#1. 수강 과목 : 컴퓨터 과학 기초(6과)
#2. 수강 콘텐츠 : 모두를 위한 컴퓨터 과학(CS50 2019)
<데이터 구조>
- malloc과 포인터 복습
int main(void)
{
int *x;
int *y;
x = malloc(sizeof(int));
*x = 42;
*y = 13;
}현재 x, y라는 포인터를 만들고 42, 13이라는 값에 연결 시키려고 함. 그런데 x가 42를 가리킨다는 것은 malloc통해 지정되었지만 y는 지정된 것이 없음. 따라서
y = x;
*y = 13;로 값을 초기화 시켜줘서 포인터가 값을 가리킬 수 있게 코딩해야 한다고 함.
- 배열의 크기 조정
배열 : 메모리는 사물함 구조. 공간이 모자랄 때 옆에 메모리 칸 함부로 쓰는 것이 아니라 정의된 배열 크기 자체를 바꿀 수 있는 방법.
1 2 3 을 채운 메모리에서 1 2 3 4 를 채워야 할 때 빈 공간으로 얘네를 옮기고 원래 공간을 free처리 해준 다음 새로운 4를 추가하는 식
#include <stdio.h>
#include <stdlib.h>
int main(void){
int *list = malloc(3 * sizeof(int));
if (list == NULL){
return 1;
}
list[0] = 1;
list[1] = 2;
list[2] = 3;
int *tmp = malloc(4 * sizeof(int));
if (tmp == NULL){
return 1;
}
for (int i = 0; i< 3; i++){
tmp[i] = list[i];
}
tmp[3] = 4;
free(list);
list= tmp;
for (int i = 0; i< 4 ; i ++){
printf("%i\n", list[i]);
}
}
1
2
3
4 // 4가 추가 됨.이거 말고 realloc을 사용하면 코드가 조금 더 간단해짐.
#include <stdio.h>
#include <stdlib.h>
int main(void){
int *list = malloc(3 * sizeof(int));
if (list == NULL){
return 1;
}
list[0] = 1;
list[1] = 2;
list[2] = 3;
int *tmp = realloc(list, 4*sizeof(int));
if (tmp == NULL){
return 1;
}
list = tmp;
tmp[3] = 4;
for (int i = 0; i< 4 ; i ++){
printf("%i\n", list[i]);
}
free(list);
}
- 연결 리스트 : 도입
먼저 1, 2, 3은 각각 다른 주소를 가지고 다른 메모리칸에 저장되어 있다.
->
근데 이걸 세로로 두 칸짜리라 하고 남은 한 칸에 다음 숫자 16진법 주소가 적혀있다고 가정한다.(넥스트)
->
이후 포인터로 그 주소가 숫자를 연결한다.(주소->2, 주소->3)
코드로 표현하면?
(참고로 Node는 네모, 상자 이런 뜻. 거기에 담겨 있다.)
typedef struct node{
int number;
struct node *next;
}
node;- 연결 리스트 : 코딩
아까 만든 두칸 짜리 1, 2, 3을 리스트로 한 칸에 만드는 코드
#include <stdio.h>
#include <stdlib.h>
//연결 리스트의 기본 단위가 되는 node 구조체를 정의합니다.
typedef struct node
{
//node 안에서 정수형 값이 저장되는 변수를 name으로 지정합니다.
int number;
//다음 node의 주소를 가리키는 포인터를 *next로 지정합니다.
struct node *next;
}
node;
int main(void)
{
// list라는 이름의 node 포인터를 정의합니다. 연결 리스트의 가장 첫 번째 node를 가리킬 것입니다.
// 이 포인터는 현재 아무 것도 가리키고 있지 않기 때문에 NULL 로 초기화합니다.
node *list = NULL;
// 새로운 node를 위해 메모리를 할당하고 포인터 *n으로 가리킵니다.
node *n = malloc(sizeof(node));
if (n == NULL)
{
return 1;
}
// n의 number 필드에 1의 값을 저장합니다. “n->number”는 “(*n).numer”와 동일한 의미입니다.
// 즉, n이 가리키는 node의 number 필드를 의미하는 것입니다.
// 간단하게 화살표 표시 ‘->’로 쓸 수 있습니다. n의 number의 값을 1로 저장합니다.
n->number = 1;
// n 다음에 정의된 node가 없으므로 NULL로 초기화합니다.
n->next = NULL;
// 이제 첫번째 node를 정의했기 떄문에 list 포인터를 n 포인터로 바꿔 줍니다.
list = n;
// 이제 list에 다른 node를 더 연결하기 위해 n에 새로운 메모리를 다시 할당합니다.
n = malloc(sizeof(node));
if (n == NULL)
{
return 1;
}
// n의 number와 next의 값을 각각 저장합니다.
n->number = 2;
n->next = NULL;
// list가 가리키는 것은 첫 번째 node입니다.
//이 node의 다음 node를 n 포인터로 지정합니다.
list->next = n;
// 다시 한 번 n 포인터에 새로운 메모리를 할당하고 number과 next의 값을 저장합니다.
n = malloc(sizeof(node));
if (n == NULL)
{
return 1;
}
n->number = 3;
n->next = NULL;
// 현재 list는 첫번째 node를 가리키고, 이는 두번째 node와 연결되어 있습니다.
// 따라서 세 번째 node를 더 연결하기 위해 첫 번째 node (list)의
// 다음 node(list->next)의 다음 node(list->next->next)를 n 포인터로 지정합니다.
list->next->next = n;
// 이제 list에 연결된 node를 처음부터 방문하면서 각 number 값을 출력합니다.
