1. 지능형 시스템의 정의와 분해
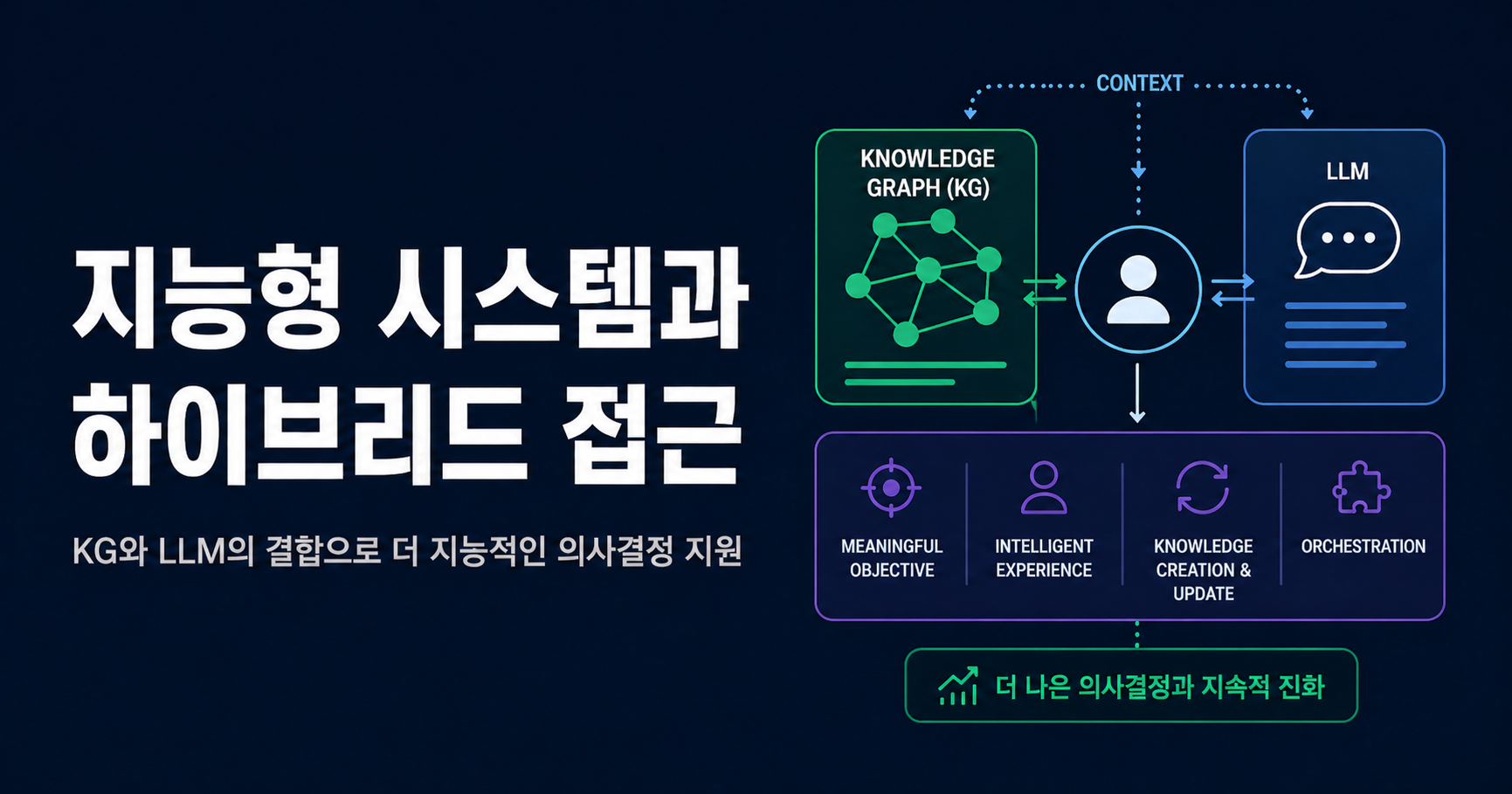
지능형 시스템(intelligent system)은 사용자를 AI/ML과 연결해 의미 있는 목적을 달성하는 시스템으로 정의된다. 핵심 속성은 사용자와의 상호작용을 관찰하며 시간에 따라 지능이 진화한다는 점이다. 외부에서 보면 복잡한 작업을 수행하는 black box이지만, 이를 이해하기 위한 첫 단계는 기능 단위로 분해하는 것이다.
