
<오늘 한 일>
- pandas 실습 파일 3 마무리
- 실습 파일 4
- axis = 0 : 행 방향 (수직) / axis = 1 : 열 방향 (수평)
- axis = 0 : 눕혀서 정리하는 스타일 / axis =1 : 세워서 정리하는 스타일
인덱스
- 행의 대표 정보
코랩
- 런타임 - '이전 셀 실행' 메뉴 있다
- 수정 - 모든 출력 지우기
- 런타임 다시 시작 - 셀 실행해놨던 것들이 사라지고, 모든 셀의 런타임이 [] 빈칸이 됨
데이터 타입마다 사용 가능한 메서드 목록이 다르다
- 다 외울 수는 없으니, 확인 방법: dir()
# 문자열의 메소드들 dir("약품명")[-10:]
Pandas
컬럼명으로 데이터 가져오기
df["약품명"]2개 이상의 컬럼명 가져오기
- 리스트 자료형을 사용
df[["약품명", "가격"]]행을 기준으로 데이터 가져오기
- loc: locate
- loc는 인덱스 값 기준, 문자도 가능
- loc인자가 하나 들어가면 행 정보, 두 개 들어가면 행,열 정보!
df.loc[0] df.loc[[0,1,2]]
- set_index() : 0-8 같은 숫자 인덱스 대신 변수명으로 인덱스 바꾸기
df.set_index("약품명")행과 열을 함께 가져오기
- loc인자가 하나 들어가면 행 정보, 두 개 들어가면 행,열 정보
특정약품만 가져오기
파생변수 만들기
가격이 특정 금액 이상인 것만 가져오기
정렬하기
파일로 저장하기
Seaborn
- 파이차트 제공 X
라이브러리 로드
데이터 로드 (2가지 방법)
# sns.load_dataset("anscombe") : 데이터파일 가져오기 # 깃허브 온라인 연결해서 가져오기 df = pd.read_csv("https://raw.githubusercontent.com/mwaskom/seaborn-data/master/anscombe.csv") df일부 데이터만 가져오기
df.head() df.tail() df.sample(frac=0.05, random_state=42)
기본 정보 보기
dataset
개별 데이터셋의 기술통계
Series의 빈도수
Groupby 를 통한 dataset 별 기술통계
상관 계수
seaborn 시각화
barplot
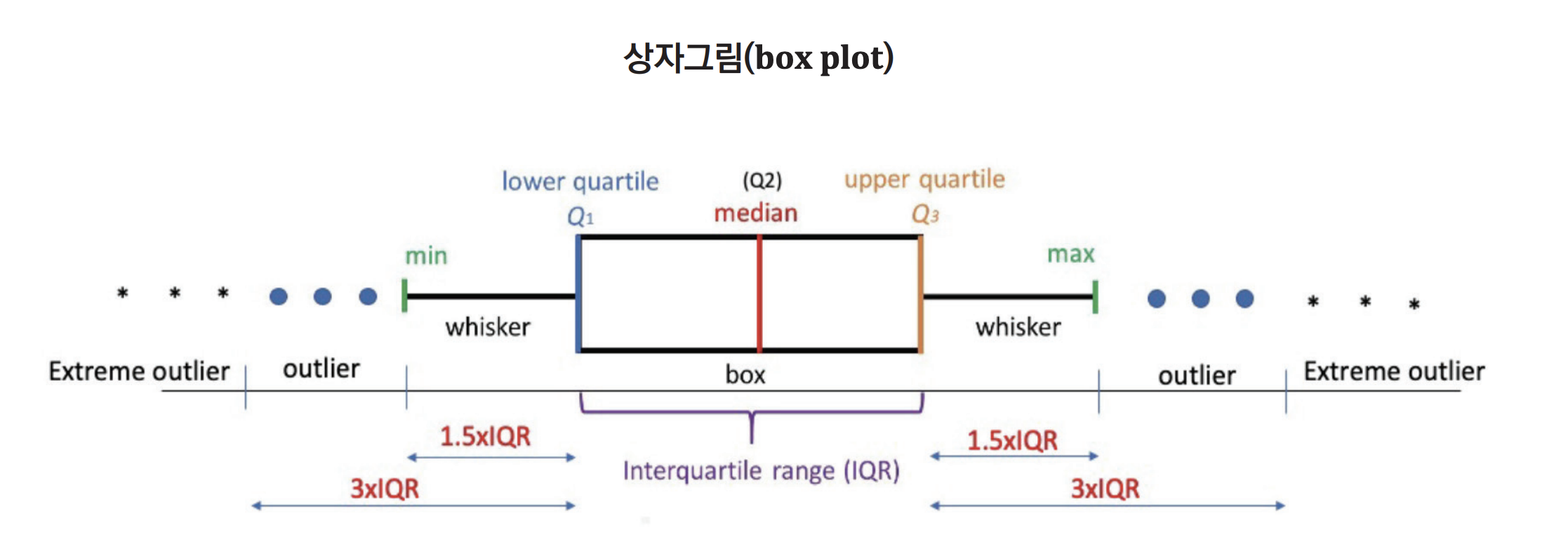
boxplot
- 단점: 데이터가 변화되어도(관측값이 바뀌어도) 4분위수가 같으면 알 수 없다. = 로버스트하다. = 강건하다.
violinplot
- 그런 단점을 보완한 것이 바이올린 플롯
- 분포(히스토그램)를 부드러운 곡선으로 표현
- 밀도추정방법(kde: kernel density estimation)
scatterplot
regplot
lmplot
시각화가 왜 중요한가?
