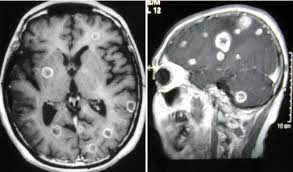
02번째 게시물
첫 게시물에서 정형데이터(excel)활용하여 Binary 분류를 실시했었습니다. 이번에는 좀더 나아가서 이미지데이터를 멀티클래스로 분류하는 과제입니다.
(윈도우, visualstuiocode 사용)
Brain Tumor MRI Classfication
데이터 : https://www.kaggle.com/datasets/sartajbhuvaji/brain-tumor-classification-mri
데이터 유형 : 이미지(.jpg)
데이터 선택이유 : 이미지 멀티클래스 분류를 하려 했는데 딱 맞음
전제조건 : 디렉토리로 라벨링 되어 있어서 수정하면 안됨
0) 필요한 패키지 모듈 가져오기
import os
import torch
import numpy as np
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
import pandas as pd
import albumentations as A
from torchvision import models
from PIL import Image
from torchinfo import summary
from torch.utils.data import Dataset, DataLoader
from albumentations.pytorch.transforms import ToTensorV21) 데이터 확인

Brain Tumor MRI Classification
ㄴTesting
glioma_tumor,meningioma_tumor,no_tumor,pituitary_tumor
ㄴTraining
glioma_tumor,meningioma_tumor,no_tumor,pituitary_tumor
ㄴValidation
glioma_tumor,meningioma_tumor,no_tumor,pituitary_tumor
ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ
glioma_tumor : 교모세포종양
meningioma_tumor : 수막종양
no_tumor : 종양없음
pituitary_tumor : 뇌하수체종양
ㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡㅡ
데이터가 디렉토리로 Trainig, Testing, Validation 구분 되어 있으며 그안에 다시 디렉토리 명으로 각각 4개의 클래스가 존재하네요.
2) 데이터 불러오기, 데이터 라벨, 원-핫 인코딩
별도의 데이터 분류 없이 폴더 명을 통해서 Training,Testing,Validation 구분한 뒤 하위 디렉토리 명으로 라벨링을 실시 합니다.
def split_feature_label(file_path):
label = file_path.split("\\")[1]
img = Image.open(file_path).convert("L")
img_array = np.array(img, dtype=np.uint8)
return img_array, label
def fileopen_splitdata_labeling(dir):
train_data = {"numpy": [], "label": []}
val_data = {"numpy": [], "label": []}
test_data = {"numpy": [], "label": []}
train_shape = np.zeros(2)
val_shape = np.zeros(2)
test_shape = np.zeros(2)
test_path = []
for (directory, _, filenames) in os.walk(dir):
if "Training" in directory:
for filename in filenames:
if ".jpg" in filename:
file_path = os.path.join(directory, filename)
img_array, label = split_feature_label(file_path=file_path)
train_shape = train_shape + img_array.shape
train_data["numpy"].append(img_array)
train_data["label"].append(label)
elif "Validation" in directory:
for filename in filenames:
if ".jpg" in filename:
file_path = os.path.join(directory, filename)
img_array, label = split_feature_label(file_path=file_path)
val_shape = val_shape + img_array.shape
val_data["numpy"].append(img_array)
val_data["label"].append(label)
elif "Testing" in directory:
for filename in filenames:
if ".jpg" in filename:
file_path = os.path.join(directory, filename)
test_path.append(file_path)
img_array, label = split_feature_label(file_path=file_path)
test_shape = test_shape + img_array.shape
test_data["numpy"].append(img_array)
test_data["label"].append(label)
train_data["label"] = pd.get_dummies(train_data["label"])
val_data["label"] = pd.get_dummies(val_data["label"])
test_data["label"] = pd.get_dummies(test_data["label"])
train_avg_shape = train_shape / len(train_data["numpy"])
val_avg_shape = val_shape / len(val_data["numpy"])
test_avg_shape = test_shape / len(test_data["numpy"])
print(f"\n\n###데이터 셋 별 평균 이미지 크기 확인###\n!!!!WARNING!!!!")
print(f"1. train데이터 평균 이미지 크기 : {train_avg_shape}")
print(f"2. val데이터 평균 이미지 크기 : {val_avg_shape}")
print(f"3. test데이터 평균 이미지 크기 : {test_avg_shape}")
return train_data, val_data, test_data,test_path
if __name__ == "__main__":
dir = "C:/Users/PC_1M/Desktop/코딩/kaggle_data/BrainTumor/Brain Tumor MRI Classfication/"
save_path = "C:/Users/PC_1M/Desktop/코딩/model/brain_tumor_epoch100.pt"
train_data, val_data, test_data,test_path = fileopen_splitdata_labeling(dir=dir)
class_num = len(set(train_data["label"]))
먼저 Training, Validation, Testing을 각각 가져온뒤 파일이름에 .jpg가 있는 이미지 파일(흑백으로)들만 가져오고 그때의 class폴더명을 라벨로 가져옵니다. 이 때에 모든 이미지의 크기가 동일한지 확인하기 위해서 각 구분 별 평균 shape 크기를 계산합니다.
