빅데이터 분석의 첫걸음 R코딩 기반의 수업 정리 내용
데이터로 움직이는 사회
4차 산업혁명
- 인공지능, 로봇, 바이오, 사물인터넷, 가상현실, 빅데이터, 자율주행차, 드론 등의 다양한 기술이 융합
- 경제, 정치, 사회 등 모든 분야에서 혁신적인 변화가 나타나는 새로운 패러다임의 시대로 변모
- 융합 사례: 아마존 고

데이터로 움직이는 사회
4차 산업혁명 시대, 데이터는 세상의 흐름을 주도하고 변화시키는 주요 자원
-> 기하급수적인 발전
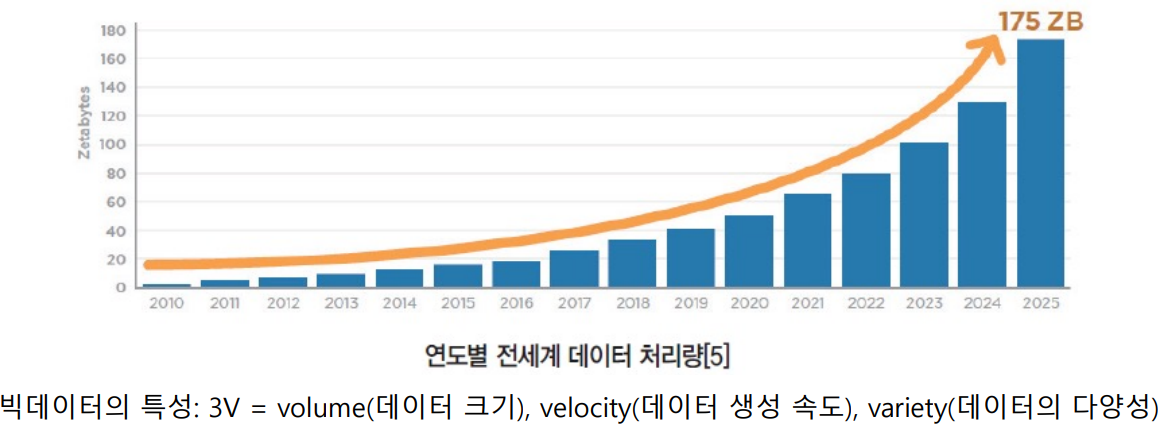
빅데이터의 특성 3V : volume(데이터 크기), velocity(데이터 생성 속도), variety(데이터의 다양성)
빅데이터 활용 사례
- 야간 버스, 자율주행 사동차
데이터 분석 도구 R
통계처리 도구인 MATLAB, SAS, SPSS의 대안
R의 장점
- 설치 간단
- 문법과 절차에 따라 명령어들을 기술한 R스크립트의 편집과 실행 용이
- 탁월한 데이터 처리 능력
