UNIT(Unsupervised Image-to-Image Translation)
Abstract
- UNIT은 개별 도메인 이미지들의 주변확률분포를 사용해 다른 도메인들의 결합확률분포를 배우는 것을 목표로 합니다.
- 단, 추가적인 가정 없이는 이 태스크가 불가능하기 때문에 shared-latent space를 가정하고 Coupled GAN을 사용하게 됩니다.
Introduction
- Supervised 에서는 서로 다른 도메인의 영상 쌍이 존재하지만, Unsupervised Learning에서는 이러한 쌍이 존재하지 않습니다.
- 단, 훈련 데이터의 수집은 훨씬 쉽기 때문에 성능만 보장된다면 아주 좋은 학습 방법일 수 있습니다.
- 확률모델 관점에서 Image-to-Image Translation은 서로 다른 도메인의 결합 확률분포를 배우는 것입니다.
- 다만 Coupling theory에 따르면 일반적으로 주어진 주변 확률분포에 도달할 수 있는 무수한 결합확률분포의 가능성이 생깁니다.
- 그래서 추가적인 가정을 ( ) 제안합니다.
Assumptions
shared-latent space를 가정하기 때문에 가 고정된 latent code인 를 가집니다.
(수식)
위와 같이 식을 채운다면 shared-latent가 cycle consistency loss와 유사한 것을 볼 수 있습니다.
Framework
특히, Shared-latent spcae 가정을 기반으로 두 VAE를 연관시키기 위해 가중치를 공유합니다.
다만, 이로는 부족하긴 한데, adversarial traning을 통해 공통의 latent code에 매핑될 수 있다고 가정합니다.
GAN
특히, VAE를 통한 reconstruction stream은 라벨 를 통해 지도학습으로 할 수 있기 때문에 translation stream만 adversarial traning을 저굥합니다.
Learning
학습 자체는 두 개의 VAE, 그리고 두 개의 GAN을 결합하여 reconstruction, translation, cycle-reconstruction을 학습하게 됩니다.
M(ultimodal) UNIT
Abstract
- UNIT은 Translation 태스크로, conditional distribution을 학습하게 됩니다.
- 단, 기존의 접근 방식은 일대일 매핑으로 진행되기 때문에 Unimodal합니다.
Introduction
- 대표적으로, MUNIT은 아래와 같은 가정을 진행합니다.
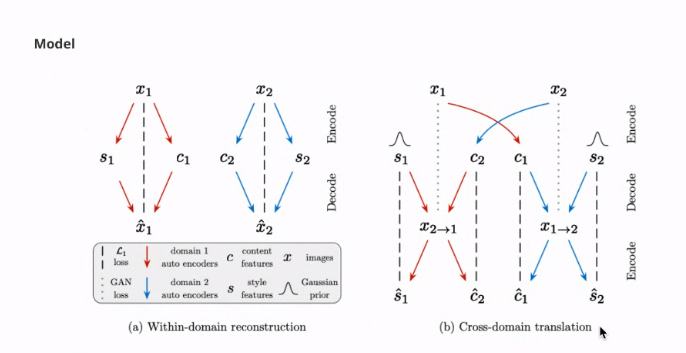
- 이미지의 latent space는 content space와 style space로 나뉠 수 있습니다.
- 서로 다른 도메인이라면 content space를 공유하고, style space는 공유하지 않습니다.
MUNIT
Assumptions
- 위에서 말했듯 각 이미지 는 content latent 와 style latent 로부터 생성이 됩니다.
- 추가적으로 결정론 함수인 의 역함수를 각각 라 가정합니다.
역함수 가정은 (...)를 위해서 진행합니다.
Model
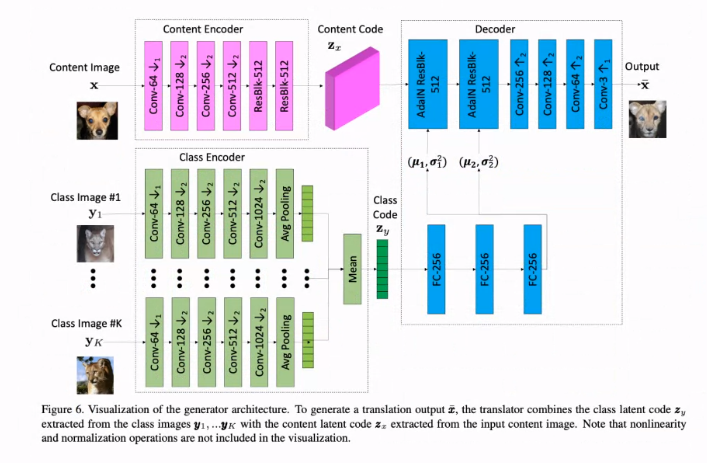
Content Encoder
Style Encoder
- 몇 개의 strided convolution과 GAP + FCN을 사용합니다.
Decoder
- Style Transfer를tngodgkqslek.
Discriminator
- LSGAN의 구조와 multi-scale discriminator를 활용합니다.
F(ew-shot) UNIT
Abstract
- UNIT이든, MUNIT이든, 학습을 위해 도메인 당 이미지가 굉장히 많이 필요합니다.
- FUNIT은 몇 개의 예시 이미지만으로도 새로운 class에 대해 translation을 진행할 수 있습니다.
Introduction
-
Test-time 때에는 소수의 이미지만을 활용해 source class 에 대한 translation을 진행하는 알고리즘을 제안합니다.
-
이를 위해 애초에 많은 class(domain)을 활용해 학습하게 됩니다.
Architecture

-