1. 정보 이론(information theory)
-
추상적인 '정보'라는 개념을 정량화하고 정보의 저장과 통신을 연구하는 분야
-
정량적으로 표현하기 위한 3가지 조건
- 일어날 가능성이 높은 사건은 정보량이 낮고, 반드시 일어나는 사건에는 정보가 없는 것이나 마찬가지입니다.
- 일어날 가능성이 낮은 사건은 정보량이 높습니다.
- 두 개의 독립적인 사건이 있을 때, 전체 정보량은 각각의 정보량을 더한 것과 같습니다.
-
정보량(information content) : 한 가지 사건에 대한 값
수식으로 표현하면, 사건 가 일어날 확륭을 라고 할 때,
사건의 정보량 는- 는 주로 2, , 10 값을 사용
- 일때, 는 정보를 나타내기 위한 필요한 bit의 수
- 일때 그래프

- 는 주로 2, , 10 값을 사용
2. Entropy
- 특정 확률분포를 따르는 사건들의 정보량 기댓값 = 불확실성 정도
- 이산 확률 변수의 entropy
이산 확률 변수 일때 엔트로피는
- 여러가지 색의 공이 있는 주머니 vs 단색공 주머니

- 10개의 색 공의 비율 1:9 vs 6:4
- 사건들의 확률이 균등할수록 엔트로피값은 증가

- 사건들의 확률이 균등할수록 엔트로피값은 증가
- ex) 동전과 같이 앞면이 나올 확률 0.5, 뒷면이 나올 확률 0.5일때, 균등 분포(uniform distribution)) 엔트로피값이 최대
⇨ 즉, 앞면이 나올 확률 0.9인 동전을 던질 때보다 0.5확률 일때가 가장 예측하기 어렵다. (= 불확실 성이 크다)라고 해석