- 8,000여개의 라이브러리 간단한 코드 작서으로 고급 데이터 분석과 시각화
- 다른 프로그래밍 언어에서 사용되는 임베디드 기능
- 기존 라이브러리를 활용하여 여러기능으로 쉽게 확장
- 풍부한 실습용 데이터 세트가 제공되어 학습에 용이
- 무료!
개발환경
패키지와 라이브러리

데이터 구조
식별자
변수 또는 함수 등을 다른 것들과 구별하기 위해 사용하는 '이름'을 지칭하는 용어
- 문자, 숫자, '.','_'으로 구성
- 숫자와 '_' 으로 시작 불가
- 예약어 사용불가
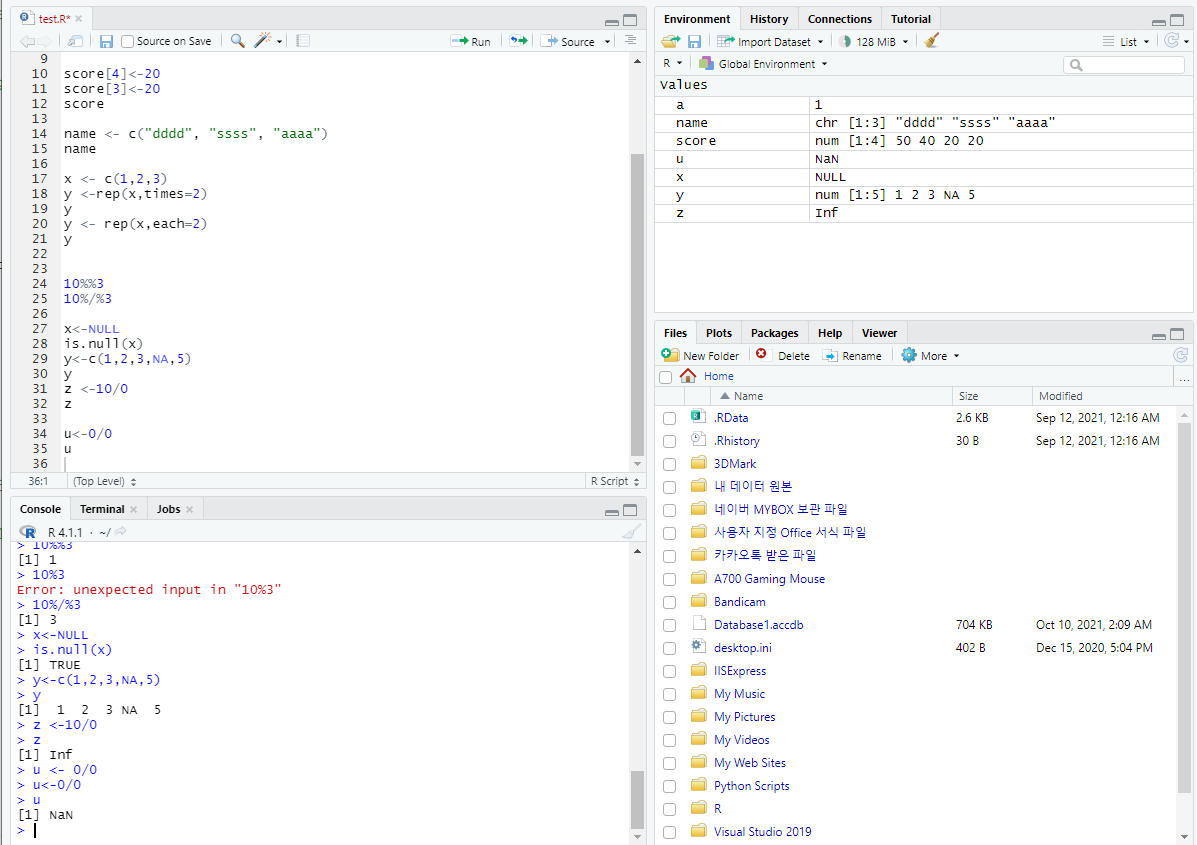
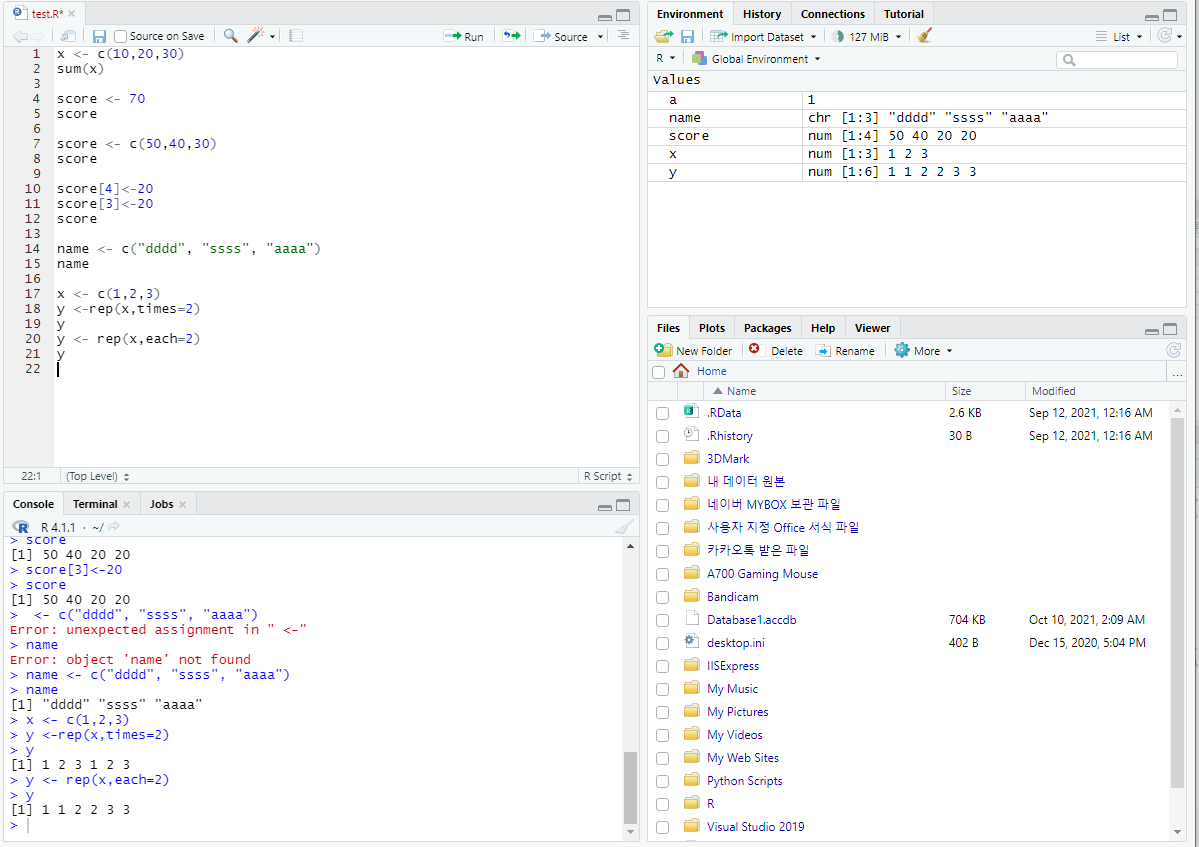
결측치(NA)와 널(NULL)
NA(not available) : 데이터의 누락
-설문조사 과정에서 해당 데이터가 누락되는 경우
NULL: 변수를 만드는 과정에서 변수 이름만 있는 경우
-초기화 과정에서 많이 사용
0이 아닌수를 0으로 나눌수 없다.
N/0 : 불능, 무한대를 의미 Infinity
0을 0으로 나눌수 없다.
