1. 숫자로 요약하기 : 정보의 대푯값
- 중위수(median) : 자료의 순서상 가운데 위치한 값
- 최빈값(mode) : 자료 중에서 가장 많은 값
- 평균(mean)
- 산술평균
- 기하평균
- 조화평균
- 평균 사용 주의점
- 디즈니 공주들의 평균 나이
- 다른 공주들의 나이는 10대이나 '키다' 공주의 나이가 8800살이라 평균 나이대는 505세
- 미국 노스캐롤라이나대학에서 졸업생 평균 연봉이 가장 높은 학과
- 지리학과
- 마이클 조던이 지리학과 졸업생이기 때문
- 디즈니 공주들의 평균 나이
import numpy as np
import pandas as pd
# 평균
np.mean(df['열'])
df['열'].mean()
# 중앙값
np.median(df['열'])
df['열'].median()
# 최빈값
df['열'].mode()2. 숫자로 요약하기 : 사분위수
- 사분위수
- 데이터를 오름차순으로 정렬 후 4등분하여 각 경계에 해당하는 값
- 25%, 50%, 75% 위치의 값
3. 숫자로 요약하기 : 기초 통계량
- df.describe()
- count : 데이터 개수
- NaN이 존재할 경우 개수에서 제외
- 사분위수
- 25% : 1사분위수
- 50% : 2사분위수
- 75% : 3 사분위수
- count : 데이터 개수
4. 숫자형 변수 시각화하기 : Histogram
- diabetes : 당뇨병 환자 데이터
- ID : ID
- Pregnancies : 임신횟수
- Glucose : 포도당 부하 검사 수치
- BloodPressure : 혈압
- SkinThickness : 팔 삼두근 뒤쪽의 피하지방 측정값
- Insulin : 혈청 인슐린
- BMI : 체질량 지수
- DiabetesPedigreeFunction : 당뇨 내력 가중치 값
- Age : 나이
- Outcome : 당뇨여부(0 또는 1)
# plt.hist(변수명, bins = 구간 수, [edgecolor = '색'])
plt.hist(diabetes['Age'], bins = 5, edgecolor = 'gray')
plt.xlabel('Age')
plt.ylabel('Frequency')
plt.show()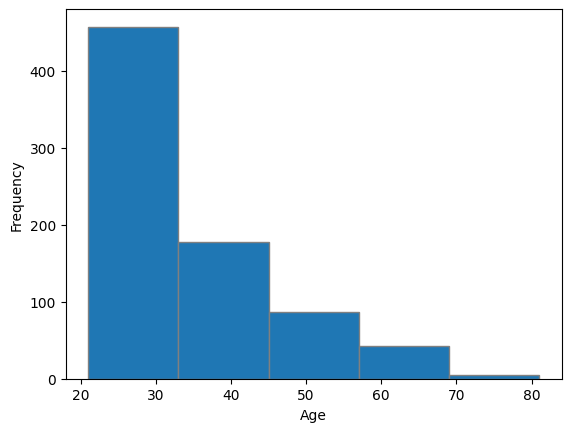
# 빈도수 조정
plt.hist(diabetes['Age'], bins = 10, edgecolor = 'gray')
