🔬 실전 프로젝트 3) 상품 정보 데이터 수집하기
1. 셀레니움 기초 사용법 정리
request의 한계
- 로그인이 필요한 사이트에 대해 크롤링이 어려움 (가능하긴 하지만 세션처리가 어려움)
- 동적으로 HTML을 만드는 경우 크롤링이 어려움
- 동적으로 HTML 만드는 경우- 스크롤하거나 클릭하면 데이터가 생성됨
- URL 주소가 변경되지 않앗는데 데이터가 변함
- 표, 테이블 형태의 데이터
셀레니움이란?
웹 어플리케이션 테스트를 위한 도구이며 브라우저를 실제로 띄워서 사람처럼 동작하도록 만들 수 있다. 셀레니움을 사용하기 위해서 크롬 드라이버를 다운로드 받아야하고 셀레니움 라이브러리를 설치해야한다.
pip install selenium아래 사이트에 들어가서 크롬 드라이버를 설치해준다.
👉 https://chromedriver.chromium.org/downloads
맥북의 경우, homebrew를 이용하여 설치할 수 있다. 아래의 코드를 터미널에 입력하면 크롬드라이버를 설치할 수 있다. 또한 맥북을 사용한다면, 접근 권한도 부여해야하는데 그 아래 코드를 통하여 크롬 드라이버를 사용할 수 있다.