0/0 : 부정, NaN(Not a Number)
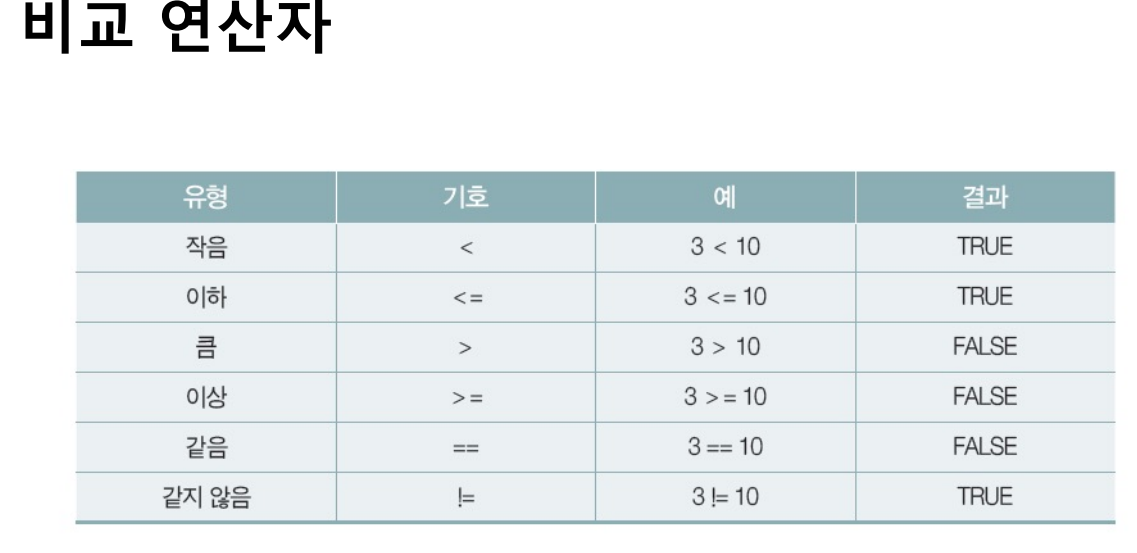
연산자
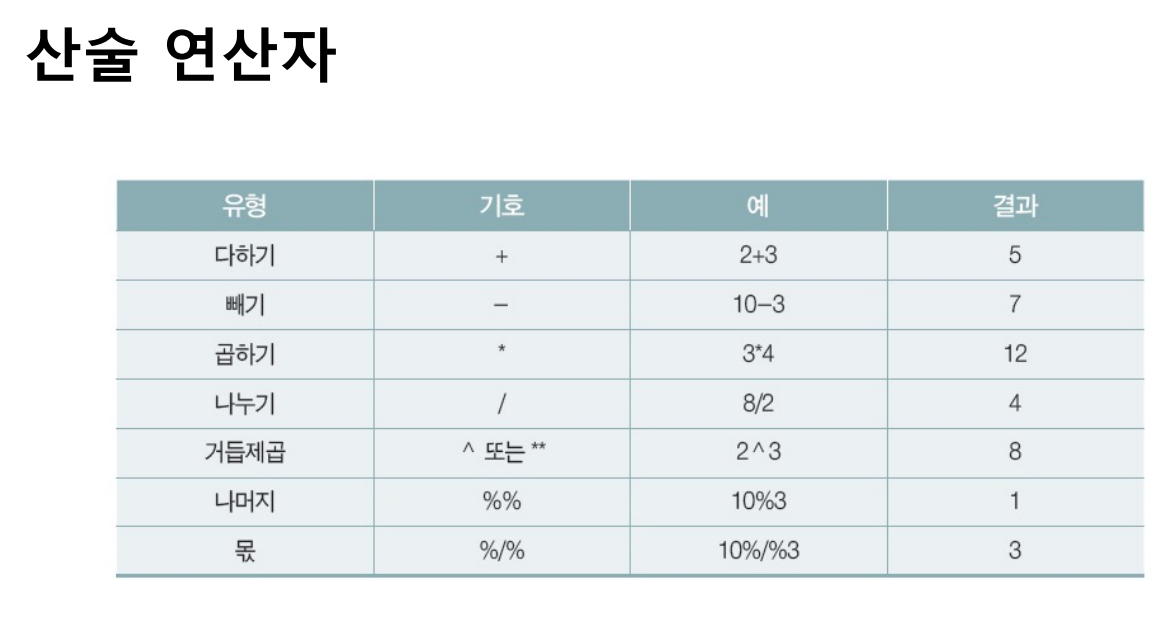
x<-c(10,20,30,40)
z<-c(2,4)
x+z출력값
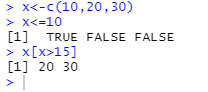
#x의 각원소는 10 이하인가?
x<-c(10,20,30)
x<=10
#x백터에서 15보다 큰 원소
x[x>15]출력값
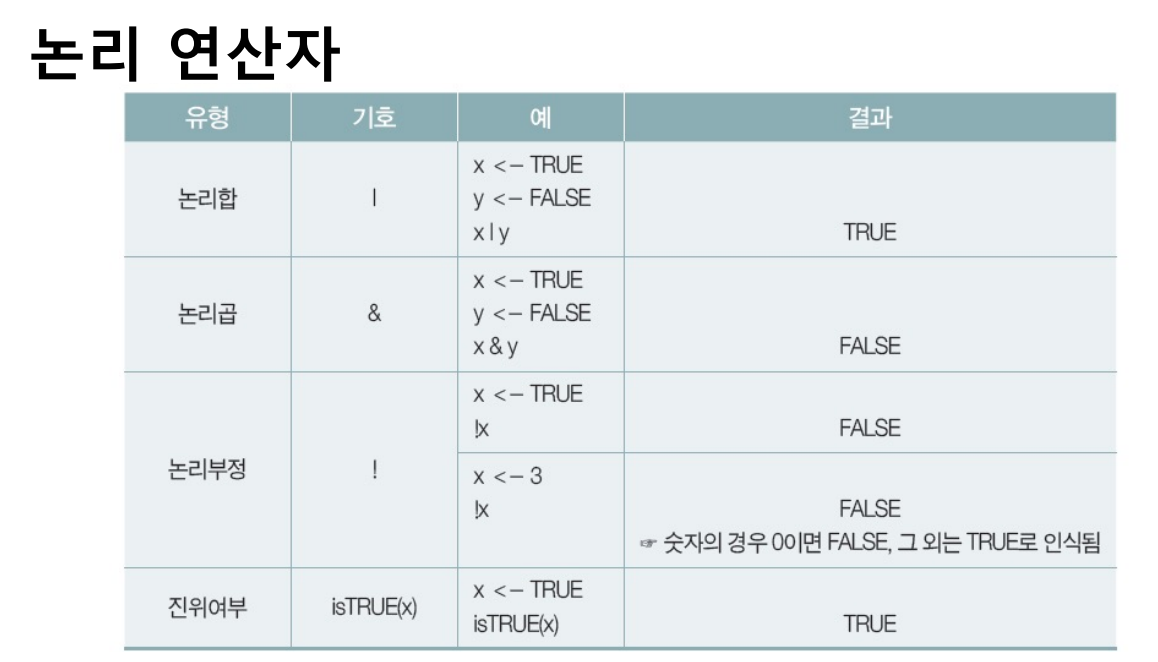
x<-c(TRUE,TRUE,FALSE,FALSE)
y<-c(TRUE,FALSE,TRUE,FALSE)
x&y
x|y
xor(x,y)
출력값

스칼라
그냥 숫자!!!