앤스컴 콰르텟
다 같거나 비슷한 기술 통계값을 가지는데, 시각화 해보면 각각 이렇게나 다르다.
특히 4번 그래프는 이상치 하나 때문에 회귀선이 그려지는 모습을 볼 수 있다.
참고 링크
- 인코딩 문제
https://d2.naver.com/helloworld/19187
https://www.hani.co.kr/arti/society/society_general/864914.html- cheat sheet
https://pandas.pydata.org/Pandas_Cheat_Sheet.pdf- 앤스컴 콰르텟
https://ko.wikipedia.org/wiki/%EC%95%A4%EC%8A%A4%EC%BB%B4_%EC%BD%B0%EB%A5%B4%ED%85%9F
https://seaborn.pydata.org/examples/anscombes_quartet.html- seaborn
https://seaborn.pydata.org/examples/different_scatter_variables.html- matplotilb
https://matplotlib.org/- groupby
https://pandas.pydata.org/docs/user_guide/groupby.html- 자료
- seaborn으로 그릴 수 있는 그래프 (re/dis/catplot)
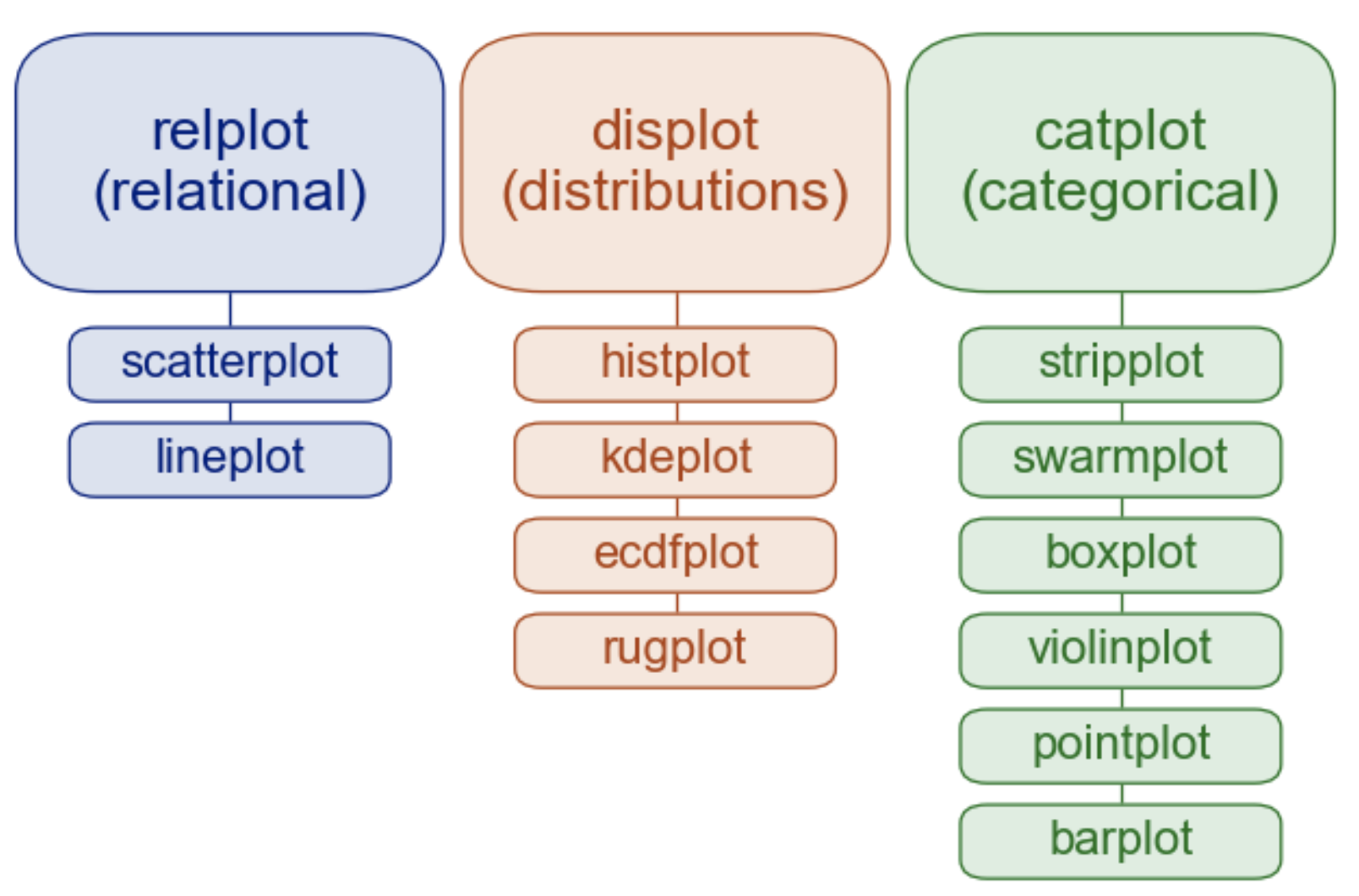
seaborn에서, 변수 하나 혹은 두개의 값 분포를 나타내기 위한 그래프에는 histplot, kdeplot, rugplot, ecdfplot 등이 있습니다.
