
도입
인공지능과 데이터 분야에 대한 관심이 점점 커지고 있는 요즘, 많은 사람이 실제로 어떻게 기술을 활용할 수 있을지 고민하고 있다. 이번 강의는 파이썬과 OpenAI API를 이용해 데이터를 다루고, 의미 있는 결과물을 도출하는 과정을 다룬다. 파이썬을 어느 정도 다룰 줄 안다면 누구나 따라 할 수 있는 실습 프로젝트들로 구성되어 있어, 학습자가 자신의 실력을 자연스럽게 발전시킬 수 있는 기회를 제공한다.
8개의 다양한 프로젝트를 통해, 자연어 처리부터 감정 분석, 데이터 시각화까지 다루며 현업에서 바로 적용할 수 있는 스킬들을 익힐 수 있다. 실제로 데이터 수집부터 분석, 그리고 모델 튜닝까지의 전체 과정을 경험하면서 AI와 데이터 사이언스의 기본기를 확실히 다질 수 있을 것이다.
지금 이 강의를 통해, 데이터의 세계에서 원하는 결과를 보다 쉽게 얻어보라. 어렵게 느껴질 수 있는 AI 기술이 실습과 프로젝트를 통해 친숙해질 것이다.

https://metacodes.co.kr/edu/read2.nx?M2_IDX=31635&EP_IDX=9859&EM_IDX=9683
1. 프로젝트 개요

이번 프로젝트는 NewsAPI를 활용하여 키워드에 맞는 최신 뉴스를 수집하고
수집한 결과를 알아보기 쉽게 Dashboard를 만들어서 visualization까지 수행하는 프로젝트이다.
2. News API
해당 홈페이지에 접속하여 가입을 하면
가입한 직후 바로 API Key가 발급된다.
발급받은 API는 관리를 위하여 .env에 새로이 기입을 해주고...
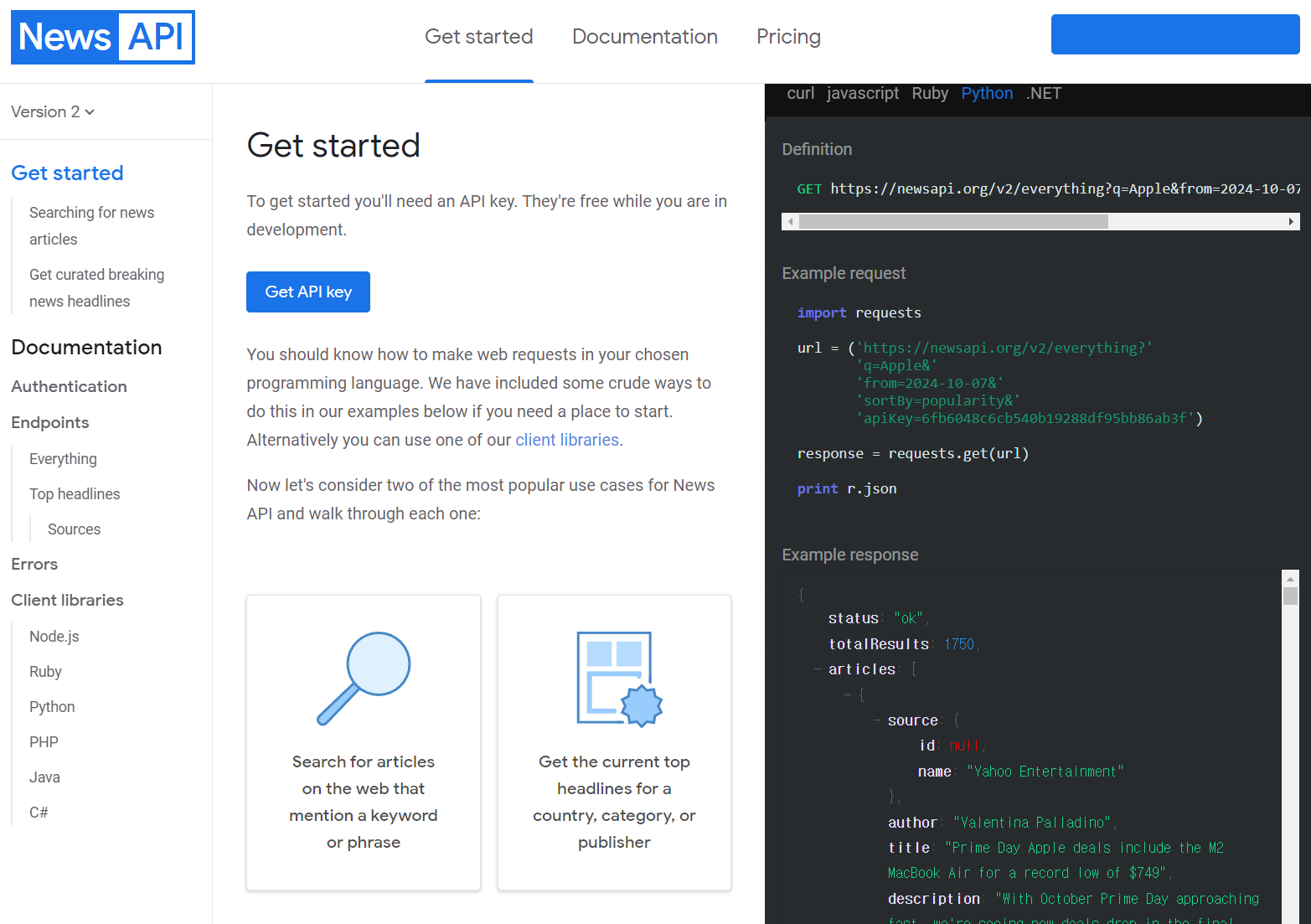
가입 후 해당 페이지에서 getting stard guide 링크를 클릭하면 사용 방법이랑 예제코드를 각 개발언어별로 옆의 코드창에 디스플레이 해준다
youtube data v3 api는 document구성이 형펀없었는데
NewsAPI는 상당히 쉽게 접근할 수 있도록 문서가 제공되고 있다.
2.1 최신 뉴스 가져오기
주어진 키워드에 대해서 최신 기사를 수집하는 함수를 설계하고자 한다.
코드는 아래와 같다.
from dotenv import load_dotenv
from openai import OpenAI
import os
load_dotenv() # .env 파일의 환경 변수를 불러옴
api_key = os.getenv('OPENAI_API_KEY')
news_api_key = os.getenv('NEWS_API_KEY')
