
주소창에 네이버, 구글과 같은 URL을 검색하면 웹이 어떻게 작동하는지 알아보자! 😀😀😀
💁♀️ 주소창에 URL을 검색하면
1. 브라우저가 데이터를 받는다. (웹 페이지 요청, 서버응답)
2. 브라우저 렌더링 과정을 통해 웹 노출한다. (CRP 과정)
브라우저가 데이터를 받는 과정
🟨 1. URL 검색

🟨 2. 브라우저는 캐싱된 DNS 기록을 통해 URL에 대응하는 IP주소 여부 확인
✏️ 브라우저가 DNS 서버에서 URL의 IP 주소 확인
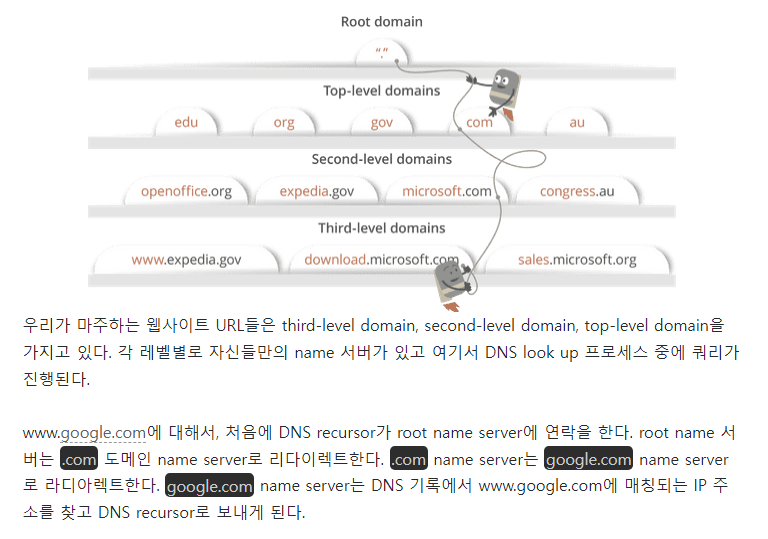
- URL의 고유 IP를 통해 네이버 웹사이트를 호스팅하는 서버 컴퓨터에 접근
- DNS(Domain Name System) : 전화번호부 같은 역할! / URL들 이름, IP주소를 저장하는 데이터베이스 / 웹사이트 이름들과 웹사이트를 접근하기 위해 필요한 IP주소를 저장하고 있다.
- DNS 목적 : 사용자에게 편리함을 선사 / 숫자로 된 IP 주소를 작성해도 웹사이트 접속이 가능하지만 사람들이 웹사이트에 쉽게 접속할 수 있게 매핑(도메인 이름을 해당 웹사이트 IP 주소로 변환하는 과정)을 해주는 역할을 한다.
- 웹사이트 이름을 브라우저에 검색하면 브라우저는 DNS 기록을 4가지의 캐시(자주 사용되는 데이터를 임시로 저장해 두는 저장 공간)에서 확인한다.
- 브라우저 캐시 : 브라우저가 저장한 DNS 기록. 브라우저는 일정기간 동안(유저가 이전에 설정한)의 DNS 기록을 저장하고 있다. DNS query가 이 곳에서 가장 먼저 실행
- 운영체제(OS) 캐시 : OS가 저장한 DNS 기록. 컴퓨터의 운영체제가 저장해둔 DNS 기록이다. 시스템 호출(system call)을 통해 OS가 저장하고 있는 DNS 기록들의 캐시에 접근
- router 캐시 : 라우터가 저장한 DNS 기록. 집, 사무실에서 사용하는 라우터가 저장해둔 DNS 기록이다. 브라우저는 router와 통신하여 router의 캐시 확인
- ISP 캐시 : ISP의 DNS 서버가 저장한 DNS 기록. ISP 캐시는 ISP(인터넷 서비스 제공업체)가 관리하는 DNS 기록이다. ISP의 DNS 서버에 요청을 보내서 캐시 확인
🟨 3. 브라우저가 서버와 TCP connection
✏️ 브라우저가 요청 보내기 전 서버와의 통신 준비를 위해 TCP 연결 설정(three-way handshake)
- 브라우저가 올바른 IP 주소를 받게 되면 서버와 connection을 빌드한다. IP 주소를 가진 서버와 인터넷 프로토콜을 사용해 연결을 시도한다.