벡터
동일한 데이터 유형(숫자 또는 문자 등)의 단일 값들이 일차원적으로 구성 like 1차원배열
일반적인 벡터 선언 : c(10,20,30) //combine(합치다)
연속적인 값들의 벡터 : seq(1,10, by=3) //sequence(연속적인)
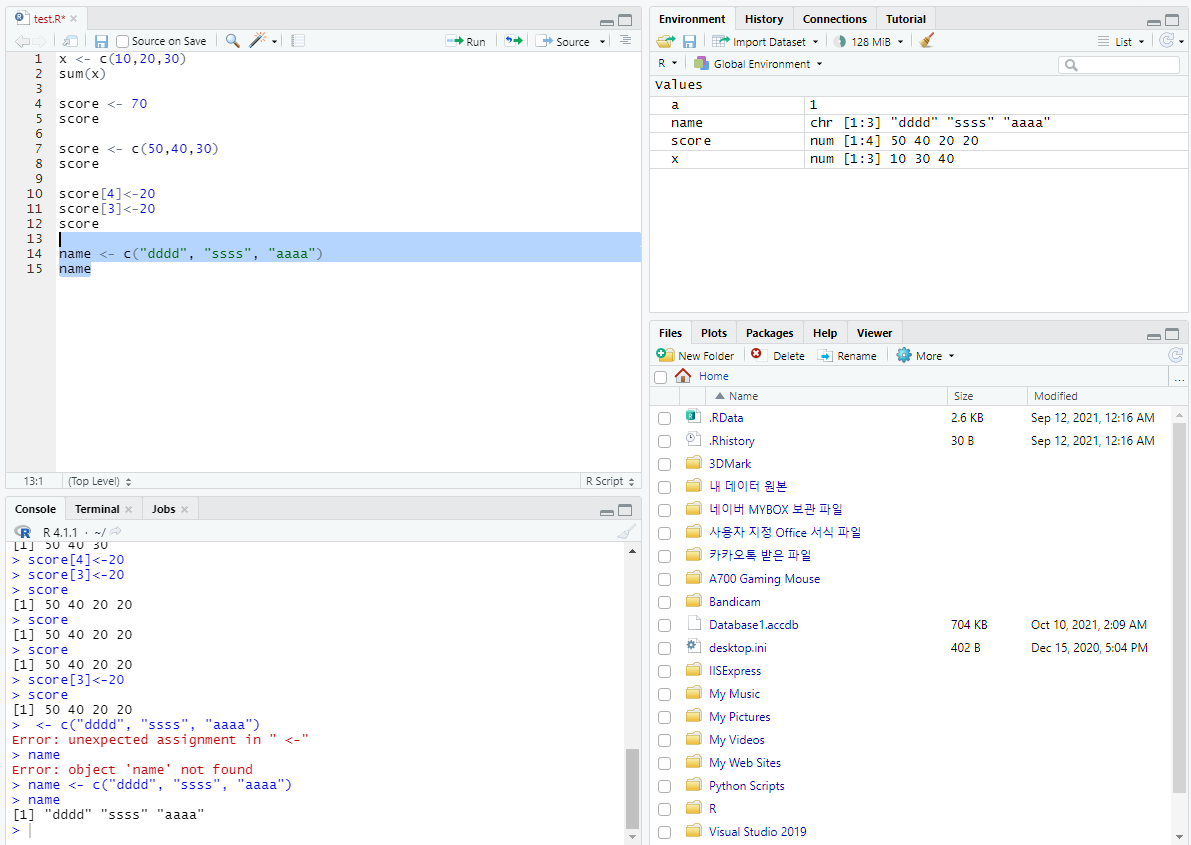
반복적인 값들의 벡터 : x <- c(1,2,3)
y <- req(x, times=2)//x를 2번 반복
y //1 2 3 1 2 3
y <- req(x, each=2)//각 인덱스 값을 2번씩 출력
y <- 1 1 2 2 3 3
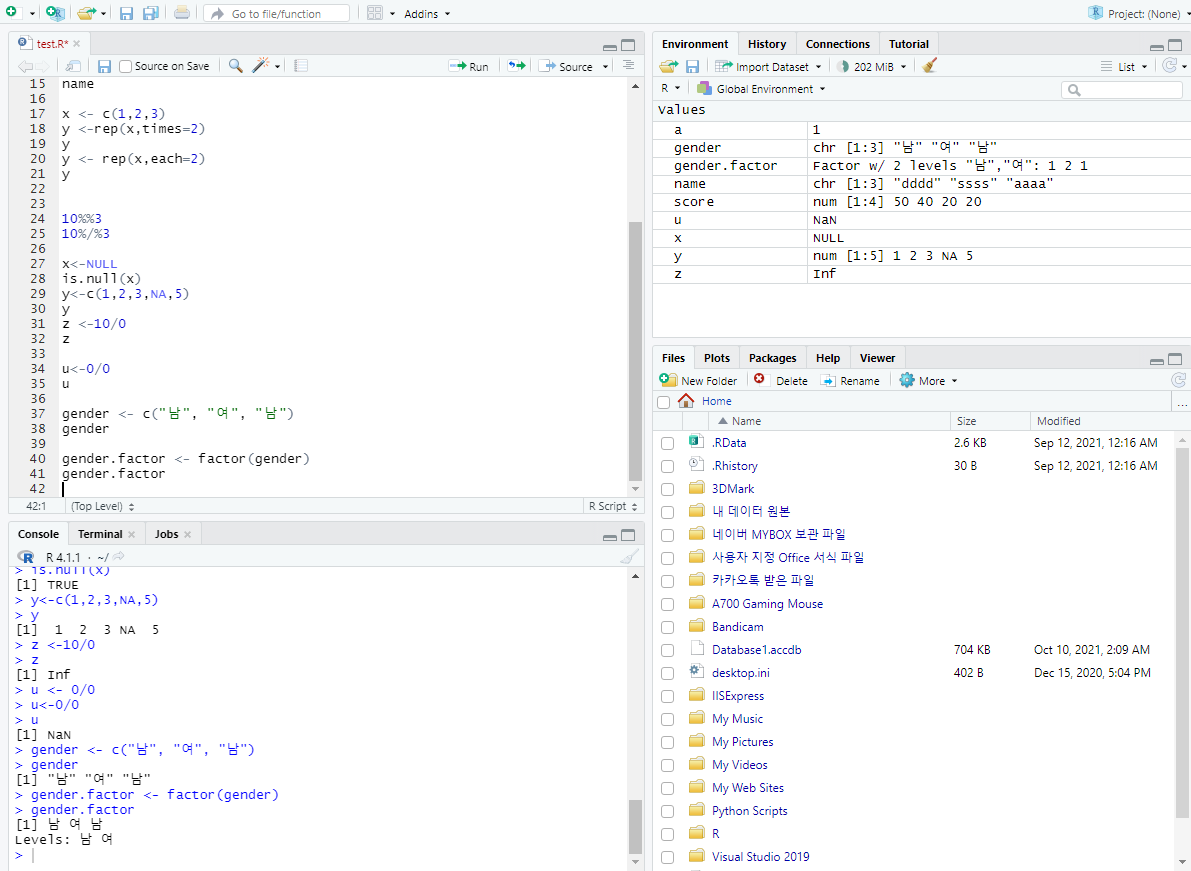
요인(factor)
문자 벡터에 그룹으로 분류한 범주 정보인 레벨이 추가된 데이터 구조 ex) 성별
배열과 행렬
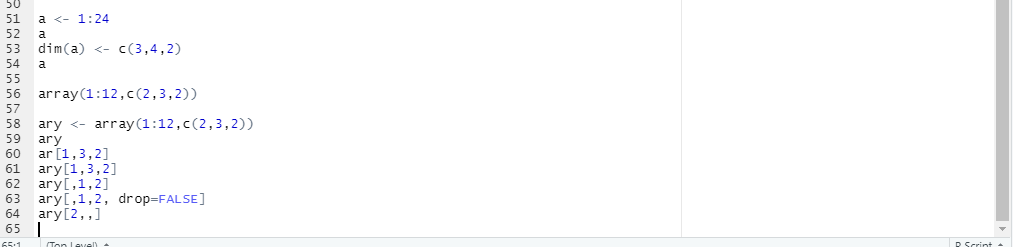
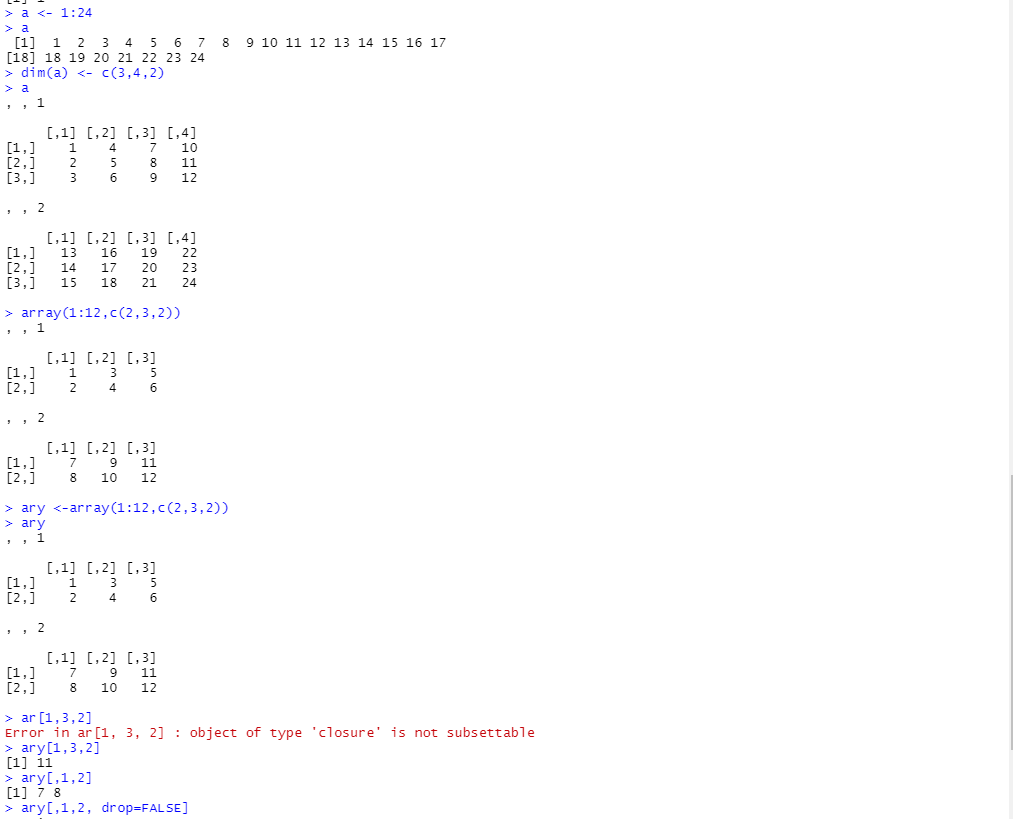
배열
- 한 개 이상의 벡터로 구성되며, 동일한 데이터 유형을 갖음
- 행과 열로 구성되고, 다차원으로 확장가능
- 배열 생성 함수 : array() //array는 세로로 값을 넣음
- dim = c(행, 열, z) //dim은 가로로 값을 넣음

행렬
- 행과 열로 구성되는 2차원 배열
- 행렬 생성 함수 : matrix()
v <-1:12
v
dim(v) <- c(3,4)
v
v <-1:12
# 열의 방향으로 값이 들어감
matrix(data =v,nrow=3,ncol=4)
#행의 방향으로 값이 들어감
matrix(data =v,nrow=3,ncol=4, byrow= TRUE)
