
ResNet
2015년에 개최된 ILSVRC에서 우승을 한 모델은 ResNet이다. 이 ResNet은 마이크로소프트에서 개발한 알고리즘이다. ResNet의 중요한 점은 2014년의 GoogLeNet이 22개 층으로 구성된 것에 비해, ResNet은 152개 층을 갖는다는 것이다. 1년 사이에 네트워크가 약 7배가 깊어진 것이다.
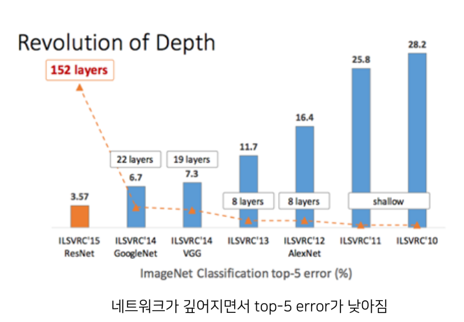
기존의 CNN 모델들은 네트워크가 깊어지면 성능이 좋아진다고 가정했기 때문에 모델을 깊게 만들려고 했다.
그러나 vanishing gradient나 exploding gradient가 발생하여 성능저하가 생겼는데, 이를 해결하기 위해 웨이트의 초기화를 적절히 설정하거나, batch normalization으로 정규화를 하는 방법을 사용하였었다. 따라서 가중치값이 매우 작아지거나 커지는 현상을 막았지만, 여전히 특정 레이어 개수 이상으로 깊어지게 되면 오류율이 증가하였다.
그러나 이는 과적합이 되어 생기는 현상으로 보았는데, 마이크로소프트는 이러한 현상이 오버피팅의 문제가 아니라고 생각하였다.
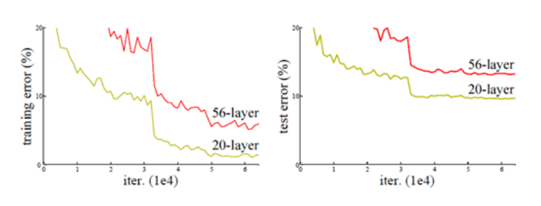
위 차트는 같은 조건을 가진 20개의 레이어와 56개의 레이어를 가지고 실험을 한 것인데, 테스트 데이터를 가지고 실험을 했을 때를 보면, 더 깊은 56개의 레이어 모델이 에러율이 더 높은 것을 확인할 수 있다.
그러나 트레이닝 데이터로 실험을 했을 때에도, 더 깊은 56개의 레이어 모델이 에러율이 높은데, 과적합은 훈련데이터에서는 좋은 성능이 나오는 것이므로, 이를 단순히 오버피팅의 문제라고 보기는 어렵다는 것이다.
따라서 마이크로소프트에서는 Residual Block을 해결방안으로 제시한다.

Residual Block
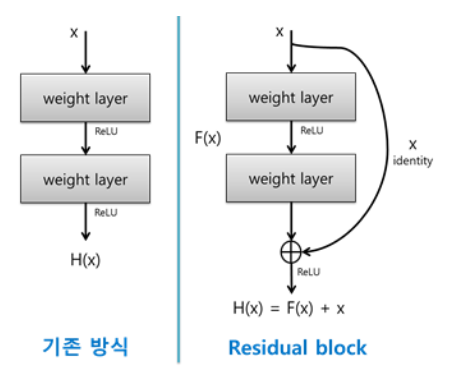
기존의 신경망은 입력값 x를 타겟값 y로 매핑하는 함수 H(x)를 얻는 것이 목적이었다. 따라서 H(x)-y 를 최소화하는 방향으로 학습을 진행한다.
이때 이미지 분류 문제의 경우 x에 대한 타겟값 y는 사실 인풋 x를 나타내는 것으로 y와 x가 동일한 의미를 가지게 mapping해야 한다.
따라서, ResNet은 F(x) = H(x)-x 를 최소화하는 것을 목적으로 한다.
이때 x는 현시점에서 변할 수 없는 값이므로 F(x)를 0에 가깝게 만드는 것이 목적이 된다.