# API 키가 정상적으로 불러와졌는지 확인
#print(f"API Key: {api_key}")
client = OpenAI()# 주어진 키워드, 쿼리에 대한 최신 기사 수집 함수
# 이때 수집하는 최신 기사는 '한국' 뉴스 사이트 도메인으로 제한
# 수집 기사의 언어도 '한국어'로 제한
def get_latest_news(query, api_key, num_articles=5):
# 한국 주요 뉴스 사이트 도메인 설정
# 주요 뉴스 도메인을 콤마로 구분된 문자열로 join
korean_domains = ','.join(kr_domain_list)
# 뉴스 API에 요청할 URL 생성
url = (f'https://newsapi.org/v2/everything' # 메인 헤드문
f'?q={query}' # 이 쿼리에 수집하고 싶은 주제어를 입력
f'&language=ko' # 수집하는 기사의 언어는 한국어로 제한
# f'&domains={korean_domains}' # 수집하는 기사의 발행사는 특정 도메인으로 제한
f'&sortBy=publishedAt' # 수집한 기사를 최신순으로 정렬
f'&apiKey={api_key}' # NewsAPI 키 입력부분
)
print(f'생성한 URL: \n{url}')
# API 요청을 보내고 응답 받기
response = requests.get(url)
# 응답이 성공적(상태 코드 200)인지 확인
if response.status_code == 200:
# 응답에서 기사 리스트 추출 (최대 num_articles 개수만큼)
articles = response.json().get('articles', [])[:num_articles]
# 기사 제목, 본문, URL을 포함하는 리스트 생성
news_list = [{'title': article['title'],
'content': article['content'],
'url': article['url']}
for article in articles]
else:
# 오류가 발생했을 때 에러 메시지 출력
print(f"에러발생, 에러코드: {response.status_code}")
news_list = []
return news_listNewsAPI로 기사를 수집하는건 실제로
URL을 생성한 뒤 이 URL을 바탕으로 NewsAPI를 관리하는 메인 서버에서 연산을 전부 수행하고
그 결과물이 웹페이지에 저장되면
해당 웹페이지의 결과물을 가져오는 형식인 듯 하다.
