
개요
본 블로그 포스팅은 수도권 ICT 이노베이션 스퀘어에서 진행하는 AI 핵심 기술 집중 클래스의 자연어처리(NLP) 강좌 내용을 필자가 다시 복기한 내용에 관한 것입니다.
1. 벡터화 방법론과 LM
이전 포스트 1. NLP-Text 전처리 : 고전벡터화(TF-IDF) - AI 핵심기술 강의 복습 에서 Text Preprocessing(텍스트 전처리) -
6. Vectorization (Embedding)의 방법론으로
DTM(Document Term Matrix),
TF-IDF(Term Frequency Inverse - Inverse Document Frequency) 에 대하여 학습했고
위 방법론으로 문서를 벡터화 한 뒤 이를 기초적인 LM(Language Model)에 입력 및 학습을 진행했다.
이를 도식화 하면 아래와 같다.
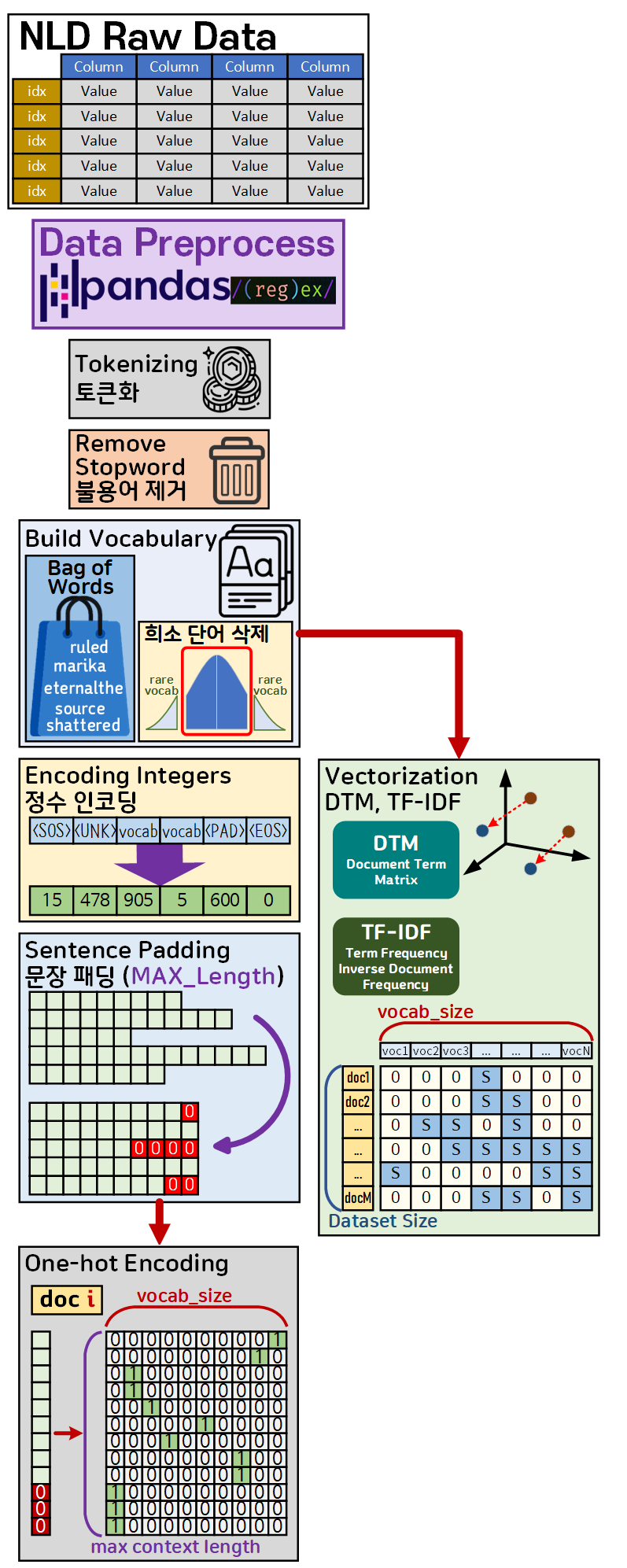
위 그림처럼 Text Preprocessing(텍스트 전처리)를 다양한 단계를 거쳐서 진행되는 것을 알 수 있으며
문장 패딩까지 진행 후 최종 결과물은
One-hot Encoding 처리된 벡터가 언어 모델, LM에 입력되고
고전 벡터화 방법론으로 벡터화를 수행한다면
단어장 생성 결과물로 TF-IDF으로 처리된 벡터가 언어 모델, LM에 입력되는 것이다.
이를 비교하자면 아래와 같다.
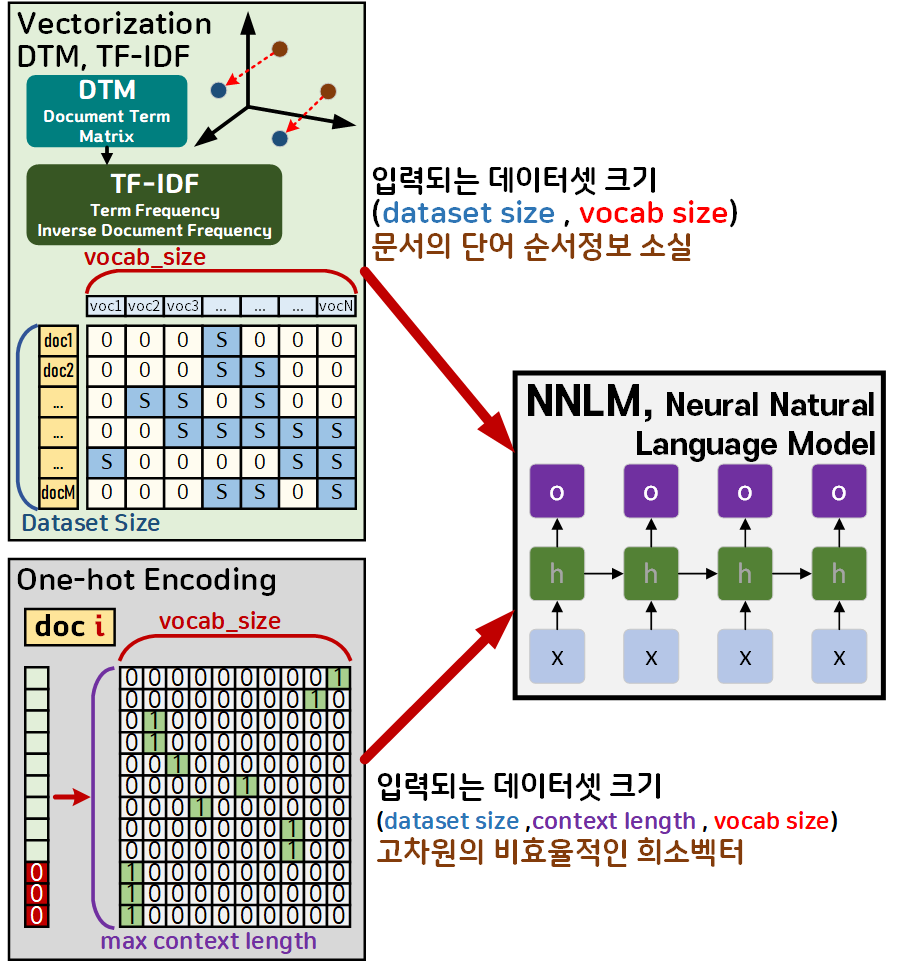
여기서 사전에 알아둘 필요가 있는 항목은
흔히 문장패딩까지 완료한 정수인코딩 결과값과
이 정수인코딩+문장패딩 결과값을 다시 One-hot encoding 를 적용한 결과값을 딥러닝 모델에 입력했을 시 성능차이가 없음을 알아야 한다.
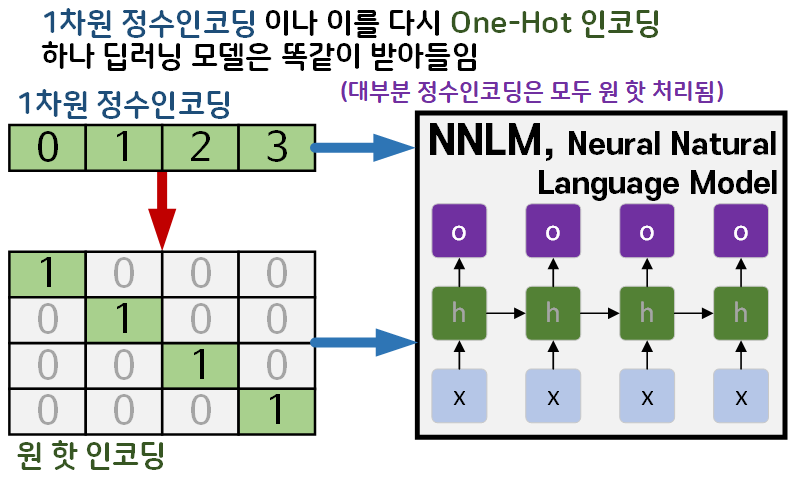
이는 1차원 정수인코딩 결과치는 따지고 보면 단순히 단어에 대한 고유한 정수 ID를 부여한 것에 불과한 것이고
이를 벡터화 한 것이 One-hot encoding이기 때문이다.
따라서 입력받는 모델 입장에서는 두 데이터는 차이가 존재하지 않는다.
이것을 이해했다면 One-hot encoding처리된 데이터셋이 (dataset_size, context_length, vocab_size) 3차원의 정보로 인코딩 됨을 이해할 수 있을 것이며,
인코딩 결과 고 차원에 대부분의 원소가 의미없는 0으로 차있는 희소 벡터로 변환됨을 알 수 있을 것이다.
즉, One-hot encoding는 딥러닝 모델에 입력하기에는 매우 비 효율적으로 처리된 데이터라 볼 수 있다.
이 문제를 개선하기 위해 단어의 빈도정보에 집중한
DTM, TF-IDF와 같은 벡터화 방법론이 제시되었으나,
DTM, TF-IDF는 문서의 구성요소인 단어의 순서정보가 완전히 유실된다.
따라서 해당 문서가 담고 있는 문맥적인 관계를 유추하거나 생성하는 것이 불가능하다.
1.1 Projection Layer
따라서 단어의 순서정보가 완전히 유실되는 TF-IDF보다는 문맥 정보라도 유추하는 것이 가능한 One-hot encoding를 기반으로 고차원의 희소벡터를 최적화 하기 위하여
저 차원의 밀집 벡터(Dense vector)로 변환하는 과정을 적용한다
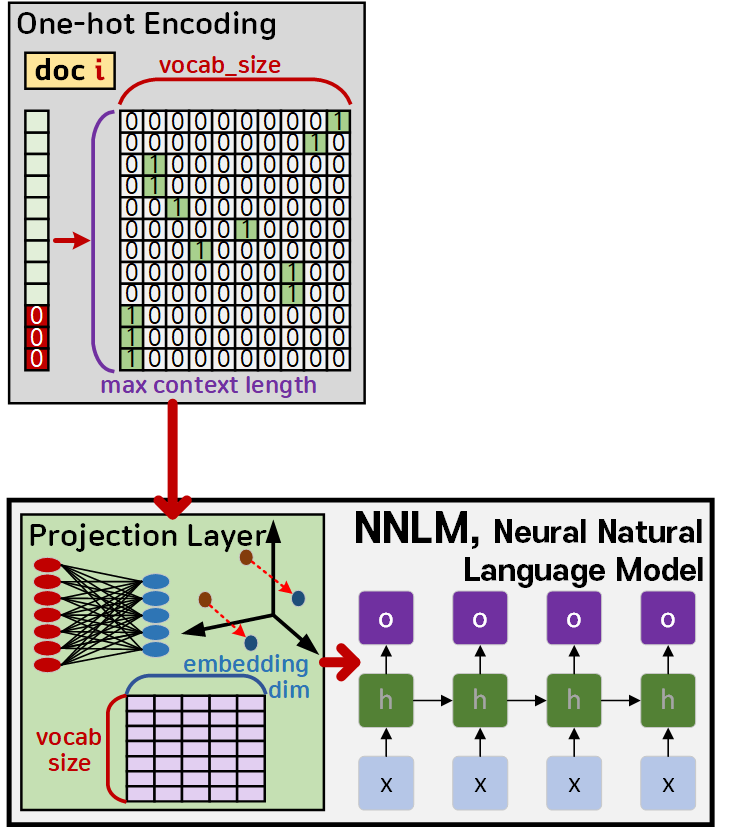
이 Projection layer는 그림에서 표현한 것을 보면 알 수 있듯이 1층짜리 퍼셉트론 레이어로 해당 레이어를 구성하면서 발생하는 weighted matrix를
lookup tabele로 사용하는 특징을 갖고 있다.
