
pandas를 활용한 데이터 비식별화
이번 주에 학습할 내용들
- pyarrow를 통해 이용할 경우에 속도차이 등 확인
- 범주화 -> 5세 단위로 범주화, 10세 단위로 범주화
마스킹 -> 앞자리 부터 5개, 뒷자리부터 5개- key+salt 2개 파일 머지, 2개 파일 chunk 방식 머지
- 정규분포, pandas describe 출력 및 시각화, 데이터 분포 시각화
pandas vs pyarrow
pandas가 file을 load 하는 시간
# Pandas만 사용한 경우의 시간 측정
start_time = time.time()
df_pandas = pd.read_csv(file_path)
pandas_time = time.time() - start_time
print(f"Pandas load time: {pandas_time:.6f} seconds")pyarrow가 file을 load 하는 시간
PyArrow를 사용한 경우의 시간 측정
start_time = time.time()
table = pv.read_csv(file_path) # pyarrow로 csv 읽기
arrow_time = time.time() - start_time
print(f"PyArrow load time: {arrow_time:.6f} seconds")
확실히 file loading은 pyArrow가 훨씬 빠르다.
pandas merge
key + salt 2개의 파일을 merge, 2개의 파일을 chunk 방식으로 merge
다음은 전체 코드다. 하나씩 뜯어보자.
import pandas as pd
import hashlib
# SHA256 암호화 함수 정의
def encrypt_data_sha256(data):
sha_signature = hashlib.sha256(data.encode()).hexdigest()
return sha_signature
# 파일 경로 설정
file1_path = './key_index_to_csv.csv'
file2_path = './key_index_to_csv1.csv'
output_path = './sha256_merged_file.csv'
# chunk 단위로 데이터를 읽어서 처리 및 암호화
chunk_size = 1000
with pd.read_csv(file1_path, chunksize=chunk_size) as reader1, \
pd.read_csv(file2_path, chunksize=chunk_size) as reader2:
merged_chunks = []
for chunk1, chunk2 in zip(reader1, reader2):
# 'name' 열을 SHA256으로 암호화
chunk1['name'] = chunk1['name'].apply(encrypt_data_sha256)
chunk2['name'] = chunk2['name'].apply(encrypt_data_sha256)
# 두 chunk를 합치기
merged_chunk = pd.concat([chunk1, chunk2])
merged_chunks.append(merged_chunk)
# 전체를 하나의 데이터프레임으로 결합
final_df = pd.concat(merged_chunks)
# 결과를 CSV 파일로 저장
final_df.to_csv(output_path, index=False)
print(f"파일이 성공적으로 병합되어 저장되었습니다: {output_path}")def encrypt_data_sha256(data):
sha_signature = hashlib.sha256(data.encode()).hexdigest()
return sha_signature- encrypt_data_sha256 함수: 문자열 데이터를 SHA256 알고리즘을 사용하여 해시 처리한다.
hashlib.sha256(data.encode()).hexdigest()는 문자열을 UTF-8로 인코딩한 후 SHA256 해시를 계산하고, 그 결과를 16진수 문자열로 반환한다.
file1_path = ''./key_index_to_csv.csv''
file2_path = './key_index_to_csv1.csv'
output_path = './sha256_merged_file.csv'- 파일 경로 정의: 처리할 입력 파일(
file1_path,file2_path)과 결과를 저장할 파일(output_path)의 경로와 파일명을 설정한다.
chunk_size = 1000
with pd.read_csv(file1_path, chunksize=chunk_size) as reader1, \
pd.read_csv(file2_path, chunksize=chunk_size) as reader2:- Chunk 단위로 파일 읽기:
pd.read_csv함수는chunksize매개변수를 사용하여 파일을 일정 크기만큼(여기서는 1000줄씩) 읽어온다. 이렇게 하면 파일 전체를 메모리에 한 번에 로드하지 않고, 부분적으로 처리할 수 있어 메모리 사용량을 줄일 수 있다. reader1,reader2는 각각의 파일을 chunk 단위로 순차적으로 읽어오는 반복자(iterator)이다.