brew install --cask chromedriver #chromedirver 설치
#chromedriver 권한부여, 인터넷에서 다운받아도 아래 코드는 적용해야한다.
xattr -d com.apple.quarantine /opt/homebrew/bin/chromedriver이제, 크롬 브라우저를 하나 생성해보자. 아래는 셀레니움과 크롬 드라이버를 사용하여 네이버 브라우저를 하나 띄우는 코드이다.
from selenium import webdriver
browser = webdriver.Chrome() #브라우저 생성
browser.get('https://www.naver.com') #웹사이트 열기
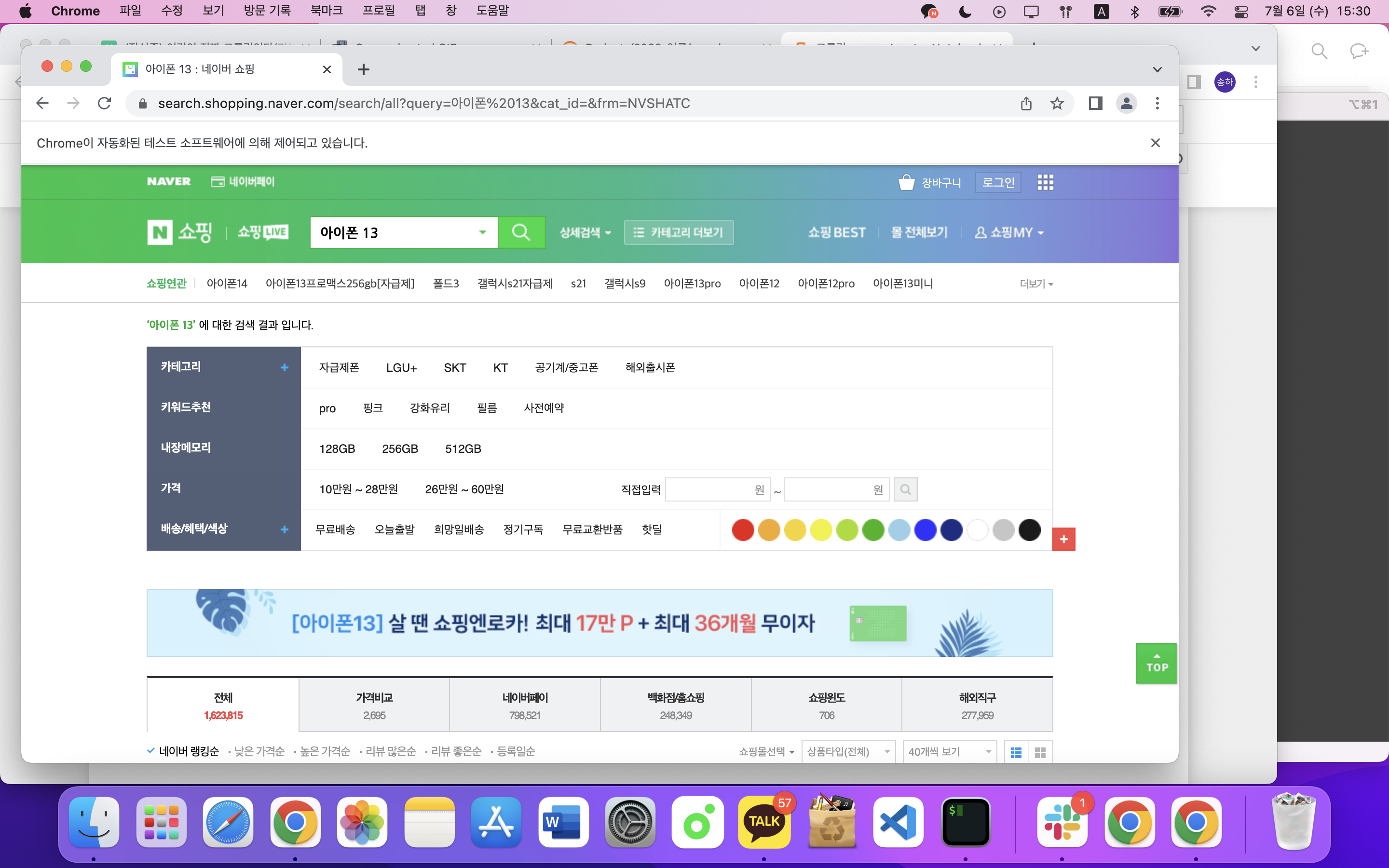
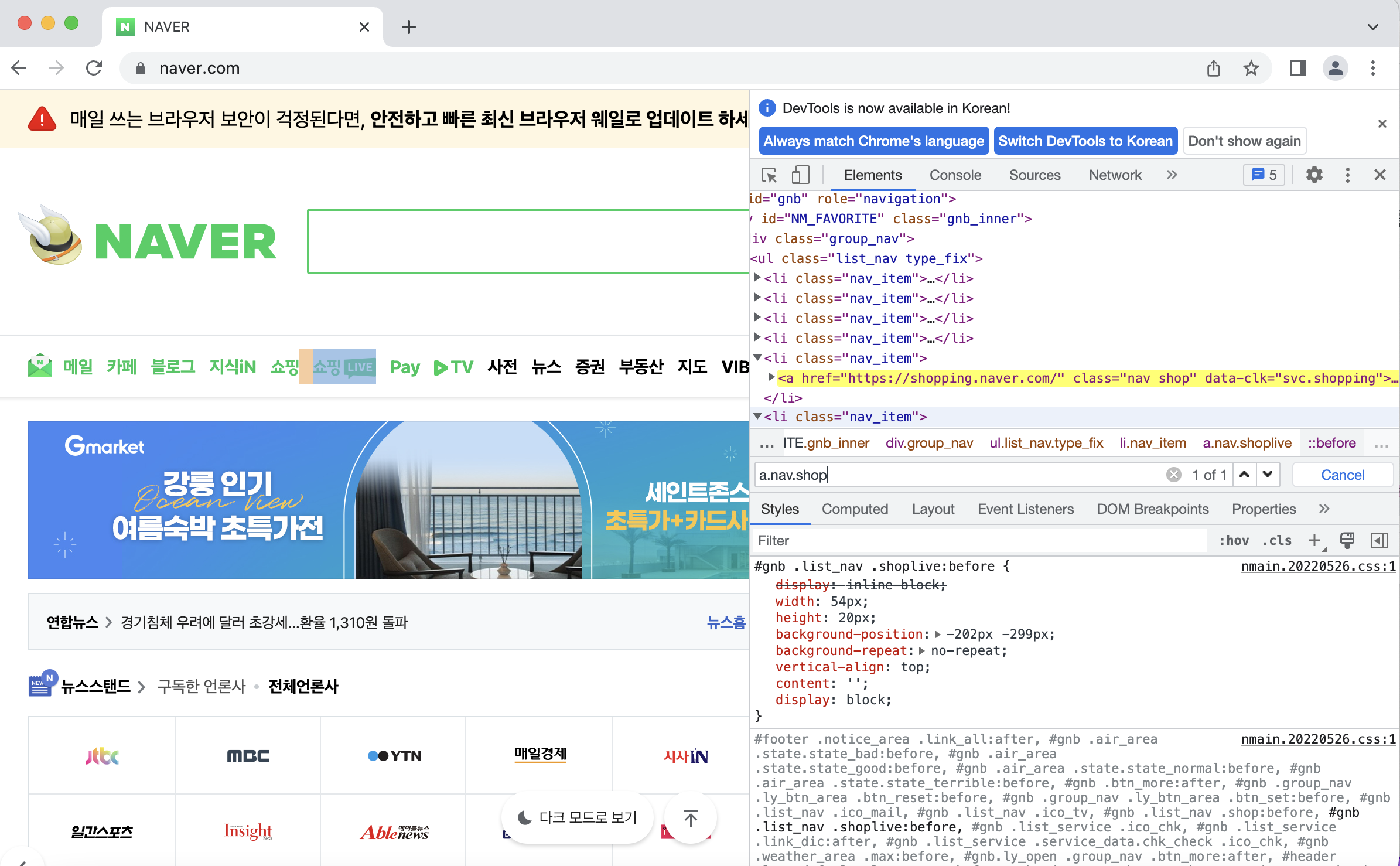
이제 새로운 브라우저에서 크롤링을 해보자. 먼저 개발자 도구를 사용해서 쇼핑을 찾아보고, CSS 선택자를 정하자. 여기서는 a.nav.shop으로 정하였다.
이제 브라우저를 키면 자동으로 네이버 쇼핑까지 가서 아이폰 13을 검색하는 코드를 작성해보자. 셀레니움 4.3.0 버전부터 find_element 메서드만 사용할 수 있으므로 주의해서 코드를 작성하면 다음과 같다.