rnames <-c("r1", "r2","r3")
colnames<-c("c1", "c2","c3","c4")
#dimnames는 행과 열의 이름을 넣어줄수 있음
matrix(data=v,nrow=3,ncol=4,dimnames = list(rnames,colnames))
#굳이 인수의 이름을 안적어도 됨
matrix(0,3,4)
matrix(NA,3,4)
# 굳이 행,열 다 안적어도 데이터의 갯수를 알고있다면 알아서 넣어줌
matrix(v,ncol=4)
mat <- matrix(v,ncol=4)
mat
#행렬의 내부구조를 알고싶을때
str(mat)
# 행열을 벡터형으로 알려줌
dim(mat)
dim(mat)[1]
dim(mat)[2]
nrow(mat)
ncol(mat)
length(mat)
#행의 방향으로 벡터를 결합
v1<-c(1,2,3,4,5)
v2<-c(5,7,8,9,10)
rbind(v1,v2)
#열의 방향으로 벡터를 결함
cbind(v1,v2)
cbind(1:3,4:6,matrix(7:12,3,2))
rbind(matrix(1:6,2,3),matrix(7:12,2,3))
# 추가!!
y<-c(7,8,9)
mtx <- matrix(1:6,2,3,byrow=TRUE)
mtx <-rbind(mtx,y)
rownames(mtx)[3]
mtx
z<-c(10,11,12)
mtx<-cbind(mtx,z)
mtx
출력



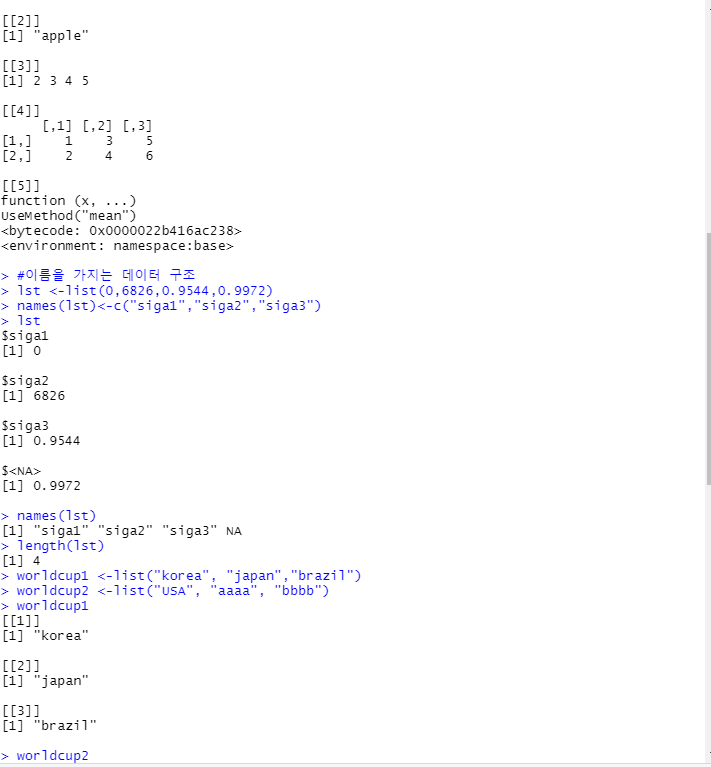
리스트
- 벡터를 원소로하는 데이터 구성
- 원소 : 이름, 서로다른 데이터 유형의 원소 가능, 하나 이상의 값으로 구성
- 리스트 생성함수 : list()
#리스트
list(0,6826,0.9544,0.9972)
