Lecture 5 -1 Logistic (regression) classification
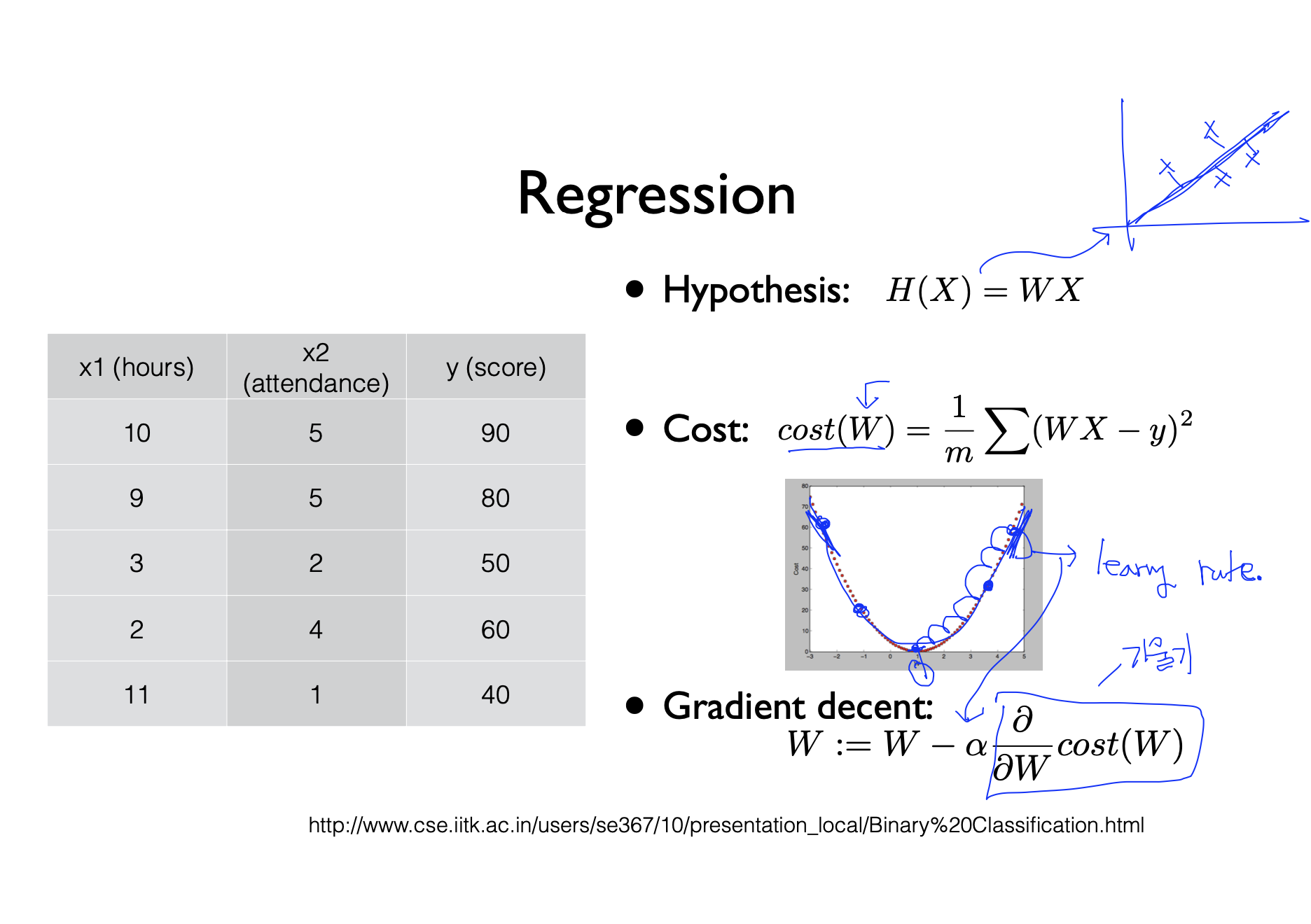
- 분석은 다음과 같은 함수를 사용한다. 이때 Cost 함수는 가장 최소인 W의 값을 찾기 위한 함수이다. Cost함수에서 시그마 뒤에 나오는 부분은 가설과 실제값 차이가 얼마인지를 파악하기 위함이다. learning rate는 step의 사이즈이다. 그림에서 learning rate 대로 학습을 하다보면 W의 값을 찾을 수 있게 된다.