(이 weighted matrix 는 embedding matrix라고도 불리우며, 주요 특징으로는 (vocab_size, embedding_dim) 차원으로 이뤄진 학습 가능한 가중치요소만 포함된 매트릭스이고, 통상 bias는 존재하지 않는다.)
여기서 lookup tabele으로만 사용된다는 것이 매우 중요한데 이는 아래의 예시를 통해 그 의미를 파악할 수 있다.
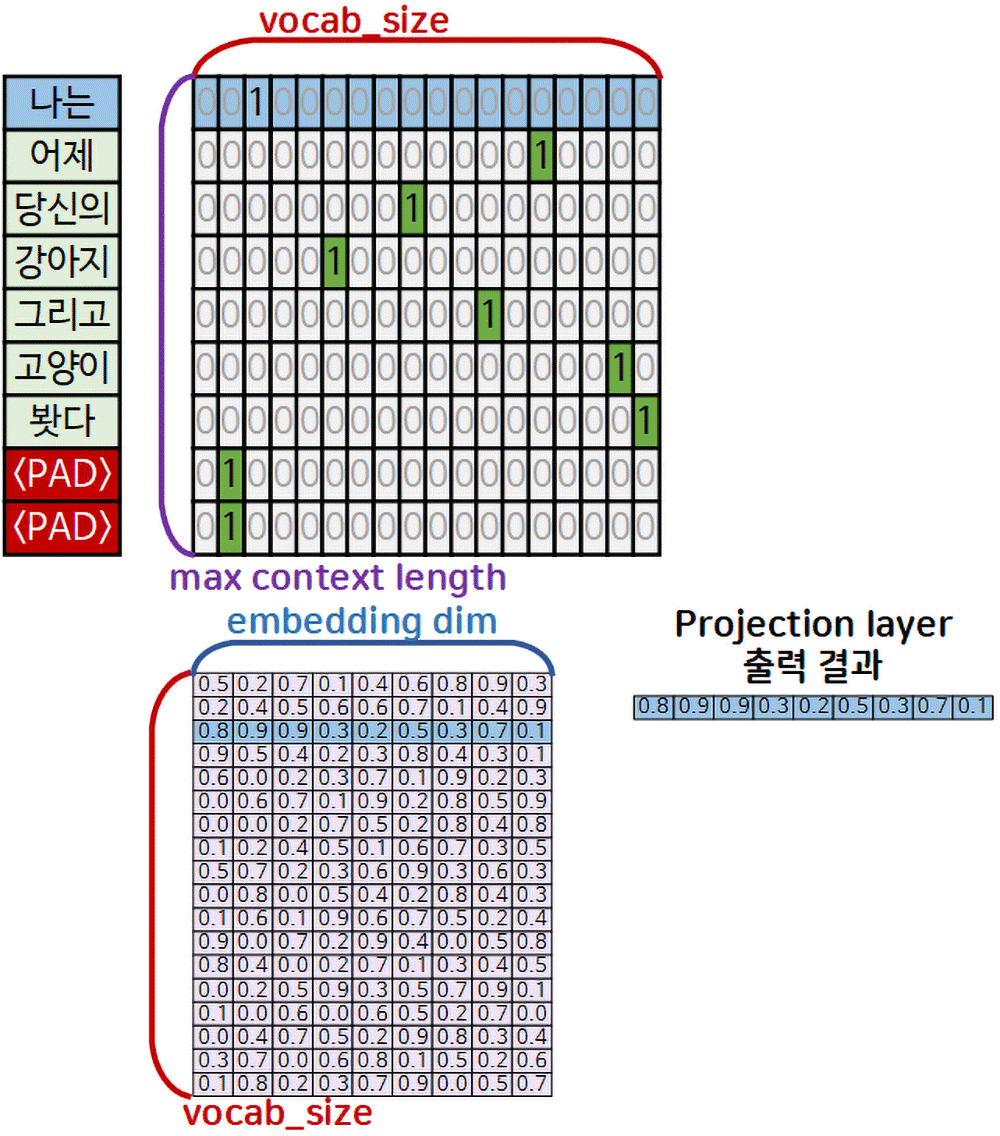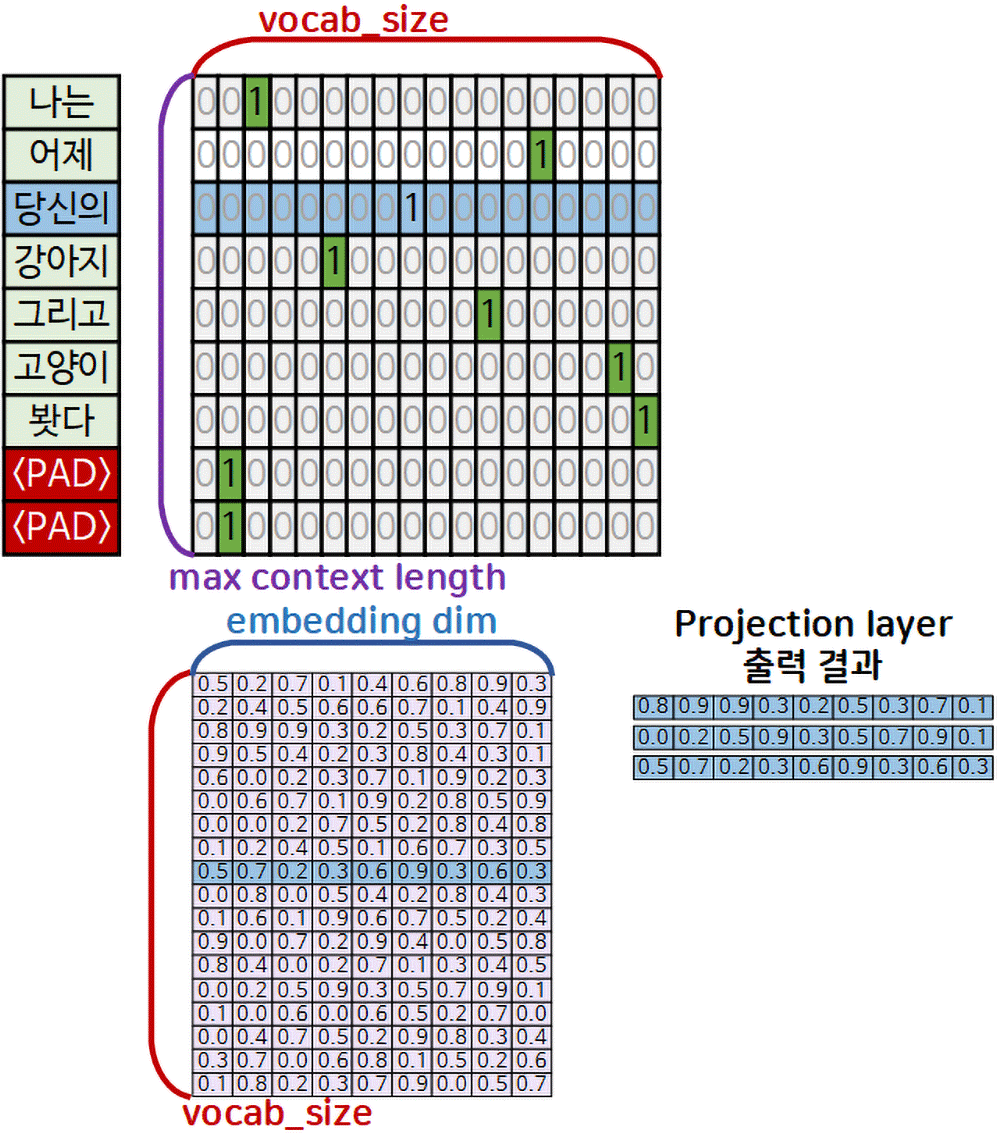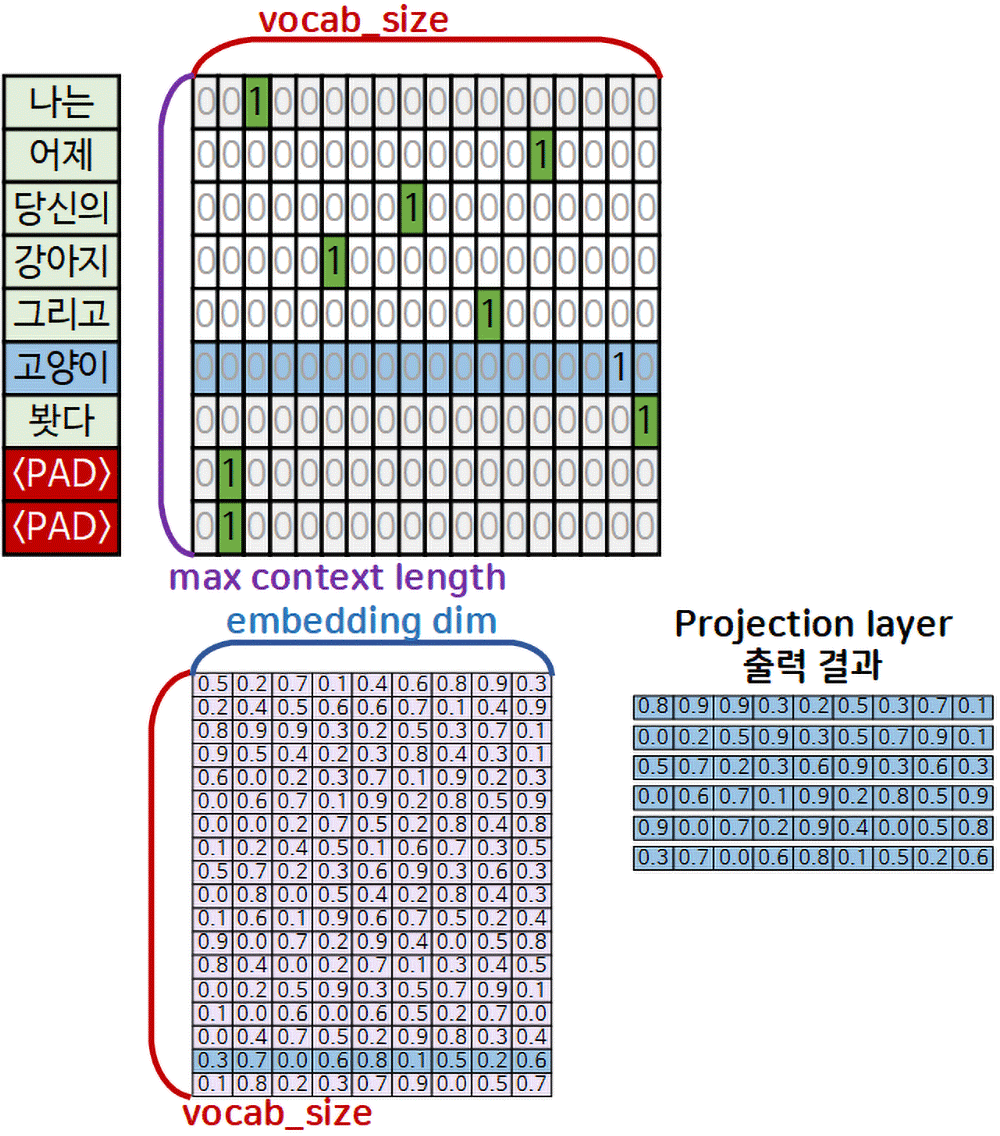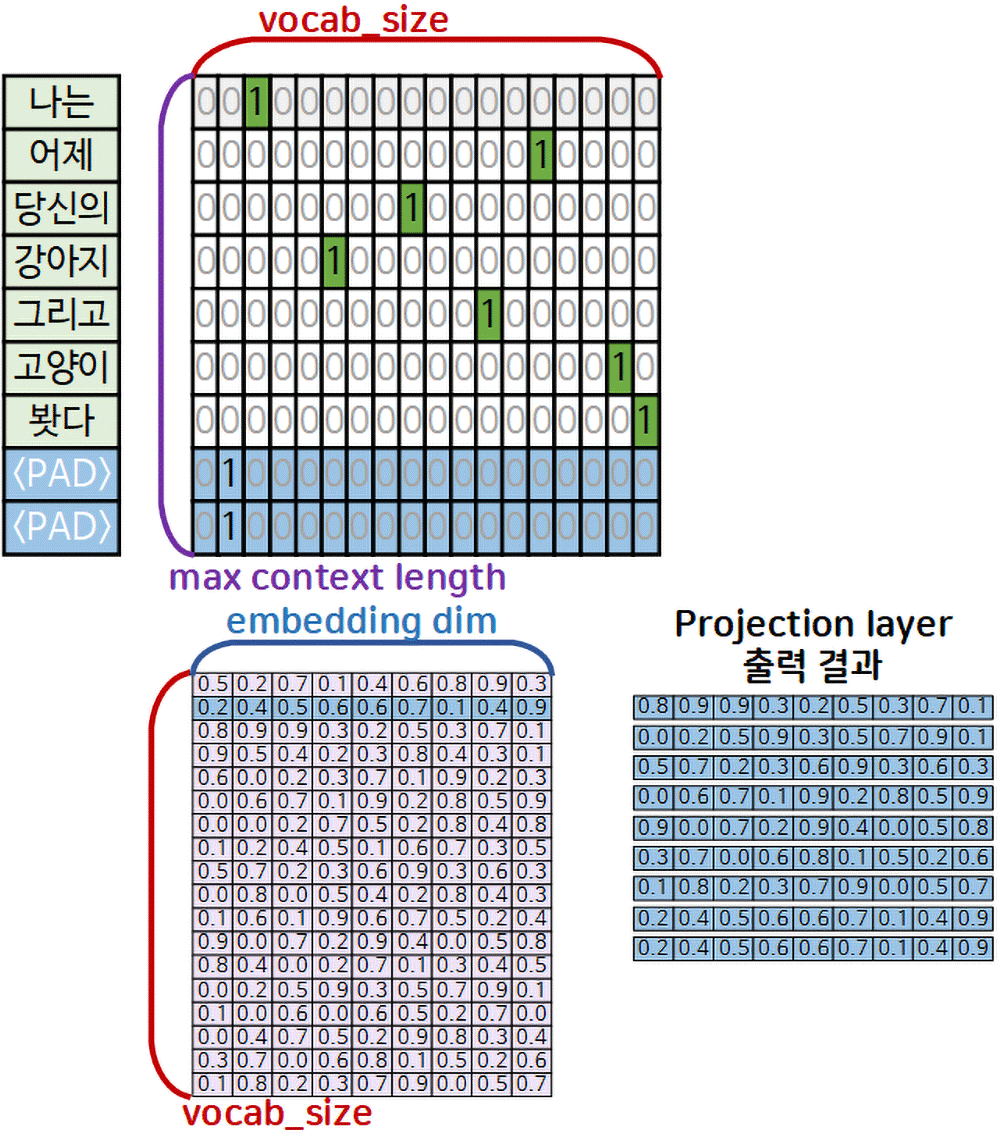
위 gif처럼 One-hot encoding 코딩 결과물에서 각 단어와 매칭되는 원소 = 유효 값(significant value)은 1이 차 있을 것이고,
Projection layer에서는 해당 유효 값을 embedding matrix 에서 row idx로 활용하여 해당 열 데이터(lookup)을 가져와 붙이는 방식으로
lookup table결과물로
차원이 축소된 밀집 벡터(Dense vector)로 변환하는 것이다.
