⚗️ 실전 프로젝트 2) 주가 정보 데이터 수집하기
1. 네이버 주식 현재가 정보 수집하기
네이버 증권 사이트 현재가 데이터를 파이썬으로 가져온다. 네이버 금융에서 원하는 주식의 가격을 확인해보고 어떤 데이터를 가져올 지 확인해본다. 아래의 사진처럼 확인한 결과 시세 탭에서 가져오는 것이 적절하다고 판단하였다.
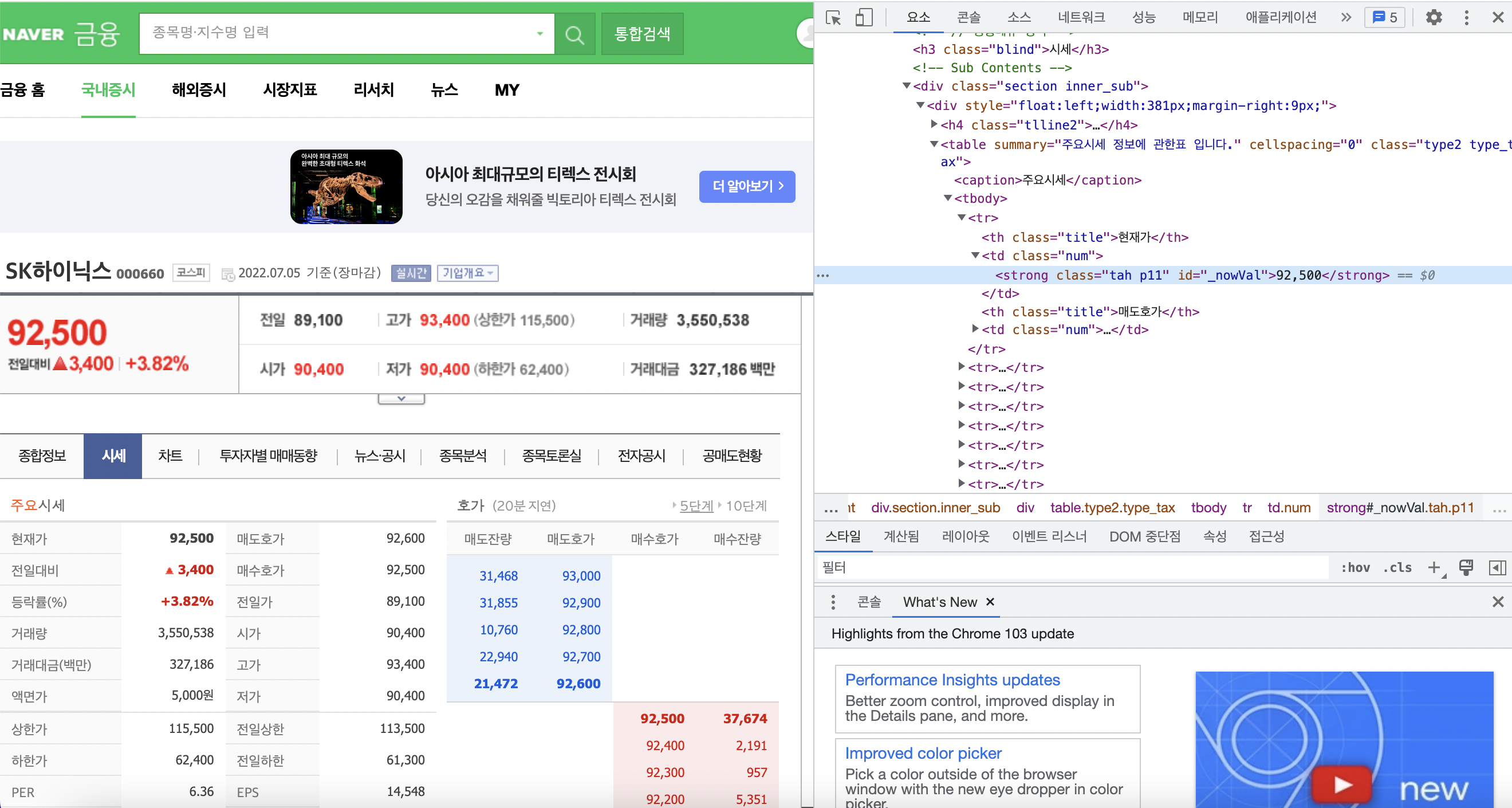
주식 시세를 가져오는 코드는 다음과 같다. url을 확인해보니 code=의 뒷부분이 달라진 것을 알 수 있었다. 따라서 종목 코드 리스트를 통해 여러가지 주식의 시세를 확인해 볼 수 있다.
#네이버 주식 현재가 정보 수집하기
import requests
from bs4 import BeautifulSoup
#종목 코드 리스트
codes = [
'005930', #삼성전자
'000660', #SK하이닉스
'035720' #카카오
]
for code in codes:
url = f'https://finance.naver.com/item/sise.naver?code={code}'
response = requests.get(url)
html = response.text
soup = BeautifulSoup(html, 'html.parser')
price = soup.select_one("#_nowVal").text
price = price.replace(',','')
print(price)2. 파이썬에서 엑셀 다루는 방법 - 수집한 데이터를 엑셀에 저장하기
공식문서란?
프로그램을 개발한 사람들이 사용자에게 사용법을 알려주는 사이트
openpyxl
파이썬에서 엑셀을 쉽게 다룰 수 있도록 도와주는 라이브러리로 아래의 코드를 터미널에 입력하여 설치한다.
pip install openpyxlopenpyxl을 설치한 뒤 엑셀파일을 만드는 실습을 진행해보자.