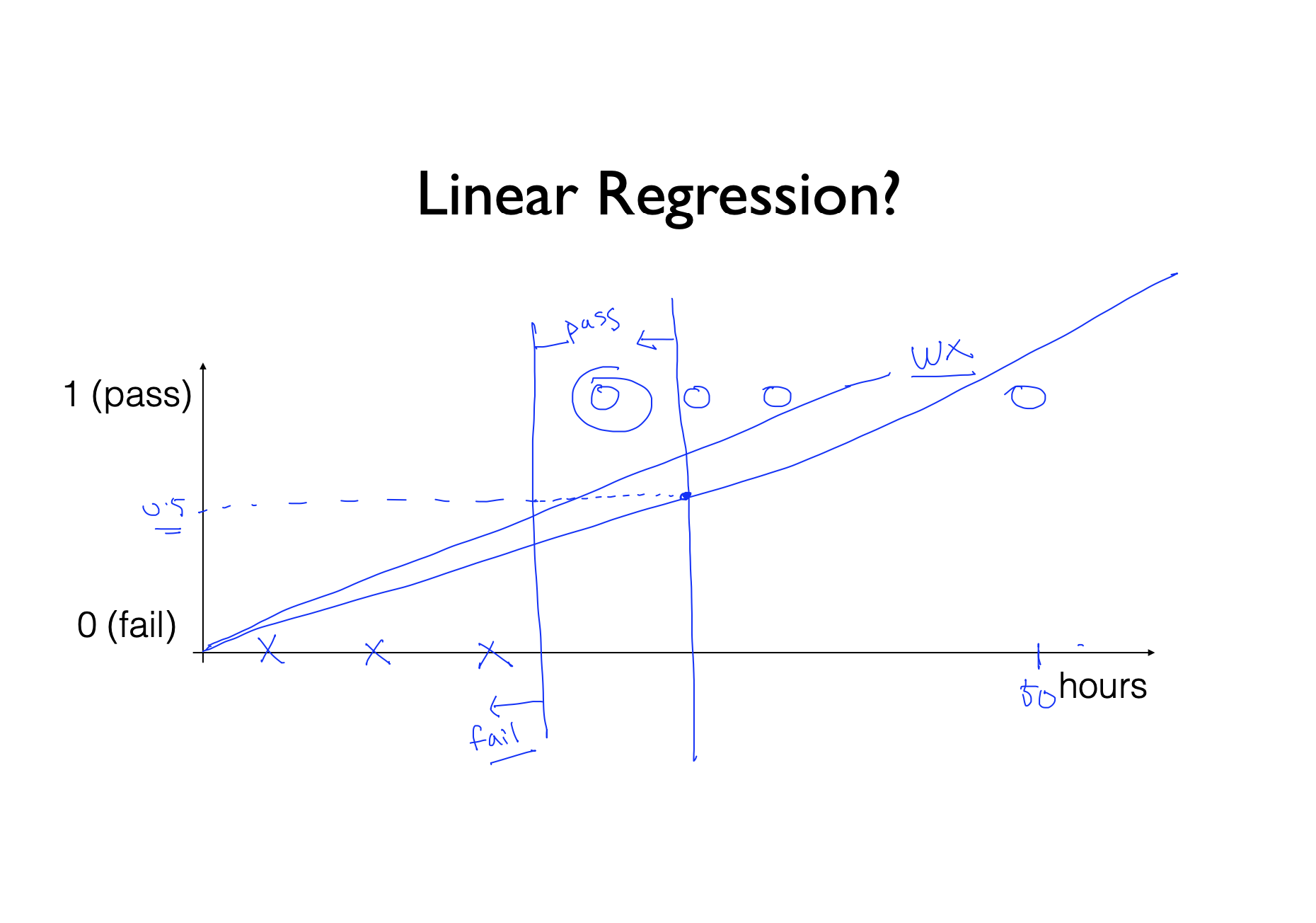
- Binary Classification은 기존의 숫자를 예측하던 Classification과 달리 두가지로만 구분되는 것이다. 예를 들어 Spam E-mail Detection: Spam or Ham, Facebook feed: show or hide 등이 있다. 두가지로 구분되기 때문에 우리는 간단하게 0 과 1로 구분해서 분류한다.