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.chrome.options import Options
import time
import warnings
chrome_options = Options()
chrome_options.add_experimental_option("excludeSwitches", ["enable-logging"]) # 셀레니움 로그 무시
warnings.filterwarnings("ignore", category=DeprecationWarning) # Deprecated warning 무시
browser = webdriver.Chrome(options = chrome_options)
browser.get('https://www.naver.com')
browser.implicitly_wait(10) #로딩이 끝날동안 10초 기다린다
browser.find_element(By.CSS_SELECTOR, 'a.nav.shop').click() #쇼핑메뉴 클릭
time.sleep(2)
#검색창 클릭
search = browser.find_element(By.CSS_SELECTOR, 'input._searchInput_search_input_QXUFf')
search.click()
#검색어 입력
search.send_keys('아이폰 13')
search.send_keys(Keys.ENTER)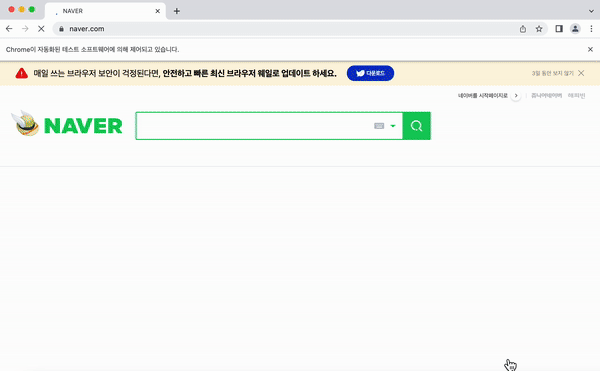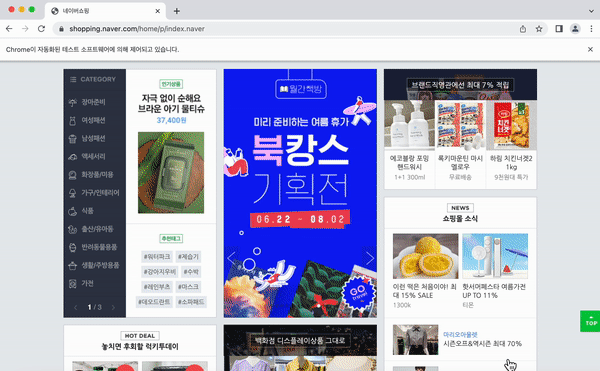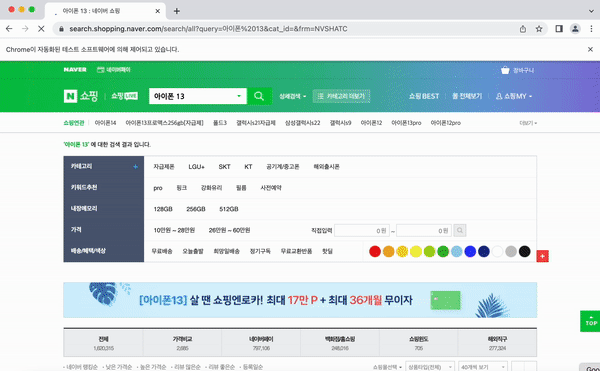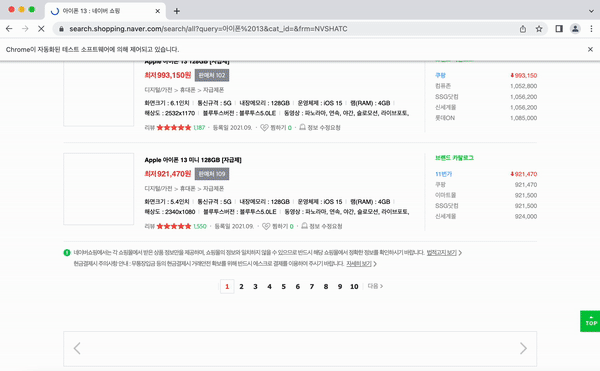
이렇게 브라우저가 켜지고 바로 네이버 쇼핑으로 이동하여 아이폰 13을 검색하는 것을 확인할 수 있다.
2. 네이버 쇼핑 상품 정보 수집하기
무한 스크롤 처리 방법
현재 스크롤된 높이를 알 수 이쓴 자바스크립트 명령어를 이용한다
- window.scrollY
앞에서 진행했던 실습을 응용하여 페이지 끝까지 스크롤 하여 상품의 이름과 가격, 링크를 가져오는 실습을 해보자.
개발자 도구로 html을 분석한 뒤 어떤 것을 가져올지 정한 뒤 코드를 짜면 아래와 같다.