- 다양한 인터넷 프로토콜이 있지만, HTTP 요청 시 TCP(Transmission Control Protocol : 전송 제어 프로토콜 / 데이터가 제대로 전달되도록 보장하는 프로토콜)를 사용한다.
- IP : 패킷들이 가장 효율적인 방법으로 최종 목적지로 갈 수 있도록 해주는 프로토콜
- TCP : IP의 상위버전, 신뢰성 있고 무결성을 보장하는 연결을 통해 데이터를 안전하게 전송해주는 전송 프로토콜 / 도착한 패킷(데이터 조각)들을 점검해서 줄을 세우고 망가지거나 빠진 부분을 다시 요청해서 데이터 통신을 진행
- TCP 연결 설정, 브라우저와 서버 간에 안정적인 연결을 위해 three-way handshake라는 프로세스를 사용
- three-way handshake : 브라우저와 서버가 SYN, ACK메세지들을 가지고 3번의 프로세스를 거친 후 연결
- 브라우저 : 통신 시작할까요?(SYN) / 클라이언트(브라우저)는 SYN 패킷(TCP 연결 시작을 위해 클라이언트가 서버에 보내는 신호)을 서버에 보내 연결 요청
- 서버 : 좋아요!(SYN/ACK 패킷) / 서버는 SYN/ACK 패킷을 보내 클라이언트 요청 수락 후 응답
- 브라우저 : 시작해요! (ACK 패킷) / 클라이언트는 ACK 패킷을 보내 연결 완료 확인
- TCP connection 완성!
- three-way handshake : 브라우저와 서버가 SYN, ACK메세지들을 가지고 3번의 프로세스를 거친 후 연결
🟨 4. TLS Handshake
✏️ TLS 핸드쉐이크를 통해 서버와 연결 수립
브라우저→서버ClientHello ⇒
서버→브라우저ServerHello 및 Certificate ⇒
브라우저→서버ClientKeyExchange ⇒
브라우저→서버Finished ⇒
서버→브라우저Finished
🟨 5. 브라우저가 웹 서버에 HTTP 요청
✏️ 브라우저가 HTTP 프로토콜을 사용해 요청 메시지 생성
-
TCP 연결이 완료되었다면, 데이터를 전송
-
브라우저는 GET 요청을 통해 서버에게 URL 웹페이지를 요구한다.
-
요청 시 부가적인 정보들도 함께 전달된다.
-
borwser identification(User-Agent 헤더)
-
받아들일 요청의 종류 (Accept 헤더)
-
추가적인 요청을 위해 TCP connection의 유지를 요청하는 connection 헤더
-
브라우저에서 얻은 쿠키 정보
-
기타 등등…
- TCP 연결이 완료되었다면, 데이터를 전송한다.
- 브라우저는 GET 요청을 통해 서버에게 URL 웹페이지를 요구한다.
- 요청 시 부가적인 정보들도 함께 전달된다.
- borwser identification(User-Agent 헤더)
- 받아들일 요청의 종류 (Accept 헤더)
- 추가적인 요청을 위해 TCP connection의 유지를 요청하는 connection 헤더
- 브라우저에서 얻은 쿠키 정보
- 기타 등등…

- 요청 시 부가적인 정보들도 함께 전달된다.
-
-
🟨 6. 서버가 요청을 처리하고 response를 생성
✏️ 서버가 요청 처리 후 HTTP response 생성
- 서버는 브라우저의 요청을 받고 request handler한테 요청을 전달하여 요청을 읽고 response를 생성한다.
- Request handler
- ASP.NET, PHP, Ruby 등으로 작성된 프로그램
- 요청과 요청의 헤더, 쿠키를 읽어 요청 파악하고 필요 시 서버 정보 업데이트
- response 특정한 포맷(JSON, XML, HTML)으로 작성
- 서버는 브라우저의 요청을 받고 request handler한테 요청을 전달하여 요청을 읽고 response를 생성한다.