- 그림에서 보이는것은 공부한 시간에 따라 통과인지 불통인지를 구분짓는 그래프이다. 6시간이상 공부했을때 통과라고 했을때, 6시간 미만은 fail(0)으로 6시간 이상이면 pass(1)인것을 볼수 있다. 이것을 직선을 그어 선형으로 분석해보면 0과 1 사이의 중간값 0.5와 그래프를 직선으로 그려서 만나는 점을 기준으로 pas와 fail을 나눌수있다. 그런데 만약 50시간 공부해서 통과한 사람이 있다면, 그 사람때문에 0.5인 선과 그래프가 만나는 점이 뒤로가서 pass인 사람이 fail로 분류당하게 된다.
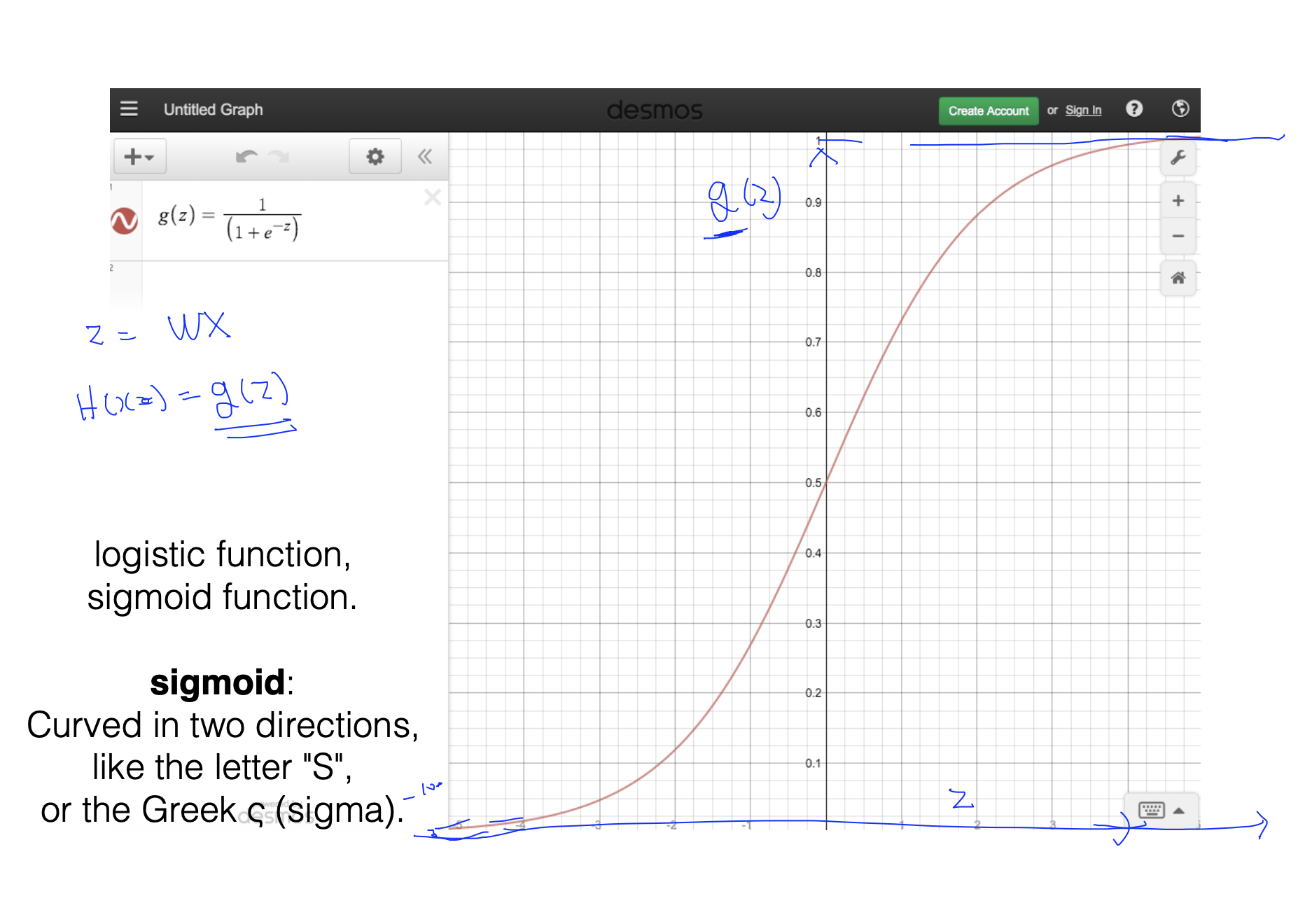
- 그래서 우리는 새로운 함수를 만들게 되었다. 바로 sigmod함수인데 이 함수는 0과 1 사이의 값만 취하면서, 기준에서 너무 떨어지는 값이 생기더라고 아까와 같은 오류를 범하지 않게 되는 함수이다.
Lecture 5-2 Logistic (regression) classification cost fucntion & gradient decent
