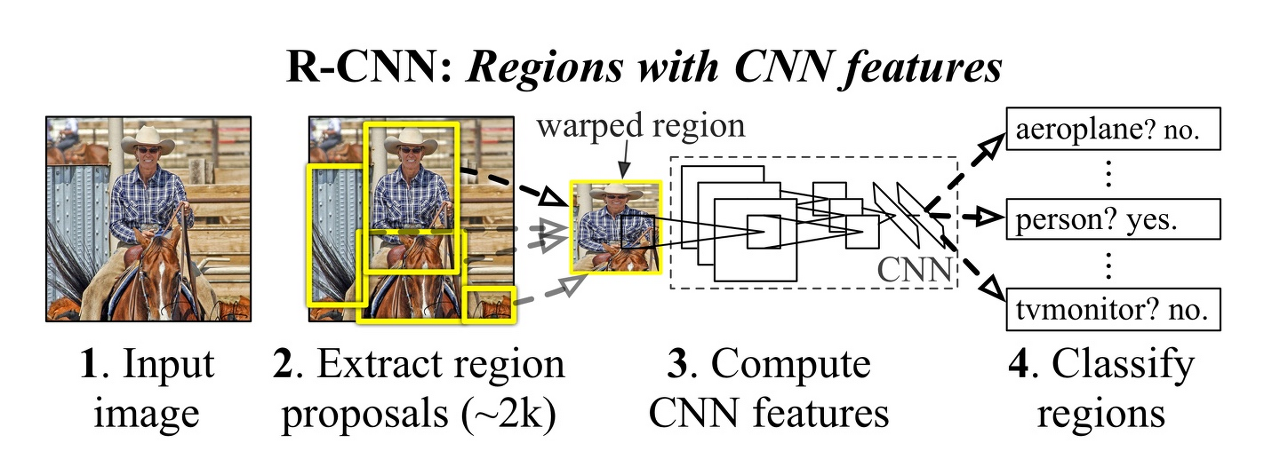
"R-CNN"
- R-CNN 패밀리중 가장 최초로 나온 논문
- 객체 감지 관련 논문들의 조상 격 되는 논문
- 엄청나게 느리지만 그래도 알고 넘어가야 하는 논문
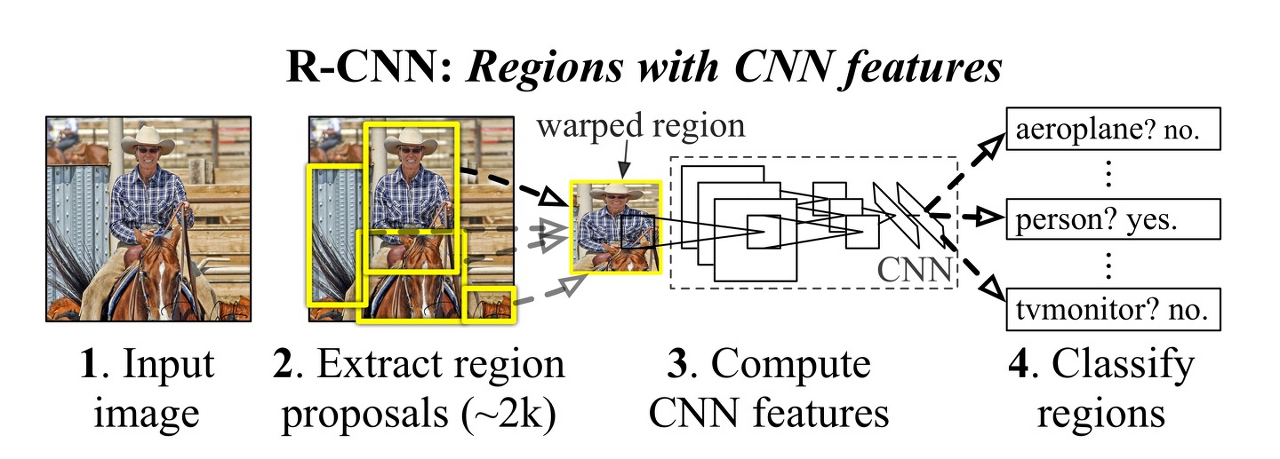
위는 R-CNN을 요약하는 대표적인 이미지입니다.
1. Extract region proposal
Selective Search:
이미지를 색상, 질감 등을 이용해서 segmentation을 수행하고 점차 단계별로 탐욕법을 이용해서 영역들을 합쳐나가는 알고리즘입니다. 초기 segmentation은 Efficient GraphBased Image Segmentation 라는 알고리즘을 통해 이루어지는데 이 부분은 복잡한 반면 아주 중요하다고는 생각이 들지 않아 넘어가겠습니다.