물론 embedding matrix는 학습 가능한 가중치요소이기에 이 Projection layer는 학습이 진행될 수록 원소값이 더 적합한 값으로 변화할 것이다.
그렇다, embedding matrix는 매칭된 단어가 해당 문서와 문서가 포함된 데이터셋에서 어떤 의미적 정보를 갖고있는지 표현하는 Feature Map이라 해석할 수 있다.
따라서 Projection layer가 포함된 언어모델은 학습이 진행될 수록 embedding matrix의 표현력이 점점 정확해지는 쪽으로 업데이트 된다.
이렇게 Projection layer는 단순히 차원을 축소한 밀집 벡터(Dense vector)만 만드는 것이 아니라 단어의 의미적 유사성을 벡터공간에 투영하기에 이 내용을 함축하여 표현할 수 있는 더욱 적합한 단어
Embedding layer라 부르는 것이 더 일반적이다.
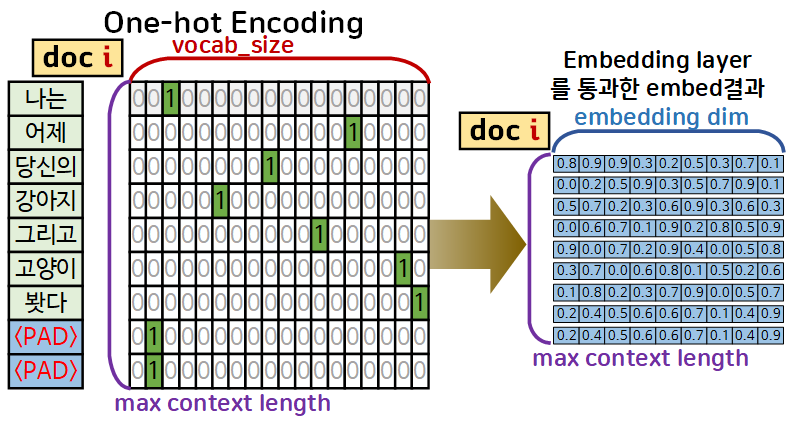
따라서 결과물도 요약해서 보자면 One-hot encoding 대비 차원도 축소되고, 차원 내 벡터도 단어의 의미적 유사성 정보가 같이 포함되기에
언어모델을 설계할 때는 통상적으로 맨 앞단 레이어는 Embedding layer을 포함하여 모델을 설계한다.
2. Embedding 레이어
2.1 Embedding 레이어 실습 준비
실습 주제는 자연어 데이터셋을 최종적으로
1) One-hot encoding
2) TF-IDF
3) Embedding layer 적용
3가지 방식으로 자연어 처리 작업을 설계한 뒤
각각의 경우에 따른 성능을 비교평가 하고자 한다.
자연어 데이터셋
이제 위 파일을 다운로드 하자
import urllib.request
# 다운로드할 파일의 URL
url = "https://raw.githubusercontent.com/e9t/nsmc/master/ratings.txt"
# 저장할 파일 경로
txt_file = "ratings.txt"
# 파일 다운로드
urllib.request.urlretrieve(url, txt_file)다운로드 한 뒤에는 DataFrame
형식으로 파일을 열람한다.
import numpy as np
import pandas as pd
import matplotlib.pyplot as pltraw_data = pd.read_table(txt_file)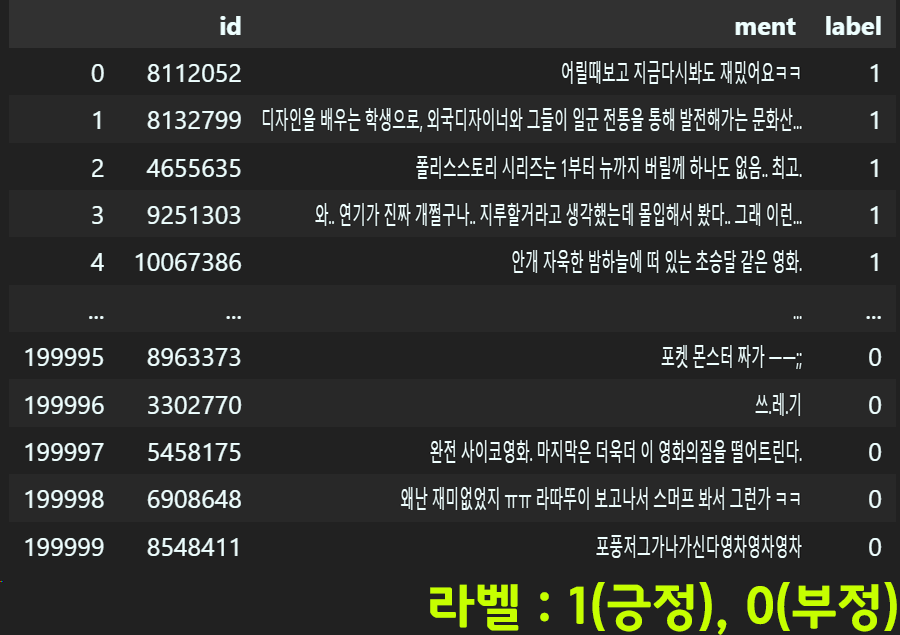
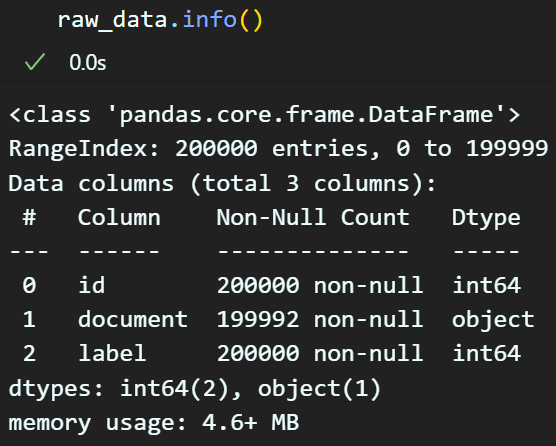
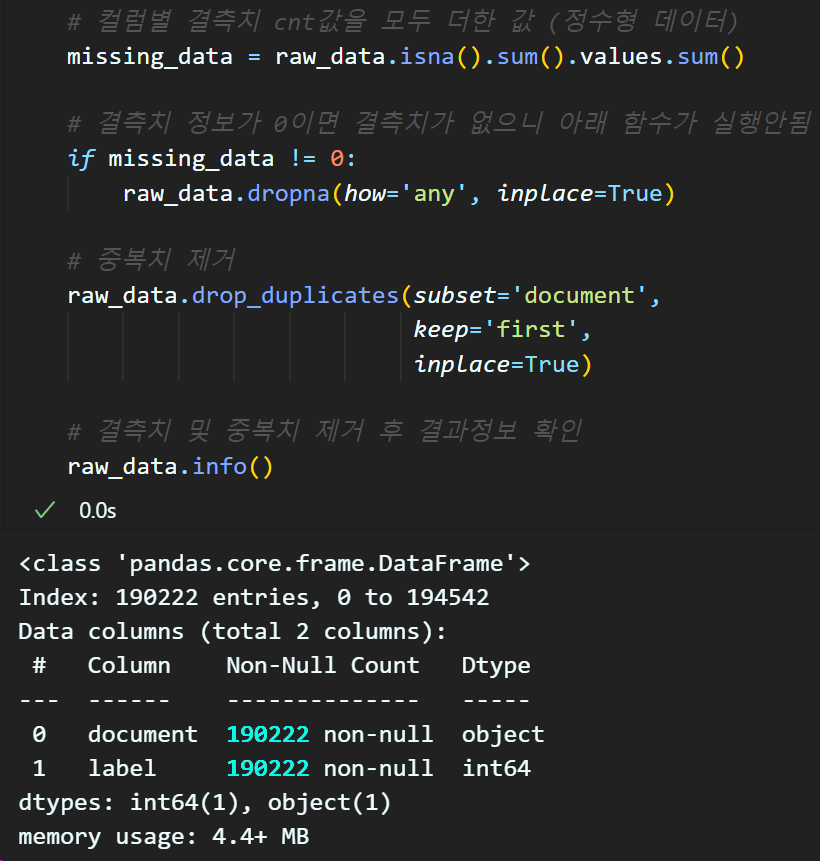
데이터 전처리 - 결측치& 중복치 제거
# 컬럼별 결측치 cnt값을 모두 더한 값 (정수형 데이터)
missing_data = raw_data.isna().sum().values.sum()
# 결측치 정보가 0이면 결측치가 없으니 아래 함수가 실행안됨
if missing_data != 0:
raw_data.dropna(how='any', inplace=True)
# 중복치 제거
raw_data.drop_duplicates(subset='document',
keep='first',
inplace=True)
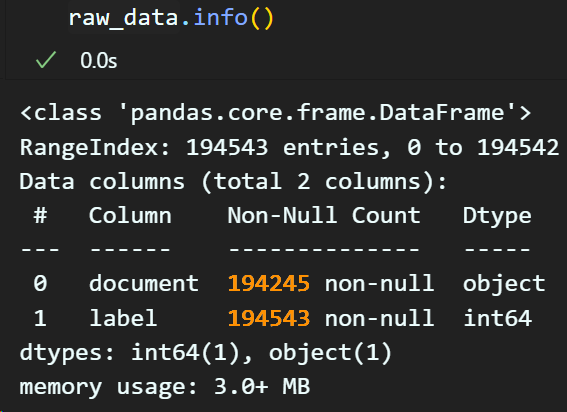
# 결측치 및 중복치 제거 후 결과정보 확인
raw_data.info()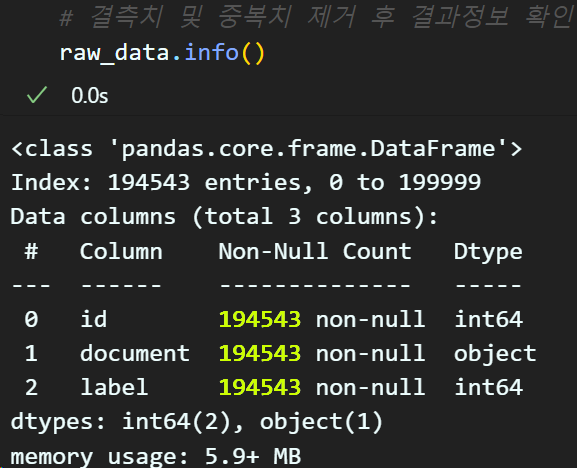
데이터 전처리 - 정규표현식
import re
# 사용할 정규표현식 객체
p1 = re.compile(r'[^ㄱ-ㅎ가-힣a-zA-Z0-9\s]') # 한글, 영어(소문자, 대문자), 숫자
p2 = re.compile(r'[ㄱ-ㅎㅏ-ㅣ]+') # 자음 또는 모음만 있는 한글 문자열
p3 = re.compile(r'\n|\s+') # 개행문자 + 하나 이상의 공백문자
p4 = re.compile(r'([\W_]{2,})') # 이상 반복되는 모든 종류의 특수문자
def regex_sub(origin_sent):
clean_text = p1.sub(repl=" ", string=origin_sent)
clean_text = p2.sub(repl="", string=clean_text)
clean_text = p3.sub(" ", clean_text)
clean_text = p4.sub(repl="", string=clean_text)
return clean_textraw_data['document'] = raw_data['document'].apply(regex_sub)영화 리뷰 데이터는 일상어 기반으로 댓글이 달린 정보를 크롤링 한 것이기에 정규표현식을 종류별로 적용하여 Cleaning을 수행했다.