merged_chunks = []
for chunk1, chunk2 in zip(reader1, reader2):
# 'name' 열을 SHA256으로 암호화
chunk1['name'] = chunk1['name'].apply(encrypt_data_sha256)
chunk2['name'] = chunk2['name'].apply(encrypt_data_sha256)
# 두 chunk를 합치기
merged_chunk = pd.concat([chunk1, chunk2])
merged_chunks.append(merged_chunk)- 리스트
merged_chunks: 각 chunk에서 암호화 후 병합된 데이터를 저장할 리스트이다. for루프: 두 파일의 chunk들을 동시에 읽어온다.zip(reader1, reader2)는 두 반복자에서 동일한 순서의 chunk를 함께 처리한다.- 암호화 처리: 각 chunk의
name열을encrypt_data_sha256함수를 통해 SHA256으로 암호화한다. - chunk 병합:
pd.concat([chunk1, chunk2])를 사용하여 두 chunk를 병합한다. 각 chunk를 처리한 후 결과를merged_chunks리스트에 추가한다.
# 전체를 하나의 데이터프레임으로 결합
final_df = pd.concat(merged_chunks)- 최종 데이터프레임: 각 chunk에서 병합된 데이터를 다시 한번 전체적으로 병합하여 하나의 큰 데이터프레임(
final_df)으로 만든다.
final_df.to_csv(output_path, index=False)- 결과 저장: 최종적으로 병합된 데이터프레임을 CSV 파일로 저장한다.
index=False는 인덱스를 파일에 포함하지 않도록 한다.
print(f"파일이 성공적으로 병합되어 저장되었습니다: {output_path}")- 결과 확인: 파일이 성공적으로 저장되었음을 알려주는 메시지를 출력한다.
pandas를 활용한 데이터 시각화
데이터 시각화는 데이터 마이닝에서 매우 중요한 역할을 한다.
seaborn이란?
- Seaborn은 matplotlib 기반의 시각화 라이브러리다. 유익한 통계 그래픽을 그리기 위한 고급 인터페이스를 제공한다.
회귀분석 예제 및 잔차 정규성 검정
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from scipy.stats import norm