#파이썬에서 엑셀 다루기
import openpyxl
wb = openpyxl.Workbook() #엑셀 만들기
ws = wb.create_sheet('종이의 집') #엑셀 워크시트 만들기
#데이터 추가하기
ws['A1'] = '역할'
ws['B1'] = '배우'
ws['A2'] = '교수'
ws['B2'] = '박해수'
wb.save('출연진_data.xlsx') #엑셀 저장하기 -> 경로를 지정해서 저장할 수도 있음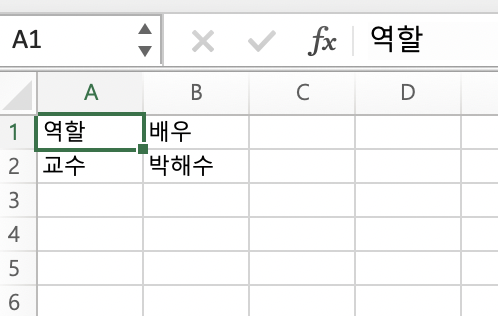
위의 코드를 돌렸을 때 위의 사진과 같은 결과가 나오는 것을 알 수 있다. 이번에는 원래 있던 엑셀 파일을 불러서 수정한 뒤 저장하는 실습을 해보자.
import openpyxl
fpath = r'/Users/kimsongha/Projects/2022-여름/(기)이진크/출연진_data.xlsx'
wb = openpyxl.load_workbook(fpath) #엑셀 불러오기
ws = wb['종이의 집']
#데이터 수정하기
ws['A3'] = '도쿄'
ws['B3'] = '전종서'
wb.save(fpath)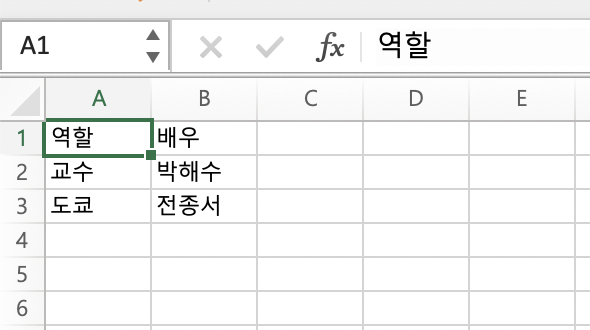
3번째 줄에 새로운 값들이 추가된 것을 확인할 수 있다.
📍 실습과제
- 주식 현재가 크롤링 했던 데이터를 아래 양식의 엑셀을 불러와서 B2, B3, B4에 저장해보자.
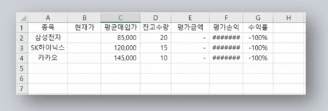
먼저 아래 사진과 같은 엑셀을 만들어주고, 빈칸의 현재가는 크롤링을 통하여 정보를 가지고 온 뒤 채워준다.
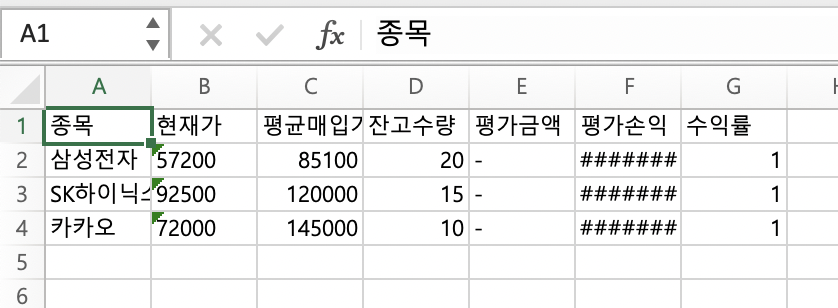
크롤링 한 데이터로 값을 채워주면 아래와 같은 엑셀 시트가 만들어진다.
이런식으로 엑셀을 만들어주기 위한 코드는 아래와 같다.
#실습 과제
import requests
from bs4 import BeautifulSoup
import openpyxl
wb = openpyxl.Workbook() #엑셀 만들기
ws = wb.create_sheet('실습과제_주식') #엑셀 워크시트 만들기
#데이터 추가하기
ws['A1'] = '종목'
ws['B1'] = '현재가'
ws['C1'] = '평균매입가'
ws['D1'] = '잔고수량'
ws['E1'] = '평가금액'
ws['F1'] = '평가손익'
ws['G1'] = '수익률'
ws['A2'] = '삼성전자'
ws['A3'] = 'SK하이닉스'
ws['A4'] = '카카오'
ws['C2'] = 85100
ws['C3'] = 120000
ws['C4'] = 145000
ws['D2'] = 20
ws['D3'] = 15
ws['D4'] = 10
for i in range(2, 5):
ws['E'+str(i)] = '-'
ws['F'+str(i)] = '#######'
ws['G'+str(i)] = '=100%'
wb.save('주식현재가.xlsx') #엑셀 저장
codes = [
'005930',
'000660',
'035720'
]
prices = []
for code in codes:
url = f'https://finance.naver.com/item/sise.naver?code={code}'
response = requests.get(url)
html = response.text
soup = BeautifulSoup(html, 'html.parser')
price = soup.select_one("#_nowVal").text
price = price.replace(',','')
prices.append(price)
fpath = r'/Users/kimsongha/Projects/2022-여름/(기)이진크/주식현재가.xlsx'
wb = openpyxl.load_workbook(fpath) #엑셀 불러오기
#ws = wb.active -> 현재 활성화 된 시트를 가지고 온다.
ws = wb['실습과제_주식']
for i in range(2, 5):
ws['B'+str(i)] = prices[i-2] #인덱스 범위 잘 확인하기
wb.save(fpath)
Master Student @ KU👩🏻🎓