- 여러가지 색의 공이 있는 주머니 vs 단색공 주머니
- 연속 확률 변수의 entropy = 미분 엔트로피(differential entropy)
확률 변수 의 확률 밀도 함수가 일 때 엔트로피는
3. Kullback Leibler Divergence
-
머신러닝의 목표 : 새로운 입력 데이터가 들어와도 예측이 잘 되도록, 모델의 확률 분포를 데이터의 실제 확률 분포에 가깝게 만드는 것
-
머신러닝 모델의 종류
- 우선 결정 모델(discriminative model) : 데이터의 실제 분포를 모델링 하지 않고 결정 경계(decision boundary)만을 학습합
- ex) 모델의 결과값이 0보다 작으면 1번 클래스, 크다면 2번 클래스로 분류
- 생성 모델(generative model) : 데이터와 모델로부터 도출할 수 있는 여러 확률 분포와 베이즈 이론을 이용해서 데이터의 실제 분포를 간접적으로 모델링
- 두 확률 분포의 차이를 나타내는 지표 : 쿨백-라이블러 발산(Kullback-Leibler divergence, KL divergence) 등
- 우선 결정 모델(discriminative model) : 데이터의 실제 분포를 모델링 하지 않고 결정 경계(decision boundary)만을 학습합
-
두 확률 분포의 KL divergence란
- 데이터의 실제 확률 분포 , 모델의 학습으로 도출된 확률분포일 때, 를 기준으로 계산된 의 평균정보량과 의 평균 정보량의 차이
- 이산 확률 변수
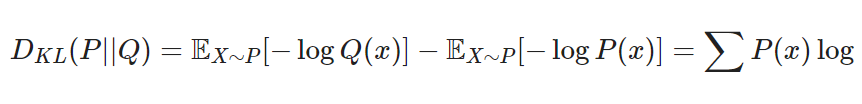
- 연속 확률 변수
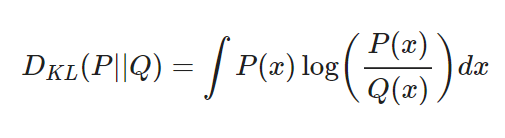
-
특성
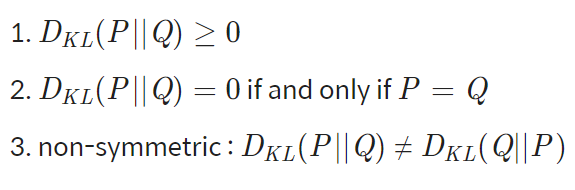
-
두 확률 분포의 차이를 줄여야 하므로 를 최소화하는 방향으로 모델을 학습
- 빨간색 : 실제 분포, 고정 값
- 파란색 : 바꿀 수 있는 부분. KL divergence의 최소화 = Q(x)를 최소화하는 문제 = $P(x)에 대한 의 교차 엔트로피의 최소화
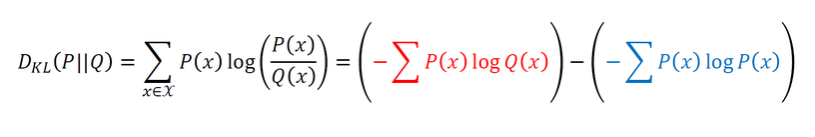
-
교차 엔트로피(cross entropy)
- 에 대한 의 교차 엔트로피
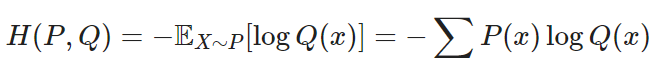
- 관계식
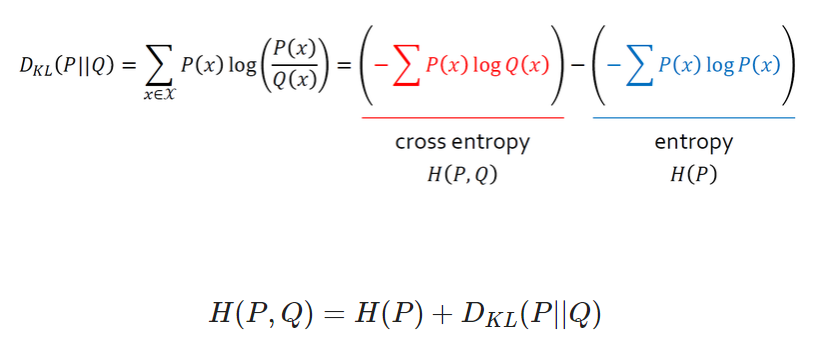
- 에 대한 의 교차 엔트로피
4. Cross Entropy Loss
- 손실 함수(loss function) : 머신러닝에서 모델이 나타내는 확률 분포와 데이터가 따르는 실제 확률 분포 사이의 차이를 나타내는 함수
(정리 안됨)
- Cross Entropy와 Likelihood의 관계
모델 파라미터를 로 놓으면, 모델을 표현하는 확률분포 , 실제 데이터 분포 %P(y|X)를 나타낸다.- 는 예측값의 분포를 나타내고 모델의 likelihood와 같다.
- 고정값 : X와 y(데이터셋에 의해 결정되는 값이기 때문)
- 바꿀 수 있는 부분 : $-\log Q(y|X, \theta)
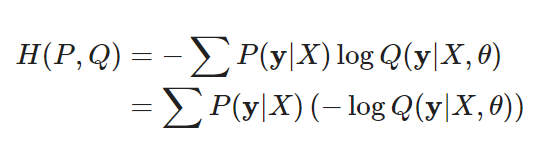
∴ cross entropy 최소화 하는 파라미터 값 구하기 = negative log likelihood를 최소화하는 파라미터 값 구하기
5. Decision Tree와 Entropy
- 의사결정 트리
- 엔트로피 감소 ⇨ 모델 내부에 정보 이득(Information Gain)
- 엔트로피 증가 ⇨ 정보 손실량
- 는 라는 분류 기준 채택을 통해 얻은 정보 이득의 양