# 예제 데이터 생성
np.random.seed(0)
x = np.random.rand(100)
y = 2 * x + np.random.normal(0, 0.1, 100)
data = pd.DataFrame({'x': x, 'y': y})
# 회귀분석 수행
model = np.polyfit(data['x'], data['y'], 1)
data['y_pred'] = np.polyval(model, data['x'])
# 잔차 계산
data['residuals'] = data['y'] - data['y_pred']
# 잔차의 히스토그램과 정규분포 곡선
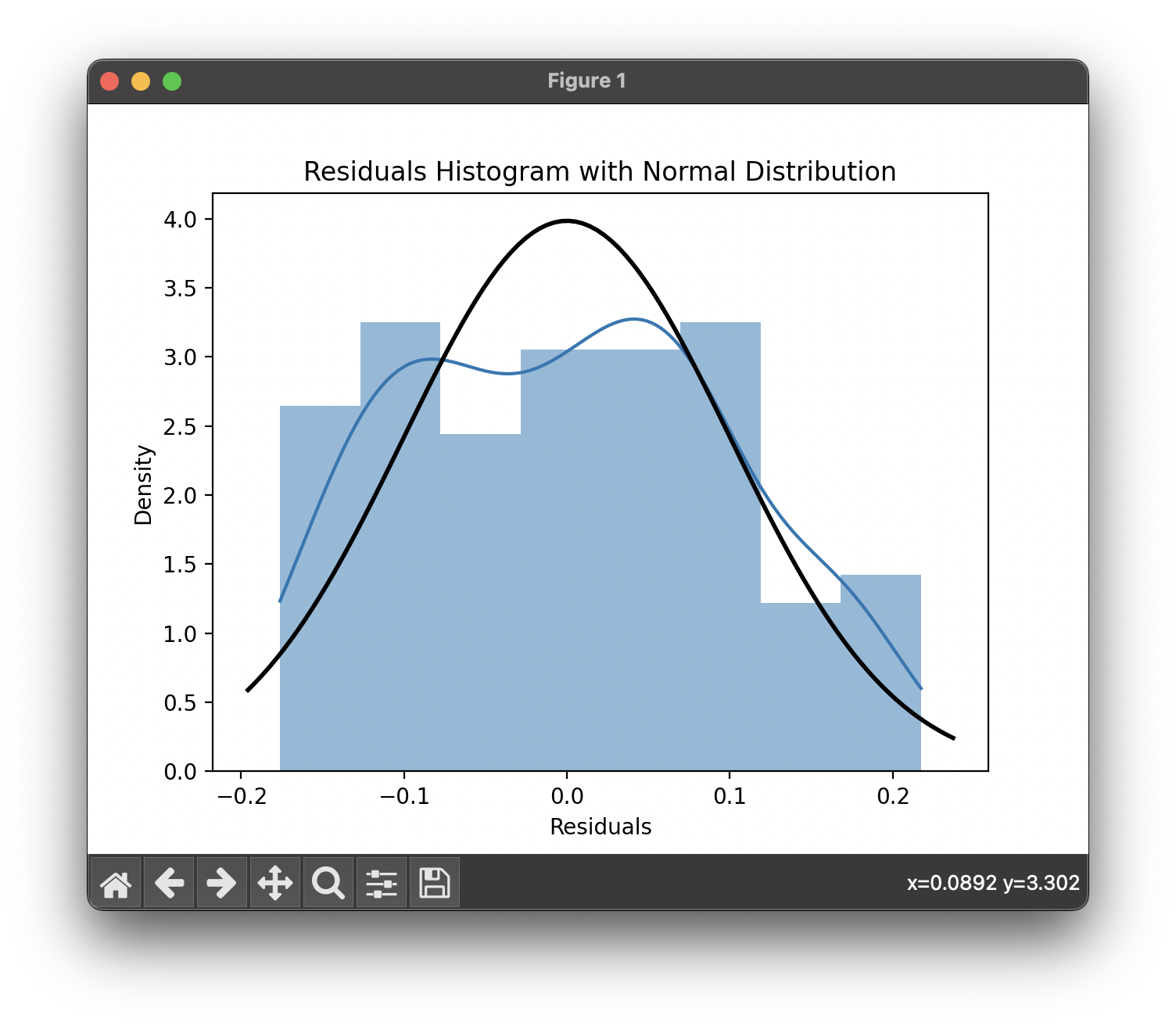
sns.histplot(data['residuals'], kde=True, stat="density", linewidth=0)
plt.title('Residuals Histogram with Normal Distribution')
plt.xlabel('Residuals')
# 정규분포 곡선 추가
xmin, xmax = plt.xlim()
x = np.linspace(xmin, xmax, 100)
p = norm.pdf(x, data['residuals'].mean(), data['residuals'].std())
plt.plot(x, p, 'k', linewidth=2)
plt.show()
# 잔차의 Q-Q 플롯
sns.qqplot(data['residuals'], line ='45')
plt.title('Q-Q Plot of Residuals')
plt.show()- 히스토그램: 데이터를 시각적으로 확인하는 기본 도구로, 값의 분포를 보여준다.
- Boxplot: 데이터의 중간값, 사분위수 및 이상치를 시각화하는 도구입니다.
- describe(): Pandas의 describe() 함수는 데이터의 요약 통계를 제공한다.
- 회귀분석: np.polyfit()을 사용하여 회귀모델을 만들고, 잔차를 계산한다.
- 잔차의 정규성 검정: 잔차가 정규분포를 따르는지 확인하기 위해 히스토그램과 Q-Q 플롯을 사용한다.
이 코드는 회귀분석을 수행한 후, 잔차(residuals)를 분석하여 그 분포가 정규분포를 따르는지 확인하는 과정을 보여준다. 코드는 잔차의 히스토그램과 정규분포 곡선, 그리고 Q-Q 플롯을 통해 시각적으로 잔차의 정규성을 평가한다.