R-CNN은 입력 이미지를 Selective Search 알고리즘으로 2000개에 달하는 region propsal을 추출해 낸 뒤 이를 wrap해서(크기를 227 * 227로 조정) 한 뒤 CNN 신경망을 이용해서 학습을 진행합니다.
2. Supervised pre-training.
AlexNet(A. Krizhevsky, I. Sutskever, and G. Hinton. ImageNet classification with deep convolutional neural networks. In NIPS, 2012)을 ImageNet 데이터셋(ILSVRC2012 classification)중 image-level annotations만을 가지고 pre-training을 진행하는 과정입니다.
논문에서는 Caffe를 이용해서 학습시켰다고 합니다.
3. Domain-specific fine-tuning.
분류층인 1000-way classification layer을 랜덤적으로 (N+1)-way classification layer로 초기화합니다. 이 때 N은 분류할 클래스의 개수로 VOC 데이터셋을 예로 들면 N=20입니다. 이 때 1을 더하는 이유는 배경을 클래스로 추가하기 때문이라고 합니다.
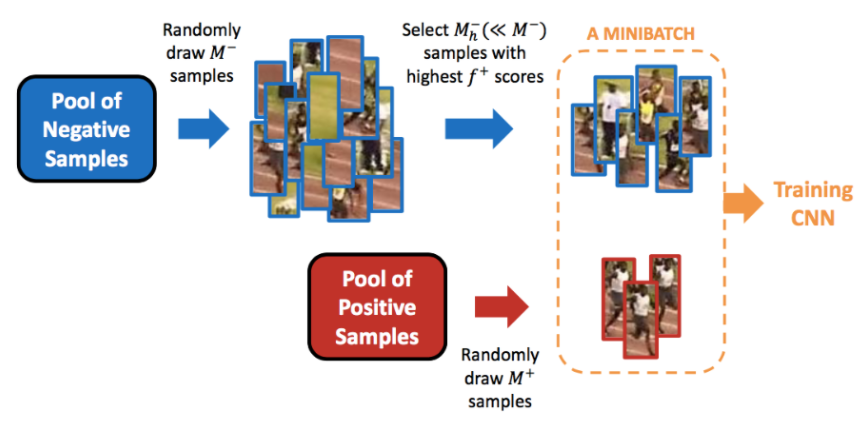
먼저 각각의 region proposal과 ground-truth box의 IoU를 계산합니다. 이 때 IoU란 (교집합 영역 넓이 / 합집합 영역 넓이)로 계산하기 쉽게 바꾸면 (첫번째 박스 넓이 + 두번째 박스 넓이 - 교집합 영역 넓이 / 교집합 영역 넓이)가 될 수 있겠네요. 교집합 넓이는 박스의 길이와 좌표를 이용하면 구할 수 있습니다. 그 후 IoU가 0.5보다 작거나 같은 region proposal을 positives 로 옮기고 나머지는 negatives 에 놔둡니다. 그 후 32개의 positives 와 96개의 negatives 를 합쳐 128개의 wrap된 region proposal 들을 한 미니 배치로 정합니다.
SGD를 사용해서 learning rate 0.001 로 fine-tuning 을 시작합니다.
4. Object category classifiers.
linear SVM들을 훈련 시킬 차례입니다. 이는 이진 분류이므로 클래스 수 이상의 SVM이 필요합니다.(OvR 방식)
그 전에 ground truth 들은 모두 positives에 넣고 IoU가 0.3보다 작은 것들을 negatives 에 넣습니다. 그 후 아까와 같은 방식으로 미니 배치를 구성 한 뒤 2번 과정을 통해 fine-tuning 된 신경망을 통과시킵니다. 이 때 (N+1)-way classification layer(full connected layer)의 전 단계인 4096 길이의 벡터를 추출합니다. 그 후 4096 벡터를 SVM을 통해 객체인지 배경인지를 판단하고, 각각 클래스의 score도 얻습니다. 그 후 4096 벡터를 SVM을 통해 객체인지 배경인지를 판단하고, 각각 클래스의 score도 얻습니다. 그 후 hard negative mining 이라는 작업을 통해 SVM 결과에서 False positive(배경을 사람으로 잘못 인식, hard negative 와 같은 의미) 들을 미니 배치에 넣고 positives도 넣어서 재학습을 합니다. 에포크마다 이를 반복합니다.
4.1. Bounding-box regression:
릿지 선형 회귀 방식으로 bounding-box의 정확한 위치를 구하는 방법입니다.
P^i = {P_x, P_y, P_w, P_h}
이고 G도 비슷합니다.
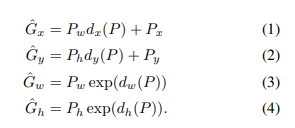
기본적인 식으로 예측한 region proposal의 좌표가 ground truth의 좌표에 더 가깝게 하는 회귀식입니다.
