
문제
https://www.acmicpc.net/problem/2263
문제 설명
이진 트리를 순회하는 방법 중에는 전위 순회, 중위 순회, 후위 순회가 있다. 이 문제는 어떤 이진 트리를 중위 순회, 후위 순회 하였을 때 방문하게 되는 노드의 순서를 가지고 전위 순회를 했을 때 노드를 방문하는 순서를 구해야 하는 문제이고 이진 트리의 특성과 3가지 순회의 차이점을 이해해야 하는 문제이다. 그래서 이 문제의 풀이를 이해하기 위해서는 일단 이진 트리와 그 순회에 대해 이해해야 한다.
이진 트리와 3가지 순회
만약 다음과 같은 이진 트리가 있다고 가정해보자.
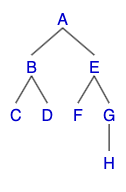
이진 트리는 각각의 노드가 최대 2개의 자식 노드를 가질 수 있는 트리이다. 이 규칙은 모든 자식 노드들에도 해당이 되므로 이진 트리는 어떤 부분을 자르던 그 부분 역시 이진 트리라는 특징을 가진다. 예를 들어 위의 트리에서도 어떤식으로 자르던 다음과 같이 모두 이진 트리가 된다.
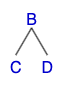
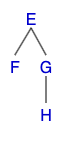
이 특징을 인지한 상태로 3가지 순회에 대해 생각을 해보자. 각 3가지 순회는 트리를 다음과 같은 순서대로 순회를 한다.
- 전위 순회: 부모 - 왼쪽 - 오른쪽
- 중위 순회: 왼쪽 - 부모 - 오른쪽
- 후위 순회: 왼쪽 - 오른쪽 - 부모
각 순회의 규칙은 매우 단순하다. 중위 순회를 기준으로 생각해보면, 부모 노드, 왼쪽 자식 노드, 오른쪽 자식 노드가 있을 때 왼쪽, 부모, 오른쪽 노드 순서대로 방문을 한다는 규칙만 지키면 된다. 복잡해보이는 트리를 순회하는데 있어서 이 간단한 규칙만 지키면 되는 이유는 간단하다. 앞서 설명했다 시피, 이진 트리는 어떤 노드를 방문하든 왼쪽, 오른쪽 두 개의 자식 노드만을 가지는 프랙탈 구조이기 때문이다.
다시 이 트리를 보자. 이 트리를 3가지 방식으로 순회를 하면 방문하는 노드의 순서는 다음과 같다.
- 전위 순회: ABCDEFGH
- 중위 순회: CBDAFEHG
- 후위 순회: CDBFHGEA
앞서 말했듯이 이진 트리를 프랙탈 구조를 가지고 있다. 그렇기에 이 방문 노드 순서에서도 프랙탈 구조를 엿볼 수 있다. 중위 순회를 기준으로 보자.
왼쪽 - 부모 - 오른쪽(CBDAFEHG)
중위 순회는 부모, 왼쪽, 오른쪽 3개의 노드를 기준으로 무조건 왼쪽을 먼저 방문하므로 최상위 노드인 A를 기준으로 보면 A의 입장에서 왼쪽 노드의 영역인 B, C, D가 모두 A의 왼쪽에 있는 것을 확인할 수 있다. 그리고 오른쪽 노드의 영역인 E, F, G, H는 모두 A의 오른쪽에 있다.
그 다음 B, C, D를 보면 CBD의 순서로 방문을 하게 되는데 이 때도 여기를 기준으로 최상위 루트 노드는 B인데 왼쪽 노드인 C를 먼저 방문하므로 B의 왼쪽에 C가 있음을 확인할 수 있다.