데이터 전처리 - 한글 띄어쓰기 적용

리뷰 데이터를 몇개 훑어보면.. 역시 일상어를 댓글로 단 정보다 보니 띄어쓰기도 많이 심각한 상황이다. 이걸 처리를 해줘야 하는데
https://github.com/haven-jeon/PyKoSpacing

이 띄어쓰기를 처리해주는 라이브러리가 PyKoSpacing과
https://github.com/ssut/py-hanspell
py-hanspell 두가지 종류가 있다.
둘다 한글 맞춤법을 검사해서 적합한 띄어쓰기를 제공하는것인데.. 요약을 하자면
1) PyKoSpacing : 사용 가능이나 Tensorflow(GPU) 라이브러리가 설치되어야함, Pytorch상에서는 동작 안하는 라이브러리
2) py-hanspell : 영업종료 (4년간 유지보수가 진행되지 않았고 24년을 기점으로 구동이 안됨)
그래서 답안은 PyKoSpacing뿐인데 기반 라이브러리가 Tensorflow(GPU)다 보니 윈도우 환경에서는 구동이 안된다.
이러니 tensorflow 점유율이 나락을가지
PyKoSpacing을 사용하려면 2.16이상의 Tensorflow(GPU)를 설치해야한다.
결국 WSL이나 리눅스, colob 환경에서 구동을 해야하는데...
어찌저찌 설치하긴 했지만(필자는 WSL을 사용..)
from pykospacing import Spacing
spacing = Spacing()
def kr_spaceing(origin_sent):
kospacing_sent = spacing(origin_sent)
return kospacing_sentfrom tqdm import tqdm
tqdm.pandas() # tqdm을 pandas에 통합
# 띄어쓰기 적용 진행상황을 체크하려함
# 띄어쓰기 적용하면서 진행상황 확인
raw_data['document'] = raw_data['document'].progress_apply(kr_spaceing)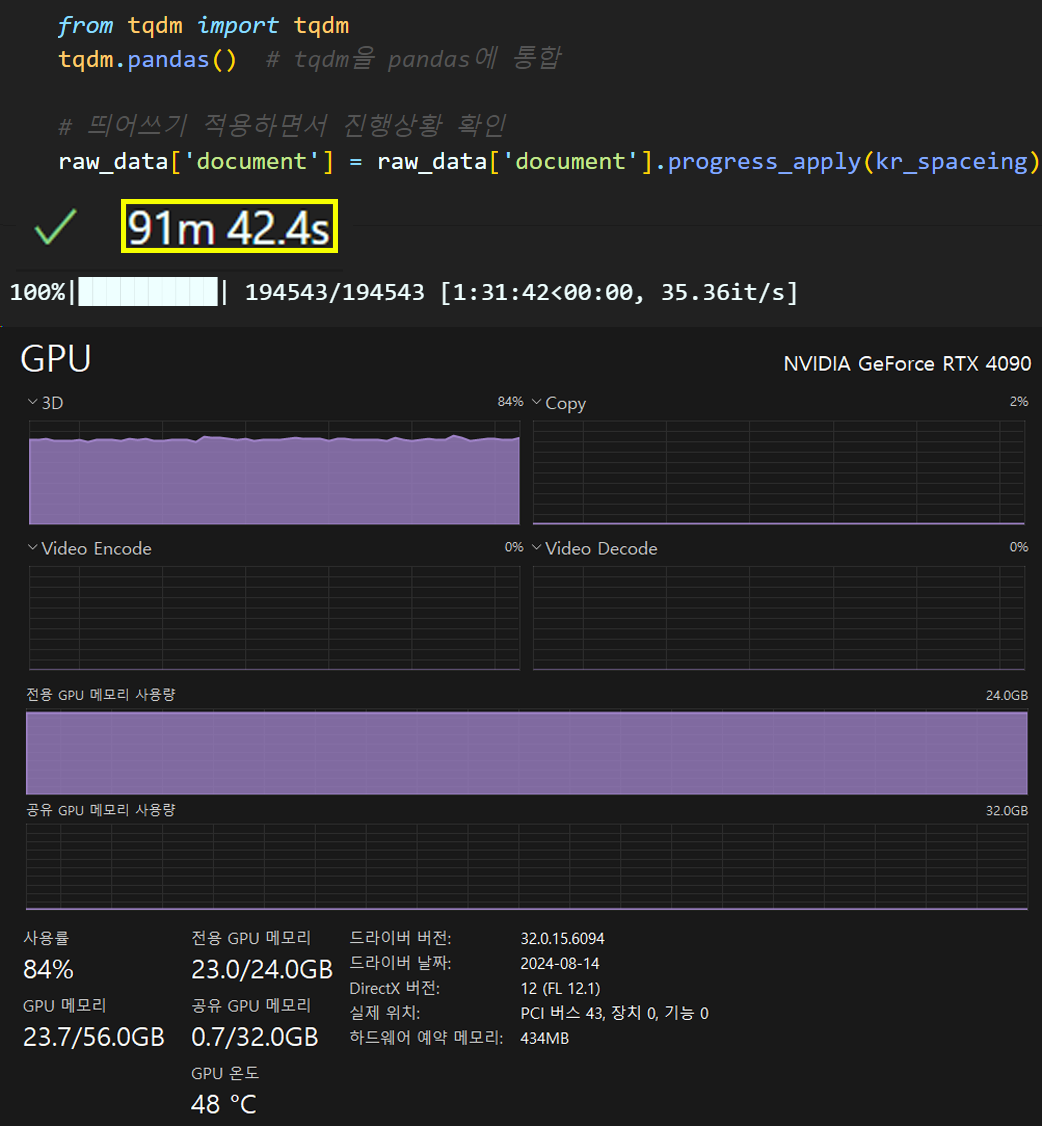
이게 띄어쓰기를 수행하는데 처리속도도 꽤 걸리고 (데이터가 20만개에 육박하긴 하지만 1개의 문장을 처리하는데 평균 36초..)
또 GPU VRAM도 엄청 많이 잡아먹는 딥러닝 기반의 모델로 띄어쓰기 교정작업을 수행하는 라이브러리다.
따라서 데이터 전처리가 된 파일을 D_ratings.csv로 저장하여 구글 드라이브에 업로드 했다.
이 작업을 매번 수행하는것은 굉장히 비효율 적이다.
D_ratings.csv 저장하기
# 인덱스를 리셋하기(인덱스 재 조정)
raw_data.reset_index(drop=True)
# 필요한 정보만 담긴 컬럼만 줄여서 저장하기
raw_data.loc[:, ['document', 'label']].to_csv('D_ratings.csv', index=False)https://drive.google.com/file/d/1NbkjKiwUcSFdovdh-4zVMX3v_fzfQ4xT/view?usp=drive_link
import gdown
# 구글 드라이브에 업로드된 train.csv 파일 ID
file_id = '1NbkjKiwUcSFdovdh-4zVMX3v_fzfQ4xT'
# 파일 다운로드 링크 생성
url = f'https://drive.google.com/uc?id={file_id}'
# 'train.csv'파일을 다운로드한 뒤 저장할 경로 지정(파일명도 함께)
csv_file = './data/D_ratings.csv'
# 파일 다운로드
gdown.download(url, csv_file, quiet=True)raw_data = pd.read_csv(csv_file)
데이터 전처리를 완수하기 위해 WSL을 구동하고 WSL에서 전처리 한 파일을 구글 드라이버에 올려서 이걸 다운로드를 받을 줄은 몰랐는데...

참고로 띄어쓰기 교정을 수행한 데이터를 다시 확인해보면 결측치가 상당히 많이 존재한다
그래서 결측치 및 중복치 제거 함수를 다시 돌리면
쓸모있는 데이터는 총 19만개로
대략 1만개의 데이터가 깎여나간다...
텍스트 전처리 - 토큰화
# 데이터프레임의 항목을 분리 후 리스트 타입으로 변경
raw_x_data = raw_data['document'].values.tolist()
raw_y_label = raw_data['label'].values.tolist()
from mecab import MeCab #한글 단어 토크나이저
from tqdm import tqdm
#mecab 형태소 분석기 인스턴스화
word_tokenizer = MeCab()
# document 컬럼에 대한 워드 토크나이징 수행
def tokenize(x_data, word_tokenizer):
tokenized_sentences = list()
for sent in tqdm(x_data):
tokenized_sent = word_tokenizer.morphs(sent)
tokenized_sentences.append(tokenized_sent)
return tokenized_sentences이제 이 raw_x_data를 토큰화를 하려고 하는데
이때 꼭 앞에서 수행한 결측치&중복치 제거를 수행했는지 확인해야 한다.
띄어쓰기 교정을 수행한 이후 변경된 데이터에는
깨진 문서 파일이 존재하며,
이 정보가 그대로 토큰화 함수에 인가될 시
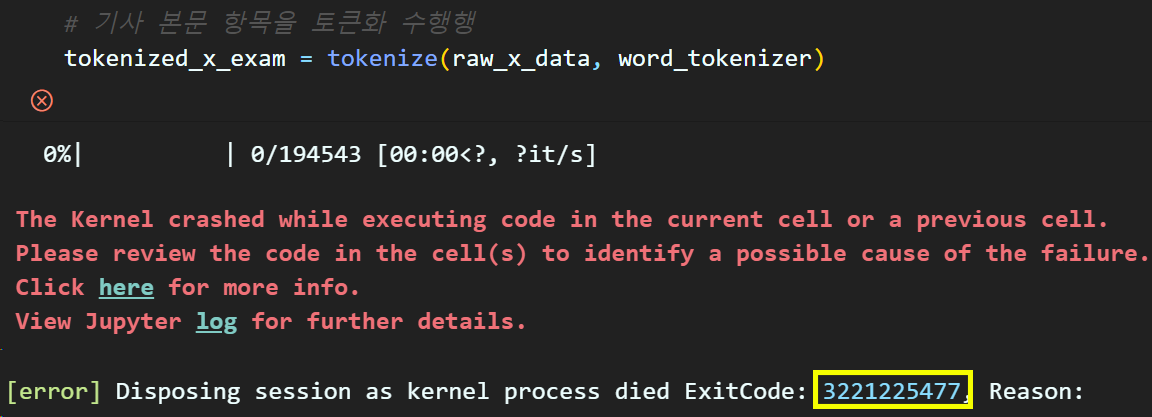
위와 같은 에러 메세지가 발생한다.
참고로 위 에러메세지는 원인을 해결하기 정말 어렵다
(구글에서도 자료를 찾아보면 C언어 기반의 메모리 용량부족 오류만 출력되지 파이썬-판다스 라이브러리 기반 오류리포트는 거의 없음)
이거 해결하는데 한나절 날림
아무튼 뭔가 데이터셋의 문서에 큰 교정작업이 수행되면
언제고 결측치&중복치가 발생할 수 있으니 이 자료를 다시한번 cleaning 해줘야 한다.