list(1.23,"apple", c(2,3,4,5),matrix(1:6,ncol=3),mean)
lst <- list()
lst[[1]] <- 1.23
lst[[2]]<- "apple"
lst[[3]] <- c(2,3,4,5)
lst[[4]] <- matrix(1:6,ncol=3)
lst[[5]]<- mean
lst
#이름을 가지는 데이터 구조
lst <-list(0,6826,0.9544,0.9972)
names(lst)<-c("siga1","siga2","siga3")
lst
#이름(인덱스 추출)
names(lst)
#원소의 길이
length(lst)
#리스트 합치기
worldcup1 <-list("korea", "japan","brazil")
worldcup2 <-list("USA", "aaaa", "bbbb")
worldcup1
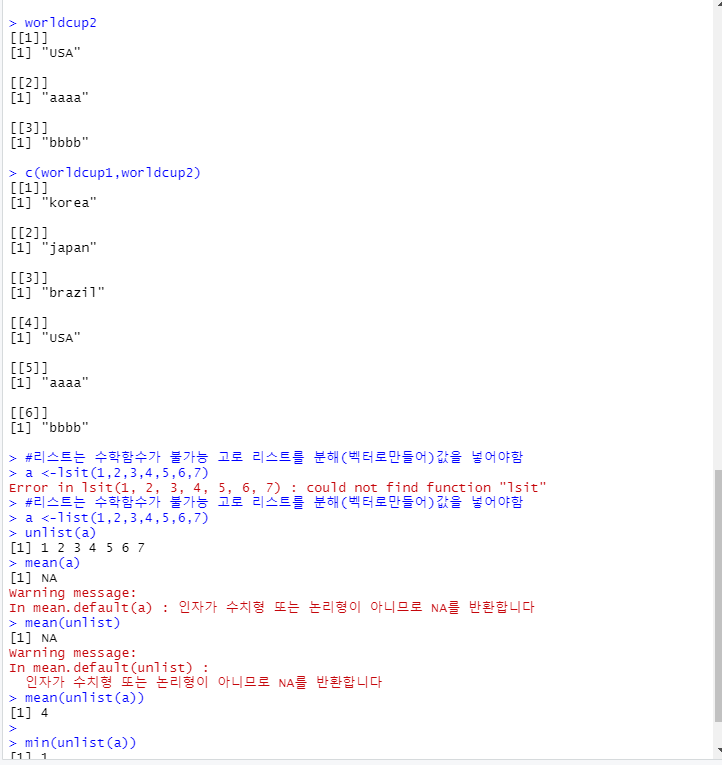
worldcup2
c(worldcup1,worldcup2)
#리스트는 수학함수가 불가능 고로 리스트를 분해(벡터로만들어)값을 넣어야함
a <-list(1,2,3,4,5,6,7)
unlist(a)
mean(unlist(a))
min(unlist(a))
max(unlist(a))
# 추가
x <- list(성명="알라딘",나이=20,성적=c(70,80))
x
#자료 자체를 가져옴(색인, 값) // list형
x[1]
#자료의 값만 가져옴 //string형
x[[1]]
#인덱스의 원소값 추출
x[c(2,3)]
# true인 값들만 남고 제거
x[c(FALSE,TRUE,TRUE)]
#첫번째 원소값 제거
x[-1]
x$성명
#없는 인덱스를 추출하려고 하면 NULL출력됨