지능형 에이전트는 두 개의 핵심 컴포넌트로 분해된다. knowledge representation은 AI 시스템이 도메인 정보를 구조화·인코딩·전달하기 위해 사용하는 "언어"이며, AI가 추론하고 예측하기 위한 전제이자 그 결과를 해석하는 수단이다. 어떤 표현을 선택하느냐가 시스템의 능력과 한계를 결정한다. reasoning은 정보를 분석하고 규칙을 적용해 결론을 도출하는 인지 과정으로, deductive·inductive 등 여러 형태가 있다. KG와 LLM을 결합한 시스템은 이 reasoning 능력을 확장하는 방향으로 발전하고 있다.
2. Autonomous System vs Advisor System
지능형 시스템은 사용자를 대신해 행동하는가, 아니면 지원하는가에 따라 두 범주로 나뉜다. intelligent autonomous system은 사용자를 대체해 의사결정과 실행을 수행하고, intelligent advisory system(IAS)은 정보와 추천을 제공하되 실행 권한은 사용자에게 남긴다.
| 비교 축 | Autonomous System | Advisory System (IAS) |
|---|---|---|
| 의사결정 주체 | 시스템 | 사용자 |
| 자동화 수준 | full automation, 인간 입력 최소 | decision support, 실행은 사용자 |
| 핵심 요건 | real-time decision-making, adaptability | context awareness, user interaction |
| 대표 예시 | 자율주행, 자동 트레이딩 | 추천 시스템, 진단 보조 |
| 실패 비용 | 높음 (직접 행동) | 낮음 (사용자가 필터) |
두 경우 모두 사용자를 대체하는 것이 아니라 사용자를 지원·보조한다는 점이 핵심이다. 책에서 채택하는 설계 방향은 autonomous advisor 쪽이다. 즉, 행동이 아닌 제안을 생성하되, 일반 지식이 아니라 도메인 전문가가 정제한 established knowledge base 위에서 동작하고, 제안 결과의 피드백으로 지식 베이스를 확장한다.
3. 지능형 시스템의 네 가지 설계 축
설계와 구현을 동시에 견인하는 네 가지 특성이 존재한다. meaningful objective는 시스템이 존재하는 구체적이고 달성 가능한 목적이며, 전체 개발 과정을 끌고 가는 축이다. intelligent experience는 예측 결과를 사용자에게 어떻게 제시하느냐의 문제로, 예측이 맞을 때 가치를 극대화하고 틀렸을 때 비용을 최소화하는 인터페이스를 요구한다. 동시에 implicit/explicit 피드백을 수집할 수 있어야 한다. knowledge creation and update는 변화하는 지식과 사용자 피드백을 지속적으로 반영하는 능력이며, LLM과 KG의 결합이 이 지점을 보강한다. orchestration은 다수의 알고리즘과 도구가 서로의 출력을 입력으로 삼아 협업하도록 조율하는 일을 가리킨다.
4. Knowledge Acquisition: KG와 LLM의 비대칭
knowledge acquisition은 원천 데이터를 reasoning engine이 사용할 수 있는 형태로 변환하는 단계다. KG와 LLM은 이 단계에서 근본적으로 다른 경로를 밟는다.
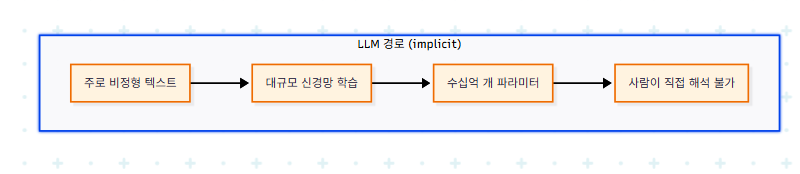

KG의 acquisition은 entity·relationship·property 단위로 데이터를 명시적 구조에 매핑하는 작업이며, 도메인 전문가가 데이터 소스 선정·스키마 설계·결과 검증 전 단계에 개입할 수 있다. LLM의 acquisition은 주로 unsupervised 학습으로 텍스트를 통계적 파라미터에 흡수하는 과정이며, 도메인 전문가의 개입은 데이터 선택과 결과 평가에 제한된다. 모델 내부 표현을 직접 보거나 수정할 수 없고, 커스텀 fine-tuning이 거의 유일한 보강 수단이다.