불용어 제거
# 구글 드라이브에 업로드된 stopword.txt 파일 ID
file_id = '1-KtRjx2HBVuqP99kN8tZTiND7oRM6DIO'
# 파일 다운로드 링크 생성
url = f'https://drive.google.com/uc?id={file_id}'
# 'stopword.txt'파일을 다운로드한 뒤 저장할 경로 지정(파일명도 함께)
stopword = './data/kr_stopword_list.txt'
# 파일 다운로드
gdown.download(url, stopword, quiet=True)# 불용어 단어장 stopword.txt를 열람 후 리스트 변수화
with open(stopword, 'r', encoding='utf-8') as file:
stopword_list = file.read().splitlines()# 리스트 컴프리핸션을 적용하여 빠르게 불용어를 제거하는 함수
def Fast_remove_stopword(tokenized_data, stopword):
return [[word for word in sent if word not in stopword]
for sent in tokenized_data]# 토큰화 처리한 '기사 본문' 데이터셋의 불용어 제거
r_t_x_exam = Fast_remove_stopword(tokenized_x_exam, stopword_list)
2.2 데이터셋 분리
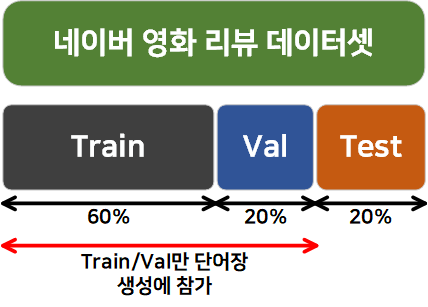
불용어 제거까지 수행하고 챕터를 나눈 이유는 그 다음 단계는 단어장 생성인데
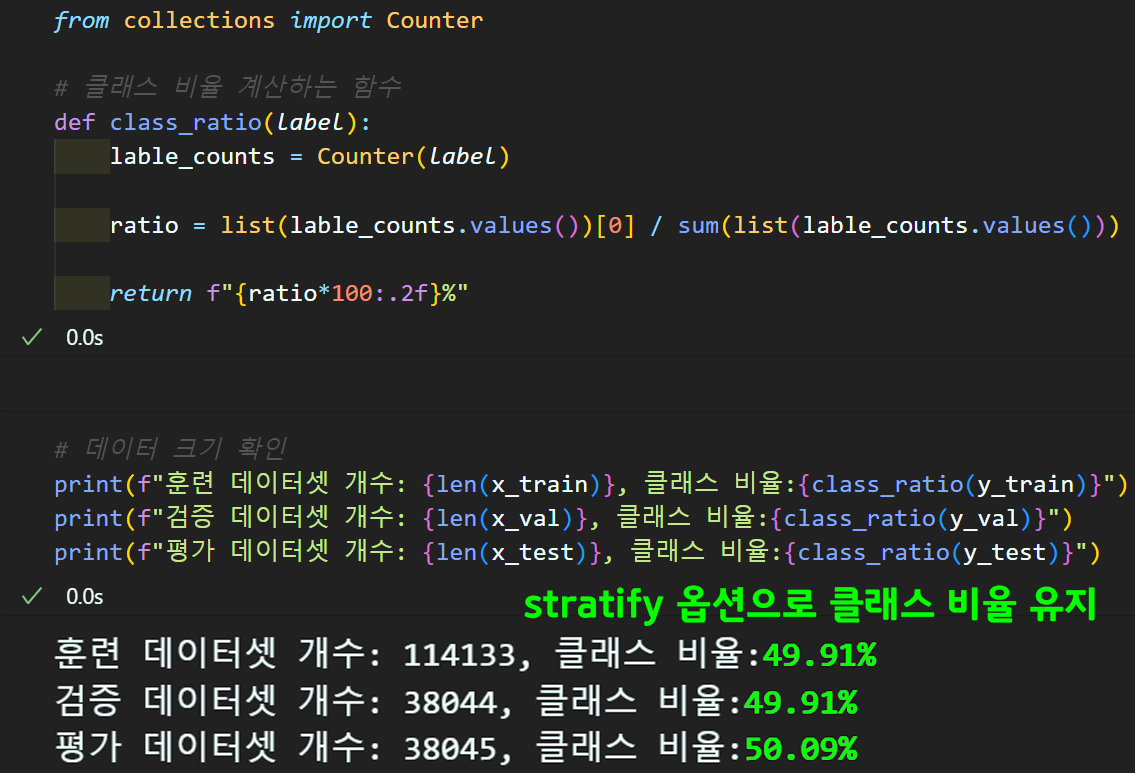
아래와 같이 train / validation / test 집단으로 데이터셋을 분리하고 단어장 생성에는 test 집단은 배제하고자 한다.
from sklearn.model_selection import train_test_split
# 훈련데이터셋(60%) 그 외 데이터셋(40)로 나누는 작업 수행
# random_state -> 데이터셋을 내누는데 '재현성' 유지를 위해 넣음 -> 안넣어도 됨
# stratify -> Y_label의 클래스 비율을 유지하면서 데이터 나눌때 옵션
x_train, x_etc, y_train, y_etc = train_test_split(
r_t_x_exam, raw_y_label, test_size=0.4, random_state=42, stratify=raw_y_label
)
# 그 외 데이터셋을 반반으로 Val, Test로 나눔
x_val, x_test, y_val, y_test = train_test_split(
x_etc, y_etc, test_size=0.5, random_state=42, stratify=y_etc
)데이터셋을 분리하는 함수로는 train_test_split를 사용했으며
분리하고자 하는 원시 데이터 : x_data, y_label
를 입력하면 x_data_1, x_data_2
y_lable_1, y_label_2
총 4개의 분리 비율 (test_size)를 유지하면서 데이터셋을 분리해준다.
이때 stratify 옵션에 y_label을 입력하면
y_label의 클래스 비율을 그대로 유지하면서 데이터셋을 분리해준다.
단어장 만들기 - 준비
from collections import Counter
word_list = []
# train항목을 워드 리스트에 입력
for sent in x_train:
for word in sent:
word_list.append(word)
# val항목을 워드 리스트에 입력
for sent in x_val:
for word in sent:
word_list.append(word)
# 단어와 해당 단어의 출몰 빈도를 함께 저장하는
# Counter 타입의 변수 생성
word_counts = Counter(word_list)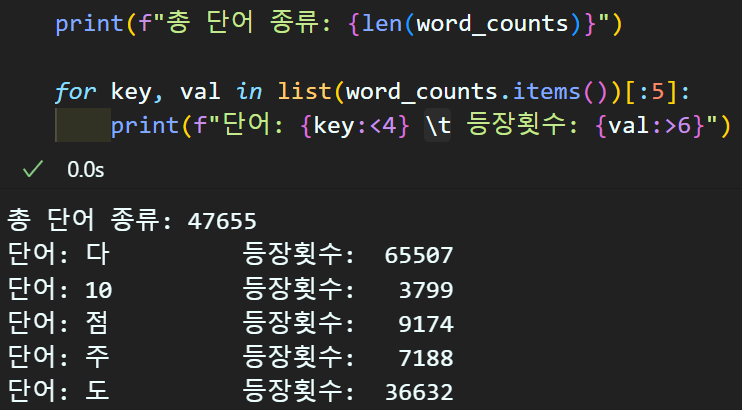
희소 단어 정리
total_vocab_cnt = len(word_counts) #전체 단어 종류
rare_vocab_cnt = 0 #등장빈도수가 적은 단어는 몇 종?
total_freq, rare_freq = 0, 0
# 희소단어를 결정하는 하이퍼 파라미터
threshold = 3
for key, value in word_counts.items():
# 전체 단어의 등장빈도를 모두 가산하여 더함
total_freq = total_freq + value
if (value < threshold):
rare_vocab_cnt += 1
rare_freq += value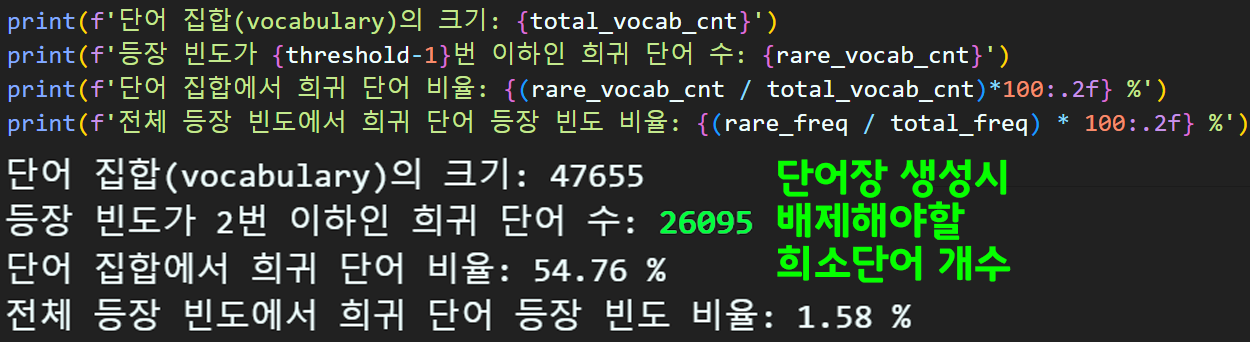
정렬된 단어장 만들기 + 스페셜 토큰 추가
#등장 빈도가 높은 단어 순으로 정렬하기
vocab = sorted(word_counts, key=word_counts.get, reverse=True)
#등장 빈도가 높은 단어만 인덱싱 하기
vocab_size = total_vocab_cnt - rare_vocab_cnt
vocab = vocab[:vocab_size]# 특수단어를 포함시켜 {단어:인덱스} 딕셔너리 생성하기
# 포함시킬 특수단어는 `<PAD>`, `<UNK>`으로
# <PAD> : 0, <UNK> : 1 순으로 특수단어는 맨 앞에 위치하기
word_to_idx = {'<PAD>' : 0, '<UNK>' : 1}
for idx, word in enumerate(vocab):
word_to_idx[word] = idx + 2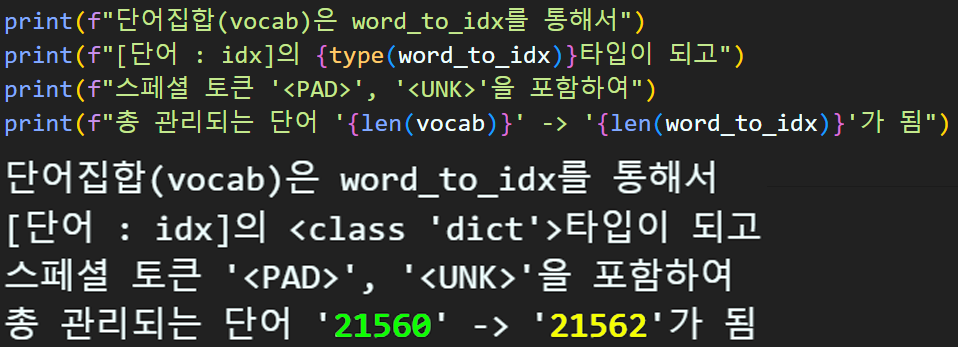
2.3 대조군 : TF-IDF 인코딩
DTM 매트릭스 생성
# 단어 : 빈도가 함께 포함되는 DTM 생성하기
def create_dtm(x_data, word_to_idx):
# row = x_data의 개수(문서 개수), col = 생성한 단어장 내 단어 개수
dtm = np.zeros((len(x_data), len(word_to_idx)), dtype=int)
for i, sent in enumerate(x_data):
for word in sent:
#word_to_idx에서 단어를 찾은 뒤 해당 단어의 인덱스(숫자)를 입력
try:
word_idx = word_to_idx[word]
# word_to_idx 딕셔너리에 없는 키(단어)등장시 UNK로 인덱싱
except KeyError:
word_idx = word_to_idx['<UNK>']
#(문서 인덱스, 찾은 단어 인덱스) 항목에 +1 가산
dtm[i, word_idx] +=1
return dtm# 설계된 DTM함수를 기반으로 train, val, test의 인코딩
dtm_train = create_dtm(x_train, word_to_idx)
dtm_val = create_dtm(x_val, word_to_idx)
dtm_test = create_dtm(x_test, word_to_idx)TF-IDF 매트릭스 생성
def create_tf_idf(dtm):
# TF 계산 : 문서(d)에서 단어(t)가 등장횟수 / 문서(d)에서 모든 단어 개수
# keepdims=True는 축 별로 더한 sum의 결과 차원정보 유지
row_sums = dtm.sum(axis=1, keepdims=True)
# row_sums, 분모가 0이 되는 경우가 있음 -> 이때 NaN이 발생하니
# 이를 방지하기 위한 코드로 개선하자.
tf = np.divide(dtm, np.where(row_sums == 0, 1, row_sums))
# 문서의 총 개수
num_docs = dtm.shape[0] #row열의 개수
# IDF 계산 : log(총 문서 개수 / 단어(t)를 포함하는 문서(d)의 개수)
df = np.sum(dtm > 0, axis=0) #단어 별 문서 등장 횟수
# 기존 수식의 분자, 분모, 그리고 총 결과값에 +1을 더해서
# 안정적인 idf를 산출 (smoothing)
idf = np.log((num_docs + 1) / (df + 1)) + 1
tf_idf = tf * idf
return tf_idf# 설계된 TF-IDF함수를 기반으로 train, val, test의 인코딩
tfidf_train = create_tf_idf(dtm_train)
tfidf_val = create_tf_idf(dtm_val)
tfidf_test = create_tf_idf(dtm_test)TF-IDF 매트릭스(인코딩)을 수행할 때에는 NaN값이 발생하는지 확인하는 작업과 이에 대한 예외처리 구문을 넣어줘야 한다.