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.chrome.options import Options
import time
import warnings
chrome_options = Options()
chrome_options.add_experimental_option("excludeSwitches", ["enable-logging"]) # 셀레니움 로그 무시
warnings.filterwarnings("ignore", category=DeprecationWarning) # Deprecated warning 무시
browser = webdriver.Chrome(options = chrome_options)
browser.get('https://www.naver.com')
browser.implicitly_wait(2) #로딩이 끝날동안 2초 기다린다
browser.find_element(By.CSS_SELECTOR, 'a.nav.shop').click() #쇼핑메뉴 클릭
time.sleep(2)
#검색창 클릭
search = browser.find_element(By.CSS_SELECTOR, 'input._searchInput_search_input_QXUFf')
search.click()
#검색어 입력
search.send_keys('아이폰 13')
search.send_keys(Keys.ENTER)
#무한 스크롤
before_h = browser.execute_script("return window.scrollY")
while True:
browser.find_element(By.CSS_SELECTOR, 'body').send_keys(Keys.END) #맨 아래로 스크롤 내림
time.sleep(2) #스크롤 사이 페이지 로딩 시간
after_h = browser.execute_script("return window.scrollY")
if after_h == before_h:
break
before_h = after_h
#상품 정보 div
items = browser.find_elements(By.CSS_SELECTOR, '.basicList_info_area__17Xyo')
for item in items:
name = item.find_element(By.CSS_SELECTOR, '.basicList_title__3P9Q7').text
try:
price = item.find_element(By.CSS_SELECTOR, '.price_num__2WUXn').text
except:
price = "판매중단"
