[요약]
Clone Site : 에어비앤비
GitHub : https://github.com/BG-YU/21-2nd-GroundBnB-backend
데모영상 : https://www.youtube.com/watch?v=nb_UiJRXuQc팀원
프론트엔드 : 백진수, 박현찬
백엔드 : 유병건, 황복실, 한성봉제작기간
2021/6/21 ~ 2021/7/2
사이트 기능
[카카오 소셜로그인]
- kakao social login / logout[숙소]
- 검색어 리스트(본인 개발, Source Code 보기)
- 숙소 리스트 조회(본인 개발, Source Code 보기)
- 숙소 상세
- 숙소 리뷰 조회(본인 개발, Source Code 보기)
- 숙소 리뷰 작성(본인 개발, Source Code 보기)
- 숙소 리뷰 삭제(본인 개발, Source Code 보기)
- 숙소 항목별 평점 조회(숙소 리뷰 기능에 포함)[위시리스트]
- 위시리스트 조회(본인 개발, Source Code 보기)
- 위시리스트 삭제(본인 개발, Source Code 보기)
- 위시리스트 추가(본인 개발, Source Code 보기)Skill Stack
Python, Django web framework, Bcrypt, JWT, MySQL, RESTful API
ETC
AQueryTool, Git, trello, gspread
1. 사이트 선정
1차 클론 프로젝트인 캐치패션 프로젝트는 프로젝트가 어떻게 흘러가고 프론트엔드와 백엔드의 의사소통이 어떻게 이루어 지며, 코딩의 감을 익히는 프로젝트였다면 2차 프로젝트는 본격적으로 기능구현에 초점을 두어 진행해 보고자 했습니다.
이번 프로젝트에서는 개인 목표와 팀의 목표를 분리하여 동시에 진행을 하는 방식으로 진행해 보았습니다.
[팀 목표]
- 소셜로그인
- GoogleMap을 활용한 숙소정보 표시
- 숙소 리스트
- 숙소 상세페이지
- 댓글 및 대댓글 기능
- 상품별 평점 기능
[개인 목표]
- 경험해 보고 싶은 기술 Stack
- redis 적용
- ec2, rds, s3사용하여 배포
- ORM의 숙련도를 올리기
- hit수를 생각하며 orm작성 해보기
1-1. 개인목표 달성하기?
1차 프로젝트 때도 aws의 ec2를 활용하여 배포를 해본 경험이 있었기에, 이번에는 rds와 s3까지 이용하여 배포를 해보고자 하는 개인적인 욕망이 생겼습니다.
그리고 데이터베이스 부하를 줄이기 위하여 redis를 활용해보고 싶은 목표도 있었기에, 사전에 팀원들에게 양해를 구해야 했습니다.
팀원들에게 redis가 무엇인지 그리고 rds와 s3를 사용하면 코딩에서 어떤 부분이 달라지는지를 아래와 같이 설명하였고, 팀원분들도 다들 허락해 주셔서 팀 프로젝트지만 저의 개인적인 욕망을 담은 프로젝트를 시작하게 되었습니다.
-
redis는 cache서버의 하나로써, cache서버에 존재하는 정보라면 DB를 거치지 않고 client쪽으로 바로 정보를 줄수 있기에, DB부하를 줄이는데 도움이 된다.
클론 프로젝트이기에 실제적으로 DB부하가 일어날 일은 없겠지만 그래도 한번 사용해본 경험이 있으면 현업에 가서 큰 차이가 있을 것이다. -
rds를 사용하여 로컬DB가 아닌 개발DB와 운영DB를 나누어 개발을 진행하게 되면 같은 데이터를 공유할수 있으므로 차후 각기 다른 데이터에서 오는 오류를 미연에 방지할수 있다.
-
s3를 사용하여 이미지 파일을 공유하게 되므로 이미지 더미 데이터 작업을 한번만 하면된다.
2. 요구정의
1차 프로젝트였던 캐치패션 프로젝트와 마찬가지로 한정된 기간안에서 프로젝트를 진행하여야 했기에 기능축소 작업을 진행하였습니다.
- 기본적인 이메일로 회원가입/로그인은 1차 프로젝트에서 경험했기에 소셜로그인만 구현한다.
- 에어비앤비의 메인페이지에 있는 숙소, 체험, 온라인체험 중 숙소 카테고리만 구현한다.
- 검색기능과 연관검색어만 구현한다.
- 숙소는 국내로 한정한다.
- 숙소의 상세페이지는 이미지를 2~3장 정도로 줄인다.
- 슈퍼호스트(관리자 기능)의 기능은 제외한다.
- 할인기능은 삭제한다.