수집 기사의 언어를 제한하는 것은 문제없이 진행됬으나
특정 도메인(신문사)만 수집하는건 어째서인지 제대로 동작하지 않았다
그러니까
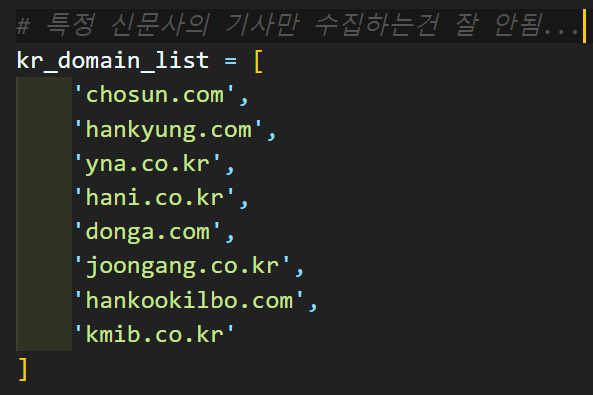
이렇게 신문사 도메인을 지정하고 해당 신문사의 기사만 수집하는건 잘 동작하지 않는다 라고 보면 된다.
아무튼
query = '이스라엘'
news_list = get_latest_news(query, news_api_key, 10)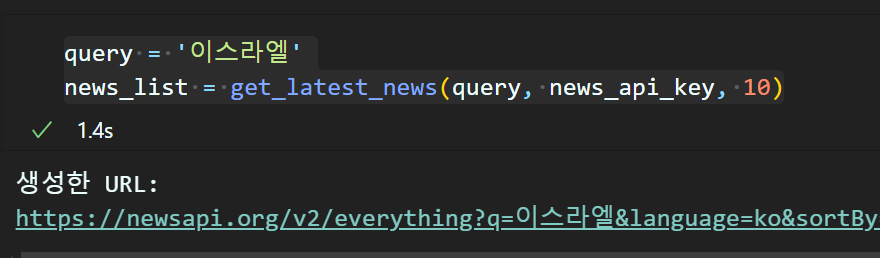
위와 같이 쿼리에 수집하고자 하는 주제를 입력하면
해당 주제를 다룬 기사를 수집하며, 이때 수집하기 위한 URL이 출력되게 코드를 설정한다.
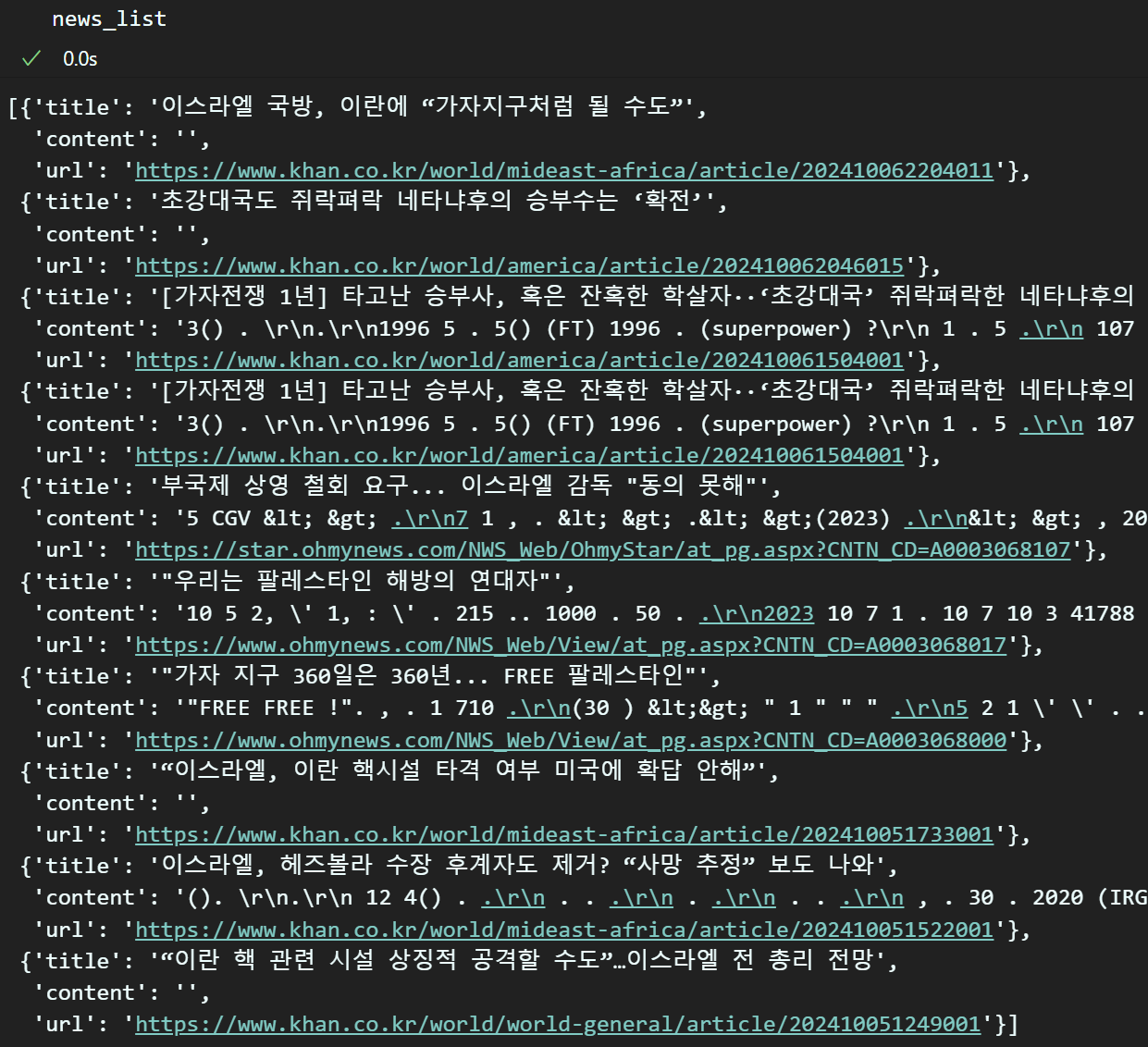
수집한 결과물 news_list를 확인하면
타이틀, 코멘트, url 순으로 정리되는 것을 확인할 수 있다.
3. 수집한 기사 요약
출력물인 news_list를 확인하면
title, content, url 3가지 항목으로 나뉘며
OpenAI API는 url에 직접 접속하여 정보를 확인할 수는 없다.
따라서 content 항목만 바탕으로 기사를 요약해야 하며
이때 NewsAPI가 제대로 content를 채우지 못하는 경우도 존재한다
이를 고려하여 예외처리 구문을 포함시킨 코드를 작성한다.
def system_prompt():
return '''기사를 요약'''
def user_prompt(content, format_template):
return f'''기사 : {content}를 정제 후 기사 요약
기사는 1개의 문장으로 요약한다.
요약된 출력 형식은 {format_template}을 준수한다.'''