link = item.find_element(By.CSS_SELECTOR, '.basicList_title__3P9Q7 > a').get_attribute('href')
print(name, price, link)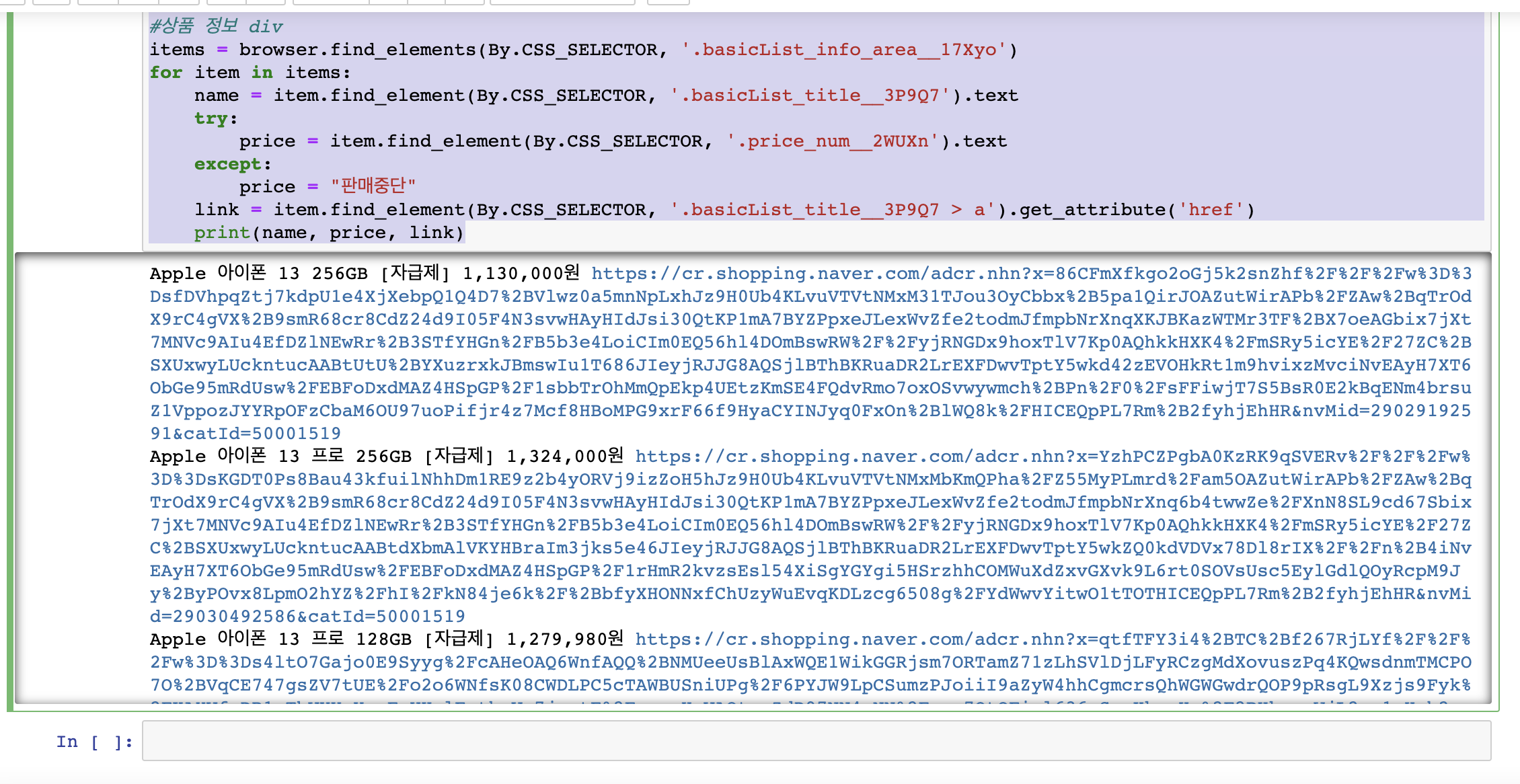
마지막으로 크롤링 결과를 csv 파일에 저장해보자
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.chrome.options import Options
import time
import csv
import warnings
chrome_options = Options()
chrome_options.add_experimental_option("excludeSwitches", ["enable-logging"]) # 셀레니움 로그 무시
warnings.filterwarnings("ignore", category=DeprecationWarning) # Deprecated warning 무시
browser = webdriver.Chrome(options = chrome_options)
browser.get('https://www.naver.com')
browser.implicitly_wait(2)
browser.find_element(By.CSS_SELECTOR, 'a.nav.shop').click()
time.sleep(2)
search = browser.find_element(By.CSS_SELECTOR, 'input._searchInput_search_input_QXUFf')
search.click()
search.send_keys('아이폰 13')
search.send_keys(Keys.ENTER)
before_h = browser.execute_script("return window.scrollY")
while True:
browser.find_element(By.CSS_SELECTOR, 'body').send_keys(Keys.END) #맨 아래로 스크롤 내림
time.sleep(2)
after_h = browser.execute_script("return window.scrollY")
if after_h == before_h:
break
before_h = after_h
f = open(r'/Users/kimsongha/Projects/2022-여름/craw/data.csv', 'w', encoding='CP949', newline='')# 파일 생성
cswriter = csv.writer(f)
items = browser.find_elements(By.CSS_SELECTOR, '.basicList_info_area__17Xyo')