- GoogleMap의 1차 기능으로는 숙소 검색시 위치 주소를 기반으로 Mark를 우선적으로 하고, 여유가 된다면 Mark대신 팝업의 형태로 숙소의 간단한 정보와 이미지를 표시한다.
...하략
3. DataBase Modeling
3-1. ERD
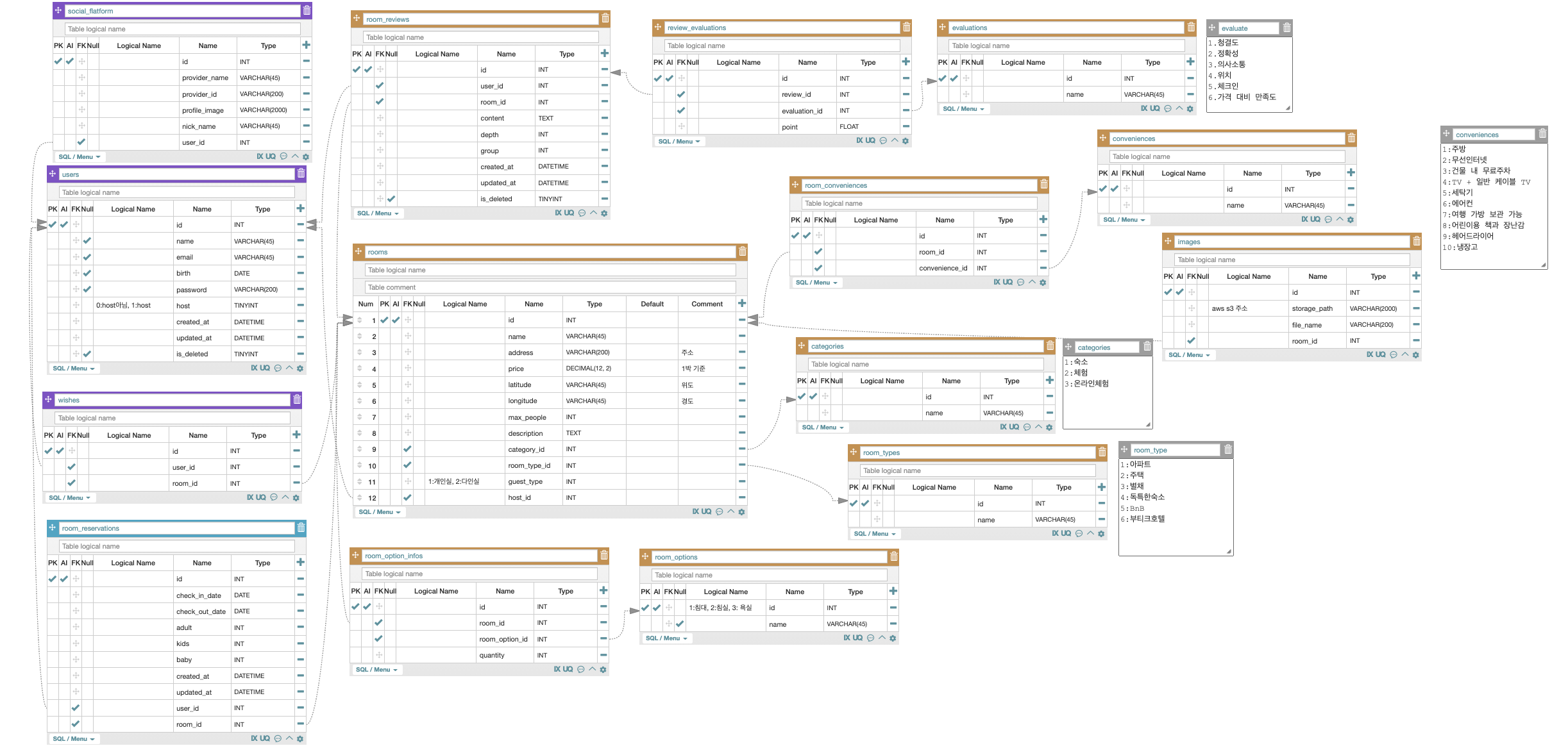
URL : https://aquerytool.com/aquerymain/index/?rurl=7869158f-d0a0-42ab-9468-f58e2f0bf55e&
Password : 66s82l
4. 기능구현
1차 프로젝트인 캐치패션 프로젝트와는 달리, 2차 프로젝트 기능구현파트에서는 제가 구현하면서 새로웠던 부분만을 간략하게 회고해볼려고 합니다.
4-1. 연관검색어
에어비앤비에서 숙소 검색은 주소기반으로 검색어를 입력하게 끔 되어 있었습니다.
