
개발 동기
최근 비대면 방식의 수업 및 업무가 대두되면서, 전자 문서의 활용도는 나날이 높아지고 있다. 이에 따라 여러 정보가 디지털 데이터로 송수신되면서 정보 전달의 매개체가 되는 문자에 미학성을 고려한 폰트가 주목받고 있다. 시각 및 디지털 디자인 관련 분야에서는 오래전부터 문자를 내용 전달 그 이상의 의미를 내포한다 여기어 한글 폰트 관련 연구가 진행되어왔으며, 현재는 폰트 제작 기술의 발전으로 폰트의 형태와 종류도 다양해지고 있다. 이러한 경향을 따라 이미지 기반 폰트 검색 서비스의 수요가 증가하면서 해당 서비스를 제공하는 사이트가 제작되었지만, 자동 시스템이 미비하며 정확도도 낮아 여전히 폰트 검색 방법은 미흡한 실정이다.
딥러닝 기술이 주목받기 시작하면서, 폰트를 특정한 모양을 갖춘 하나의 이미지로 간주하여 이미지 분류 태스크로써의 연구가 등장하였으며, 이후 여러 딥러닝 알고리즘이 제안되었다. 대표적으로 영어의 경우 폰트 분류 연구가 가장 먼저 시작되었기에 높은 정확도를 보이는 검증된 결과들이 여럿 존재한다. 하지만 한글에 대한 폰트 분류 연구 진행 상황은 상대적으로 저조한 편이다. 초성, 중성, 종성으로 구성되어있는 한글의 특성상 조합 가능한 글자의 수가 최소 2,350자에서 최대 11,172자라는 점이 52자로 구성된 알파벳과 비교했을 때 분류 난이도가 압도적으로 높아지게 된다.
본 프로젝트에서는 ResNet-18 모델을 기반으로 Data Augmentation을 적용하여 정형화된 데이터만이 아닌 여러 유형의 이미지에 대한 폰트 분류 정확도를 높이고자 하였다. 이후 카테고리 개수 및 카테고리별 데이터 개수에 따른 정확도를 확인하는 실험을 진행하고 이를 토대로 실제 테스트 문서에서의 한글 폰트 분류 정확도를 위한 모델을 제안한다.
2. 관련 연구
해외에서는 다양한 폰트에 관한 인식 방법 연구가 활발히 진행되고 있다. 2018년에 진행된 한 연구는 중국어 폰트 48종에 흰 배경에 존재하는 검은 글자 이미지, 자연 이미지에서 추출한 글자 이미지, 자연 이미지에서 추출한 뒤 Data Augmentation을 적용한 글자 이미지 등의 데이터 셋을 수집하고 각각에 대해 학습을 진행하였다. 이는 AlexNet, VGG16 모델을 사용하였다. 또한, 라틴 알파벳 폰트를 기울기, 두께, 스타일을 기준으로 분류한 연구도 존재한다. 각각 1,128종, 664종, 826종의 폰트를 사용하였으며, VGGNet을 참고한 자체 CNN 모델을 구축하여 학습하였다. 다른 연구에서는 라틴 알파벳 글자 및 단어를 분류하였고, 각각 1,116종, 2,383종의 폰트를 포함하고 있다. 이는 자체 CNN 모델을 구현하였으며, Backbone Network로 ResNet-18. 34, 50, 101을 사용하였다.
해외 연구에 비해서는 다소 미흡하지만, 한글 폰트에 관한 연구도 꾸준히 진행되고 있다. 한글 폰트 12종에 대해 LeNet, Inception ResNet v2 모델을 학습한 연구, 두 가지 구조의 CNN을 이용한 자체 모델로 한글 폰트 3,300종에 대한 분류를 시도한 연구, Data Augmentation이 적용된 한글 폰트 12종을 간소화한 VGGNet 모델로 분류한 연구 등이 존재한다.