// 마지막 node의 next에는 NULL이 저장되어 있을 것이기 때문에 이 것이 for 루프의 종료 조건이 됩니다.
for (node *tmp = list; tmp != NULL; tmp = tmp->next)
{
printf("%i\n", tmp->number);
}
// 메모리를 해제해주기 위해 list에 연결된 node들을 처음부터 방문하면서 free 해줍니다.
while (list != NULL)
{
node *tmp = list->next;
free(list);
list = tmp;
}
}
1
2
3많이 어렵다. 여하튼 1~3을 포인터와 빈 리스트로 연결하는 개념이구나 하고 그림으로 배운 것을 이해하자.
- 연결 리스트 : 시연
이런 접근에 문제점 : 임의 접근(아무 값이나 랜덤으로)이 불가능하다.
- 연결 리스트 : 트리
만일 하나씩 가리키는게 아니라 여러 요소를 함께 가리킨다면?(이진 검색 트리 모양으로 가계도 만들 듯이) ; 재귀와 연관있다고 함.
4(root)
2 6
1 3 5 7작으면 왼쪽 크면 오른쪽(선택적으로 값을 찾음)
자기 자신을 끊임없이 반복하며 묻기에 재귀라고 함.
//이진 검색 트리의 노드 구조체
typedef struct node
{
// 노드의 값
int number;
// 왼쪽 자식 노드
struct node *left;
// 오른쪽 자식 노드
struct node *right;
} node;
// 이진 검색 함수 (*tree는 이진 검색 트리를 가리키는 포인터)
bool search(node *tree)
{
// 트리가 비어있는 경우 ‘false’를 반환하고 함수 종료
if (tree == NULL)
{
return false;
}
// 현재 노드의 값이 50보다 크면 왼쪽 노드 검색
else if (50 < tree->number)
{
return search(tree->left);
}
// 현재 노드의 값이 50보다 작으면 오른쪽 노드 검색
else if (50 > tree->number)
{
return search(tree->right);
}
// 위 모든 조건이 만족하지 않으면 노드의 값이 50이므로 ‘true’ 반환
else {
return true;
}
}위와 같은 검색법으로 시간 단축할 수 있다고 함.
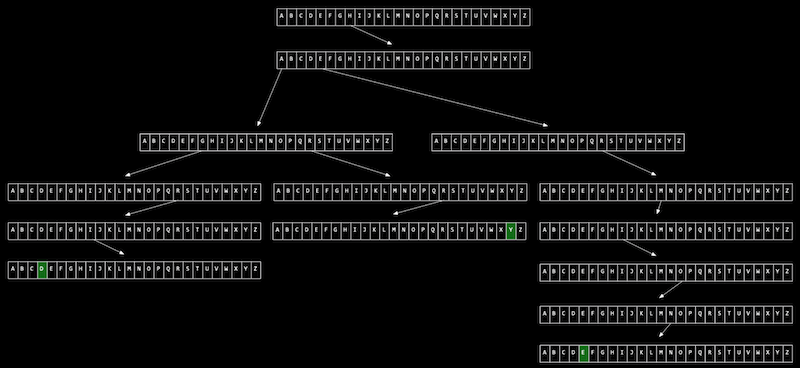
- 해시 테이블 : 연결 리스트, 트리보다 훨씬 시간을 단축하는 방법
해시 테이블은 배열과 연결리스트의 조합
e.g 이름표 정렬
버킷에 이름표를 집어 넣음-> 이미 찬 통에 넣을 뻔할 경우(같은 알파벳으로 시작) -> 트리처럼 연결해서 그대로 넣기(계속 연결 ; 충돌 중)
H로 시작하는 이름이 3개나 있다 -> 다음 글자까지 고려하여 버킷에 넣음(가지치기)... 버킷이 많아지고 시간이 많이 걸릴 수 있음.
- 인덱싱 : 여기서 사용하는 함수를 해시 함수(어떤 버킷에 담을 지 결정하는 함수, e.g 이름이 Harry면 HA, HE 봐서 넣어줌..)
이렇게 되면 모든 경우의 수가 담기므로 검색 시 바로 찾을 수는 있음. 최악의 경우는 해시 함수에 따라 한 버킷에 다 담길 수도 있음(리스트 + 가지치기)
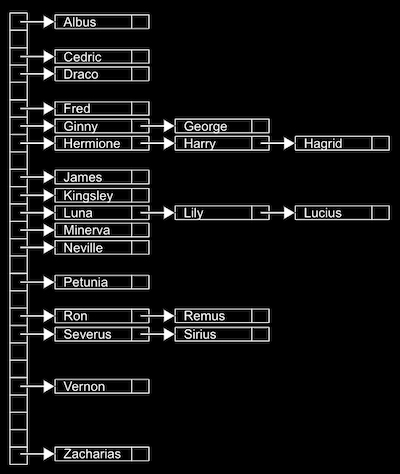
- 트라이 : 메모리 많이 들지만 자료구조 안에서 일정한 시간으로 움직임. 노드의 배열 트리
이름으로 생각하면 이름의 모든 철자를 다 보는 것임(철자 하나 하나를 분해해서 삼각 트리형으로 저장함)
자료의 길이에 따라 시간이 정해짐. 충돌이 일어나진 않지만 매우 넓고 밀도가 높음. 아주 많은 양의 메모리를 사용함.
- 스택 / 큐 / 딕셔너리
큐 : 줄서기, 선입선출(FIFO)
enqueue(줄 서서 들어가기) / dequeue(줄 서서 가나가기)
스택 : 쟁반쌓기, e-mail, 후입선출(LIFO)
push / pop
딕셔너리 : 파이썬 딕셔너리 생각. 해쉬 테이블 구현의 예.(해쉬가 약간 짝 맞추기 같은 느낌이라 그런 듯.)
전체적으로 어려웠다. 나중에 찾아서 다시 복습해야겠다.
