'Ratings': [{'Source': 'Internet Movie Database', 'Value': '7.4/10'}, {'Source': 'Rotten Tomatoes', 'Value': '90%'}, {'Source': 'Metacritic', 'Value': '73/100'}], 'Metascore': '73', 'imdbRating': '7.4', 'imdbVotes': '958,249', 'imdbID': 'tt0145487', 'Type': 'movie', 'DVD': 'N/A', 'BoxOffice': '$408,524,875', 'Production': 'N/A', 'Website': 'N/A', 'Response': 'True'}
[11/May/2026 14:28:27] "GET /webcrawl/save_data/tt0145487/ HTTP/1.1" 200 10
C:\ai_exam\002_crawling\webcrawl\views.py changed, reloading.
Watching for file changes with StatReloader그럼 데이터베이스에 저장까지 할려면?
# 데이터베이스에서 저장 명칭 틀려서 오류나는 경우 많음, 명칭 동일하게 쓰면 오류 안남
title = models.CharField(max_length=255)
year = models.CharField(max_length=10)
rated = models.CharField(max_length=20, blank=True, null=True)
released = models.CharField(max_length=50, blank=True, null=True)
runtime = models.CharField(max_length=20, blank=True, null=True)
genre = models.CharField(max_length=255, blank=True, null=True)
director = models.CharField(max_length=255, blank=True, null=True)
writer = models.CharField(max_length=255, blank=True, null=True)
actors = models.TextField(blank=True, null=True)
plot = models.TextField(blank=True, null=True)
language = models.CharField(max_length=100, blank=True, null=True)
country = models.CharField(max_length=255, blank=True, null=True)
awards = models.CharField(max_length=255, blank=True, null=True)
poster = models.URLField(max_length=500, blank=True, null=True)
# Ratings
ratings1_source = models.CharField(max_length=100, blank=True, null=True)
ratings1_value = models.CharField(max_length=20, blank=True, null=True)
ratings2_source = models.CharField(max_length=100, blank=True, null=True)
ratings2_value = models.CharField(max_length=20, blank=True, null=True)
# Score fields
metascore = models.CharField(max_length=10, blank=True, null=True)
imdb_rating = models.CharField(max_length=10, blank=True, null=True)
imdb_votes = models.CharField(max_length=20, blank=True, null=True)
imdb_id = models.CharField(max_length=20, unique=True, blank=True, null=True)
# Metadata
type = models.CharField(max_length=20, blank=True, null=True)
dvd = models.CharField(max_length=50, blank=True, null=True)
box_office = models.CharField(max_length=50, blank=True, null=True)
production = models.CharField(max_length=255, blank=True, null=True)
website = models.URLField(max_length=500, blank=True, null=True)
response = models.BooleanField(default=True)def movie_save(request, imdbId):
print("movie_save")
print("imdbId =", imdbId)
# API에서 상세정보 가져오기.
url = f"http://www.omdbapi.com/?apikey={apiKey}&i={imdbId}"
response = requests.get(url)
# 딕셔너리 변경 response.text
data = json.loads(response.text)
print(data)
# 데이터베이스에서 저장
saveData = Movie()
saveData.title = data['Title']
saveData.year = data['Year']
saveData.rated = data['Rated']
saveData.released = data['Released']
saveData.runtime = data['Runtime']
saveData.genre = data['Genre']
saveData.director = data['Director']
saveData.writer = data['Writer']
saveData.actors = data['Actors']
saveData.plot = data['Plot']
saveData.language = data['Language']
saveData.country = data['Country']
saveData.awards = data['Awards']
saveData.poster = data['Poster']
# Ratings
saveData.ratings1_source = data['Ratings'][0]['Source']
saveData.ratings1_value = data['Ratings'][0]['Value']
saveData.ratings2_source = data['Ratings'][1]['Source']
saveData.ratings2_value = data['Ratings'][1]['Value']
# Score fields
saveData.metascore = data['Metascore']
saveData.imdb_rating = data['imdbRating']
saveData.imdb_votes = data['imdbVotes']
saveData.imdb_id = data['imdbID']
# Metadata
saveData.type = data['Type']
saveData.dvd = data['DVD']
saveData.box_office = data['BoxOffice']
saveData.production = data['Production']
saveData.website = data['Website']
saveData.response = data['Response']
# 저장
saveData.save()
return HttpResponse("movie_save")다만 중복 저장일땐 이렇게 뜬다.