1. 데이터 생성
np.random.seed(0)
x = np.random.rand(100)
y = 2 * x + np.random.normal(0, 0.1, 100)
data = pd.DataFrame({'x': x, 'y': y})np.random.seed(0): 난수 생성의 시드를 설정하여, 동일한 결과를 재현할 수 있도록 한다.x = np.random.rand(100): 0과 1 사이에서 100개의 난수를 생성한다.y = 2 * x + np.random.normal(0, 0.1, 100):x에 대해 선형 관계를 갖는y값을 생성한다. 여기서2 * x는 기울기가 2인 직선이며,np.random.normal(0, 0.1, 100)은 평균이 0이고 표준편차가 0.1인 정규분포에서 난수를 생성하여 오차를 추가한다.data = pd.DataFrame({'x': x, 'y': y}):x와y값을 사용하여DataFrame을 생성한다.
2. 회귀분석 수행
model = np.polyfit(data['x'], data['y'], 1)
data['y_pred'] = np.polyval(model, data['x'])model = np.polyfit(data['x'], data['y'], 1):np.polyfit함수는 다항 회귀분석을 수행한다. 여기서1은 1차 회귀(즉, 선형 회귀)를 의미한다. 이 함수는 회귀 직선의 계수를 반환한다.data['y_pred'] = np.polyval(model, data['x']):np.polyval함수는 주어진 회귀 모델(model)을 사용하여x에 대한 예측값y_pred를 계산한다. 이 예측값을data데이터프레임에 추가한다.
3. 잔차 계산
data['residuals'] = data['y'] - data['y_pred']- 잔차(residuals)는 실제 값(
y)과 예측 값(y_pred)의 차이로 계산된다. 잔차는 회귀모델이 실제 데이터를 얼마나 잘 설명하는지를 나타내는 중요한 지표이다.
4. 잔차의 히스토그램과 정규분포 곡선 시각화
sns.histplot(data['residuals'], kde=True, stat="density", linewidth=0)
plt.title('Residuals Histogram with Normal Distribution')
plt.xlabel('Residuals')sns.histplot(data['residuals'], kde=True, stat="density", linewidth=0): 잔차의 히스토그램을 그리며,kde=True옵션을 통해 커널 밀도 추정(KDE) 곡선도 함께 그린다. 이 히스토그램은 잔차의 분포를 시각화하여, 정규분포를 따르는지 확인할 수 있게 해준다.plt.title과plt.xlabel은 그래프의 제목과 x축 라벨을 설정한다.
정규분포 곡선 추가
xmin, xmax = plt.xlim()
x = np.linspace(xmin, xmax, 100)
p = norm.pdf(x, data['residuals'].mean(), data['residuals'].std())
plt.plot(x, p, 'k', linewidth=2)
plt.show()xmin, xmax = plt.xlim(): 현재 플롯의 x축 범위를 가져온다.x = np.linspace(xmin, xmax, 100):xmin과xmax사이에 100개의 점을 생성한다.p = norm.pdf(x, data['residuals'].mean(), data['residuals'].std()): 정규분포의 확률 밀도 함수(PDF)를 계산한다. 여기서data['residuals'].mean()과data['residuals'].std()는 잔차의 평균과 표준편차이다.plt.plot(x, p, 'k', linewidth=2): 계산된 정규분포 곡선을 히스토그램 위에 그린다.
5. 잔차의 Q-Q 플롯 시각화
sns.qqplot(data['residuals'], line ='45')
plt.title('Q-Q Plot of Residuals')
plt.show()sns.qqplot(data['residuals'], line ='45'): 잔차의 Q-Q 플롯을 생성하여, 잔차가 정규분포를 따르는지 확인한다.line='45'는 이론적 분포와 일치할 경우 점들이 위치해야 하는 대각선(45도 선)을 그린다.plt.title('Q-Q Plot of Residuals'): Q-Q 플롯의 제목을 설정한다.
결과
데이터를 시각화하는 17가지 방법
Distribution Plot
Distribution Plot은 데이터의 분포를 시각화하는데 도움이 된다. 이 그래프를 사용하여 데이터의 평균, 중위수, 범위, 분산, 편차 등을 이해 할 수 있다.