🟨 7. 서버가 HTTP response를 보냄
✏️ 인터넷을 통해 URL 서버로 전달
- 서버가 브라우저의 요청을 처리한 후, HTTP 응답을 브라우저에 보낸다.
- 응답에는 여러 정보가 포함되어 있으며, 각 정보는 브라우저가 요청한 웹페이지를 올바르게 처리하고 표시하는 데 도움을 준다.
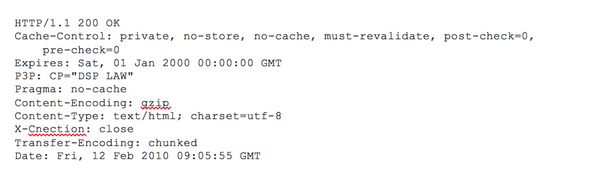
- HTTP 응답 주요 구성요소
- 상태 코드(status code) : 응답의 첫 줄 / response 상태 / 요청이 어떻게 처리되었는지 나타냄
- status code의 5가지 종류
1) 1xx : 정보만 담긴 메시지임을 의미
2) 2xx : response가 성공적임을 의미
3) 3xx : 클라이언트를 다른 URL로 리다이렉트함을 의미
4) 4xx : 클라이언트 측에서 에러 발생
5) 5xx : 서버 측에서 에러 발생
- status code의 5가지 종류
- 헤더(header) : 부가적인 정보 / 콘텐츠 인코딩 방식, 캐싱 방법, 쿠키 설정 등
- 본문(body) : 실제 요청한 웹페이지나 데이터
- 상태 코드(status code) : 응답의 첫 줄 / response 상태 / 요청이 어떻게 처리되었는지 나타냄