F(x)가 0이 되면 출력과 입력이 모두 x로 같아지게 된다.
F(x) = H(x)-x 이므로 F(x)를 최소로 해준다는 것은 H(x)-x 를 최소로 해주는 것과 동일한 의미를 지닌다.
여기서 H(x)-x 를 residual(잔차)라고 한다.
즉, 잔차를 최소로 해주는 것이므로 ResNet이란 이름이 붙게 된 것이다.
이러한 ResNet을 이용하면 layer의 깊이와 상관없이 output 값이 최소 x 이상이므로, 이를 미분한 gradient가 1이상의 값을 가지게 된다. 따라서 ResNet을 이용하면 vanishing gradient problem를 해결하게 된다.
이미지 출처: https://bskyvision.com/644
residual block 정리
- 이미지에서는 H(x)=x가 되도록 training한다.
- 네트워크의 output F(x)는 0이 되도록 training한다.
- 이렇게 하면 모든 레이어에서 미분했을 때 최소 1 이상의 값을 갖게 된다.
- gradient vanishing 문제가 해결된다.
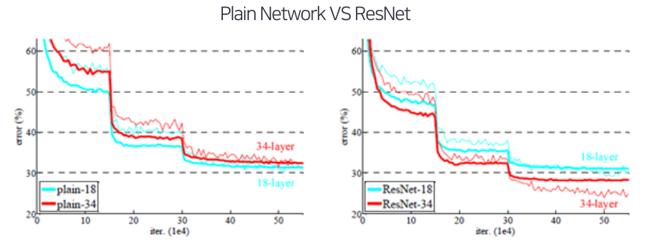
위 그래프는 Residual block들이 효과가 있는지를 알기 위해 이미지넷에서 18층 및 34층의 plain 네트워크와 ResNet의 성능을 비교한 것이다.
ResNet의 구조
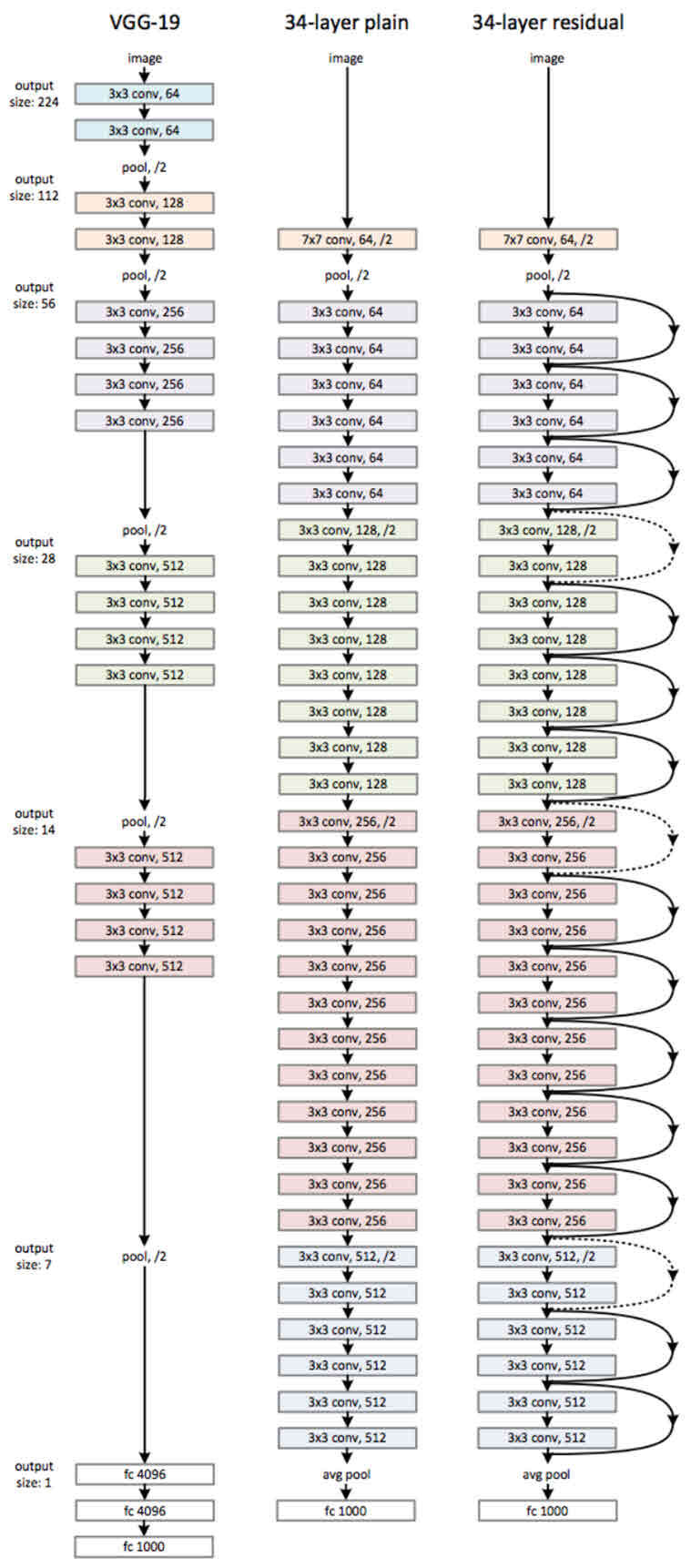
Plain 모델과 ResNet의 구조
Plain과 ResNet은 기본적으로 VGG-19의 구조를 뼈대로 한다. 그러므로 처음을 제외한 모든 conv filter는 3x3으로 적용한다. 따라서 전체적인 구조는 다음과 같다.
처음을 제외한 모든 conv filter는 3x3으로 적용한다.
output feature map size를 줄일 때, conv filter에 stride를 2를 적용하며, 이렇게 피쳐 맵의 사이즈를 줄일 때는 filter 수를 늘려 피쳐 맵의 깊이는 2배를 해준다.