format_template = '문장1.'def summarize_aritcle(article):
content = article['content']
title = article['title']
summary_result = {"title" : "",
"article_summary": "",
"url": ""}
summary_result['title'] = title
summary_result['url'] = article['url']
if content is None or len(content.strip()) == 0:
summary_result['article_summary'] = "News API 기사 불러오기 실패"
return summary_result
# openai를 사용해 기사 요약하기
response = client.chat.completions.create(
model = "gpt-4-turbo",
messages=[
{"role": "system", "content": system_prompt()},
{"role": "user", "content":
user_prompt(content, format_template)},
],
max_tokens = 100
)
try :
summary_result['article_summary'] = response.choices[0].message.content
except Exception as e:
summary_result['article_summary'] = "기사 요약 실패"
return summary_result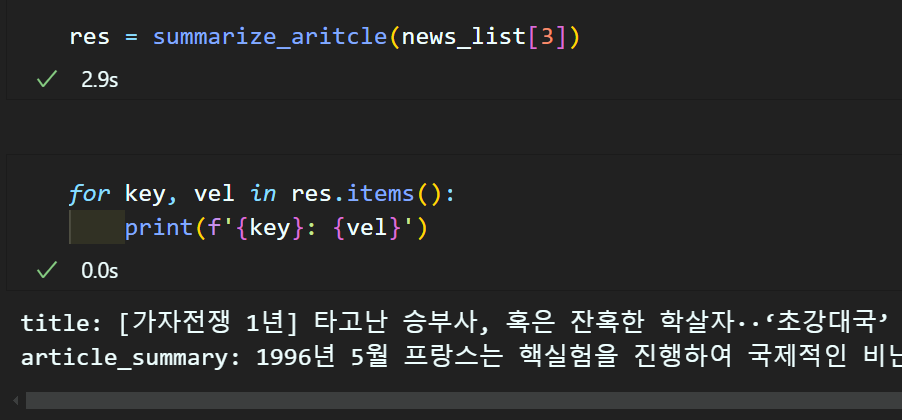
하나의 기사에 대한 중간결과물을 확인한다면 위와 같이 기사제목, 기사 요약 정보가 딕셔너리 형태로 출력되게 코드를 작성한다.
결과물 출력이 어떤 형식으로 되는지 확인하였으니
아래의 코드를 통해 모든 뉴스 요약본을 리스트화 하여 정리하자
summaries = []
for news in news_list:
summary_result = summarize_aritcle(news)
summaries.append(summary_result)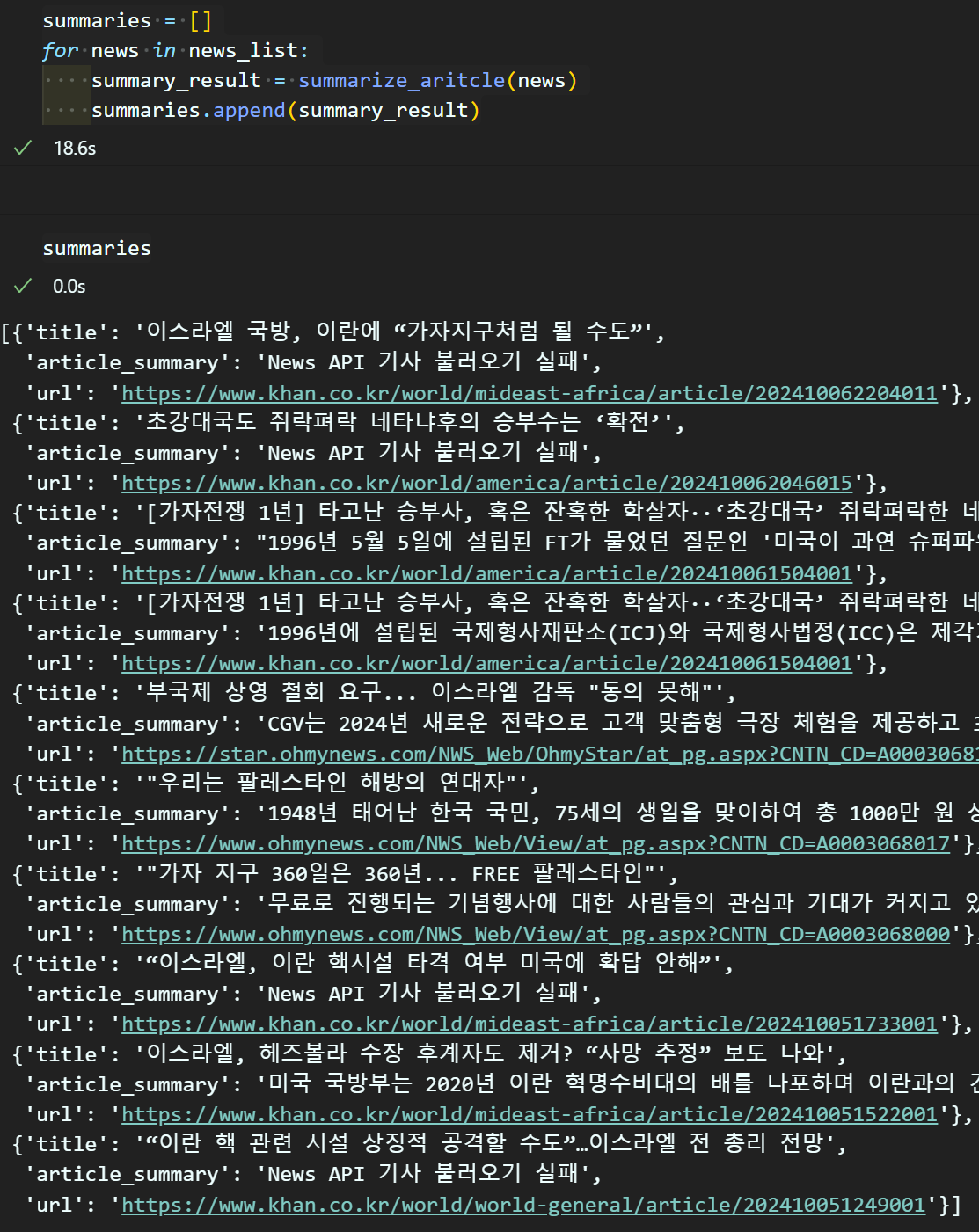
3.1 Dash App를 활용한 뉴스 수집 앱 개발
https://dash-bootstrap-components.opensource.faculty.ai/
https://dash.plotly.com/