- HTTP 응답 주요 구성요소
브라우저 렌더링 과정 (CRP)
🟨 8. DOM 트리 생성
✏️ HTML 파일 다운로드 및 파싱 DOM 생성
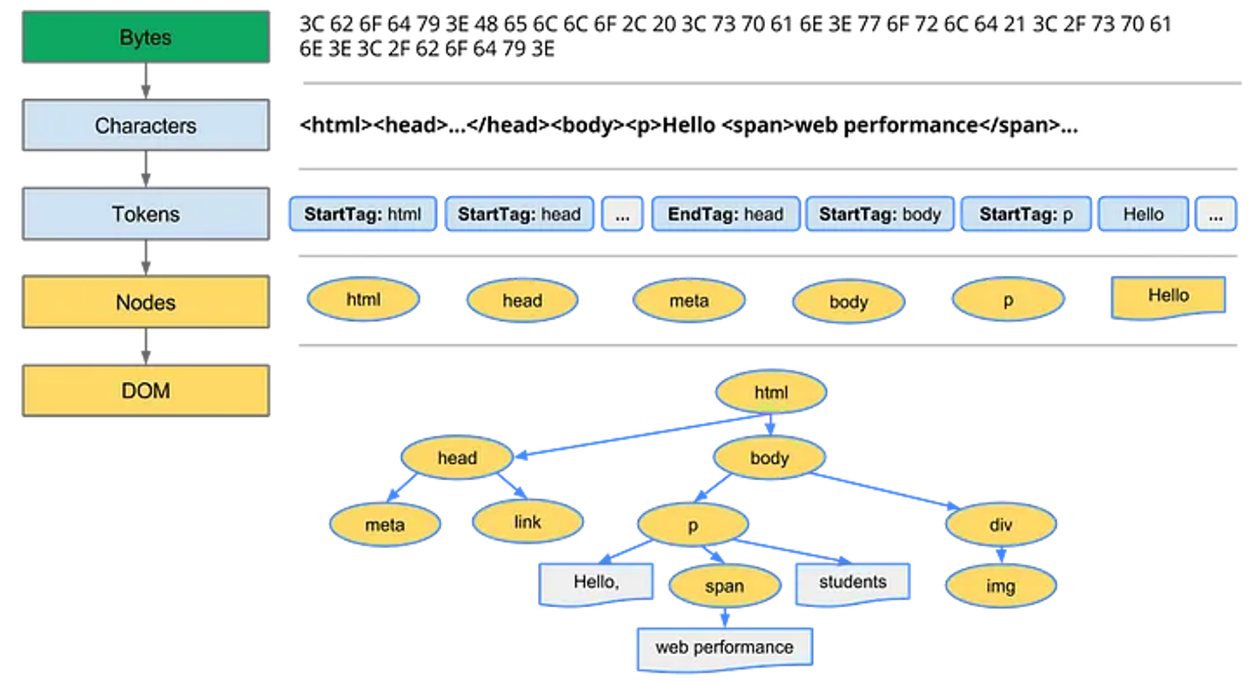
- 변환 : 바이트(UTF-8) → 문자
브라우저가 HTML의 원시바이트를 읽어오면 HTML에 정의된 인코딩 방법에 따라 문자로 변환한다. - 토큰화 : 문자 → 토큰
<,>,/문자에 따라 문자들을 토큰화(문자를 하나씩 읽고 코드를 해석) - 렉싱 : 토큰 → 노드
토근은 속성과 규칙에 맞는 “객체”로 변환 / 구조화 시킴 - DOM 생성 : 노드 → 객체 모델
트리 구조로 연결되어 최종적인 트리 형태의 DOM TREE 완성 / 관계 삽입
🟨 9. CSSOM 트리 생성
✏️ CSS파일 다운로드 및 파싱 CSSOM 생성
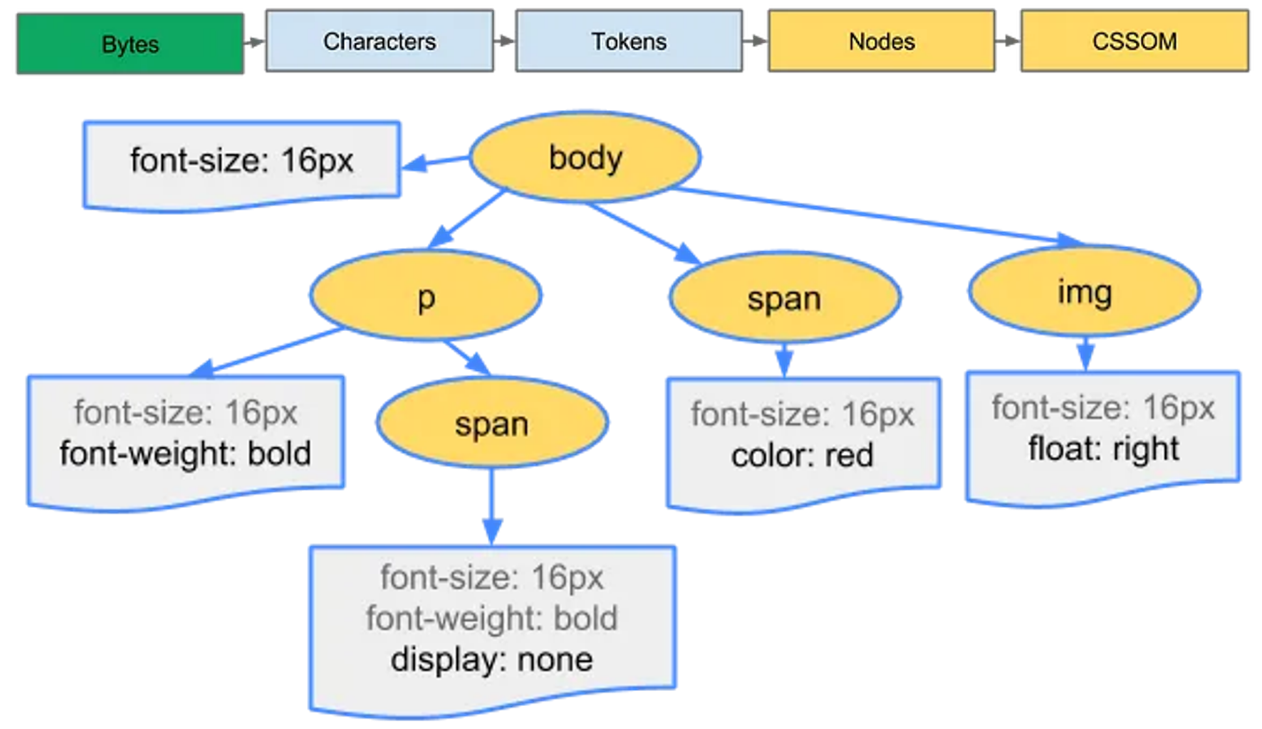
렌더링 엔진이 HTML파일을 파싱하면서 외부 CSS파일이나 style 태그를 만나게 되면 DOM트리 생성과 동일한 과정으로 CSSOM(CSS Object Model) 트리를 생성
css는 DOM의 생성을 막지 않기 때문에 상단에 위치해도 괜찮다!