하지만, 이와 같은 기존 한글 폰트 분류 연구들은 소량의 한글 폰트 인식을 시도하였기에 최근 생성된 여러 종류의 폰트 인식에는 한계가 있다. 그뿐만 아니라 Data Augmentation을 고려하지 않았기에 폰트에 존재하는 노이즈를 처리하기에는 어려움이 있다. 이는 다양한 환경에서의 폰트를 인식하기에는 부적합하다는 점을 의미한다.
3. 모델 구성
1) 데이터 셋

본 프로젝트에서는 AI Hub에서 제공하는 한국어 글자체 이미지 50종과 자체 수집 글자체 이미지 650종을 사용한다. 한글 폰트 총 700종에 각 폰트 당 한글 약 2,350자에 해당하는 이미지를 포함하고 있다.
AI Hub 한국어 글자체 이미지는 한글 폰트 50종에 약 11,172자에 해당하는 이미지를 포함하고 있다. 하지만 자체 데이터 구축 과정에서 2,350자만 지원하는 폰트가 많다는 점을 확인하였고, 해당 데이터 셋의 11,172자에서 2,350자만 추출하여 사용하였다.
자체 수집 글자체 이미지는 Text generator 웹 서비스에 대해 Selenium 라이브러리를 활용한 매크로 자동 시스템을 구현하여 구축하였다. 650종의 무료 상업 폰트를 수집하여 구축했으며, 한 종류의 폰트에 대해 한 가지 굵기만 포함하였다. 굵기에 대한 우선순위는 Regular, Medium, Bold, Light이다.
2) 모델 선정
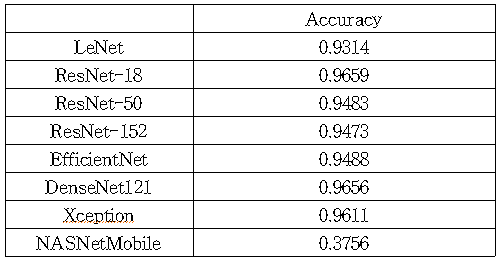
본격적인 연구에 앞서, 실험에 사용될 기본 모델을 선정하고자 여러 모델에 대해 학습을 진행하고 결과를 확인하였다. 데이터 셋으로는 AI Hub 한국어 글자체 이미지을 사용하였다. 한글 폰트 50종에 대한 약 11,172자 이미지를 학습 데이터 셋, 검증 데이터 셋, 평가 데이터 셋으로 각각 60%, 20%, 20%의 비율로 분할하여 학습을 진행하였다.
기존 폰트 관련 연구들에서 대부분 계층 수가 적은 모델을 사용했다는 점과 문자 이미지는 다른 이미지들에 비해 특징이 간단하다는 점을 고려하여 비교적 얕은 층을 가진 LeNet과 ResNet을 비교 대상으로 선정하였다. 다만, LeNet과 ResNet이 오래된 모델이라는 점을 고려하여 비교적 최근 모델인 EfficientNet, DenseNet121, Xception, NASNetMobile에 대해서도 학습을 진행했다.
결과적으로 ResNet-18가 가장 우수함을 확인할 수 있었다. 미세하지만 DenseNet과 Xception 또한 유사한 성능을 보였으나 해당 모델들은 학습 진행 시 Validation Accuracy 및 Loss가 불안정하다는 점을 고려하여 기본 모델을 ResNet-18로 결정하여 추후 실험을 진행하였다.
4. 성능 분석 및 결과
AI Hub 한국어 글자체 이미지 50종 및 자체 수집 데이터 셋 650종까지 도합 700종의 이미지에 대한 학습 epoch은 50으로 진행하였다. Data Augmentation의 경우 수평 및 수직 방향으로의 RandomFlip과 factor 값을 0.05로 지정한 RandomRotation, RandomZoom을 적용하였다. 데이터 셋은 학습 데이터 셋, 검증 데이터 셋, 평가 데이터 셋으로 각각 80%, 10%, 10%의 비율로 분할하였다. Dropout은 0.2만큼 적용한 후 patience 값 5의 Early Stopping을 적용하여 ResNet-18 모델에서 실험을 진행하였다.