x$국밥밥
x[["국밥밥밥"]]
#인덱스로 숫자를 넣으면 error
x[[5]]
# 이병신같은 언어는 뭐지
# c(1,3,5) 벡터 형식으로 추출하면 NULL
x[c(2,4,6)]
#중첩 리스트
lst <- list(one =1,two=2,three=list(alpha=3.1,beta=3.3))
lst
lst[["three"]][["beta"]]
#리스트 값 변경
lst[[2]] <- 20
lst
출력





데이터 프레임
- 성명, 성별, 나이, 국어, 음악 등과 같이 여러 항목ㄱ들로 구성
- 각 항목들 간 데이터 유형은 다를 수있음
- 각 항목들은 단일 값을 표현되는 2차원적인 데이터 구조
- 데이터 프레임 생성 함수 : data.frame()
# 데이터 프레임
df <- data.frame(성명 =c("알라딘","자스민"),나이=c(20,19),국어=c(70,85))
df <- cbind(df,음악=c(80,90))
df
df<- rbind(df,data.frame(성명 ="지니",나이=30,국어=90,음악=75))
df
#추출하기
df[-2,]
df[,-3]
str(df)
df[1,2] <- 21
df
df[1,1] <-"aladin"
df
df<-data.frame(성명=c("알라딘","자스민"),나이=c(20,19),국어=c(70,90))
str(df)
df[1,1] <-"aladin"
df
출력

데이터 파일 읽기
R의 datasets 패키지에는 여러 데이터 세트가 존재
추가적인 패키지 사용시 library()로 패키지 로딩후 사용
# 데이터 세트
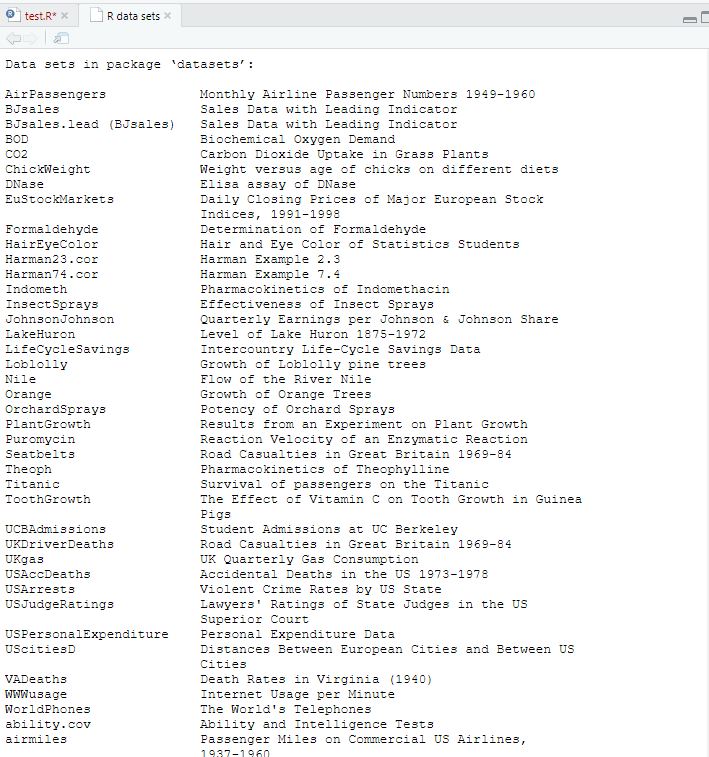
data(package="datasets")