마지막 레이어 부분은 Global Average Pooling을 이용하여 1000개의 뉴런을 갖는 softmax를 사용하는 하나의 Fully Connected layer를 갖는다.
Residual Network는 이러한 Plain 모델에 residual block들을 추가한 것이다.
이때, conv filter 수가 증가할때는 F(x)의 차원이 높아지게 되므로 이때 residual block를 추가할때는 x의 차원에도 zero padding을 해주거나 1x1 conv를 사용하여 증가시켜준다.
Bottleneck
파라미터의 수를 줄여 학습시간을 줄이기 위해 resnet - 50, 101, 152 layer에서는 bottleneck이라는 구조를 사용했다.

이미지 출처: https://velog.io/@good159897/ResNet
이 bottlenect은 1x1 convolution을 사용하여 차원을 줄인 후, 기존의 3x3 conv를 적용한 뒤, 다시 1x1 conv로 차원을 늘리는 것이다.

즉, 이런 형태를 띄게 되므로 bottleneck이라는 이름이 붙게 된 것이다.
1x1 Conv 의 효과
① channel 수 조정
Convoultion layer를 사용할 경우, channel의 수는 하이퍼파라미터로 사람이 직접 결정해 주어야 한다. 따라서 1x1 Conv 연산을 하면 channel의 수를 마음껏 조절할 수 있다.
② 계산량 감소
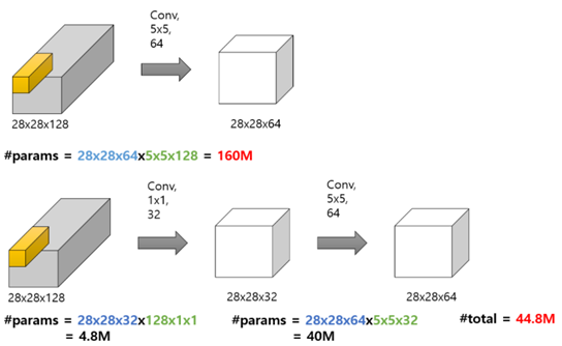
이미지 출처: https://hwiyong.tistory.com/45
③ 비선형성
1x1 Conv 사용 후, 활성화 함수로 ReLU를 사용하여 모델에 비선형성을 증가시켜준다. 따라서 복잡한 패턴을 더 잘 인식할 수 있게 된다.