위 두개의 홈페이지에서 설명하고 있는 Dash 라이브러리를 통해서 데이터 시각화 기능을 지원하는 라이브러리라 보면 된다.
이를 수행하기 위해 아래의 두개 라이브러리를 설치한다
! pip install dash
! pip install dash-bootstrap-components설치 후 사용은 아래와 같다.
import dash
from dash import dcc, html
import dash_bootstrap_components as dbc# Dash 앱 초기화, Bootstrap 테마 사용
app = dash.Dash(__name__, external_stylesheets=[dbc.themes.BOOTSTRAP])
# 앱 레이아웃 정의
app.layout = dbc.Container([
# 첫 번째 행: 대시보드 제목을 포함한 행
dbc.Row([ # H1 태그로 대시보드 제목 표시
dbc.Col(html.H1("Personalized News Dashboard"), className="mb-4")
]),
# 두 번째 행: 각 기사를 카드 형식으로 표시하는 행
dbc.Row([
# 각 기사를 열(Column)로 생성
dbc.Col(
# 카드 컴포넌트 생성
dbc.Card(
# 카드의 본문 생성
dbc.CardBody([
html.H4(article['title']), # 기사 제목 표시
html.P(article['article_summary']), # 기사 요약 표시
# 'Read more' 버튼 생성, 클릭 시 원본 기사를 새 탭에서 열기
dbc.Button("Read more", color="primary",
className="mt-auto", href=article['url'],
target="_blank")
])
), width=4, className="mb-4") # 카드 열의 너비 설정 및 하단 마진 추가
for article in summaries # 기사 요약본(리스트)에 대해서 반복수행
])
])
# 앱 실행
if __name__ == '__main__':
app.run_server(debug=True, port=8053) # 서버를 디버그 모드로 실행, 포트 번호 8051 사용
이렇게 코드가 실행되면 vscode IDE환경이라면
cell script 아래에 바로 웹페이지가 열린다
이를 크롬이나 네이버 웨일 웹 브라우저에서 열람을 하고 싶다면
http://127.0.0.1:8053 포트번호로 접속을 하면 된다.