#quakes 데이터 세트(위도, 경도, 진원지, 지진규모, 관측소 번호)(피지섬)
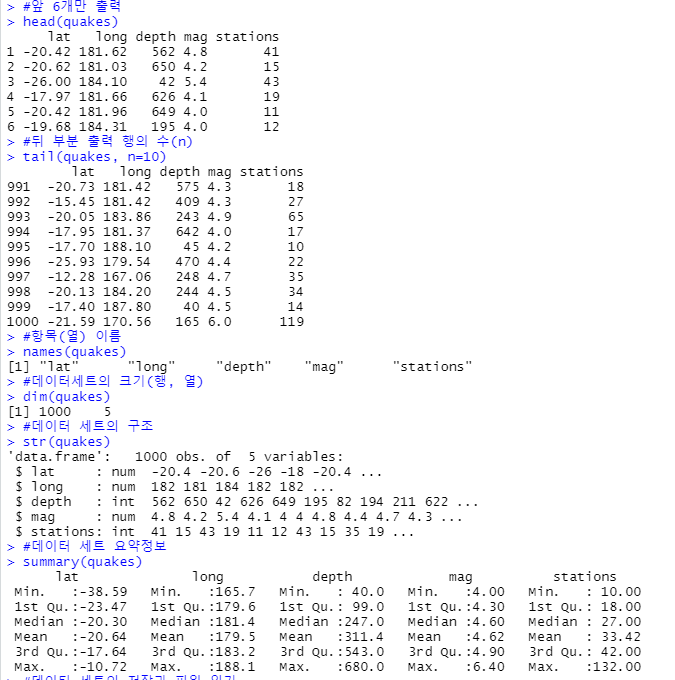
quakes
#앞 6개만 출력
head(quakes)
#뒤 부분 출력 행의 수(n)
tail(quakes, n=10)
#항목(열) 이름
names(quakes)
#데이터세트의 크기(행, 열)
dim(quakes)
#데이터 세트의 구조
str(quakes)
#데이터 세트 요약정보
summary(quakes)
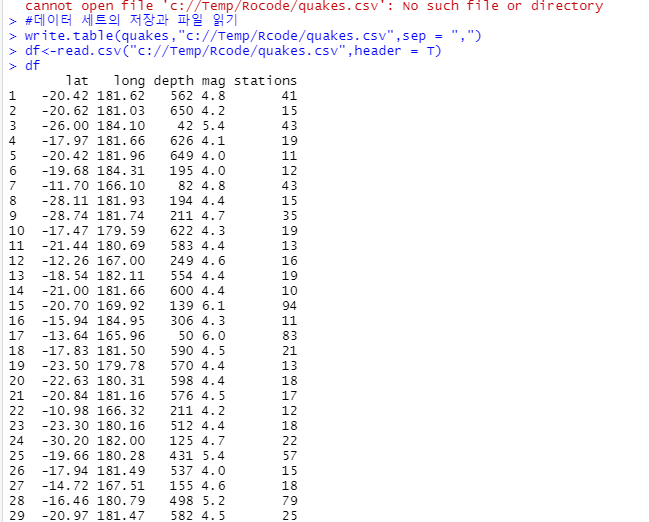
#데이터 세트의 저장과 파일 읽기
#데이터간 구분은 ","사용
write.table(quakes,"c://Temp/Rcode/quakes.csv",sep = ",")
#파일읽기/첫행은 항목명으로 인식
df<-read.csv("c://Temp/Rcode/quakes.csv",header = T)
df
출력
data(package="datasets") 불ㄹ러오기
함수
- 하나 이상의 명령어들을 묶어 놓은 것
- 함수의 이점
번거로운 반복적인 코딩시간 절약
검증된 코드를 사용해 프로그래밍 - R : 패키지로 다양한 함수 제공
수학함수

#함수
#절댓값
abs(-12)
#평균
mean(1:10)
#표준편차
sd(1:10)
#제곱근
sqrt(100)
#합
sum(1:10)
#분산
var(1:10)

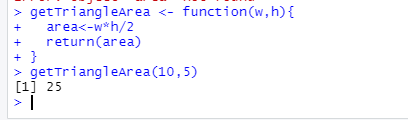
사용자 정의 함수
#사용자 정의함수
getTriangleArea <- function(w,h){
area<-w*h/2
return(area)
}
getTriangleArea(10,5)