MDP를 모르는 경우, 다시말해 보상 함수 r^a_s와 전이확률 P^a_ss'을 모르는 경우에는 액션을 해보기 전까지는 보상도, 어떤 상태로 이동할지도 모르게 된다.
이런 상황을 액션에 대한 환경의 반응을 모르므로, 모델을 세울 수 없는 모델 프리한 상황이라고 한다.
5.1 몬테카를로 학습
어떤 일이 일어날 확률을 몰라서 기댓값을 계산할 수 없다면, 시행을 늘려보면 보상에 시행회수를 나누는 것으로 기댓값과 확률을 추정해볼 수 있다.
큰 수의 법칙(Law of large numbers)에 의해 시행을 늘리면 점점 확률은 정확하게 수렴할 가능성이 높은데, 이것을 몬테카를로방법론(Monte Carlo Method)이라고 한다.
상태 가치 함수는 리턴의 기댓값과 같으므로, 여러 에피소드를 통해 리턴들을 구한 후, 그 값의 평균을 내면 실제 가치에 수렴할 것을 예상할 수 있다.
몬테카를로 학습 알고리즘
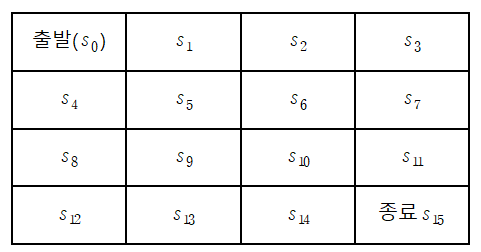
똑같은 그리드 월드를 생각한다면, MDP를 모른다는 것은
상태 s에서 액션 a에 대한 보상(r^a_s)과
상태 s에서 액션 a를 하기로 했을 때, 어떤 state로 변할지에 대한 확률,
즉 전이확률 P^a_ss'을 모른다는 것을 뜻한다.
MDP를 알때는 정책 π에 따라 어느쪽으로 이동하기로 결정했을 때,
정책에 따라 이동할 확률이 100%라는 전이확률을 알고 있었으므로,
일종의 계획(Planning)을 세워 바로 실제 가치를 평가할 수 있었으나
지금은 같은 정책 π를 정하더라도, 어떻게 변화할지를 모르므로
계획을 세우는 대신 직접 경험을 하면서(시행착오) 데이터를 수집하게 된다.
조금씩 업데이트하는 버전
위 방식에서는 단순히 모든 에피소드의 리턴을 더해서 산술평균을 내주는 방식을
사용해 상태 가치 함수 v(s)의 근사치를 구해줬다고 한다면,
조금씩 업데이트하는 버전은 가중치 α를 설정해서 가중 평균을 구해준다.
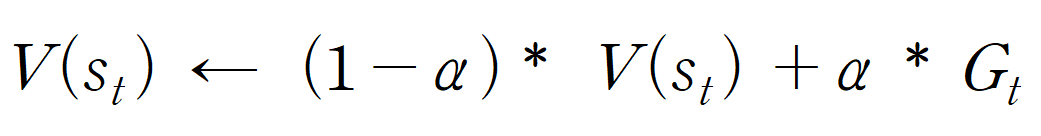
위 수식을 정리하자면, 기존 가치함수 V(s_t)에 대해
특정 state에 대한 새로운 에피소드(관측치)의 리턴 G_t가 관측된다면
기존 가치함수에 (1-α)를 곱해주고, 새로운 리턴값에 α를 곱해주는 방식을 통해
계속 평균을 내서 에피소드가 끝날때 마다 테이블을 업데이트 해준다.
pseudo-code
1. 테이블 초기화 : 모든 state에 대해 가치함수 v(s)를 0으로 만들어준다.
2. 임의의 정책 π (여기서는 동서남북 랜덤, 시작점 s_0)를 통해 경험을 쌓는다.
3. while 에피소드는 s_0, a_0, r_0, s_1, .... a_T-1, r_T-1, s_T(s_15, done)가 되고
이 과정에서 각 r_0, r_1... r_T-1 등 리워드들이 관측되므로
각 상태의 리턴(G_t), 즉 상태 가치 함수를 알 수 있다.
4. for 관측된 리턴을 기반으로 역순으로 reward를 확인하고
α를 통한 가중평균으로 table을 업데이트 한다.