# NaN 값이 있는지 확인하는 함수
def check_nan(matrix, name):
if np.isnan(matrix).any():
print(f"{name} 매트릭스에 NaN 값이 있습니다.")
else:
print(f"{name} 매트릭스에 NaN 값이 없습니다.")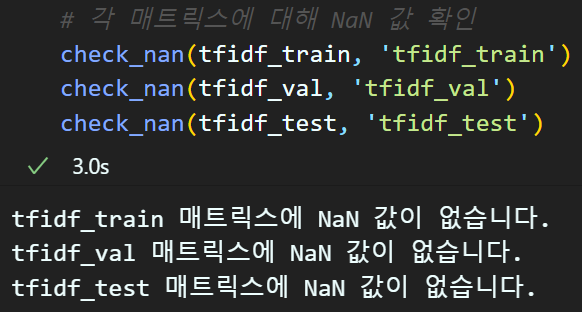

2.4 실험군 : 정수(원핫)인코딩
정수인코딩
# 단어를 정수 인덱싱 규칙으로 정수 인덱싱 수행하기
def text_to_sequences(tokenized_data, word_to_idx):
encoded_data = [] #리턴해야할 정수 인코딩 결과값
for sent in tokenized_data:
idx_sequence = [] #단어장 리스트에서 idx를 찾아서 여기에 입력
for word in sent:
try: #word_to_idx에서 단어를 찾은 뒤 해당 단어의 인덱스(숫자)를 입력
idx_sequence.append(word_to_idx[word])
except KeyError: # word_to_idx 딕셔너리에 없는 키(단어)등장시 UNK로 인덱싱
idx_sequence.append(word_to_idx['<UNK>'])
#문장 내 단어를 모두 정수로 변환한 후에 이를 리턴값(리스트)에 입력
encoded_data.append(idx_sequence)
return encoded_data# 데이터셋의 정수 인코딩 수행
e_x_train = text_to_sequences(x_train, word_to_idx)
e_x_val = text_to_sequences(x_val, word_to_idx)
e_x_test = text_to_sequences(x_test, word_to_idx)정수인코딩이 잘 되었는지는 아래의 코드로 확인한다.
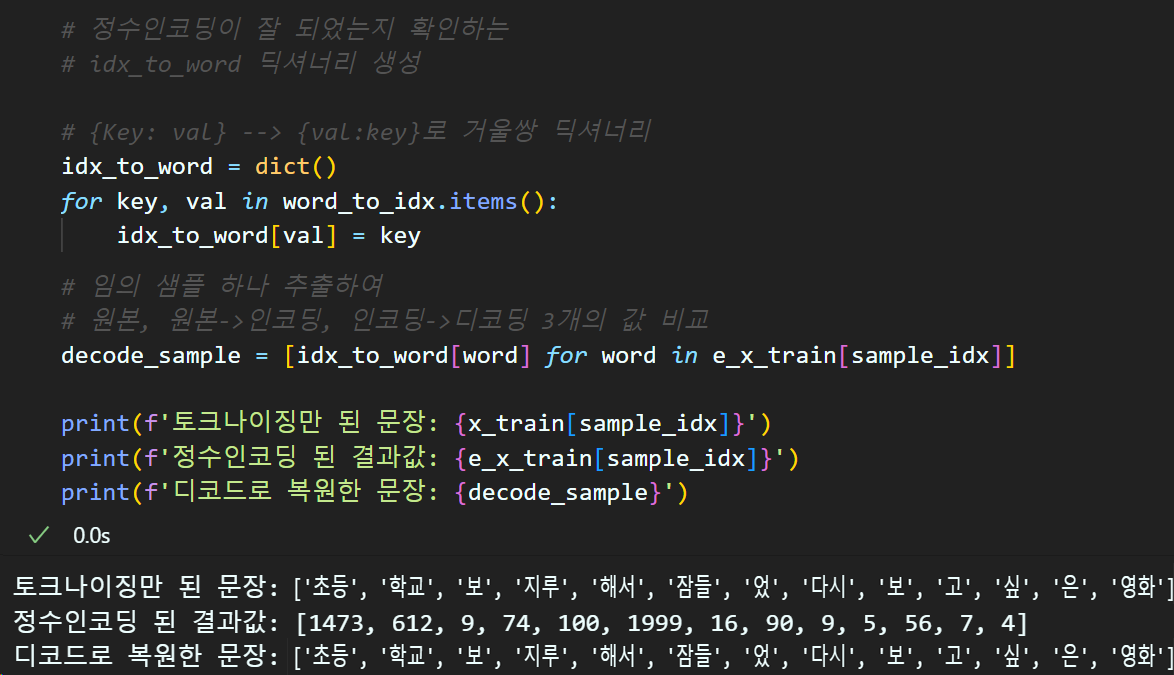
문장 패딩
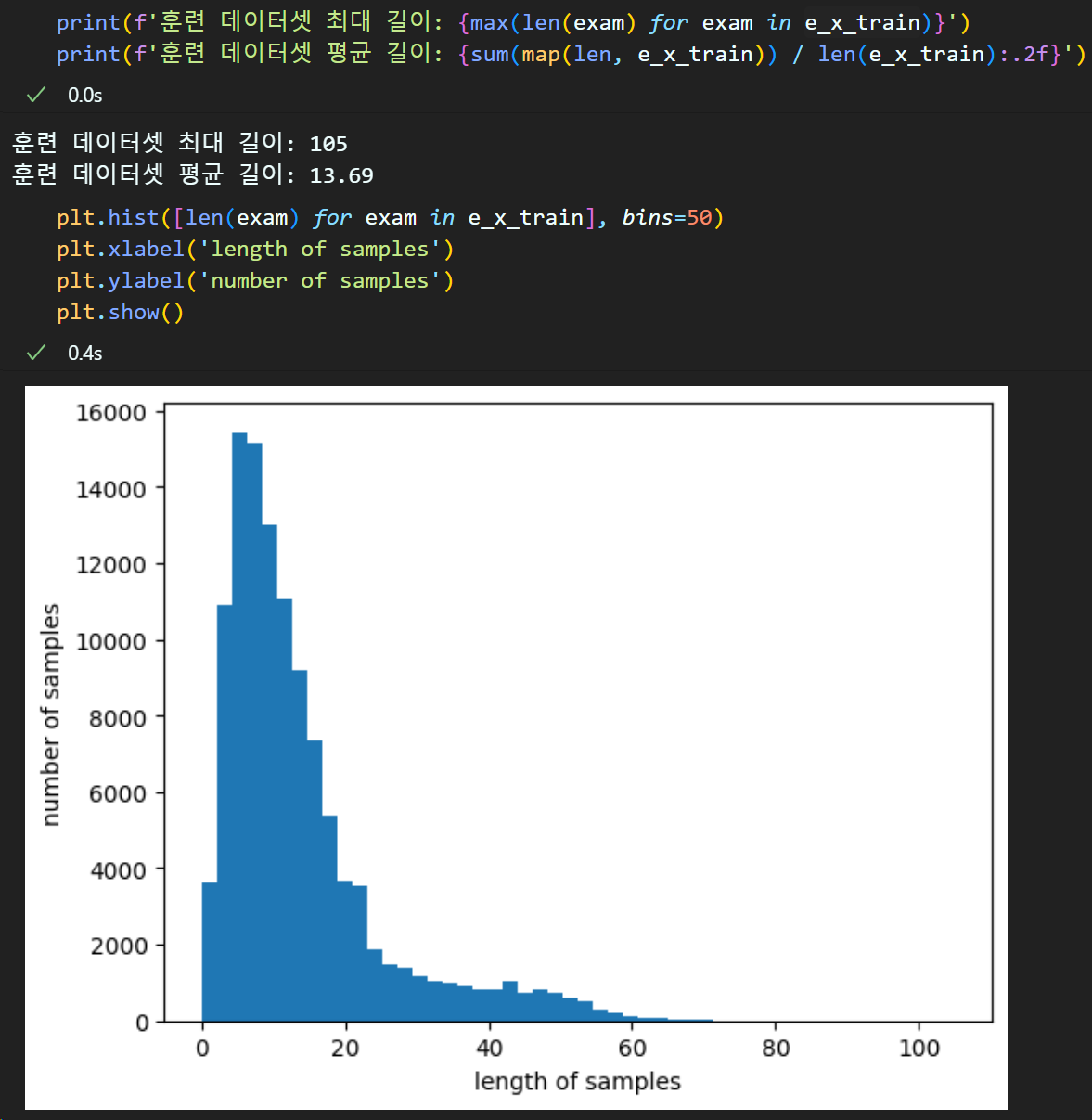
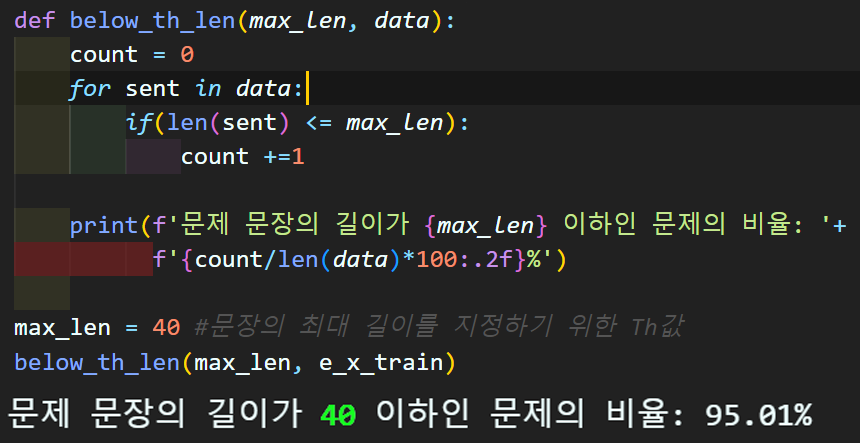
max_len = 40 #문장의 최대 길이를 지정하기 위한 Th값
# x_data 항목을 문장패딩하기 위한 코드
def pad_seq_x(x_data, max_len):
features = np.zeros((len(x_data), max_len), dtype=int)
for idx, sent in enumerate(x_data):
if len(sent) != 0: #예외처리구문
features[idx, :len(sent)] = np.array(sent)[:max_len]
return features# 문장패딩 처리한 x_data (인코딩 완료)
VOCAB_SIZE = len(word_to_idx) #단어장 길이는 꼭 기억하자
padded_x_train = pad_seq_x(e_x_train, max_len)
padded_x_val = pad_seq_x(e_x_val, max_len)
padded_x_test = pad_seq_x(e_x_test, max_len)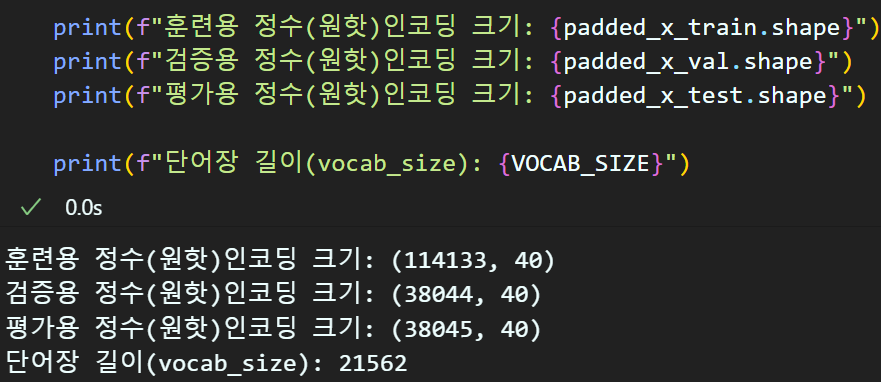
문장패딩까지 완료된 정수 인코딩 결과값은 궂이
One-Hot encoding은 안해도 되긴 하지만
나중을 위해 vocab_size은 저장해두도록 한다.