for item in items:
name = item.find_element(By.CSS_SELECTOR, '.basicList_title__3P9Q7').text
try:
price = item.find_element(By.CSS_SELECTOR, '.price_num__2WUXn').text
except:
price = "판매중단"
link = item.find_element(By.CSS_SELECTOR, '.basicList_title__3P9Q7 > a').get_attribute('href')
print(name, price, link)
cswriter.writerow([name, price, link]) #데이터 쓰기
f.close() #파일 닫기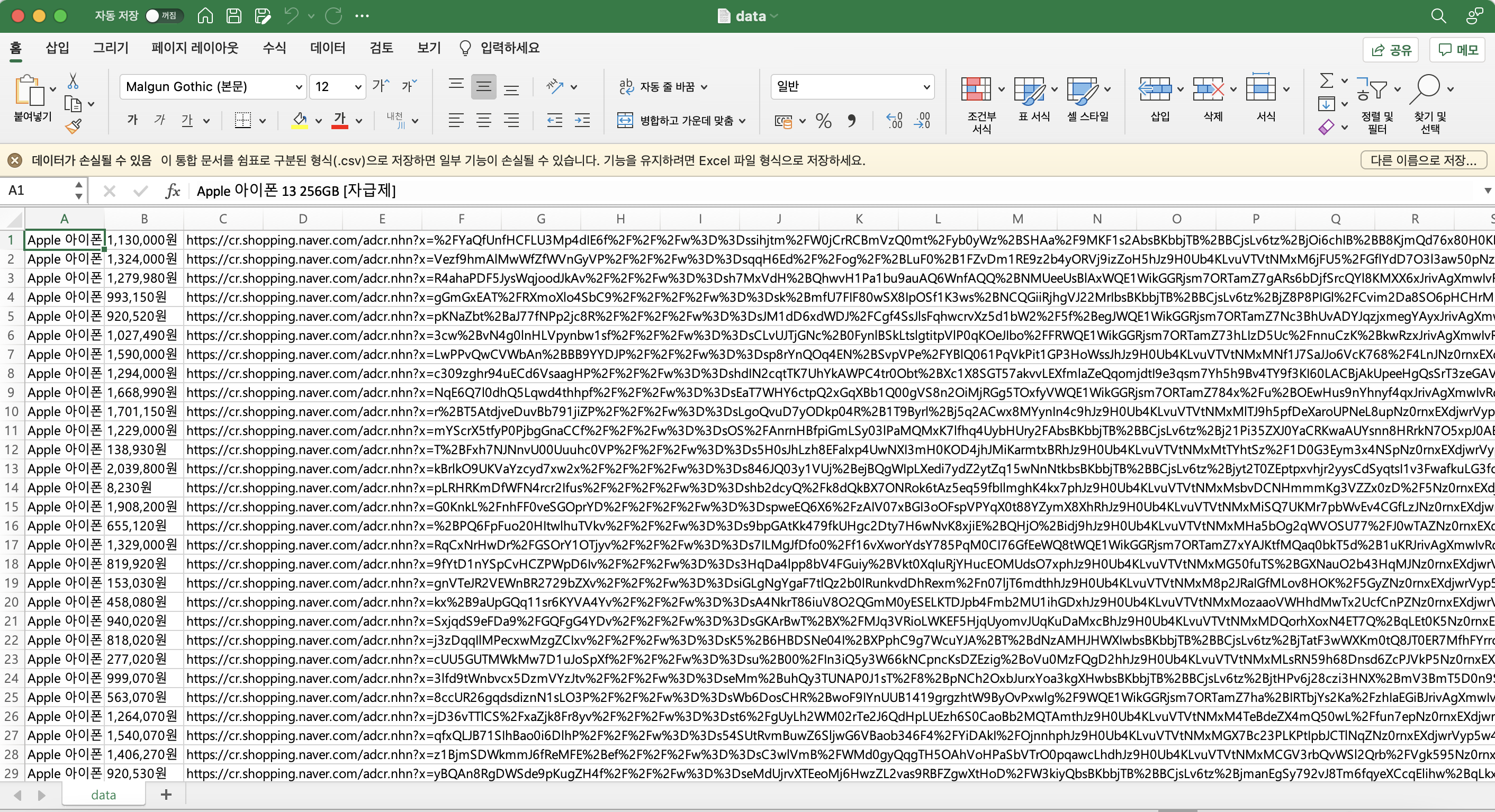
csv 파일로 잘 저장된 것을 확인할 수 있다.
3. Bonus
웹사이트 자동화
웹사이트 자동화에는 크롤링, 로그인, 업로드, 다운로드, 좋아요 등이 있다
셀레니움 업데이트 하는 법
셀레니움 4로 업데이트 하기 위해 다음과 같은 코드를 터미널에 입력한다
pip install --upgrade pip
pip install --upgrade selenium웹드라이버 자동 업데이트
웹 드라이버를 자동으로 업데이트 하기 위해 다음과 같은 코드를 터미널에 입력한다
pip install webdriver_manager셀레니움 기본설정
#셀레니움 기본설정
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from webdriver_manager.chrome import ChromeDriverManager #크롬 드라이버 자동 업데이트
chrome_options = Options()
chrome_options.add_experimental_option("detach", True) #브라우저 꺼짐 방지
chrome_options.add_experimental_option("excludeSwitches", ["enable-logging"]) #불필요한 에러 메세지 없애기
service = Service(executable_path = ChromeDriverManager().install())
driver = webdriver.Chrome(service = service, options = chrome_options)
driver.get('https://www.naver.com')📍 실습
네이버 로그인 화면에서 로그인을 해보자~
#네이버 로그인 자동화