plt.xlabel('Age')
plt.ylabel('Frequency')
plt.show()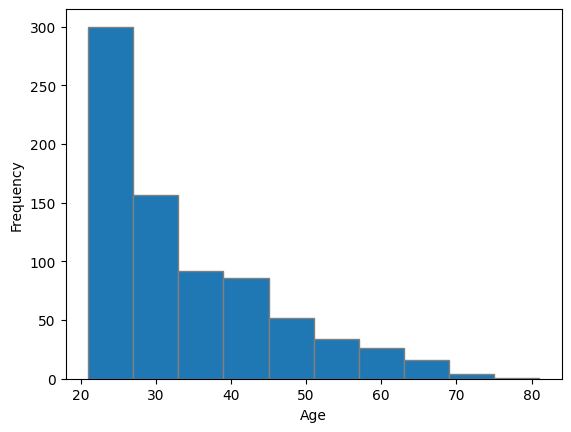
# seaborn 사용
sns.histplot(x= 'Age', data = diabetes)
# 엣지 자동 지정, bin 미지정 시 자동 지정
plt.show()
# x라벨과 y라벨도 자동 지정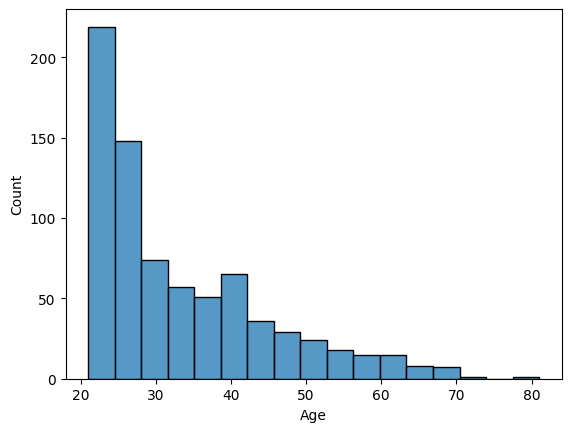
- 해당 그래프로 해당 데이터의 조사 대상은 20~40대 초반 임을 확인 가능
5. 숫자형 변수 시각화하기 - Density Plot(KDE Plot)
- 히스토그램의 단점
- 구간의 너비에 따라 그래프의 모양이 달라짐
- 이를 보완한 (확률 추정)밀도함수 그래프
- 구간의 너비가 필요 없음
- 밀도함수 그래프 아래의 면적은 1
- 면적으로 구간에 대한 확률 추정
sns.kdeplot(diabetes['Age'])
# sns.kdeplot(x='Age', data = diabetes)
plt.show()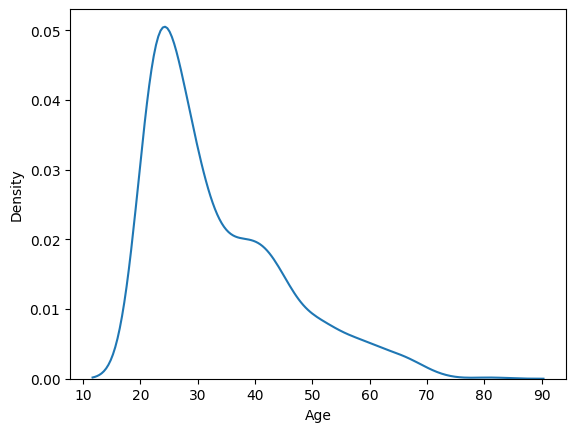