5. for 2-4과정을 테이블이 수렴할때까지 반복5.2 Temporal Difference 학습
몬테카를로 학습방법(MC)는 한 에피소드가 끝난 다음에 리턴들을 확인하고
상태가치함수를 업데이트하기 때문에, 에피소드가 굉장히 길거나, 종료조건이 없는 경우에는 사용하기 쉽지 않다.
때문에 에피소드가 끝나기 전에 업데이트를 진행하는 방식인
Temporal Difference(TD)방법을 사용하게 된다.
상태변화(s->s')는 시간변화(t->t')를 수반하고
벨만 방정식
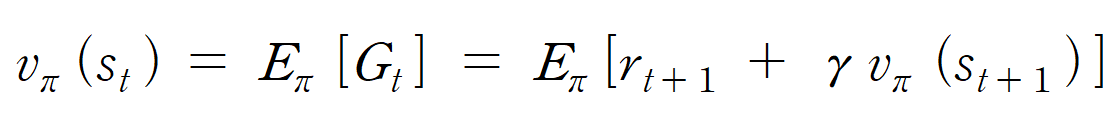
식에 의해여, v_pi(s_t+1)이 약간 편향되었을 가능성이 있긴하지만,
MC때와 마찬가지로 많은 값들을 뽑아서 평균을 낸다면 결과적으로는
언젠가는 정답에 가까운 G_t에 수렴할 수 있기 때문에,
행동에 수반되는 리워드와, 변화한 state의 상태가치만을 이용해서
기대값의 추정치를 업데이트 할 수 있다.
한 에피소드를 통해서 지나친 state들의 상태가치를 업데이트하고
에피소드를 충분히 진행하면, 결국 테이블 값이 수렴할 수 있다.
pseudo-code
1. 테이블 초기화 : 모든 state에 대해 가치함수 v(s)를 0으로 만들어준다.
2. 임의의 정책 π (여기서는 동서남북 랜덤, 시작점 s_0)를 통해 경험을 쌓는다.
3. 한번의 액션에서 관측되는 값 (초기에는 죄다 0이고, 마지막 부분만 업데이트 됨)
-> s_0, a_0, r_0, s_1
에서 관측된 r_0, s_1를 토대로 s_0를 업데이트
4. while 에피소드가 끝날때(done)까지 지나온 state들을 업데이트
5. for 테이블이 수렴할때까지 에피소드(3-4)를 반복함5.3 몬테카를로 vs TD
학습시점
MC는 에피소드가 끝나고 리턴을 확인한뒤, 학습이 진행되지만,
TD는 한 스텝마다 바로 테이블을 업데이트할 수 있다.
이는 위에서 이야기한대로 종료상태나 에피소드의 길이에 따라 장단점이 있다.
편향성
MC는 리턴의 평균을 내서 업데이트하므로 편향이 없는 안전한 방법에 해당한다.
반명 TD는 추측치를 통해 추측치로 업데이트하므로 편향되어있을 가능성이 닜다.
분산
MC는 리턴을 통해 업데이트되므로, 리턴을 이루는 많은 에피소드들의 평균이 필요하다. 때문에 많은 에피소드가 필요하며, 그로부터 필연적으로 에피소드들의 분산이 커지게 된다. (에피소드의 길이가 엄청나게 다양할 수 있기 때문에)
반면 TD는 매 스텝 업데이트하기 때문에 확률적 요소가 그리 크지 않으므로, 분산이 작고, 비교적 적은 데이터로 학습이 일어날 수 있따.
5.4 몬테카를로와 TD의 중간
n스텝 TD
우리는 항상 특정 terminal state(s_t) 다시 말해서 특정상태에서 에피소드가 끝나는 지점까지를 리턴으로 정의했지만, 실제로는 에피소드에서 임의의 state를 잡아서 리턴을 계산할 수 있다.
다시 말해 우리가 알고 있던 TD (한 스텝마다 업데이트)는 실제로는 TD_zero이고
임의의 n스텝마다 리턴을 구해서 MC처럼 업데이트 해주는 방식을 사용할 수 있다.
적절한 n을 찾는 것은 어렵지만, n-step 리턴을 계산하는 방식으로 실제
상태가치함수를 학습시킬 수 있다.