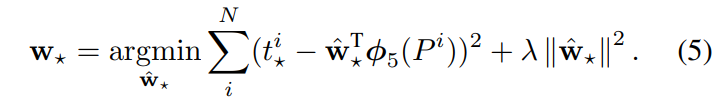
위는 릿지 회귀식과 동일하며 라이브러리에서는 람다를 알파로 표현하기도 합니다. 논문에서는 람다를 1000으로 설정했습니다. 이때 t는 다음과 같습니다. 릿지 회귀는 제일 아래에 링크를 달아놓았습니다.
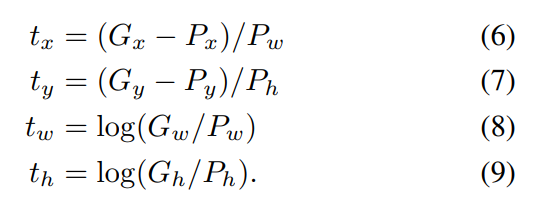
이제 scikit-learn과 같은 라이브러리를 이용해서 회귀를 수행하면 됩니다.
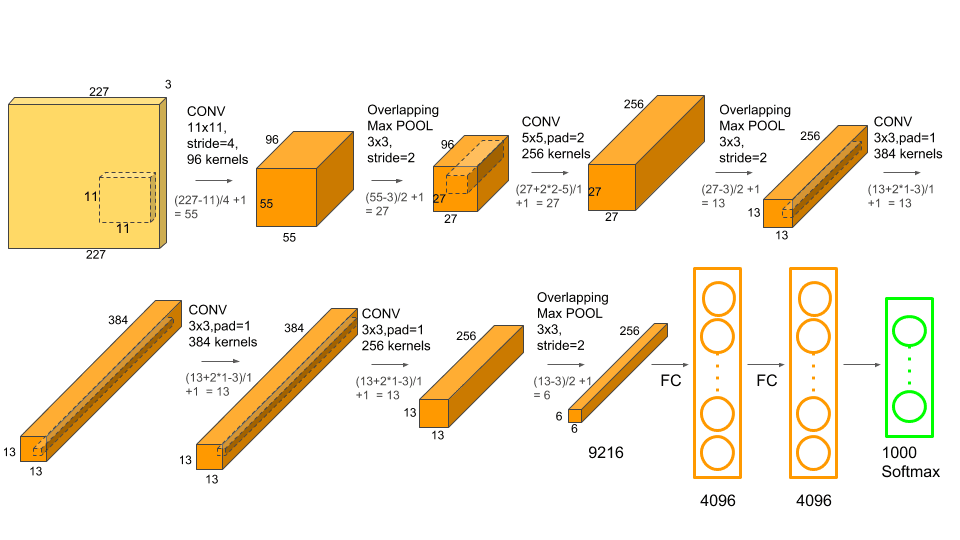
t를 타겟값으로 두고 특성으로 pool5 feature vector를 사용합니다. 이때 pool5 feature vector는 어떤 의미인지는 모르겠지만 논문에 의하면 크기가 6 * 6 * 256이라고 합니다. 따라서 다음 그림을 참고해보면 마지막 풀링층을 지난 vector 같습니다.
4.2. Non-Maximum Supression
NMS라고도 불리는 이 작업은 여러 bounding-box가 겹쳐 있는것을 제거해서 한개로 만드는것입니다.
아까전에 구했던 각각 bounding box의 score(confidence score) 중 confidence scroe threshold 를 넘지 않는 bounding box는 제거합니다. 그 후 남은 bounding box들의 score를 비교해서 가장 큰 것부터 정렬합니다. 그 후 score가 가장 큰 박스와 다른 박스들의 IoU를 각각 구하고 이 IoU가 threshold 값을 넘는 것은 동일한 객체를 감지했다고 생각하고 제거합니다. 이 때 threshold와 confidence scroe threshold의 정확한 값은 논문에 나와있지 않습니다.
어쨌든 겹쳐있는 여러가지 박스를 가장 정답에 가까운 박스 하나만 남긴다고 생각하면 될 것 같습니다.
참고한 글:
hard negative mining: https://blog.naver.com/PostView.nhn?isHttpsRedirect=true&blogId=sogangori&logNo=221073537958&parentCategoryNo=&categoryNo=6&viewDate=&isShowPopularPosts=false&from=postView
RCNN의 전체적인 흐름 정리: https://velog.io/@skhim520/R-CNN-%EB%85%BC%EB%AC%B8-%EB%A6%AC%EB%B7%B0
릿지 회귀: https://velog.io/@ljs7463/%EB%A6%BF%EC%A7%80%ED%9A%8C%EA%B7%80Ridge-Regression
RCNN 파이썬 코드 구현: https://github.com/rockgoat95/RCNN/blob/main/src/RCNN.py
NMS 설명: https://mickael-k.tistory.com/147
논문: Rich feature hierarchies for accurate object detection and semantic segmentation