그리고 가져온 4개 class라벨을 다시 원핫인코딩 시켜주고 반환합니다.
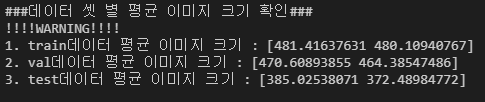
계산해보니 이미지 크기가 다른 것들이 존재하네요 따라서 추후에 augmentation 으로 이미지를 동일한 사이즈로 crop 해야될 것 같습니다.
3) 딥러닝을 위한 Dataset Batch, Dataloader 설정
# dataset class
class dataset(Dataset):
def __init__(self, data):
self.x = data["numpy"]
self.y = data["label"]
def __len__(self):
return len(self.y)
def __getitem__(self, index):
single_x = self.x[index]
single_y = self.y.iloc[index]
single_y = torch.tensor(single_y)
self.augmentor = self.augmentation()
augmented = self.augmentor(image=single_x)["image"]
normalizated = self.normalization(augmented)
return normalizated, single_y
def augmentation(self):
pipeline = []
pipeline.append(A.HorizontalFlip(p=0.5))
pipeline.append(A.RandomBrightnessContrast(p=0.5))
pipeline.append(A.CenterCrop(height=167,width=174,p=1))
pipeline.append(ToTensorV2(transpose_mask=True, p=1))
return A.Compose(pipeline, p=1)
def normalization(self, array):
normalizated_array = (array - array.min()) / (array.max() - array.min())
return normalizated_array
train_dataset = dataset(train_data)
val_dataset = dataset(val_data)
test_dataset = dataset(test_data)
print("\n###데이터셋 정의완료###")
train_batch = 32
val_batch = 1
test_batch = 1
train_dataloader = DataLoader(train_dataset, batch_size=train_batch,shuffle=True)
val_dataloader = DataLoader(val_dataset, batch_size=val_batch)
test_dataloader = DataLoader(test_dataset, batch_size=test_batch)
print("###데이터로더 정의완료###")
딥러닝 전용 커스터미이징 데이터셋으로 클래스를 구성합니다. 주의해야할 점은 feature들은 픽셀이며 모여서 하나의 이미지로 이루져있고 라벨들은 원핫인코딩된 상태이기 때문에 전자와 후자 getitem에서 인덱싱하는 방법이 다르다는 것 입니다.
또한 위에서 언급했듯이 이미지의 크기가 다르기 때문에 Albumentation 패키지의 CenterCrop을 실시하여 이미지를 동일한 크기로 만듭니다. 그리고 추가적인 augmentation으로 주로 이미지에 적용하는 Flip(Horizontal), RandomBrightnessContrast(밝기,조도) 적용한뒤 ToTensorV2모듈로 텐서화 시켜줍니다.
이때에 현재 이미지 는 h x w형태의 2차원인데 2차원을 ToTensorV2를 적용시키면 자동으로 c x h x w (c=1)로 반환시켜주기 때문에 차원크기를 조심합니다.
그리고 마지막으로 이미지의 각 픽셀 값이 0~255로 다양하게 분포되기 때문에 이미지 데이터 작업시 항상 실시하는 정규화(normalization)를 시켜 0~1 사이 값들로 바꿔줍니다.
만든 클래스로 각각 인스턴스를 생성한 뒤 batch를 설정하고 딥러닝 네트워크에 batch만큼 데이터를 가져다줄 DataLoader객체를 만듭니다.
4) Network 설정
class network(nn.Module):
def __init__(self, class_num):
super().__init__()
self.class_num = class_num
self.init = torch.nn.Conv2d(in_channels=1, out_channels=3, kernel_size=(1, 1))
self.model = models.resnet18(pretrained=True)
self.num_ftrs = self.model.fc.in_features
self.model.fc = nn.Linear(
in_features=self.num_ftrs, out_features=self.class_num
)
self.softmax = torch.nn.Softmax(dim=1)
def forward(self, x):
output = self.init(x)
output = self.model(output)
output = self.softmax(output)
return output
model = network(class_num=class_num)
print("###모델 정의 완료(resnet18)###\n", summary(model))네트워크를 설정하는데 이번에는 이미지 분류이다 보니 기존모델을 전이학습 하도록 하겠습니다. 이미지 크기가 위에서 확인한결과 대락 450 x 450이니 라이트한 모델 resnet18로 전이학습하도록 하겠습니다.
하지만 resnet18은 input으로 칼라이미지(channel=3)를 넣어야 되기 때문에 그 앞에 self.init 클래스 속성에 input 값으로 흑백이미지를 받는 층을 먼저 깔아줍니다.(in_channel=1,out_channel=3)
그리고 resnet18모델을 쌓은후 nn.linear층으로 분류해야하는 최종 class:4로 output을 바꿔주고 multiclass classification이다 보니 마지막층에 4개의 output을 0~1사이 확률 값으로 바꿔주는 softmax 층을 쌓겠습니다.