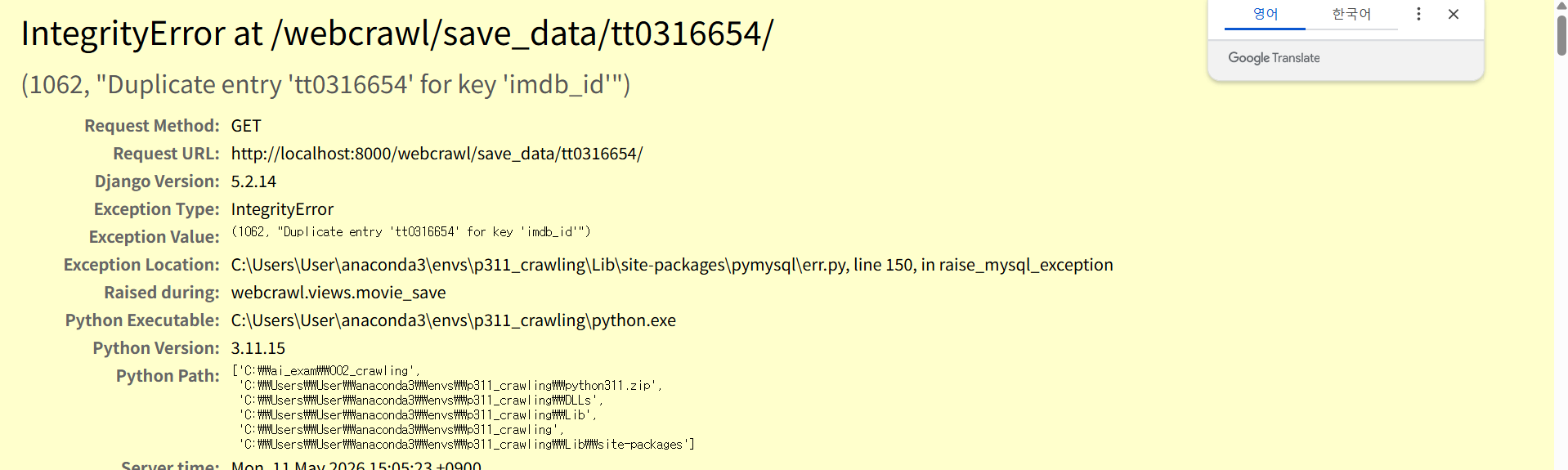
예외처리문을 메서드에 추가했다.
# 저장
try:
saveData.save()
except:
return HttpResponse("중복된 데이터 입니다.")
그외에 예외처리
# Ratings
try:
saveData.ratings1_source = data['Ratings'][0]['Source']
saveData.ratings1_value = data['Ratings'][0]['Value']
except:
saveData.ratings1_source = ''
saveData.ratings1_value = ''
try:
saveData.ratings2_source = data['Ratings'][1]['Source']
saveData.ratings2_value = data['Ratings'][1]['Value']
except:
saveData.ratings2_source = ''
saveData.ratings2_value = ''translate.py 실행결과
import urllib.request
import urllib.parse
import json
def translate_en_to_ko(text: str) -> str:
"""
영어 텍스트를 한글로 번역합니다.
- API 키 불필요
- 외부 라이브러리 불필요 (표준 라이브러리만 사용)
- Python 3.11 이상 호환
Args:
text (str): 번역할 영어 텍스트
Returns:
str: 번역된 한글 텍스트
Raises:
ValueError: 입력 텍스트가 비어있을 경우
RuntimeError: 번역 요청 실패 시
"""
if not text or not text.strip():
raise ValueError("번역할 텍스트를 입력해주세요.")
url = "https://translate.googleapis.com/translate_a/single"
params = urllib.parse.urlencode({
"client": "gtx",
"sl": "en",
"tl": "ko",
"dt": "t",
"q": text
})
req = urllib.request.Request(
f"{url}?{params}",
headers={"User-Agent": "Mozilla/5.0"}
)
try:
with urllib.request.urlopen(req, timeout=10) as response:
data = json.loads(response.read().decode("utf-8"))
return "".join(item[0] for item in data[0] if item[0])
except urllib.error.HTTPError as e:
raise RuntimeError(f"번역 요청 실패 (HTTP {e.code}): {e.reason}") from e
except urllib.error.URLError as e:
raise RuntimeError(f"네트워크 오류: {e.reason}") from e
# ── 사용 예시 ──────────────────────────────────────────────
if __name__ == "__main__":
examples = [
"Hello, how are you?",
"Artificial intelligence is transforming the world.",
"Python is a great programming language.",
"The quick brown fox jumps over the lazy dog.",
]
for text in examples:
translated = translate_en_to_ko(text)
print(f"EN: {text}")
print(f"KO: {translated}")
print()(p311_crawling) C:\ai_exam\002_crawling>C:\Users\User\anaconda3\envs\p311_crawling\python.exe c:/ai_exam/002_crawling/____test/translate.py
EN: Hello, how are you?