1. Hist plot
- 변수에 대한 히스토그램을 표시한다.
- 하나 혹은 두 개의 변수 분포를 나타내는 전형적인 시각화 도구로 범위에 포함하는 관측수를 세어 표시한다.
2. KDE plot
- 하나 혹은 두 개의 변수에 대한 분표를 그린다.
- histplot은 절대량 그러나 KDEplot은 밀도 추정치를 시각화한다.
- 결과물로는 연속된 곡선의 그래프를 나타낸다.
3. ECDF plot
- 누적 분포를 시각화한다.
- 실제 관측치의 비율을 시각화한다는 장점이 있다.
4. Rug plot
- x축과 y축을 따라 눈금을 그려서 주변 분포도를 표시한다.
- 개발 관측치에 대한 위치를 보여줌으로써 다른 그림들을 보완하는데 주로 쓰인다.
Categorical Plot
범주형 변수를 이해하는데에 도움이 된다. 일변량 혹은 이변량 분석에 사용된다.
5. Bar plot
- 이변량 분석을 위한 plot이다.
- x축에는 범주형 변수, y축에는 연속형 변수를 넣는다.
6. Count plot
- 범주형 변수의 발생 횟수를 센다.
- 일변량 분석이다.
7. Box plot
- 최대, 최소, 평균, 1사분위수, 3사분위수를 보기 위한 그래프
- 특이치를 발견하기에도 좋다.
- 단일 연속형 변수에 대해 수치를 표시하거나, 연속형 변수를 기반으로 서로 다른 범주형 변수를 분석할 수 있다.
8. Violin plot
- Box plot과 비슷하지만 분포에 대한 보충 정보가 제공된다.
9. Strip plot
- 연속형 변수와 범주형 변수 사이의 그래프다.
- 산점도로 표시되는데, 범주형 변수의 인코딩을 추가로 사용한다.
10. Swarm plot
- Strip plot + violin plot의 조합물
- 데이터 포인트 수와 함께 각 데이터의 분포도 제공한다.
Matrix plot
시각화를 위해 2차원 행렬 데이터를 사용하는 특별한 유형의 plot이다. 매트릭스 데이터에서는 사이즈가 크기 때문에 패턴을 분석하고 생성하기 어렵다. 다음에 오는 plot은 매트릭스 데이터에 색상을 제공함으로써 조금 더 분석하기 쉽게 도와준다.
11. Heat Map
- Heat Map을 통해 데이터 간의 수치에 따라 색상을 입힘으로써 직관적인 통찰을 얻을 수 있다.
12. Cluster Map
- 행렬 데이터를 가지고 있고, 유사성에 따라 몇몇 특징들을 그룹화하기 원할 때 사용된다.
Multi-plot Grid
Grid plot은 시각화에 대한 제어력을 높이고 코드 한 줄로 다양한 그래프를 표시한다.
13. Facet Grid
- 어떠한 조건에 따라 그래프를 각각 확인해보고 싶을 때 사용한다.
14. Joint plot
- 두 변수에 대한 displot의 조합이다.
- 두 변수에 분포에 대한 분석을 할 수 있다.
- 두 displot 사이에 scatter plot이 추가되어 분포를 추가로 확인할 수 있다.
- scatter plot 대신 hex plot으로 정의할 수 있다.
15. Pair plot
- 데이터셋을 통째로 넣으면 숫자형 특성에 대하여 각각에 대한 히스토그램과 두 변수 사이의 scatter plot을 그린다.
- 이 한 줄이면 데이터를 한 눈에 보기 쉬워진다.
- 다른 기능이나 유연성이 더 필요하다면 pairgrid를 사용하면 된다.
Regression plot
Regression plot은 지금까지 봐온 plot과는 개념이 조금 다른데, regression 머신러닝의 결과를 그래프에 표기해준다. 즉, 데이터를 잇는 그대로 보여주기보다는 머신러닝 결과와 함께 보여주는 것이다.
16. Reg plot
- Regression 결과를 그래프로 보여준다.
17. LM plot
- 이 plot은 regplot()과 faceGrid를 결합한 것이다.