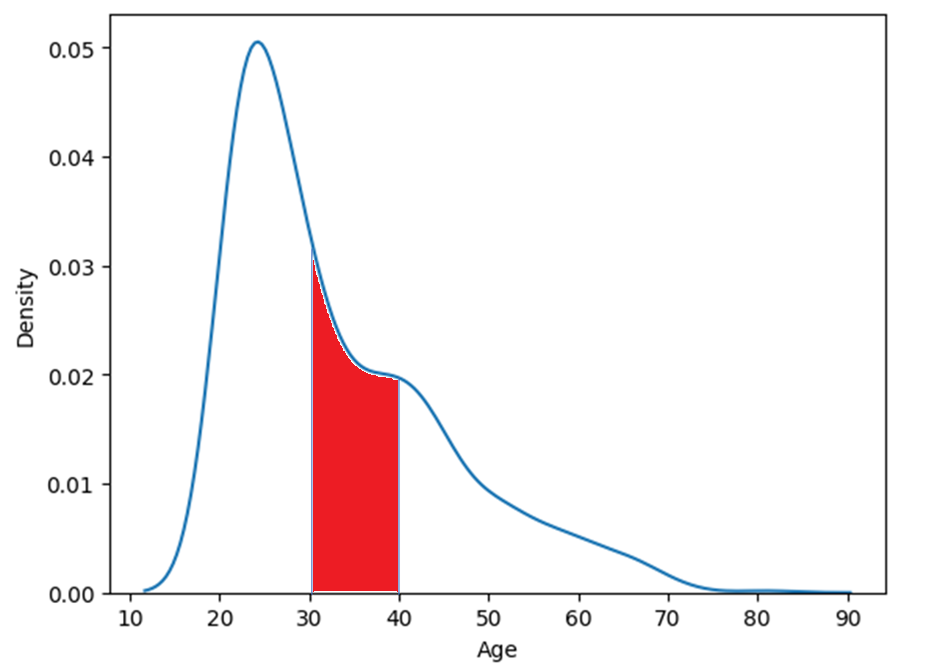
- x축의 범위가 히스토그램과 다름 -> 확률추정이기에 다름
- 어떤 사람을 지정했을 때 30대 일 확률
# 히스토그램과 밀도추정 동시 출력
sns.histplot(diabetes['Age'], kde = True)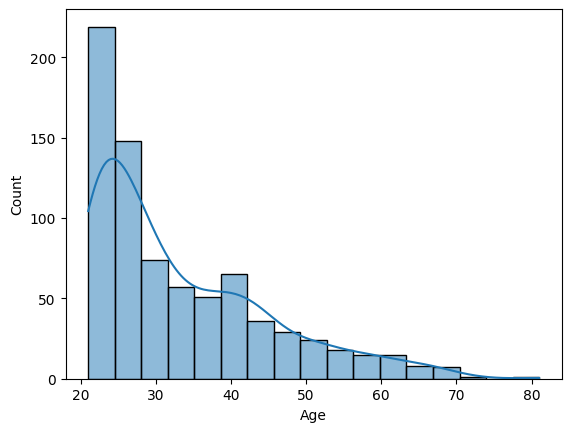
6. 숫자형 변수 시각화하기 - Box Plot
- plt.boxplot()
- 사전에 NaN을 제외 필수(sfns.boxplot은 NaN 자동 처리)
- vert : 횡(False), 종(True, 기본값)
# NaN 처리
temp = diabetes.loc[diabetes['Age'].notnull()]
# 종(세로)
plt.boxplot(temp['Age'])
plt.grid()
plt.show()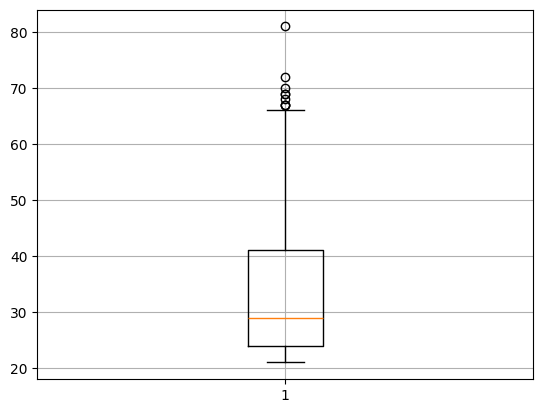
# 횡(가로)
plt.boxplot(temp['Age'], vert = False)
plt.grid()
plt.show()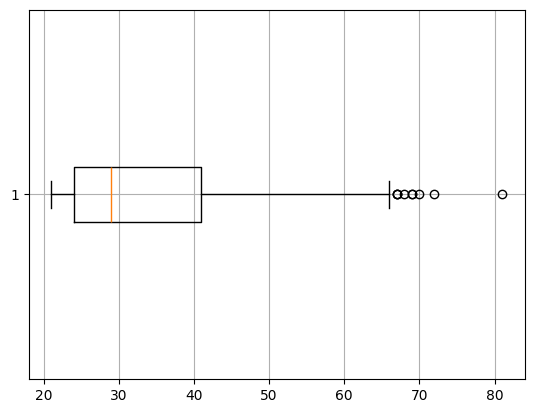
