딥러닝 기반 얼굴 인식 모델
전체 개요
목표 : 얼굴의 시선 방향 예측
사람이 정면(straight), 좌(left), 우(right), 위(up)을 바라보는지를 예측한다.
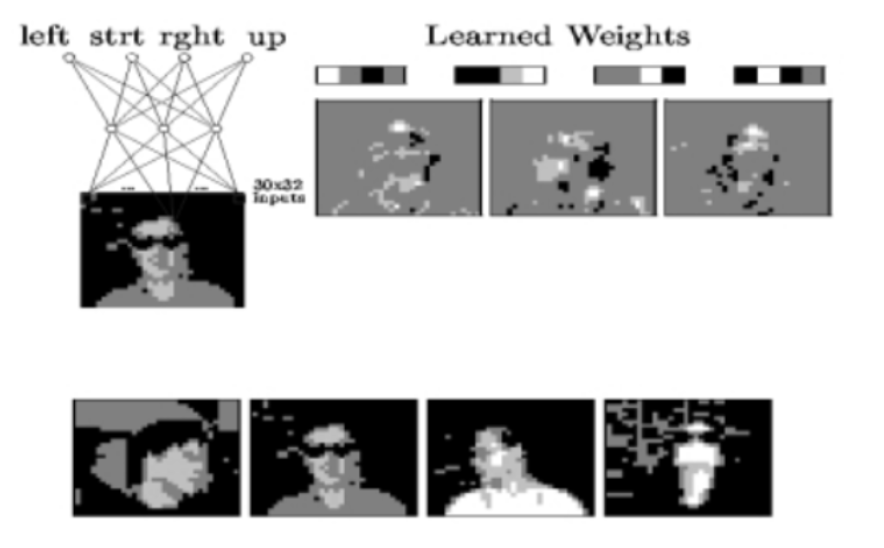
- 입력 : 사람의 얼굴 이미지 (흑백)
- 출력 : 그 사람이 어디를 바라보는지 예측 (left, right, straight, up)
1. 데이터 구성과 특징
- 총 624장의 이미지 (20명 * 32장)
- 해상도 : 120 * 128 픽셀
- 각 사람의 이미지 속성은 다양함
- 표정 : happy, sad, angry, neutral
- 시선 방향 : left, right, straight, up
- 선글라스 유무
2. 입력 인코딩 (input encoding)
- Feature Extraction (수작업 특징 추출)
- 경계선 (edge), 밝기 변화 등 중요한 정보만 추출해서 입력값 구성
- 단점 : 사람이 직접 특징 설계해야함 → 고비용, 유연성 부족
- Coarse-resolution (저해상도 압축)
- 120 128 원본 이미지를 30 32 크기로 줄여서 사용
- 총 960 픽셀 → 960개의 입력 뉴런
- 장점
- 계산량 감소
- 고정된 차원으로 입력 가능
- 사전 특징 설계 없이 전체 이미지 학습 가능
3. 출력 인코딩 (output encoding)
- Multiple unit (one-hot-encoding) ✅
- 4개의 출력 노드 사용
- 각 노드는 특정 방향을 나타냄
- 예 : [1, 0, 0, 0] → left
- Softmax와 함께 사용하여 확률로 해석 가능
- Single unit + thresholds ❌
- 출력 노드 1개 → 임계값을 나눠서 방향 구분
- 해석이 복잡해지고 정확도가 낮아짐
4. 신경망 구조 (Network Architecture)
기본 구조
- 입력층 : 960개 뉴런 (30 * 32 이미지)
- 은닉층 : 1개
- 출력층 : 4개 (one-hot)
실험
- 은닉 유닛 3개 → 정확도 90%, 학습시간 5분
- 은닉 유닛 30개 → 정확도 91.5%, 학습시간 1시간
트래이드오프
- 은닉 유닛을 늘리면 표현력은 좋아지지만, 학습시간 증가 및 과적합 위험이 있다.
5. 하이퍼파라미터 (Hyperparameters)
- learning rate : 가중치 업데이트 속도 결정
- epoch 수 : 전체 데이터를 몇 번 학습할지
- batch size : 한 번에 학습에 사용하는 데이터 개수
→ 이 값들은 모델의 성능에 큰 영향을 준다.
→ 너무 크면 발산, 너무 작으면 느림
6. 모델 시각화 & 예시
네트워크 구조
- 30 * 32 픽셀 얼굴 이미지를 입력받아, 4개의 방향 중 하나 예측
- 중간 은닉층에선는 다양한 시각 특징 학습
- 눈 위치, 윤곽선, 머리 기울기 등
- 우측의 learned weights 이미지들은 각 출력 노드(방향)에 대응하는 학습된 필터들
시각적 예
- 각 방향에 따라 강조되는 이미지 패턴이 다른