KO: 안녕하세요. 어떻게 지내세요?
EN: Artificial intelligence is transforming the world.
KO: 인공지능이 세상을 변화시키고 있습니다.
EN: Python is a great programming language.
KO: Python은 훌륭한 프로그래밍 언어입니다.
EN: The quick brown fox jumps over the lazy dog.
KO: 날렵한 갈색여우가 게으른 개를 뛰어넘습니다.class Movie(models.Model):
title = models.CharField(max_length=255)
ko_title = models.CharField(max_length=255, default='', null=True)# 코드문 추가** 데이터베이스 마이그레이션(수정, 삭제....)
python manage.py makemigrations
python manage.py migrate
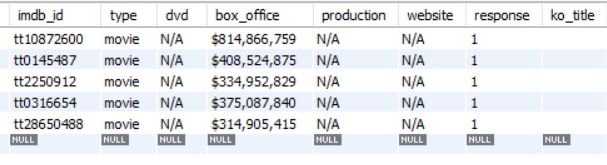
SELECT * FROM webcrawldb.movie;
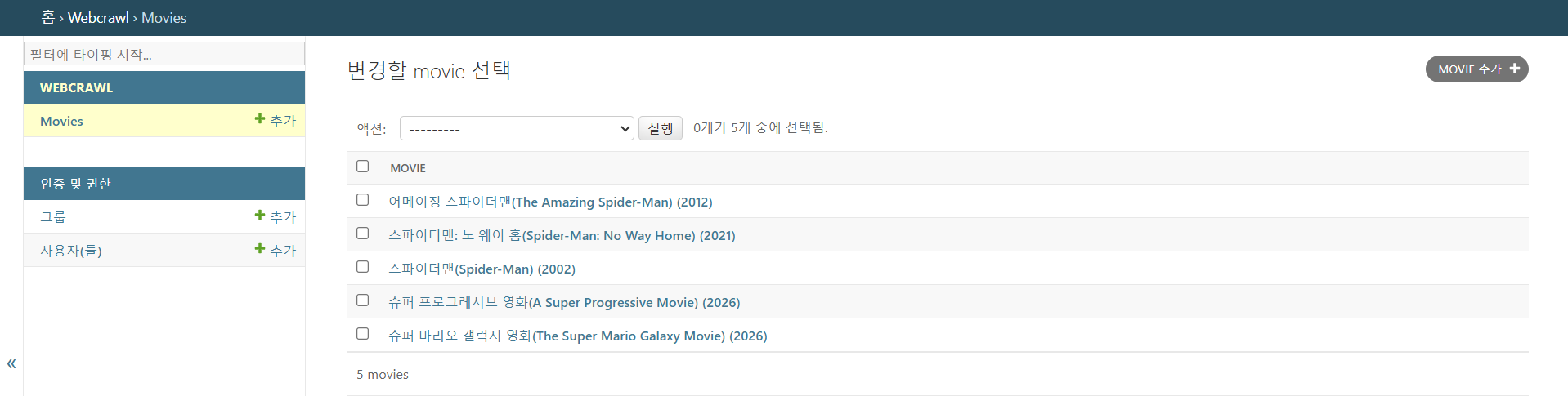
맨끝에 ko_title이라는 컬럼이 생김
DELETE FROM webcrawldb.movie;
webcrawl 경로에 또 translate.py를 만든다. test위까지 그대로 복붙
def translate_en_to_ko(text: str) -> str:
결과가 스트링을 나온다는 뜻
from . translate import translate_en_to_ko -> 다른데 또 쓸수도 있으니 임포트 분리한다 한다.