이 비대칭은 세 가지 설계 차이로 귀결된다.
| 차원 | KG | LLM |
|---|---|---|
| Access | explicit. 사람/기계 모두 해석 가능 | implicit. 파라미터 공간, 불투명 |
| Updates | node·relationship 추가/수정 | 재학습 또는 fine-tuning 필요 |
| Capabilities | 접근 패턴·스키마 설계 의존 | 자연어 이해·생성에 본질적으로 강함 |
| 전문가 검증 | 가능 (graph를 직접 검토) | 결과 평가 단계로 제한 |
5. Reasoning과 하이브리드 IAS의 근거
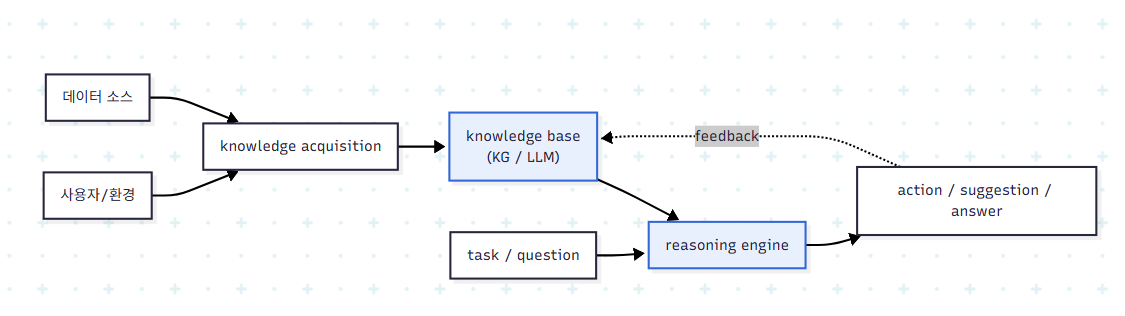
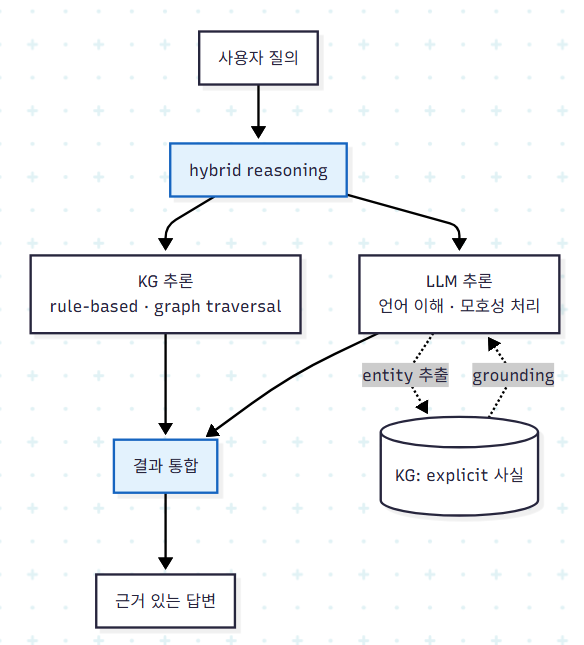
reasoning은 acquisition된 knowledge 위에서 수행되며, 새로운 지식을 생성하거나 답·제안·자율 행동을 만들어낸다. KG는 정밀한 rule-based 추론과 explicit 표현이 필요한 작업에 강하고, LLM은 패턴 인식·맥락 이해·모호하거나 불완전한 정보 처리에 강하다. 두 접근 모두 인간 수준의 common-sense reasoning은 본질적으로 갖추지 못하며, 직관적 비약이나 암묵적 맥락 파악에서 한계를 드러낸다. 이 한계가 역설적으로 hybrid IAS의 설계 근거가 된다.
