1. Introducing
2. PDF file structure
- Extracted Features
- 15개의 specific keyword의 등장 빈도
- 3개의 data description feature
- entropy in stream object(stream은 binary 형태로 저장되는데 그에 대한 entropy를 의미하는 것 같음)
- entoropy outside stream objects
- 마지막 EOF 이후 나오는 byte 개수
- 2개의 objuscation(난독화) feature
- PDF의 header가 obfuscate인지 판단(ex. header를 문서의 서두가 아닌 아래쪽에 배치)
- obfuscate된 keyword의 개수
3. System model
Improved binary gravitional search algorithm(IBGSA)를 사용하여 정확도가 가장 높게나오는 feature들을 select 하였다. 머신러닝 모델로는 Random Forest, Decision Tree를 사용하였다.
4. The proposed malicious PDF detection algorithm
만류인력 법칙에서 착안한 GSA의 이진 형태인 BGSA, 이를 발전시킨 IBGSA 알고리즘을 사용하여 feature를 select하였다.
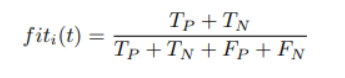
fit값을 계속 높이는 방향으로 feature들의 subset을 구성하고 가장 좋은 성능을 내는 subset을 선택한다.
classification model은 두 가지 phase로 나뉜다.
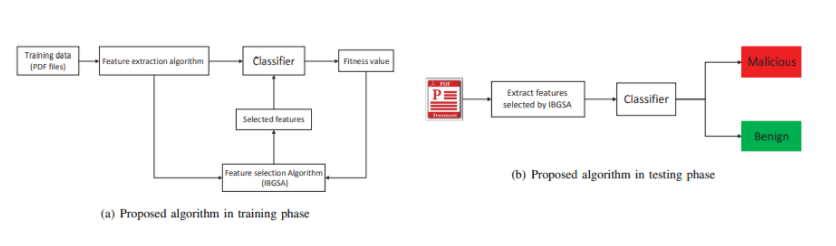
5. Experimental results
metric에 대한 수식은 아래와 같다.
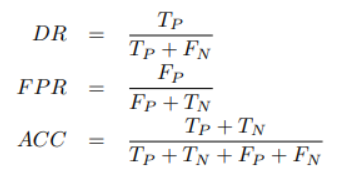
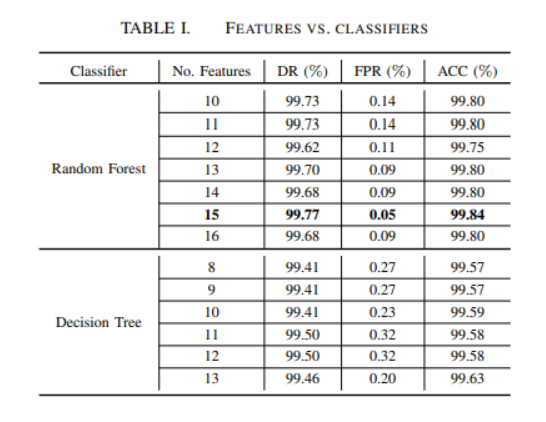
Random Forest는 feature를 15개로 섡정하였을때 가장 성능이 좋았다.
Reference
-
Data Mining Based Strategy for Detecting Malicious PDF Files
Samir G. Sayed, Mohamed Shawkey
