
준비물
- BigQuery 무료 계정
- 2년 전, 부트캠프에서 사용
- 제한된 용량에서 무료로 사용 가능
- dataset
Brazilian E-Commerce Public Dataset by Olistfrom kaggle- 선정 이유
- 2년 전보다 더 나은 분석 결과를 얻기 위해 동일한 데이터셋 선택
- 추천 수가 많은 gold 메달의 데이터셋
- 9개월 전에 업데이트
- E-Commerce라는 주제
진행 사항
환경 구성
- 새 프로젝트 생성
- 데이터셋 만들기
- 생성된 프로젝트 옆 아이콘 클릭
- 여러 테이블을 담고 있는 데이터셋 생성
olist_2022
- 테이블 만들기
- 데이터셋 옆 아이콘 클릭
- 소스
- kaggle에서 받은 csv 파일
- 용량이 크지 않으므로 로컬 파일 업로드
- 스키마 자동 감지 클릭
- 스키마 자동 생성
데이터 탐색
- 데이터 구조 정리
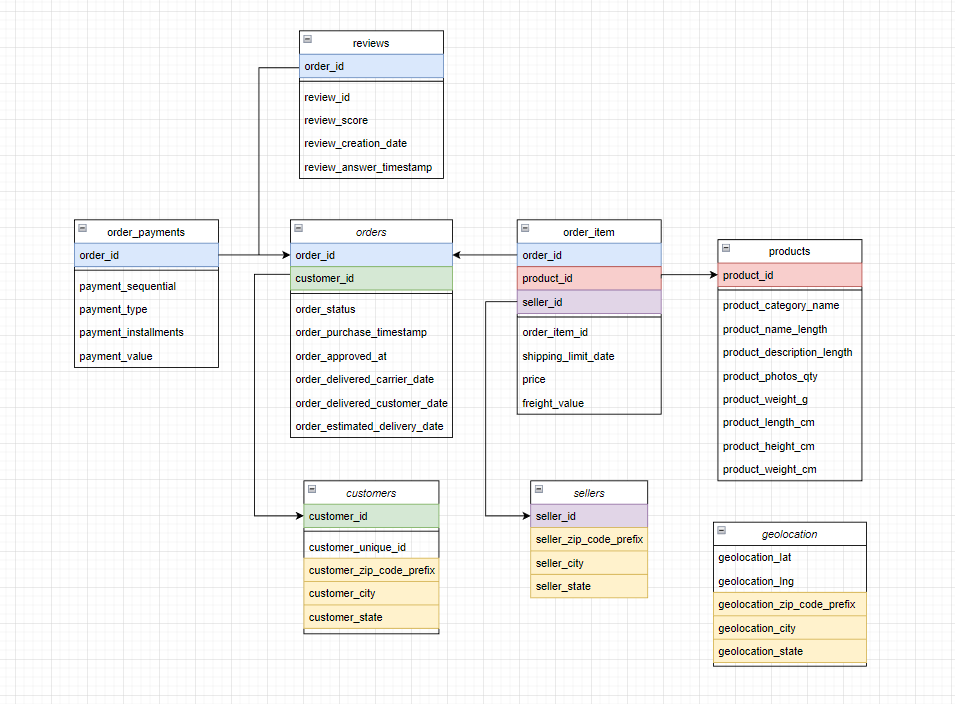
geolocation.csv와customers.csvzipcode_prefix와city,state가 같음
payment installments- 할부 개월 수
- 브라질 문화
- https://www.kaggle.com/datasets/olistbr/brazilian-ecommerce/discussion/285593?search=installmen
- 지불 기간을 늘리기 위해 할부를 택하지만 이자율이 높다
데이터 전처리
- product category name translation
- 상품 카테고리명 번역
- 포루투갈어 >> 영어
- 상품 카테고리명 번역
import pandas as pd
# 파일 불러오기
product_df = pd.read_csv('olist_products_dataset.csv', encoding='utf-8')
translation_df = pd.read_csv('product_category_name_translation.csv', encoding='utf-8')# 특정 열 가져오기
product_series = product_df['product_category_name']
name_series = translation_df['product_category_name']
eng_series = translation_df['product_category_name_english']
# 전처리하기 위해 list로 타입 변경하기
product_list = product_series.tolist()
name_list = name_series.tolist()
eng_list = eng_series.tolist()# 없는 값 확인하기
non_list = []
for product in product_list:
if product not in name_list:
non_list.append(product_list.index(product))
set(non_list) # 중복 제외 # 105, 1628, 5821# 대응되는 인덱스만 추출해서 변환하기
for product in product_list:
if product in name_list:
product_list[product_list.index(product)] = eng_list[name_list.index(product)]
# 변환한 값 적용하기
product_series = pd.Series(product_list)
product_df['product_category_name'] = product_series# 변환한 dataframe 저장하기
product_df.to_csv("olist_products_dataset.csv", mode='w', index=False)- review 테이블 특정 열 제거
- BigQuery에서는 new line이 포함된 csv 파일을 사용할 수 없다
- 포루투갈어로 적혀있기 때문에 내용보다는 review score가 더 중요하다고 판단했다
comment_title과comment_message열에 NULL 값이 많다- 따라서, 두 컬럼을 제외하기로 결론 지었다
# review 테이블 가져오기
review_df = pd.read_csv('olist_order_reviews_dataset.csv', encoding='utf-8')
# comment_title 및 comment_message 열 제거
review_df = review_df.drop(['review_comment_title','review_comment_message'], axis=1)
# review 갱신하기
review_df.to_csv("olist_order_reviews_dataset.csv", mode='w', index=False)orders테이블timestamp컬럼 타입 변환- 분석이 쉬운 datetime 형태로 변환
- python 상에서는 str로 인식
- convert str to datetime
# order 테이블 불러오기
order_df = pd.read_csv('olist_orders_dataset.csv', encoding='utf-8')
# 컬럼 type 확인하기
purchase_time = order_df['order_purchase_timestamp']
type(purchase_time[0]) # str
# datetime으로 변환하기
from datetime import datetime
date_list = []
for i in range(len(purchase_time)):
date = purchase_time[i].split(' ')
date_list.append(datetime.strptime(date[0], "%Y-%m-%d"))
purchase_time = pd.Series(date_list)
# 바뀐 데이터 적용하기
order_df['order_purchase_timestamp'] = purchase_timetimestamp가 null인 컬럼들- 형변환 시, 예외 발생하므로 '2000-01-01 00:00:00' 값으로 대체 후 전처리
.fillna적용 안되는 문제inplace=True옵션 추가- 기존 데이터프레임에 변경된 내용 적용하는 옵션
# 결측치 개수 확인
order_df.isnull().sum()order_id 0