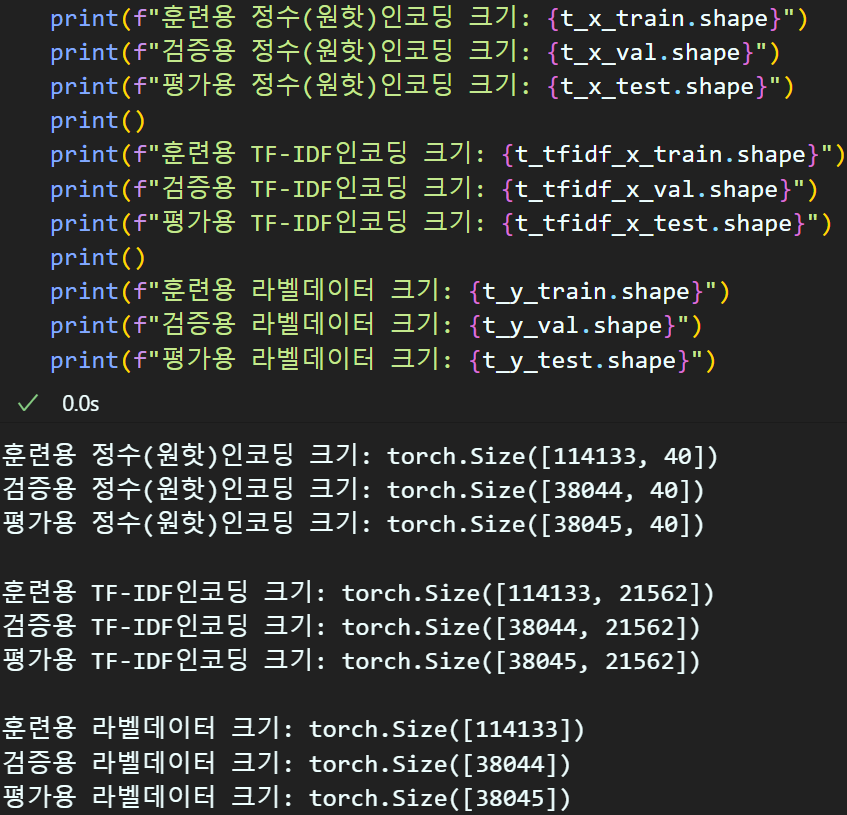
2.5 텐서 자료형 생성
TF-IDF 인코딩으로 처리된 x_data와 (대조군)
Integar 인코딩 처리된 x_data (실험군)
두가지를 준비했다
실험군은 Tensor 자료형 변환을 수행하면서
One-Hot Encoding처리를 진행하도록 하겠다.
import torch
import torch.nn.functional as F# 정수인코딩된 x_data에 대하여 텐서자료형 변환 -> 원 핫 인코딩
t_x_train = torch.tensor(padded_x_train, dtype=torch.int64)
t_x_val = torch.tensor(padded_x_val, dtype=torch.int64)
t_x_test = torch.tensor(padded_x_test, dtype=torch.int64)
# 아래 코드가 원-핫 인코딩
#----------여기 코드는 실제로는 수행하지 아니한다--------------#
oh_x_train = F.one_hot(t_x_train, num_classes=VOCAB_SIZE)
oh_x_val = F.one_hot(t_x_val, num_classes=VOCAB_SIZE)
oh_x_test = F.one_hot(t_x_test, num_classes=VOCAB_SIZE)
#----------여기 코드는 실제로는 수행하지 아니한다--------------#
# TF-IDF 인코딩된 x_data의 텐서 자료형 변환환
t_tfidf_x_train = torch.tensor(tfidf_train, dtype=torch.float32)
t_tfidf_x_val = torch.tensor(tfidf_val, dtype=torch.float32)
t_tfidf_x_test = torch.tensor(tfidf_test, dtype=torch.float32)
# Y_label의 클래스 종류가 몇종인지 확인
NUM_CLASS = int(len(set(y_train)))
# Y_label 데이터도 텐서 자료형으로 변환
t_y_train = torch.tensor(y_train, dtype=torch.int64)
t_y_val = torch.tensor(y_val, dtype=torch.int64)
t_y_test = torch.tensor(y_test, dtype=torch.int64)하지만 위 코드를 수행하면 문제가 발생한다.
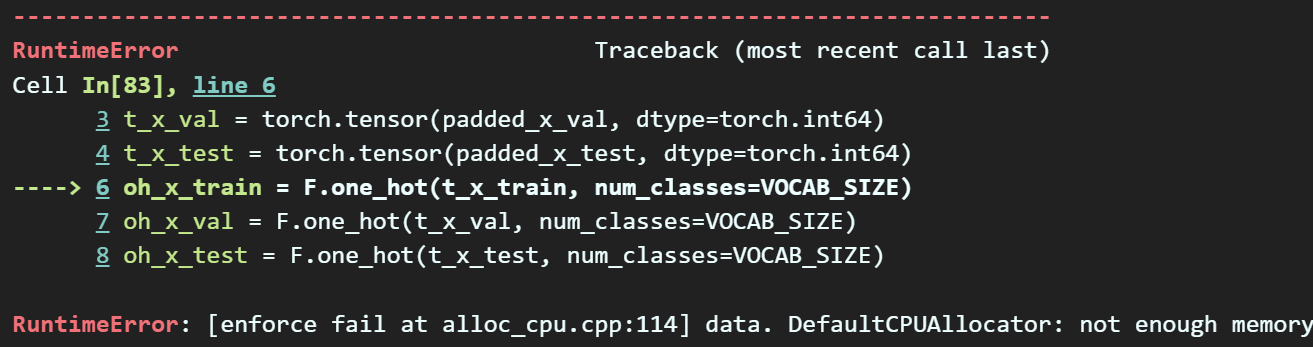
요약하자면 One-Hot encoding을 수행하면 생성되는 저 차원의 희소벡터가
메모리 용량을 너무 많이 잡아먹으니 생성이 불가하다는 메세제가 올라온다
따라서... 정수인코딩 == One-Hot encoding이니
One-Hot encoding은 스킵하는걸로...
데이터셋 + 데이터로더 생성하기
from torch.utils.data import TensorDataset, DataLoader
BS = 256 # Batch_size는 통일
# 1번 모델 정수인코딩에 입력하기 위한 데이터로더 생성
trainset = TensorDataset(t_x_train.to(dtype=torch.float32), t_y_train)
trainloader = DataLoader(trainset, shuffle=True, batch_size=BS)
valset = TensorDataset(t_x_val.to(dtype=torch.float32), t_y_val)
valloader = DataLoader(valset, shuffle=False, batch_size=BS)
testset = TensorDataset(t_x_test.to(dtype=torch.float32), t_y_test)
testloader = DataLoader(testset, shuffle=False, batch_size=BS)
# 2번 모델 TF-IDF 인코딩용 데이터셋 + 데이터로더
TI_trainset = TensorDataset(t_tfidf_x_train, t_y_train)
TI_trainloader = DataLoader(TI_trainset, shuffle=True, batch_size=BS)
TI_valset = TensorDataset(t_tfidf_x_val, t_y_val)
TI_valloader = DataLoader(TI_valset, shuffle=False, batch_size=BS)
TI_testset = TensorDataset(t_tfidf_x_test, t_y_test)
TI_testloader = DataLoader(TI_testset, shuffle=False, batch_size=BS)
# 3번 정수(원핫)인코딩 후 임베딩 모델에 입력할 데이터셋 + 데이터로더
oh_trainset = TensorDataset(t_x_train, t_y_train)
oh_trainloader = DataLoader(oh_trainset, shuffle=True, batch_size=BS)
oh_valset = TensorDataset(t_x_val, t_y_val)
oh_valloader = DataLoader(oh_valset, shuffle=False, batch_size=BS)
oh_testset = TensorDataset(t_x_test, t_y_test)
oh_testloader = DataLoader(oh_testset, shuffle=False, batch_size=BS)2.6 모델 생성
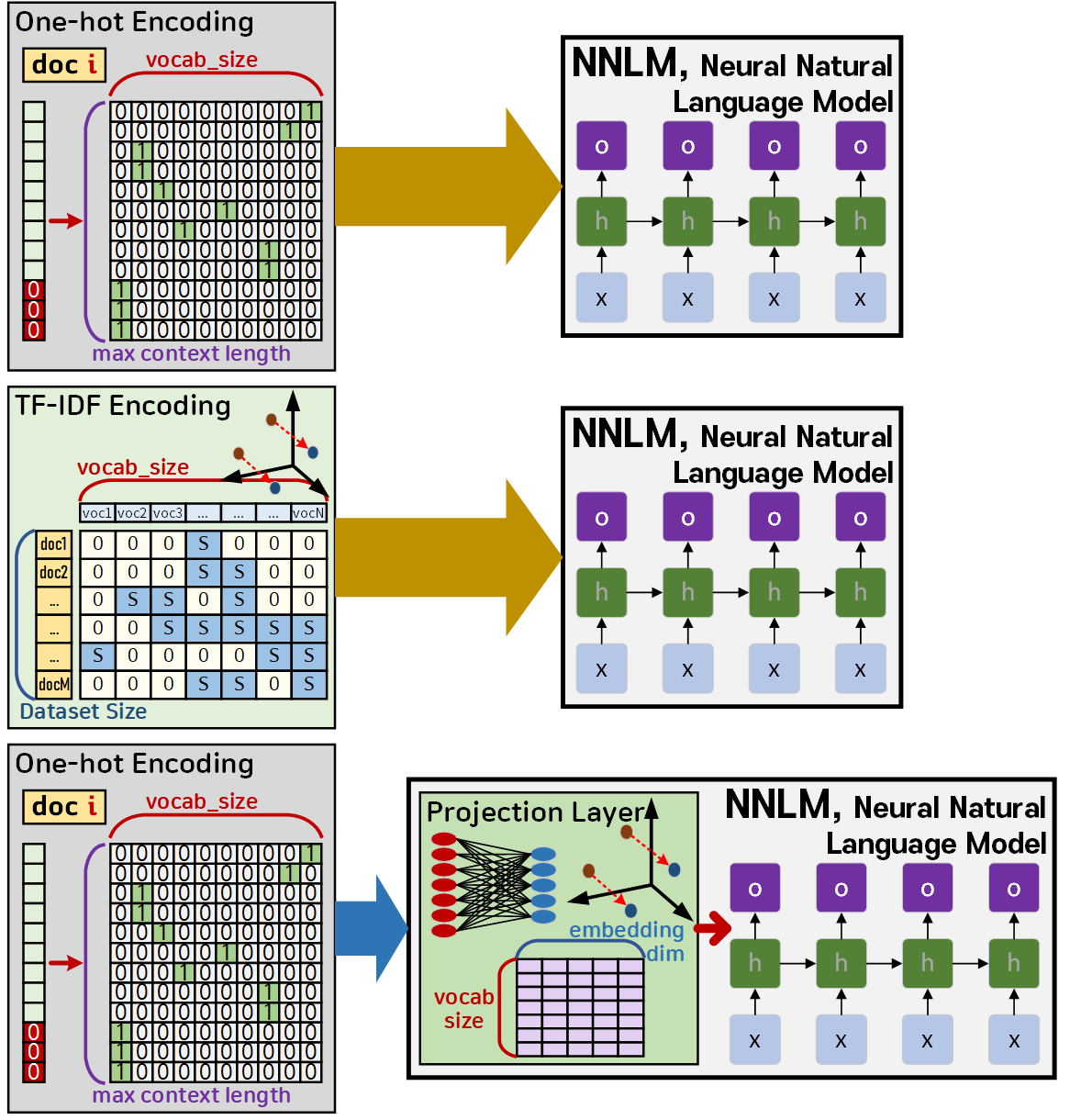
위 사진처럼 3가지 실험을 수행하기 위해
언어모델은 Embedding layer가 있는 버전의 모델과, 없는 버전의 모델 2종을 생성한다.