DOM과 CSSOM이 모두 완성되어야 다음 스텝으로 넘어갈 수 있기 때문에 CSSOM도 빠르게 만들어지는게 중요하다!
CSS파일이 너무 큰 경우 ⇒ DOM이 오래 기다려야함 (필요한 CSS만 들고 오는것도 속도에 중요한 영향을 미친다. 웹 성능 개선에 중요한 영향을 미친다.)
🟨 10. 자바스크립트 파싱
✏️ 자바스크립트 다운로드 및 파싱
렌더링 엔진은 HTML 문서를 한줄씩 파싱하며 DOM을 생성하는데, 자바스크립트 파일을 로드하는 script태그를 만나면 DOM 생성을 일시 중단한다.(그래서 스크립트 파일을 하단에다 두라고 하는거임!) script의 src 주소를 서버에 요청하고, 자바스크립트 엔진에게 제어권을 넘겨 자바스크립트 코드를 파싱한다.
파싱이 끝나면 다시 렌더링 엔진이 제어권을 갖고 DOM 생성을 이어나간다.
렌더링 엔진의 제어권을 중간에 넘기지 않기 위해 script태그에 defer를 추가하는 것이다. (스크립트파일이 상단에 있어도 접근가능!)

🟨 11. 렌더 트리 생성
✏️ DOM과 CSSOM 결합하여 렌더트리 생성
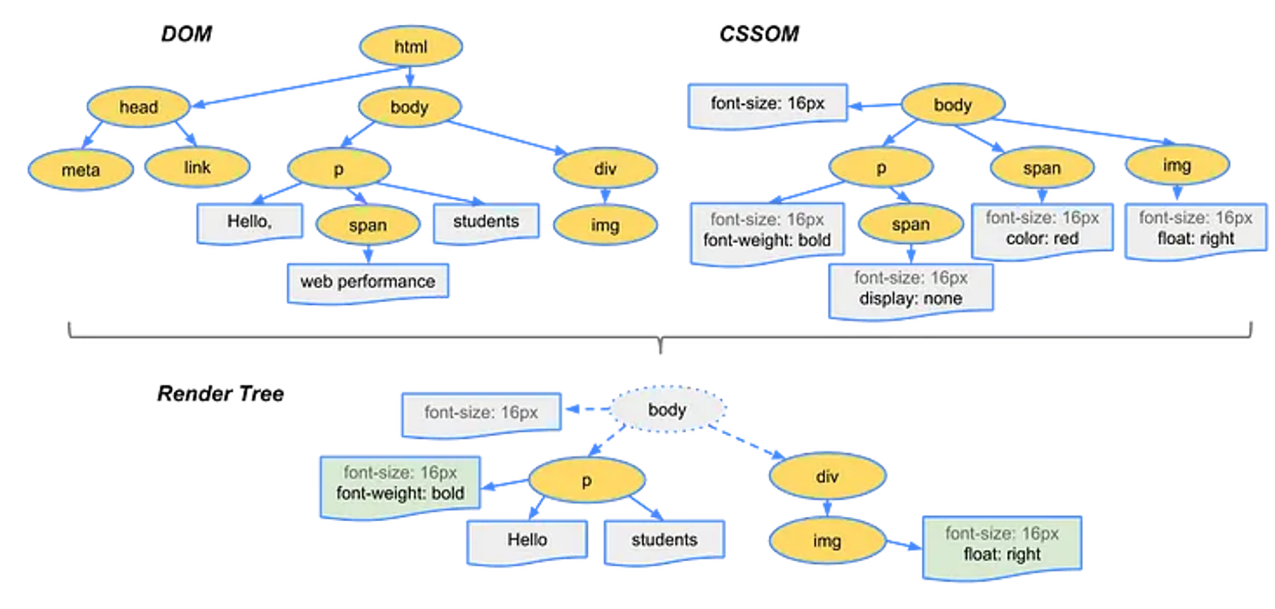
- 렌더트리 : 진짜 웹사이트를 그리기 위한 최종 설계도
- DOM트리와 CSSOM트리가 생성되면 둘을 결합해 렌더링 트리를 생성한다. 렌더링 트리에는 페이지를 렌더링 하는데 필요한 노드만 포함된다.