customer_id 0
order_status 0
order_purchase_timestamp 0
order_approved_at 160
order_delivered_carrier_date 1783
order_delivered_customer_date 2965
order_estimated_delivery_date 0
dtype: int64# 결측치 대체
order_df.fillna('2000-01-01 00:00:00', inplace=True)
order_df.isnull().sum()order_id 0
customer_id 0
order_status 0
order_purchase_timestamp 0
order_approved_at 0
order_delivered_carrier_date 0
order_delivered_customer_date 0
order_estimated_delivery_date 0
dtype: int64# 결측치 복원
order_df.replace('2000-01-01', '', inplace=True)EDA
데이터의 출처와 주제에 대한 이해
- a Brazilian ecommerce public dataset of orders made at Olist Store
- Olist Store
- Olist Website
- the largest department store in Brazilian marketplaces
- 브라질 전국의 소규모 기업들과 connection
- Olist store에서 물건을 팔고 Olist의 물류센터를 통해 직접 고객에게 물품 배송 가능
- customer and its location
- 주문 dataset에서 unique customers를 확인하고 배송지를 찾는 데 사용할 것
- 각 주문들에는 unique customer id가 부여되어 있다
- 동일한 고객이 다른 주문에 대해서 다른 id를 가질 수 있다
- customer id의 목적은 재주문을 한 고객을 찾는 데 있다
-
주제 선정
“How fast each order gets delivered to customers”
- 상품 / 서비스 측면
- 배송 서비스에 대한 고객의 만족도 측정
- 관련 테이블 및 컬럼들
ordersorder_item: [product_id], shipping_limit_dateproduct: [product_id], product_category_namereviews: [order_id], review_scorecustomers: [customer_id], ...zip_code_prefix, ...city, ...stategeolocation: ...zip_code_prefix, ...city, ...statesellers: ...zip_code_prefix, ...city, ...state
- 상품 / 서비스 측면
데이터의 크기 확인
- 2016년부터 2018년까지 생성된 100,000 건의 주문 취합
# customers
customer_df.shape
(99441, 5)# geo location
geo_df.shape
(1000163, 5)# order items
order_item_df.shape
(112650, 7)# order payments
order_payment_df.shape
(103886, 5)# order reviews
order_review_df.shape
(99224, 7)# order
order_df.shape
(99441, 8)
order_df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 99441 entries, 0 to 99440
Data columns (total 8 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 order_id 99441 non-null object
1 customer_id 99441 non-null object
2 order_status 99441 non-null object
3 order_purchase_timestamp 99441 non-null object
4 order_approved_at 99281 non-null object ***
5 order_delivered_carrier_date 97658 non-null object ***
6 order_delivered_customer_date 96476 non-null object ***
7 order_estimated_delivery_date 99441 non-null object
dtypes: object(8)
memory usage: 6.1+ MB# order products
product_df.shape
(32951, 9)
product_df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 32951 entries, 0 to 32950
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 product_id 32951 non-null object
1 product_category_name 32341 non-null object ***
2 product_name_lenght 32341 non-null float64 ***
3 product_description_lenght 32341 non-null float64 ***
4 product_photos_qty 32341 non-null float64 ***
5 product_weight_g 32949 non-null float64 ***
6 product_length_cm 32949 non-null float64 ***
7 product_height_cm 32949 non-null float64 ***
8 product_width_cm 32949 non-null float64 ***
dtypes: float64(7), object(2)
memory usage: 2.3+ MB# sellers
seller_df.shape
(3095, 4)데이터 구성 요소(feature)의 속성(특징) 확인
- 노션에 추가

There's Only One Thing To Do: Learn All We Can