잘 번역되서 저장된 모습
새로 생성한 테이블을 관리자 페이지에 등록하는 방법
http://localhost:8000/admin
from django.contrib import admin
from . models import Movie
# Register your models here.
admin.site.register(Movie)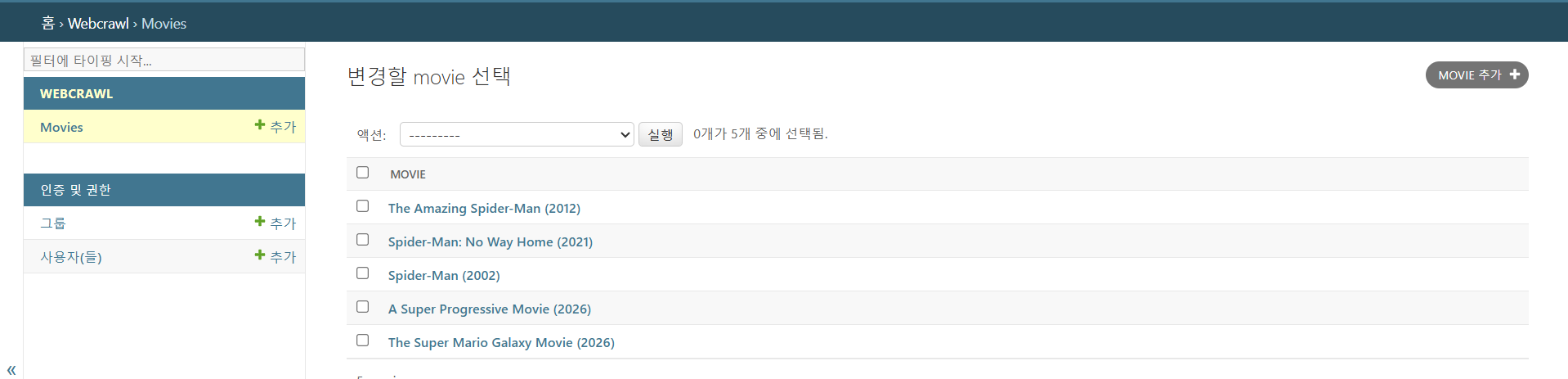
admin.py 수정
def __str__(self):
return f"{self.ko_title}({self.title}) ({self.year})"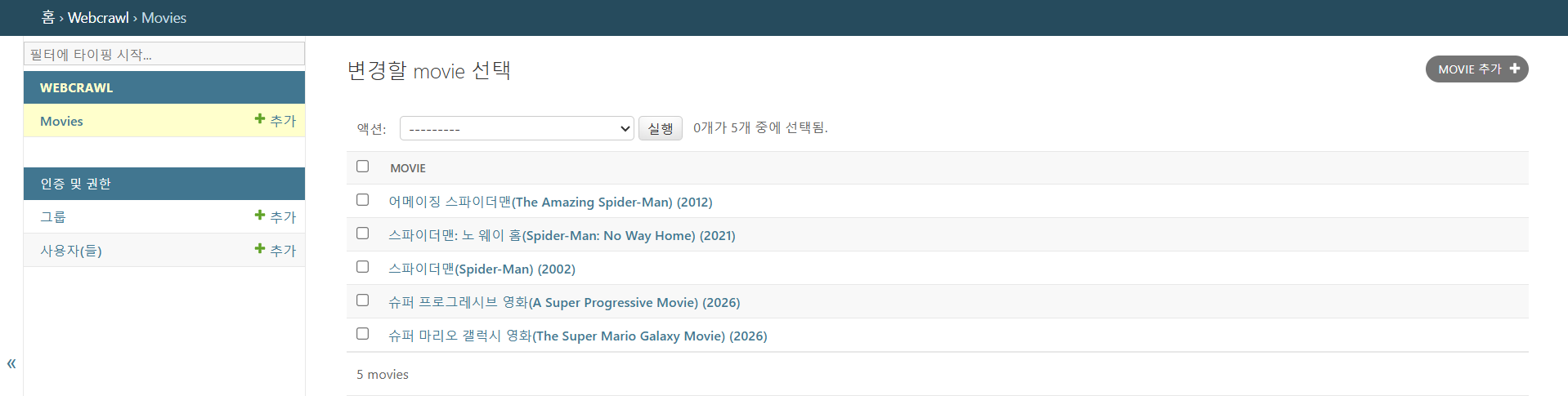
수정한대로 잘 나온다.
데이터베이스는 화면설계 끝나고 -> 요구사항 끝나고
Pypi
https://pypi.org/project/finance-datareader/
google - "finance datareader"
pip install finance-datareader
import FinanceDataReader as fdr
import FinanceDataReader as fdr
data = fdr.DataReader('005930')
print(data)잘 찾아와서 빨리 자기 제품 만드는것이 일잘하는 사람
... ... ... ... ... ... ...
2026-05-04 228000 232500 224000 232500 32920816 0.054422
2026-05-06 254000 270000 251000 266000 53097996 0.144086
2026-05-07 272000 277000 260000 271500 41404687 0.020677
2026-05-08 260000 270000 260000 268500 25875880 -0.011050
2026-05-11 284500 288500 280000 285500 34321592 0.063315
정형데이터 중 시계열 데이터라고 함
이걸로 예측이 가능함
분석하기 위해서 시계열 데이터가 가장 좋다
오전 : 60만개 데이터 mysql에 입력 SQL 명령어
오후: 1시간 미팅
오후 : 주가 분석(주가차트+사이트분석) => 화면설계