검색어가 매번 입력될때 마다 DB에 select문을 like조건으로 검색하기에는 너무 많은 부하가 걸릴것 같아 hashmap과 redis를 활용해 보기로 하였습니다.
redis를 사용하기 위해서는 기본적인 redis의 특징과 사용법을 익혀야만 했습니다.
redis를 처음 사용해보는 것이기에 진입장벽이 상당히 높을 것이라는 막연한 두려움이 있었습니다만, 막상 공부를 해보니 생각보다(?) 어렵지 않다는 것을 느꼇습니다.
일단 시간적&심리적 여유가 없었기에 딱 2가지만을 염두해 두고 구현 작업을 시작했습니다.
- redis는 dictionary와 같이 key, value의 값을 가진다.
- key값은 만료시간을 설정할 수 있다.
redis를 활용한 연관검색어 로직은 아래와 같습니다.
- ERD상 주소의 정보를 address컬럼 하나에 넣어 놓았기에 시군구읍면동 단위로 분리&중복 제거 하는 작업을 raw쿼리로 진행한다.
(ORM으로 address컬럼에 들어있는 데이터를 split하고 중복제거까지 할수 있는 방법이 떠오르지 않아, 시간관계상 raw쿼리를 사용하기로 하였습니다.)
# [address컬럼 데이터 예시]
# 서울특별시 은평구 불광동 281-23 ABC빌라 203호
# 서울특별시 은평구 불광동 ABC아파트 102동 301호
# 서울특별시 은평구 응암동 DEF아파트 301동 1009호
# 대구광역시 북구 복현동 147-1
# ORM으로 address컬럼에 들어있는 데이터를 split하고 중복제거까지 할수 있는 방법이 떠오르지 않아, 시간관계상 raw쿼리를 사용하기로 하였습니다.
address = Room.objects.raw('''
SELECT row_number() over() as id
, room_address.address
FROM (
SELECT distinct substring_index(address, ' ', 3) as address
FROM rooms
) room_address
'''
)-
redis에 address key로 값이 있는지 확인한다.
2-1. redis에 address key 값이 없다면 3번의 과정을 key값이 있다면 4번의 과정을 진행한다. -
서, 서울, 서울특, 서울특별, 서울특별시 5가지의 단어가 모두 서울특별시에 걸려들어야 하므로 raw쿼리로 가져온 데이터를 dictionary의 key로 사용하고, 전체 주소의 정보를 value값으로 설정한다.
3-1. 3번의 과정을 거친 dictionary를 redis에 address key값으로 담는다.
address_dic = cache.get('address') or {}
if not address_dic:
for object in address:
for i in range(0, len(object.address)):
word = object.address[0 : i + 1].replace(' ', '')
if address_dic.get(word.replace(' ', '')):
temp_list = address_dic[word]
if not object.address in temp_list:
temp_list.append(object.address)
address_dic[word] = temp_list
else:
address_dic[word] = [object.address]
# cache의 address key 만료시간을 24시간으로 설정한다.
cache.set('address', address_dic, 60 * 60 * 24)- redis에서 address key값으로 dictionary를 끄집어 내서 dictionary의 key값중 검색어와 일치하는 값이 있는지 비교하여 response한다.
4-2. 연관검색어 추후 보완점
-
redis의 key만료 값이 24시간 기준이므로 24시간이 지나기 전에 새로운 주소가 등록이 된다면 연관검색어에 나타나지 않는 다는 단점이 있으므로 리팩토링의 대상입니다...
-
24시간이 지나 처음으로 검색어를 사용하는 유저는 연관검색어가 처음부터 모든 로직이 실행되기에 느리다고 느낄수 있으므로, cron job등을 이용해 배치를 돌리는 것도 하나의 방법일것 같다는 생각을 하였습니다.
5. 마치며...
이번에도 자연스럽게 PM, 시니어 개발자 느낌의 서포터, API 개발을 동시에 진행하였습니다.
PM의 역할은 누가 시킨 것도 아니며, 넌 PM이야 라고 지정해 준것도 아니지만 프로젝트가 산으로 가는것을 막고자 다양한 의견을 제시하면서 스케쥴 관리 및 회의 주관을 하다보니 자연스럽게 PM의 역할을 이번에도 하게되었던것 같습니다.
그래도 이번 프로젝트에서는 개발자로써의 성장이라는 부분도 중요하였기에 API 기능구현에 좀 더 비중을 두면서 진행을 하였습니다.
덕분에 성능을 고려한 ORM 사용법과 unit테스트를 작성, redis의 사용, aws(ec2, rds, s3)를 활용한 배포 등등 개인적으로는 많은것을 얻을수 있었던 프로젝트 였습니다.