전위 순회(ABCDEFGH)를 기준으로 보면 A가 가장 왼쪽에 있고 왼쪽 노드 영역(BCD)과 오른쪽 노드 영역(EFGH)가 뒤를 이음을 볼 수 있고, 후위 순회(CDBFHGEA)를 기준으로 보면 A가 가장 오른쪽에 있고 왼쪽 노드 영역(CDB)과 오른쪽 노드 영역(FHGE)가 그 앞에 순서대로 위치함을 볼 수 있다.
즉, 노드 방문 순서 역시 당연하게도 이진 트리의 특성인 프랙탈 구조를 가지므로 이를 보고 트리의 구조를 유추할 수 있다!
풀이
n = int(input())
in_order = list(map(int, input().split()))
post_order = list(map(int, input().split()))
in_order_idx = [0] * (n + 1)
for i in range(n):
in_order_idx[in_order[i]] = i우선 중위 순회와 후위 순회의 순서를 입력 받고, 중위 순회 순서와 후위 순회의 순서를 비교해야 하므로 중위 순회의 인덱스를 저장을 해놓는다.
pre_order(0, n - 1, 0, n - 1)
def pre_order(in_s, in_e, post_s, post_e):
if in_s > in_e or post_s > post_e:
return왼쪽, 오른쪽 영역 별로 계속 리스트를 생성하는 것 보다 인덱스를 기반으로 로직을 짜는게 더 효율적이다. inorder 시작, 끝 인덱스, postorder 시작, 끝 인덱스까지 총 4개의 인수를 받는 함수를 만들고 시작 인덱스가 끝 인덱스를 넘는다면 return을 하도록 한다.
root = post_order[post_e]
root_idx = in_order_idx[root]post_order의 마지막 인덱스가 root이므로 root를 먼저 찾고 inorder 기준에서의 root의 인덱스 또한 찾아 놓는다.
left_node_cnt = root_idx - in_s
right_node_cnt = in_e - root_idx
print(root, end=' ')
pre_order(in_s, root_idx - 1, post_s, post_s + left_node_cnt - 1)
pre_order(root_idx + 1, in_e, post_e - right_node_cnt, post_e - 1)루트를 기준으로 왼쪽 영역의 개수는 inorder에서 루트 인덱스에서 시작 인덱스를 뺀 값일 것이다. 마찬가지로 오른쪽 개수의 영역의 개수는 inorder에서 끝 인덱스에서 루트 인덱스를 뺸 값일 것이다. inorder에서 루트의 인덱스는 중간에 위치하기 때문이다.
그 후 preorder는 루트를 먼저 방문해야 하므로 루트를 출력한다. 그 후 왼쪽 영역으로 넘어가야 하므로 inorder의 왼쪽 영역은 indrder 시작 인덱스 ~ 루트 인덱스 - 1이 되고 postorder의 왼쪽 영역은 postorder 시작 인덱스 ~ 시작 인덱스 + 왼쪽 노드 개수 - 1이 된다.
그 후 오른쪽 영역으로 넘어가야 하는데, inorder의 오른쪽 영역은 루트 인덱스 + 1 ~ inorder 끝 인덱스가 되고 postorder의 오른쪽 영역은 postorder 끝 인덱스 - 오른쪽 영역 노드 개수 ~ postorder 끝 인덱스 - 1이 된다.
전체 코드
import sys
input = sys.stdin.readline
sys.setrecursionlimit(10 ** 6)
def pre_order(in_s, in_e, post_s, post_e):
if in_s > in_e or post_s > post_e:
return
root = post_order[post_e]
root_idx = in_order_idx[root]
left_node_cnt = root_idx - in_s
right_node_cnt = in_e - root_idx
print(root, end=' ')
pre_order(in_s, root_idx - 1, post_s, post_s + left_node_cnt - 1)
pre_order(root_idx + 1, in_e, post_e - right_node_cnt, post_e - 1)
n = int(input())
in_order = list(map(int, input().split()))
post_order = list(map(int, input().split()))
in_order_idx = [0] * (n + 1)
for i in range(n):
in_order_idx[in_order[i]] = i
pre_order(0, n - 1, 0, n - 1)참고