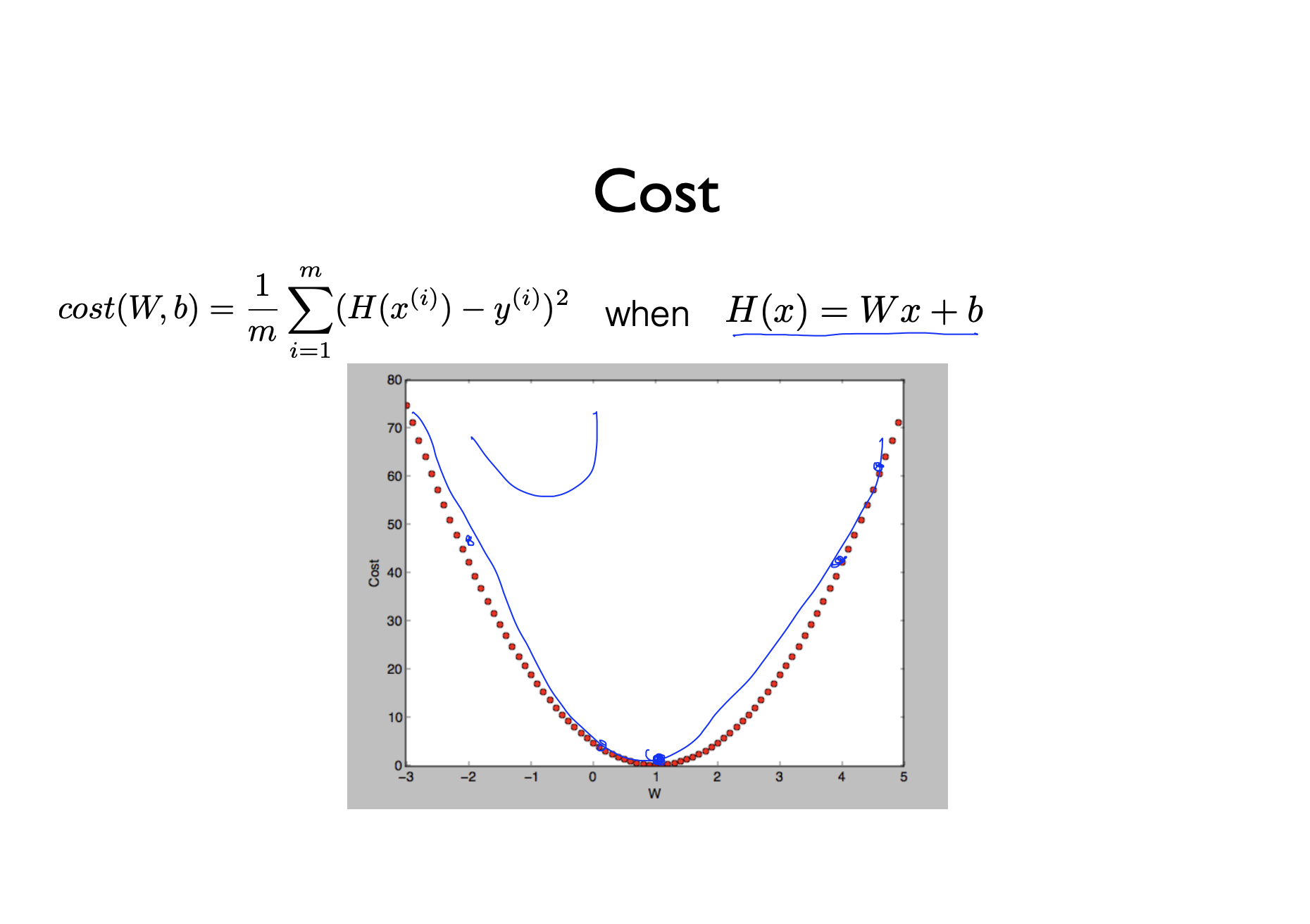
- 기존에 우리가 알던 Cost 함수는 그림과 같이 생겼다. 그런데 우리가 binary classification을 해서 새로운 함수가 만들어 졌으므로 새로운 Cost 함수가 만들어진다.
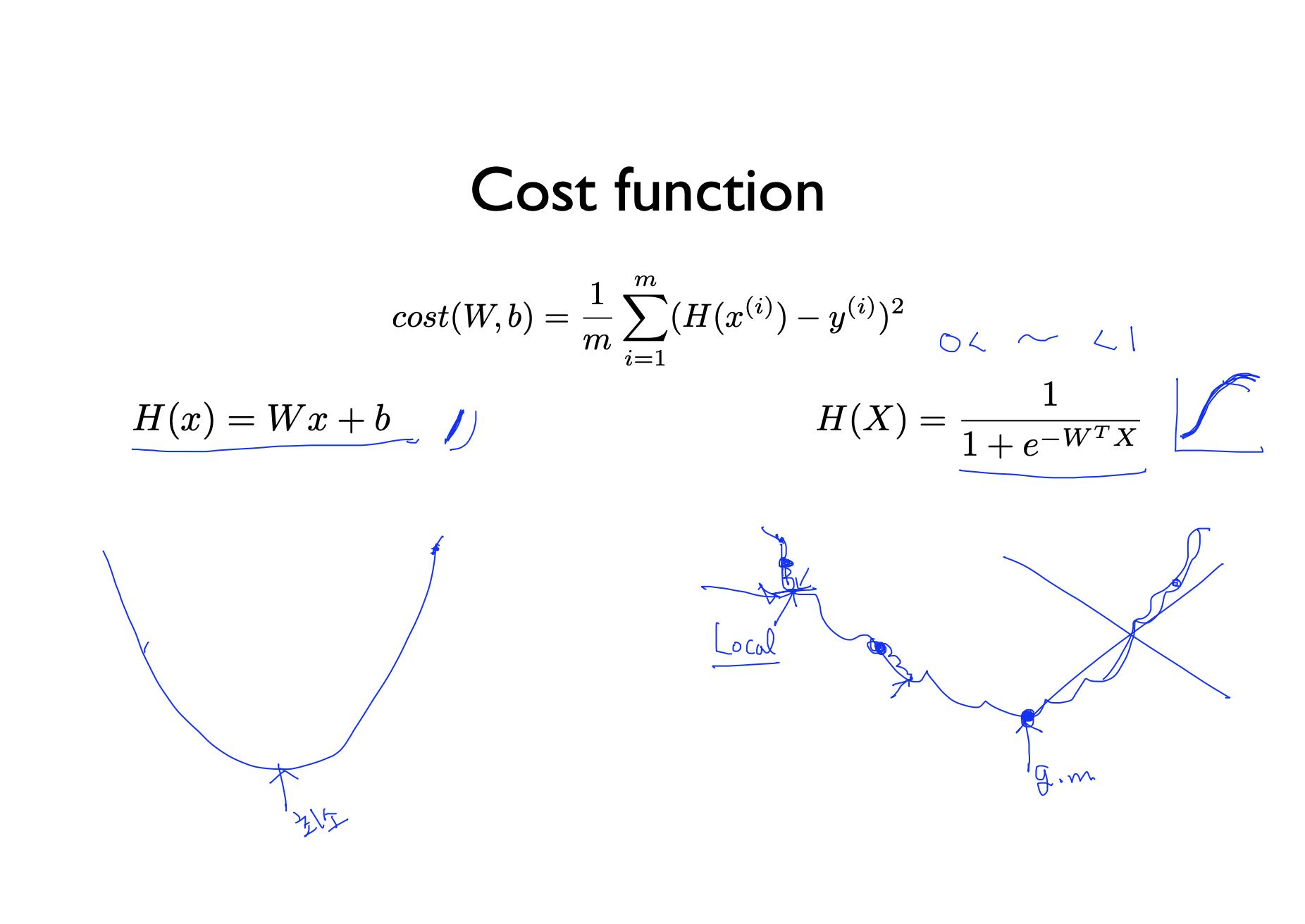
- 새로운 Cost 함수는 오른쪽 그림과 같이 생겼다. 그런데 이 함수는 문제점을 하나 가지고 있다. 