1번 및 2번에 사용할 Simple Net
import torch.nn as nn
# 간단한 simplenet 생성
# 여기서 input_size는 정수(원핫)인코딩은 context_length
# TF-IDF인코딩은 vocab_size가 입력된다.
class simpleNet(nn.Module):
def __init__(self, input_size, num_label):
super(simpleNet, self).__init__()
self.fcn1 = nn.Linear(input_size, 1400)
self.relu = nn.ReLU()
self.fcn2 = nn.Linear(1400, num_label)
def forward(self, x):
x = self.fcn1(x)
x = self.relu(x)
x = self.fcn2(x)
return x3번 임베딩 레이어를 추가한 SimpleNet
import torch.nn as nn
# 간단한 임베딩-simplenet 생성
# 임베딩은 vocab_size를 입력받아서 embed_dim으로
# 차원축소(밀집벡터)화 한 뒤 이를 LM 레이어로 전송함
# 참고로 임베딩 레이어의 단어간 의미(표현)정보는 뭉게버림
class emb_simpleNet(nn.Module):
def __init__(self, vocab_size, embed_dim, num_label):
super(emb_simpleNet, self).__init__()
self.embed = nn.Embedding(vocab_size, embed_dim)
self.fcn1 = nn.Linear(embed_dim, 1400)
self.relu = nn.ReLU()
self.fcn2 = nn.Linear(1400, num_label)
def forward(self, x):
x = self.embed(x)
# 단어의 유사성 의미정보는 뭉게버린다.
x = torch.mean(x, dim=1)
x = self.fcn1(x)
x = self.relu(x)
x = self.fcn2(x)
return x여기서 설계한 Embedding layer는 뒤에 붙어있는 언어모델이 언어모델에 특화된 네트워크가 아니라
정말 단순한 FCN기반의 모델이기에
단어의 Feature정보를 torch.mean 함수로 평준화 시켜서 다음 레이어의 입력 정보로 활용한다.
이렇게 극단적으로 정보가 유실되었는데도
TF-IDF 인코딩이랑 비교했을 때 성능이 비슷하게 나오면 그것만으로도 성공적이라 볼 수 있다.
2.6 하이퍼 파라미터 + 훈련
모델 설계 파라미터 정의
CONTEXT_LENGTH = max_len # 40
VOCAB_SIZE = len(word_to_idx) # 21562
EMB_DIM = 100 #유저가 정하는 하이퍼 파라미터
NUM_CLASS = int(len(set(y_train))) # 클래스 종류 : 2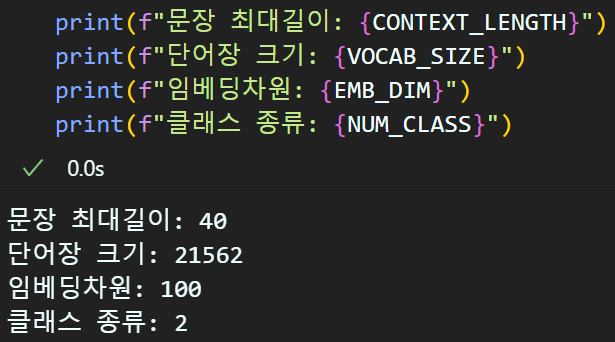
모델 객체화 + GPU로 전환
# 정수(원핫)인코딩용 언어모델
model_1 = simpleNet(CONTEXT_LENGTH, NUM_CLASS)
# TF-IDF 인코딩용 언어모델
model_2 = simpleNet(VOCAB_SIZE, NUM_CLASS)
# 임베딩 인코딩 언어모델
model_3 = emb_simpleNet(VOCAB_SIZE, EMB_DIM, NUM_CLASS)
# GPU사용 가능 유/무 확인
device = torch.device("cuda" if torch.cuda.is_available() else 'cpu')
model_1.to(device)
model_2.to(device)
model_3.to(device)
print()손실함수 + 옵티마이저 설정
import torch.optim as optim
# 로스함수 및 옵티마이저 설계
criterion = nn.CrossEntropyLoss()
LR = 0.001 # 러닝레이트는 통일
optimizer_1 = optim.Adam(model_1.parameters(), lr=LR)
optimizer_2 = optim.Adam(model_2.parameters(), lr=LR)
optimizer_3 = optim.Adam(model_3.parameters(), lr=LR)훈련/검증용 라이브러리 import
# 사전에 모듈화 한 학습/검증용 라이브러리 import
from C_ModelTrainer import ModelTrainer
ES = 1 # 디스플레이용 에포크 스텝
# BC_mode = True(이진), False(다중)
# aux = 보조분류기 유/무
# wandb = 완디비에 연결 안하면 None
trainer = ModelTrainer(epoch_step=ES, device=device, BC_mode=False, aux=False)위 훈련/검증에 사용되는 라이브러리는 필자가
24. wandb (Weights & Biases) (2) - 인공지능 고급(시각) 강의 복습 에서 별도로 설계한
평가/검증용 라이브러리 이다.
이걸로 훈련/검증 성과를 도출하는게 편해서 해당 파일을 사용했다.
https://github.com/tbvjvsladla/ResNext_wandb/blob/main/C_ModelTrainer.py
위 C_ModelTrainer.py는 깃허브에 업로드 되어 있다.
성과지표 저장 + epoch 설정
history = {'int_loss':[], 'int_acc':[],
'tfidf_loss':[], 'tfidf_acc':[],
'embed_loss':[], 'embed_acc':[],} #학습/검증 중간 정보 저장
num_epoch = 10 #총 훈련/검증 epoch값훈련 코드
for epoch in range(num_epoch):
#훈련 손실&성능지표 반환
train_loss, train_acc = trainer.model_train(model_1, trainloader,
criterion, optimizer_1, epoch)
#손실 및 성능지표를 history에 저장
history['int_loss'].append(train_loss)
history['int_acc'].append(train_acc)
# Epoch_Step(ES)일때 print하기
if (epoch+1) % ES == 0 or epoch == 0:
print(f"epoch {epoch+1:03d}," + "\t" +
f"훈련 [Loss: {train_loss:.3f}, " +
f"Acc: {train_acc*100:.2f}%]")for epoch in range(num_epoch):
#훈련 손실&성능지표 반환
train_loss, train_acc = trainer.model_train(model_2, TI_trainloader,
criterion, optimizer_2, epoch)
#손실 및 성능지표를 history에 저장
history['tfidf_loss'].append(train_loss)
history['tfidf_acc'].append(train_acc)
# Epoch_Step(ES)일때 print하기
if (epoch+1) % ES == 0 or epoch == 0:
print(f"epoch {epoch+1:03d}," + "\t" +
f"훈련 [Loss: {train_loss:.3f}, " +
f"Acc: {train_acc*100:.2f}%]")for epoch in range(num_epoch):
#훈련 손실&성능지표 반환
train_loss, train_acc = trainer.model_train(model_3, oh_trainloader,
criterion, optimizer_3, epoch)
#손실 및 성능지표를 history에 저장
history['embed_loss'].append(train_loss)
history['embed_acc'].append(train_acc)
# Epoch_Step(ES)일때 print하기
if (epoch+1) % ES == 0 or epoch == 0:
print(f"epoch {epoch+1:03d}," + "\t" +
f"훈련 [Loss: {train_loss:.3f}, " +
f"Acc: {train_acc*100:.2f}%]")2.7 결과 분석
# 1번 그래프: loss 비교
plt.figure(figsize=(5, 10)) # 그래프 크기 설정
plt.subplot(2, 1, 1) # 2행 1열의 첫 번째 서브플롯
plt.plot(history['int_loss'], label='int_loss', color='red')
plt.plot(history['tfidf_loss'], label='tfidf_loss', color='green')
plt.plot(history['embed_loss'], label='embed_loss', color='blue')
plt.title('Loss Comparison')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
# 2번 그래프: accuracy 비교
plt.subplot(2, 1, 2) # 2행 1열의 두 번째 서브플롯
plt.plot(history['int_acc'], label='int_acc', color='red')
plt.plot(history['tfidf_acc'], label='tfidf_acc', color='green')
plt.plot(history['embed_acc'], label='embed_acc', color='blue')
plt.title('Accuracy Comparison')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
# 그래프 출력
plt.tight_layout()
plt.show()위 코드로
1) 단순 정수(원핫)인코딩으로 영화리뷰 댓글 분류
2) TF-IDF 인코딩으로 영화리뷰 댓글 분류
3) 임베딩 인코딩으로 영화리뷰 댓글 분류
3가지 조건에 따른 결과를 비교하면 아래와 같다.
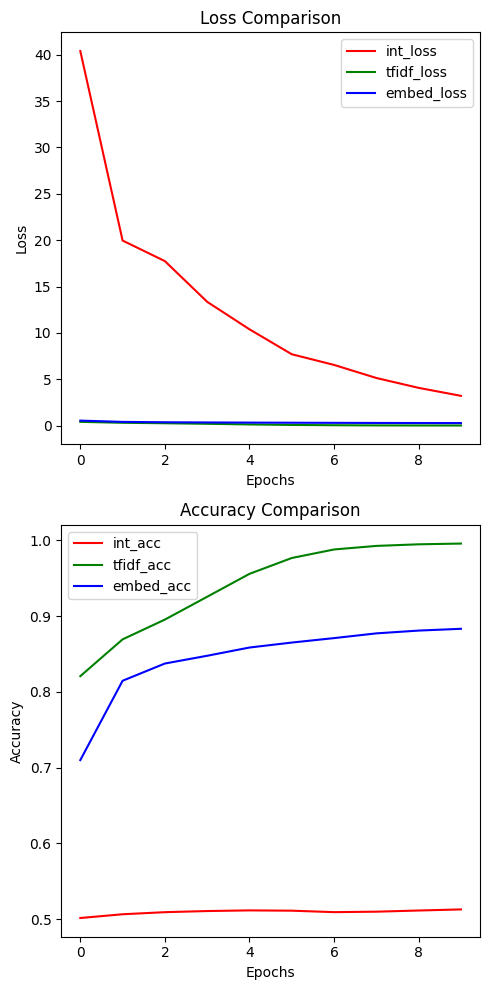
1) 단순 정수(원핫)인코딩은 학습이 많이 느리다고 보면 되니
2) TF-IDF 인코딩, 3) 임베딩 인코딩 만 다시 비교해보자
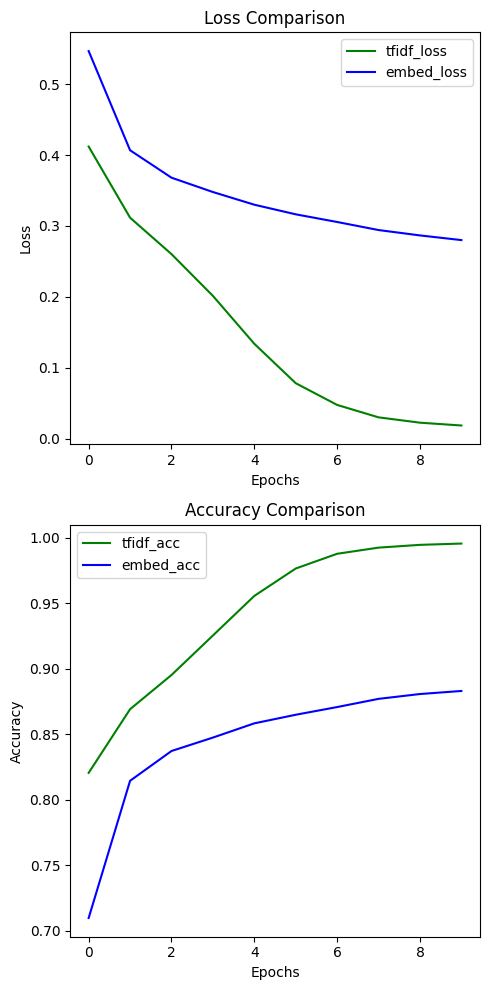
사실 따지고 본다면 3) 임베딩 인코딩은 torch.mean 함수를 통해 해당 단어가 데이터셋에서 다른 단어와 어떤 의미적 유사성이 있는지에 대한 정보가 다 뭉게졌는데도
꽤 좋은 결과를 보여주고 있다.
이는 고차원의 밀집벡터로 정사영만 시켜도 꽤 유의미한 성능을 발휘한다라고 볼 수 있는 것이다.
이렇게 Embedding layer 만 앞단에 추가해도 꽤 좋은 성능을 발휘하여
대다수의 언어모델에는 Embedding layer가 항상 앞에 붙은 상태로 설계된다.
지금 포스트에 사용된 언어모델은 설계한 Embedding layer의 성능을 제대로 활용하지 못하는 매우 낮은 성능의 모델로 설계했으니,
다음 포스트에서는 이 Embedding layer을 씹뜯맛즐 하는 언어모델에 대한 소개를 이어나가겠다.
