2.1 마르코프 프로세스 (MP)
마르코프 프로세스 : 미리 정의된 확률 분포에 따라 여러 상태를 이동하는 것, 하나의 상태에서 다른 상태로 변화할 확률들의 합은 100%가 된다.
상태의 집합 S : 에이전트가 가질 수 있는 모든 상태들
전이 확률 P_ss': 에이전트가 상태 s에서 상태 s'으로 변화할 확률들을 모든 S에 대하여 행렬로 나타낸 값들
마르코프 성질
마르코프 프로세스의 모든 상태들은 마르코프 성질을 따른다. 이는 조건부 확률로 s_t의 상태에 있을때, s_t+1으로 변화하는 것들이 s_t에 의존적이기 때문이다. 단적으로 정리하자면 마르코프 성질의 특성은 다음과 같다.
미래는 오로지 현재에 의해 결정된다.
어떤 현상을 마르코프 프로세스로 모델링 하기 위해선, 특정 상태에 대한 정보가 충분하도록 해야하며, 과거 정보에 영향이 크지 않아야 한다.
2.2 마르코프 리워드 프로세스 (MRP)
마르코프 프로세스에 상태가 변화할 때마다 보상을 받는 개념이 추가되면, 마르코프 리워드 프로세스가 된다.
보상함수(R)
어떤 상태가 변화할때, 보상을 R이라고 하며, 보상을 받을 확률또한 존재하므로 기댓값의 함수로 나타낼 수 있다.
에피소드(Episode)
마르코프 리워드 프로세스에서는 초기 상태 s_0에서 종료 상태(Terminal)인 s_T까지 이동하면서 보상 R_0부터 R_T를 받게 되며, 이 과정을 하나의 에피소드라고 한다.
리턴(G_t)
하나의 에피소드의 초기 상태와 종료 상태가 존재한다면,
특정 시점 t에서 미래에 받을 보상들의 합들을 리턴이라고 한다.
감쇠인자 γ
현재시점에서 받을 보상 R과 미래시점에서 받을 보상 R의 가치가 같다고 가정하면, 미래시점의 보상 R은 현재의 보상 R보다 가치가 낮은 감가상각이 일어난다. (복리 혹은 할부의 개념)
다시 말해 현재 얻는 보상에 가중치를 준다고 볼 수 있다.
때문에 특정 시점 t의 리턴 G_t는
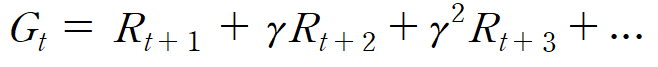
위의 식처럼 나타낼 수 있고, γ를 감쇠인자라고 하여, 파라미터로 정해줄 수 있다.
감쇠인자로, 리턴이 무한대가 되지 않을 수 있는 점
파라미터 변경을 통해 에이전트가 근시안적 Greedy를 사용하거나, 장기적 목표를 세울 수 있는 점
미래에 대한 불확실성을 반영할 수 있는 장점이 있다
(1,2번은 그렇다 쳐도, 3번은 너무 추상적인거 아닌가?!)
MRP에서 밸류 평가하기
특정 상태s_t에 대한 가치는 미래에 받을 보상의 합으로 결정된다.
때문에 리턴(G_t)를 측정하면 되는데, MRP에서 각 상태의 변화는 확률에 의해 일어나기 때문에 정확한 값을 측정할 수 없다.
때문에 리턴의 기대값을 통해 밸류를 평가하게 된다.
에피소드의 샘플링
하나의 에피소드를 진행할 때 확률에 의해 여러 상태를 변화하다가 마지막 상태 s_T에 도달하므로, 같은 환경에서 에피소드를 진행하더라도 에피소드의 길이나 변화하는 상태들이 달라질 수 있다.
때문에, 에피소드를 많이 진행하면 할수록 자연스럽게 '큰수의 법칙'에 의해서 상태가 변화할 확률들 P_ss'을 알 수 있게 되며
이 과정에서 하나하나의 에피소드는 표본으로 샘플링 된다.
대부분의 경우 상태가 변화할 확률 분포, 요컨대 전이확률행렬을 모르는 경우가 많기 때문에, 샘플링을 통해서 확률을 유추하는
Monte_Carlo 접근법을 사용한다.
상태 가치 함수
앞서 정리대로, 특정 상태(s_t)의 가치는 리턴(G_t)을 통해 알수 있으며, 이는 현재 상태에서 마지막 상태(s_T)에 도달하기 까지 얻을수 있는 보상들의 기댓값에 해당한다.
상태 가치 함수 v(s)는 특정 상태 s를 입력으로 받으면
리턴(G_t)의 기댓값을 출력하는 함수로
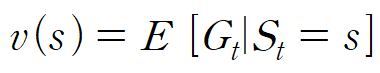
위와같은 수식으로 나타낼 수 있다.
조건부 확률로 표기하는게 의미 있나 싶긴하지만
E는 기댓값을 나타내며,
|오른쪽은 조건을 (S_t가 s일때)
|왼쪽은 출력을 의미한다.