# seaborn 활용
sns.boxplot(x = diabetes['Age'])
plt.grid()
plt.show()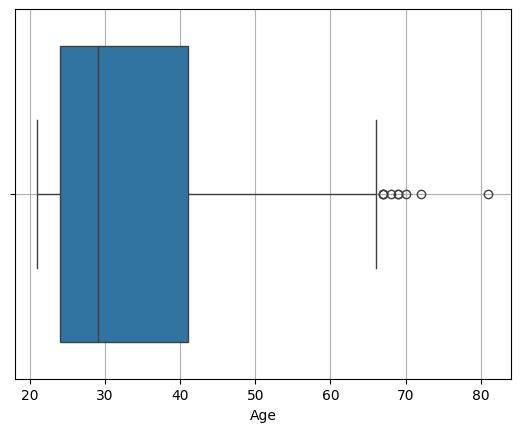
sns.boxplot(y = diabetes['Age'])
plt.grid()
plt.show()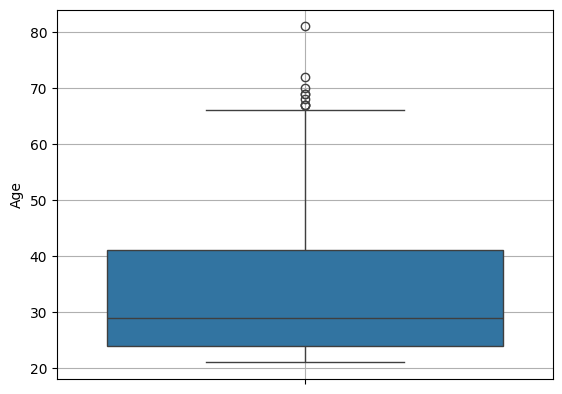
6-1. boxplot 설명
-
boxplot은 4분위수를 표현
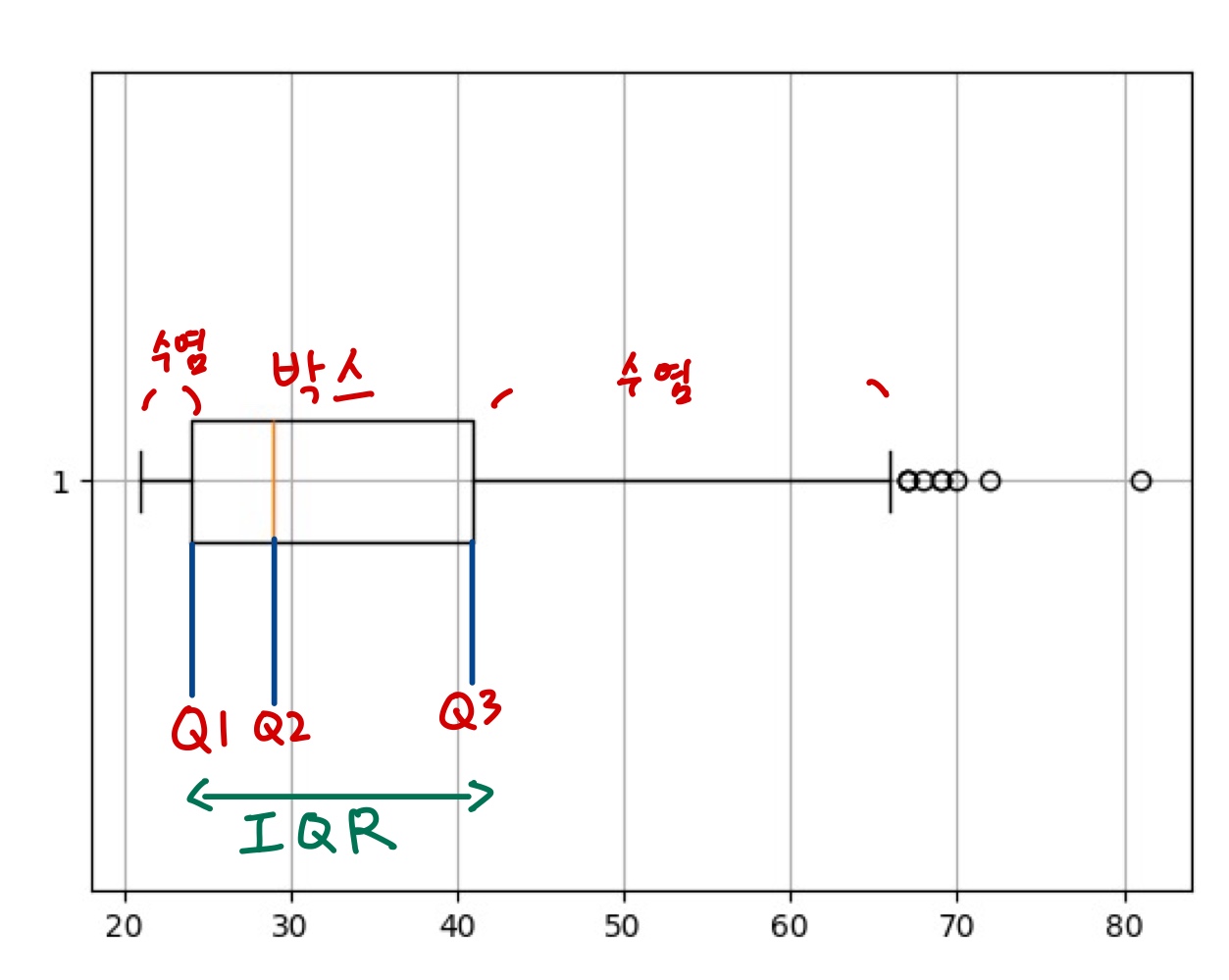
-
IQR = Q3(3사분위수) - Q1(1사분위수)
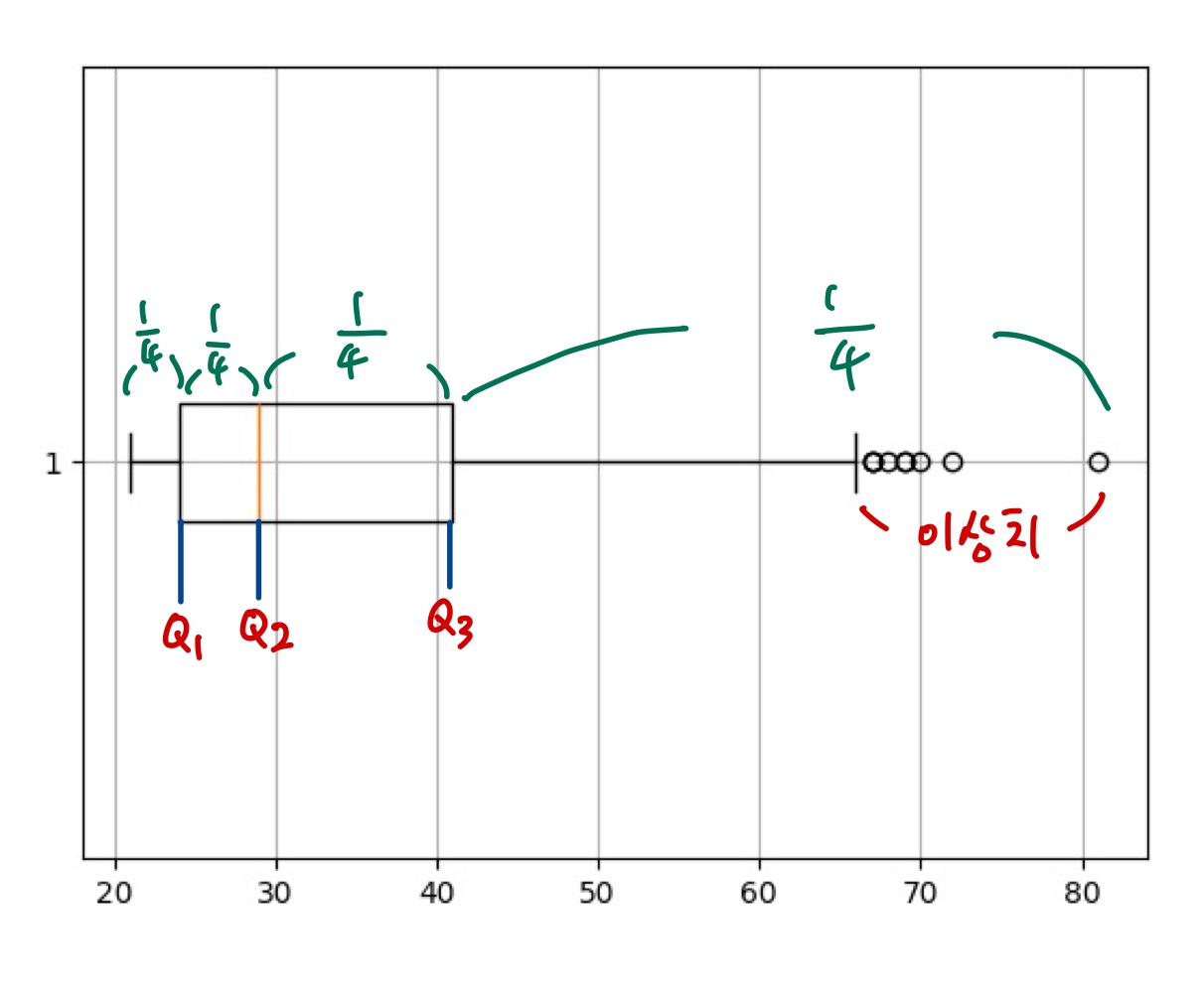
-
Potential Whisker Length : 1.5 * IQR 범위, 잠재적 수염의 길이 범위
- min = Q1 - 1.5 * IQR
- max = Q3 + 1.5 * IQR
-
Actual Whisker Length : 1.5 * IQR 범위 이내의 데이터의 최소, 최대값, boxplot 사용 시 표시되는 수염의 길이

데이터 분석가&엔지니어를 희망하는 취준생