🟨 12. 레이아웃 단계 (Reflow)
✏️ Reflow
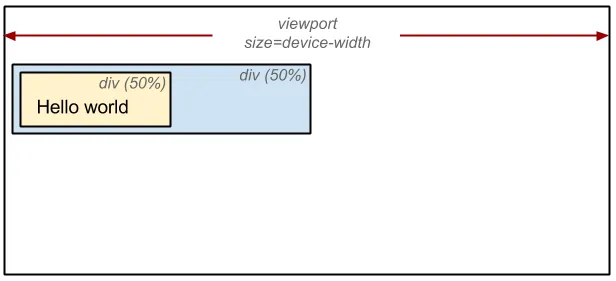
- 뷰포트 내 각 요소의 정확한 위치, 크기를 계산한다. %, rem 처럼 상대적인 값은 px단위로 변환한다.
🟨 13. 페인팅 단계 (Repaint)
✏️ Repaint
- 레이아웃 단계에서 계산된 값을 실제 픽셀로 변환하여 레이어별로 출력한다. (포토샵처럼)
- 여러장의 레이어로 만드는 이유 : 하나의 레이어에 다 그리면 나중에 바뀐 요소를 위해서 다시 처음부터 다 그려야하는데 레이어별로 그려두면 나중에 바뀐 요소가 포함된 레이어만 바꿔주면 되니까 효율적인 페인팅이 가능!
🟨 14. 컴포짓
✏️ 나눠진 레이어를 합쳐서 화면에 표시
- 레이어 합치기
🟨 15. 이후 단계
- Reflow
사용자 액션 수행 시 발생되는 이벤트로 인해 새로운 HTML요소가 추가되거나 스타일 변경 시 영향을 받는 모든 노드에 대해 렌더링 트리 생성과 레이아웃 과정을 재수행한다. Reflow가 일어나면 반드시 Repaint도 일어난다!- Reflow가 될 때
- 페이지 초기 렌더링 시 (최초 Layout과정)
- 윈도우 리사이징 시 (Viewport 크기 변경 시)
- 노드(html 태그) 추가 또는 제거
- 요소 위치, 크기 변경(left, top, margin, padding, border, width, height 등…)
- 폰트 변경(텍스트 내용)과 이미지 크기 변경(크기가 다른 이미지로 변경 시)
- Reflow가 일어나는 대표적인 속성들 :
position, width, height, margin, padding, border, border-width, font-size, font-weight, line-height, text-align, overflow
- Reflow가 될 때
- Repaint
변경사항을 실제 화면에 그려지기 위해 페인팅 단계를 재수행한다.- Repaint가 일어나는 대표적인 속성들 :
background, color, text-decoration, border-style, border-radius
- Repaint가 일어나는 대표적인 속성들 :

읽을 때마다 새로운 지식을 얻게 되는 신기한 CS 세상
오늘도 복습 끝🫶
✅ 참고
https://velog.io/@dmsgp220/%EC%A3%BC%EC%86%8C%EC%B0%BD%EC%97%90-www.google.com-%EC%9E%85%EB%A0%A5%ED%95%98%EB%A9%B4-%EC%9D%BC%EC%96%B4%EB%82%98%EB%8A%94-%EC%9D%BC
https://medium.com/%EA%B0%9C%EB%B0%9C%EC%9E%90%EC%9D%98%ED%92%88%EA%B2%A9/%EB%B8%8C%EB%9D%BC%EC%9A%B0%EC%A0%80%EC%9D%98-%EB%A0%8C%EB%8D%94%EB%A7%81-%EA%B3%BC%EC%A0%95-5c01c4158ce
https://devjin-blog.com/what-happen-browser-search/