displot은 이런 그래프들의 통합 개념이라고 생각하시면 됩니다!
3사분위: 하위 75%
1사분위: 하위 25%
분산이 클수록 평균값에서 변량들의 거리가 멀다
분산이 작을수록 평균값에서 변량들의 거리가 가깝다
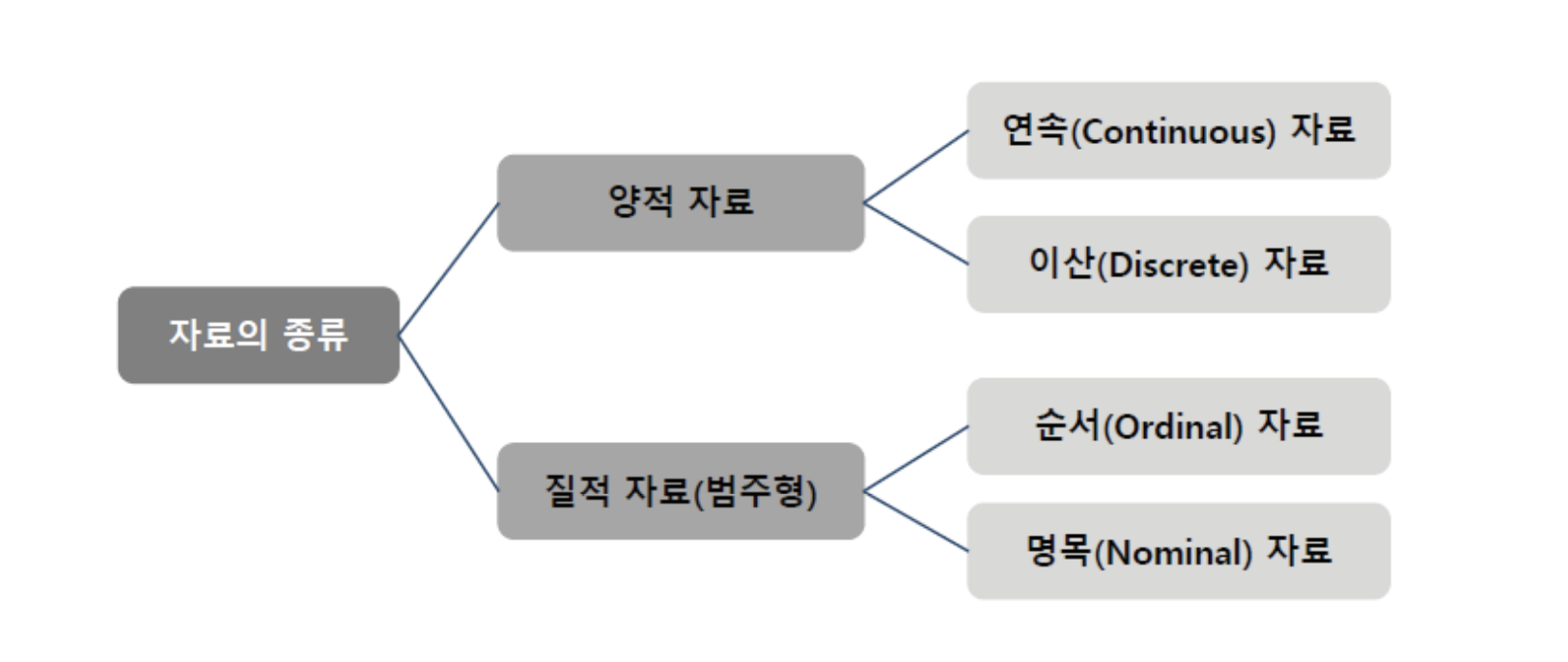
수치형 데이터 (양적 데이터)
범주형 데이터 (질적 데이터)
정형 데이터: 표 형태인 것
비정형 데이터: 표 형태가 아닌 것 (음성, 텍스트도)
초보몽키
<회고>

멋쟁이가 될꺼야~