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from webdriver_manager.chrome import ChromeDriverManager #크롬 드라이버 자동 업데이트
from selenium.webdriver.common.by import By
import time
import pyautogui
import pyperclip
chrome_options = Options()
chrome_options.add_experimental_option("detach", True) #브라우저 꺼짐 방지
chrome_options.add_experimental_option("excludeSwitches", ["enable-logging"]) #불필요한 에러 메세지 없애기
service = Service(executable_path = ChromeDriverManager().install())
driver = webdriver.Chrome(service = service, options = chrome_options)
driver.implicitly_wait(2) #웹페이지 로딩 기다림
driver.maximize_window() #화면 최대화
driver.get('https://nid.naver.com/nidlogin.login?mode=form&url=https%3A%2F%2Fnid.naver.com%2Fuser2%2Fhelp%2FmyInfoV2%3Flang%3Dko_KR')
id = driver.find_element(By.CSS_SELECTOR, '#id') #아이디 입력창
id.click()
pyperclip.copy('본인id')
pyautogui.keyDown('command')
pyautogui.press('v')
pyautogui.keyUp('command')
pw = driver.find_element(By.CSS_SELECTOR, '#pw') #아이디 입력창
pw.click()
pyperclip.copy('본인password')
pyautogui.hotkey('command', 'v')
login_btn = driver.find_element(By.CSS_SELECTOR, '#log\.login') #로그인 버튼
login_btn.click()위 코드를 실행하면 다음과 같이 오류없이 자동 로그인 된다.
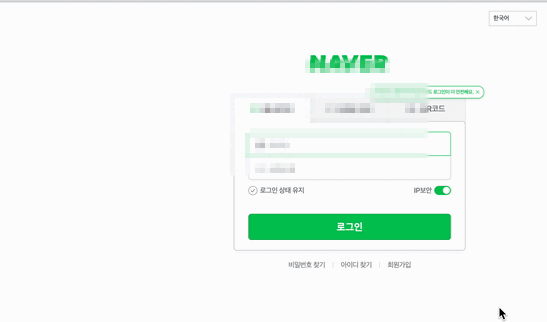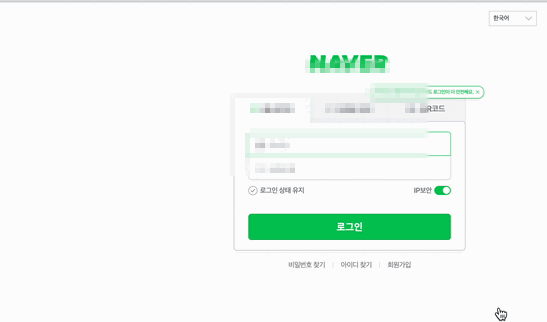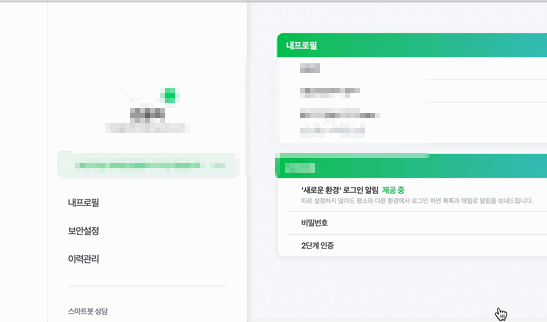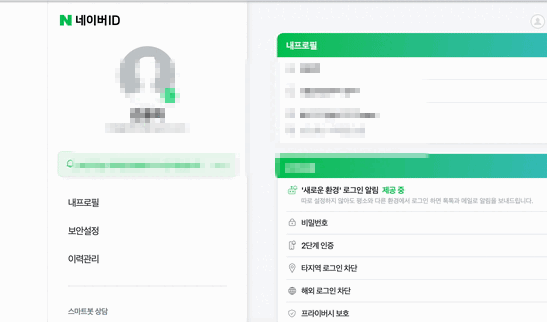
(개인정보 보호때문에 잘은 안보이지만 오류없이 작동하고 있다.)