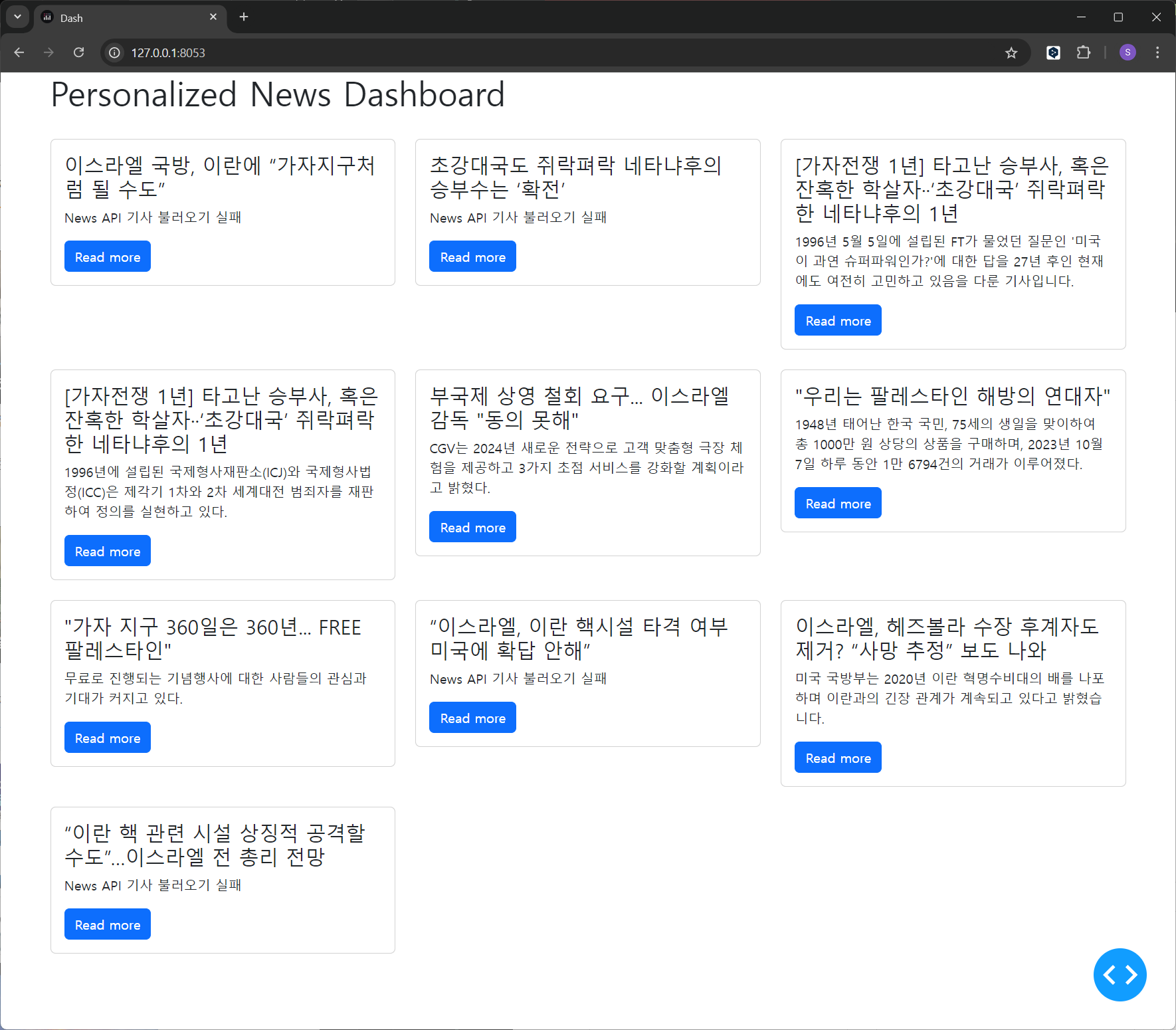
해당 페이지 주소를 크롬 브라우저에서 열람하면
위 사진처럼 HTML 형식으로 열람이 가능하며
로컬 페이지이기에 다른 PC에서는 해당 웹페이지 접속은 불가하다
아무튼 위와 같은 식으로
News API를 통해 기사 정보를 수집하고
이를 OpenAI-API로 기사 요약을 한 뒤
Dash 라이브러리를 활용해 웹페이지 형식으로
요약된 기사 리스트를 한눈에 알아볼 수 있도록 시각화가 가능하다
감사의 글

본 포스트는 메타코드 서포터즈로서 작성하였습니다