어디서 시작하든지 같은 minimum 값을 가져야하는데 지수함수의 특성때문에 시작점에 따라 minimum 값이 달라져 local minimum 값을 갖게되고 이것은 global minimum 값과 다르다는 점이다. 우리는 global minimum 값을 찾고싶은데 시작점에 따라 minimum 값을 찾으면 local minimum 값을 알게된다는 것이다.
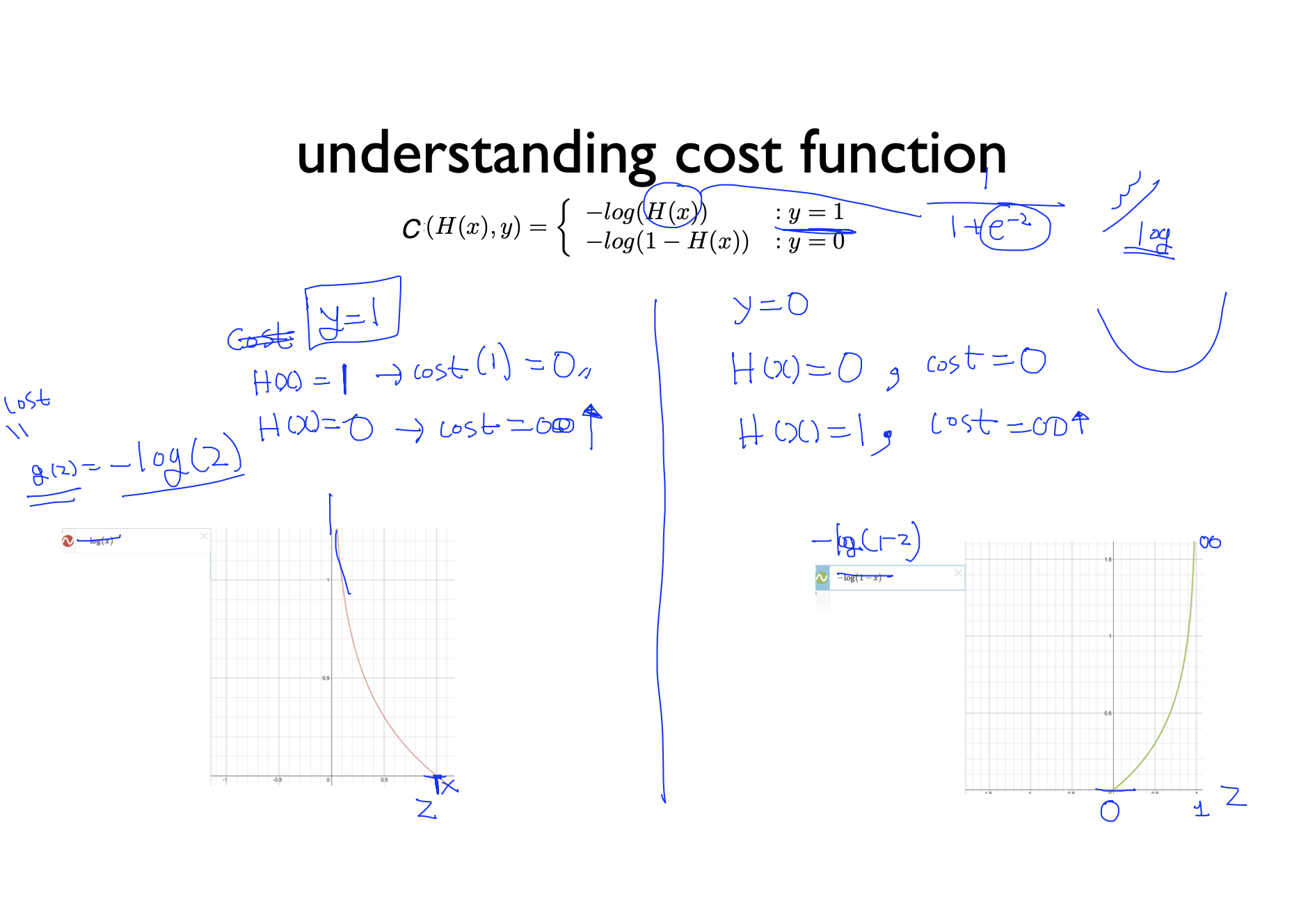
- 이 문제를 해결하기 위해 우리는 새로운 Cost 함수를 만들게 된다. 그림처럼 log를 활용해서 만드는데 y값에 따라 식이 달라진다. 왜냐하면 예측값이 틀리면 cost 값이 무한대로 가는 이상한 현상이 발생하기 때문이다. 따라서 우리는 그림과 같은 Cost 함수를 얻을 수 있다.
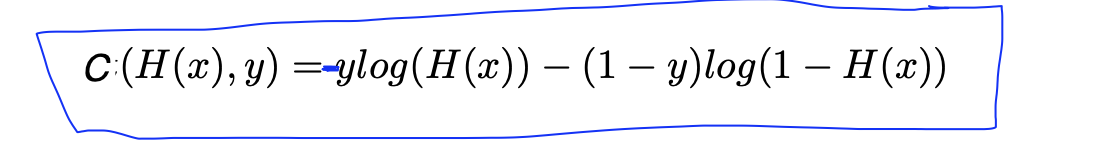
- 이 함수는 두개로 쪼개놓은 식을 하나로 합쳐준 것이다. Cost 함수가 달라졌으므로 Cost 함수를 사용하는 Gradient decent도 같이 달라지게 되고 코딩으로 보면 다음과 같다.


Master Student @ KU👩🏻🎓