ML이 KG에 기여하는 두 가지 경로가 있다. 첫째, 관련 ontology와 relationship을 학습·구축해 knowledge base의 커버리지를 확장한다. 둘째, 불확실성 하의 inference를 제공해 데이터가 불완전한 경우에도 예측을 가능하게 한다. 반대 방향에서, KG는 generative AI의 hallucination을 완화하고 최신 데이터를 공급하는 grounding 장치로 기능한다.
6. KG 구축 방식: Top-down vs Bottom-up
KG를 어떤 순서로 구축하느냐에 따라 프로젝트 성공률이 달라진다. bottom-up은 가용한 모든 데이터를 먼저 적재하고 그래프로 변환한 뒤, 어떤 task에 활용할지 사후에 고민하는 방식이다. 데이터가 이미 다 들어가 있어 스키마 변경이 어렵고, 결과적으로 functional task와 무관하게 비대해진 그래프가 나오기 쉽다. top-down은 비즈니스 목표와 functional task에서 출발해 필요한 데이터·스키마·모델을 역으로 정의하는 CRISP-DM 유형의 사이클을 따른다.
| 비교 축 | Bottom-up | Top-down (purpose-driven) |
|---|---|---|
| 출발점 | 가용 데이터 | 비즈니스 목표 |
| 스키마 진화 | 적재 후 고정 (변경 비용 큼) | iteration마다 재정의 |
| 실패 양상 | "데이터는 있는데 쓸 곳이 없음" | scope 정의 자체가 어려움 |
| 추천 상황 | 탐색적 데이터 통합 | production 시스템 구축 |
책은 top-down 방식을 권고한다. 명확한 목적이 없는 데이터 통합은 프로젝트 실패의 주요 원인이기 때문이다.
7. 한계와 트레이드오프
하이브리드 접근은 강력하지만 무비용은 아니다. 본문 개념에서 도출되는 트레이드오프는 다음과 같다.
첫째, 운영 복잡도의 증가. KG와 LLM을 동시에 관리한다는 것은 두 개의 서로 다른 lifecycle을 다룬다는 의미다. KG는 스키마 변경·데이터 일관성·전문가 검증 주기를 가지며, LLM은 재학습·fine-tuning·평가 셋 관리 주기를 가진다. orchestration 레이어가 늘어날수록 디버깅 지점도 늘어난다.
둘째, 업데이트 비대칭의 비용. KG는 노드/엣지 단위로 즉시 갱신할 수 있지만, LLM의 implicit 지식은 재학습 없이는 갱신되지 않는다. 따라서 "최신성"이 중요한 도메인일수록 사실 정보는 KG로 외부화하고 LLM은 언어 처리 계층으로 좁혀 사용하는 분업이 합리적이다. 이는 GraphRAG 계열 아키텍처가 일관되게 따르는 설계 원칙이기도 하다.
셋째, common-sense의 빈자리. 두 접근 모두 인간의 직관적 추론은 갖추지 못한다. 시스템이 "당연한" 맥락을 놓쳐 잘못된 제안을 내놓을 수 있으므로, autonomous 모드보다 advisory 모드가 안전하다는 결론은 단순한 보수적 선택이 아니라 기술적 한계에 근거한 설계 결정이다.
8. 실무 적용 시 고려사항
production 환경에서 하이브리드 IAS를 도입할 때 가장 먼저 결정할 것은 autonomous와 advisory 사이의 위치다. 의료·금융·법률처럼 실패 비용이 큰 도메인일수록 advisory 쪽으로 무게중심을 이동시키고, intelligent experience 단계에서 신뢰도와 근거를 함께 제시하는 인터페이스를 설계해야 한다. 사용자의 implicit/explicit 피드백을 KG로 환류시키는 경로를 처음부터 확보하지 않으면, 시스템은 시간이 지나도 진화하지 않는다.
다음으로 KG의 scope를 task에 맞춰 좁게 시작해야 한다. bottom-up으로 시작한 프로젝트가 실패하는 흔한 이유는 그래프가 충분히 풍부해도 그것을 활용할 reasoning task가 정의되어 있지 않기 때문이다. top-down 방식으로 단일 functional task를 먼저 해결하고, 거기서 검증된 스키마를 옆으로 확장하는 incremental 전략이 안전하다.
참고 자료
- Knowledge Graphs and LLMs in Action, Manning Publications, 2024 — Chapter 2: Intelligent systems: A hybrid approach