1) 카테고리 개수 실험
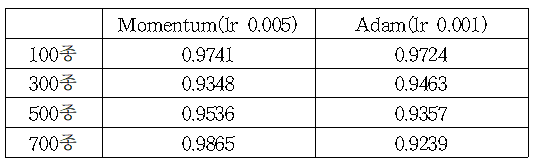
두 종류의 Optimizer를 사용하여 Momentum은 0.005의 learning rate로, Adam은 0.001의 learning rate를 설정한 후 실험을 진행하였다. 각각 2,350자로 이루어진 카테고리 700종에 대한 데이터 셋을 Momentum을 사용하여 학습했을 때 가장 우수한 accuracy를 보였다.
2) 카테고리별 데이터 개수 실험
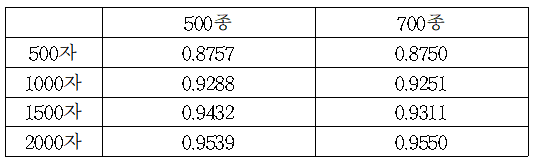
앞선 실험에서 가장 좋은 acc를 보였던 Momentum Optimizer로 실험을 진행하였다. 데이터 셋을 이루는 카테고리의 개수와 상관없이, 한 카테고리별 데이터 개수가 많을수록 높은 accuracy를 보였다. 최소 95% 이상의 정확도를 도출해내기 위해선 각 카테고리 당 최소 2000자 씩은 존재해야 함을 확인했다.
3) 입력 이미지 크기 실험

4.1, 4.2에서 이루어진 실험에서 입력 이미지 크기를 (32, 32)로 지정한 후 진행하였다. 다른 인자 값들은 동일하게 지정한 후 (224, 224)로 이미지 크기만 변경한 후 실험을 진행한 결과 0.9919라는 Top-1 자체 최고 accuracy를 도출해냈다.
4) 실제 문서 적용 실험
실제 문서에서도 학습시킨 모델을 적용할 수 있는지 확인하고자 그림 2과 같이 여러 종류의 폰트가 포함된 테스트용 문서 100장을 제작하였다. 테스트 문서는 가로, 세로 방향으로 1행에서 4행까지, 한 행당 최대 2종류의 폰트로 구성하였다. 이후 OpenCV를 사용하여 그림 3처럼 테스트 문서 내에서 각 글자를 인식하고 추출하여 실험에 사용하였다. 하지만 0.1520이라는 accuracy를 도출하여 실험 환경에서 만큼의 높은 성능을 보이지는 못했다.
5. 결론 및 향후 과제
본 프로젝트에서는 한글 폰트를 분류하고 Top-1 지표에서도 높은 성능을 보이는 이미지 기반 딥러닝 분류 모델을 제안하였다. 700가지 한글 폰트에 대해 ResNet-18 모델을 사용해 결과를 비교하였다. 실험 환경에서는 최대 0.9919의 accuracy를 보이는 것을 확인하였으나, 실제 테스트 문서에서는 그만큼의 성능에 이르지 못하는 한계를 확인하였다.
현재 실제 문서에서의 정확도가 낮으므로 이미지 resize를 기반으로 개선 방안을 모색하고 있다. 이를 기반으로 견고한 네트워크의 알고리즘이 구현된다면, 한글에 국한되지 않은 다양한 언어에 대한 폰트 분류 실험으로 확장할 수 있다. 뿐만 아니라 언어 폰트 분류에 적합한 Loss Function 구현, 테스트 이미지 자동 생성 시스템, 데이터 셋 구성의 다양화 등 연구 주제를 더욱 발전시킬 여지가 충분하다.
코드
자세한 코드는 Github에서 확인할 수 있다.