MP는 (S;상태, P;전이확률),
MRP는 (S;상태, P;전이확률, R;보상, γ;감쇠인자)로 구성된다.
2.3 마르코프 결정 프로세스
MP와 MRP는 상태 변화가 확률에따라 자동으로 이루어 졌지만, 마르코프 결정 프로세스(MDP)에서는 D(Decision)이 들어간 점에서 확인 가능하듯이 에이전트의 의사결정이 핵심이 된다.
MDP의 정의
MDP는 MRP에 행동의 주체인 에이전트가 더해진 것으로, 에이전트는 각 상황마다 액션(Action)을 취한다. 따라서 MDP의 구성요소는 (S, A, P, R, γ)가 된다.
A는 액션들의 집합으로, 에이전트가 취할 수 있는 액션을 모두 모아놓은 것에 해당한다.
P는 전이확률 행렬로, 위와 조금 달라진 점은 상태 s에서 액션 A를 선택했을때 s'에 도달할 확률이라고 할 수 있다.
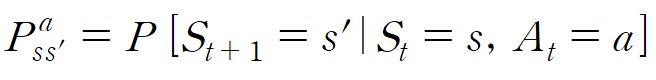
위는 정확한 수식으로, 상태 s, 액션 a를 했을때 s'이 될 확률로 정의할 수 있다.
R은 보상으로, 조건부에 액션이 a만 추가된 형태를 가진다.
그래서 결국 '보상의 합을 최대화 하려면, 에이전트는 어떤 액션을 선택해야 하는가?' 가 제일 큰 문제가 된다.
이것을 강화학습에서는 정책(Policy) 이라고 한다.
정책함수와 2가지 가치 함수
정책함수
정책 함수는 각 상태에서 어떤 액션을 선택할지 정해주는 함수로, 결과적으로 보상의 합을 최대화하는 정책을 찾으려고 한다.
정책함수는 확률값들로 나타나며,
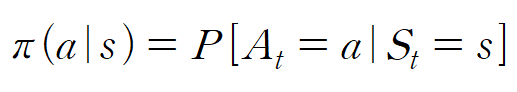
위 수식을 정리하면
정책함수 π(a|s)는 특정 상태(s)에서 특정 행동(a)를 선택할 확률을 아웃풋으로 내는 함수이다. 정책함수는 에이전트 내에 존재하며, 이 확률들을 바꿔가면서(학습) 더 큰 보상을 얻는 것이 강화학습이라고 할 수 있다.
상태 가치 함수
가치함수는 결국 어떠한 상태를 수치로 평가하고자 하는 것으로, 미래의 얻을 리턴의 기댓값을 의미했다. MRP와 다르게 MDP에서는 에이전트의 액션과 정책함수가 존재하므로, 정책함수에 따라 리턴이 달라지게 된다.
상태가치함수의 경우 정책함수가 정의되어야만 하므로
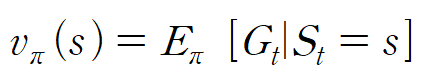
정책 함수 파이에 의존적임을 확인하기 위해 위와 같이 표기해준다.
액션 가치 함수
MDP에서는 초기상태(s) -> 액션(a) -> 변화상태(s')가 연속적으로 일어나므로, 상태에서의 가치를 평가할 수 있다면 액션에서의 가치 또한 평가할 수 있다.
비슷해보이는 액션이라도 상태에 따라 다를 수 있기 때문에, 액션가치 함수는 인풋으로 상태와 액션을 모두 받아야 하며(s, a)
마찬가지로 액션도 정책 π에 따라 결정되므로 액션 가치함수q는
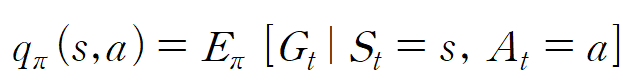
위와같은 수식으로 표현할 수 있다.
상태 가치 함수에서는 s에서 π가 액션을 결정하지만
액션 가치 함수에서는 일단 a라는 액션이 선택되어있다는 차이를 가진다고 할 수 있다.
2.4 Prediction과 Control
강화학습은 어떠한 상황(환경)이 주어졌을 때, 주어진 상황을 MDP의 형태로 만들어서 문제 상황을 해결하고자 한다.
이 때 필요한 2가지가 Prediction과 Control이다.
- Prediction : π가 주어졌을때 각 상태의 밸류를 평가
- Control : 최적정책 π* 을 찾는 것
출발 상태에서부터, 종료상태에 도달하기까지 에피소드에서
모든 상태들의 집합인 S에 대하여, 각각의 상태들이 얼마나 큰
리턴의 기댓값을 가지는지 아는 것이 Prediction
존재하는 모든 π중에 가장 기대 리턴이 큰 π* 를 찾는과정을
Control이라고 하며, π*를 따를때의 상태가치함수를
최적가치함수(v*)라고 한다.
이와 같이 최적 정책과 최적 가치함수를 찾는 것이 MDP에서 가장 중요한 일이 된다.