Network 클래스를 만든 뒤 인스턴스를 만들어줍니다.
5) 학습 실시
lr = 0.001
step_size = 30
gamma = 0.01
total_epoch = 1
train_dataloader = DataLoader(train_dataset, batch_size=train_batch,shuffle=True)
val_dataloader = DataLoader(val_dataset, batch_size=val_batch)
test_dataloader = DataLoader(test_dataset, batch_size=test_batch)
print("###데이터로더 정의완료###")
model = network(class_num=class_num)
print("###모델 정의 완료(resnet18)###\n", summary(model))
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device=device)
print(f"\n### The device is --{device}-- that we use ###")
phase = input(str("Do you want to train ? (y or n) : "))
if phase == "y":
optimizer = optim.Adam(model.parameters(), lr=lr)
scheduler = optim.lr_scheduler.StepLR(
optimizer=optimizer, step_size=step_size, gamma=gamma
)
criterion = nn.CrossEntropyLoss()
total_loss = {"Train": [], "Val": []}
for epoch in range(total_epoch):
model.train()
epoch_train_loss = 0.0
for batch_index in (train_dataloader):
inputs, labels = batch_index
inputs = inputs.float()
labels = labels.float()
optimizer.zero_grad() # 초기화
if device == torch.device("cuda"):
inputs.to(device=device)
outputs = model(inputs)
else:
outputs = model(inputs)
loss = criterion(outputs, labels)
batch_train_loss = loss.item() # loss만 가져오기
print(batch_train_loss)
# print(batch_train_loss)
loss.backward() # 역전파 기록 저장
optimizer.step() # 업데이트
epoch_train_loss += batch_train_loss
avg_train_loss = epoch_train_loss / len(train_dataloader)
model.eval()
val_epoch_loss = 0.0
for batch_index in (val_dataloader):
inputs, labels = batch_index
inputs = inputs.float()
labels = labels.float()
with torch.no_grad():
if device == torch.device("cuda"):
inputs.to(device=device)
outputs = model(inputs)
else:
outputs = model(inputs)
loss = criterion(outputs, labels)
val_batch_loss = loss.item()
val_epoch_loss += val_batch_loss
avg_val_loss = val_epoch_loss / len(val_dataloader)
total_loss["Train"].append(avg_train_loss)
total_loss["Val"].append(avg_val_loss)
print(
f"epoch : {epoch} The train loss is {avg_train_loss}, valid loss is {avg_val_loss}"
)
scheduler.step()
torch.save(model.state_dict(),save_path)
x = np.arange(1, total_epoch + 1)
plt.plot(x, total_loss["Train"], "r", label="train")
plt.plot(x, total_loss["Val"], "b", label="val")
plt.legend()
plt.title("Tumor Deeplearning")
plt.xlabel("epoch")
plt.ylabel("loss")
plt.show()1) parameter 지정
학습에 필요한 learningrate, 스텝러닝레이트 스케쥴러를 사용할거기 때문에(step=30마다 gamma값만큼 곱해져서 lr줄어듦) step_size, gamma 설정하고 몇번 학습할건지 설정합니다.
후에 device를 설정합니다. gpu달려있으면(cuda, cudnn설정) 없으면 cpu로 연산 진행
2) 딥러닝에 필요한 옵티마이저, 스케쥴러, 손실함수 설정
train 할거면 input으로 y로 신호를 줍니다. y로 입력이 있으면 옵티마이저(아담), 스케쥴러(스텝 스케쥴러), 멀티클래스분류이기 때문에 손실함수(Crossentropy)를 설정합니다.
3) 학습(Train), 검증(Validation) 실시
Network를 train으로 설정한 뒤 Optimzer를 초기화 하고 train_dataloader로 데이터를 batch 만큼 Network에 입력시킵니다. 그 뒤 output 값(x1확률,x2확률,x3확률,x4확률) 값과 실제 값(원핫 인코딩으로 인해 이런식으로 됨 : 0,0,0,1)을 설정한 loss 함수로 loss를 계산한뒤 backward로 미분합니다. 후에 저장된 gradient값을 optimizer로 업데이트 하고 loss를 loss저장 딕셔너리에 저장합니다.
validation을 진행하는데 network를 eval모드로 설정합니다. with_no_grad로 자동 gradient추적을 멈춥니다. 그리고 input 데이터를 valid batch=1 만큼 Network에 결과를 도출한뒤 똑같이 loss를 계산하고 loss저장 딕셔너리에 저장합니다.
4) 결과 시각화(loss)
이제 epoch마다 위 과정을 반복하면서 매 epoch_loss값들을 저장한뒤 시각화 합니다.
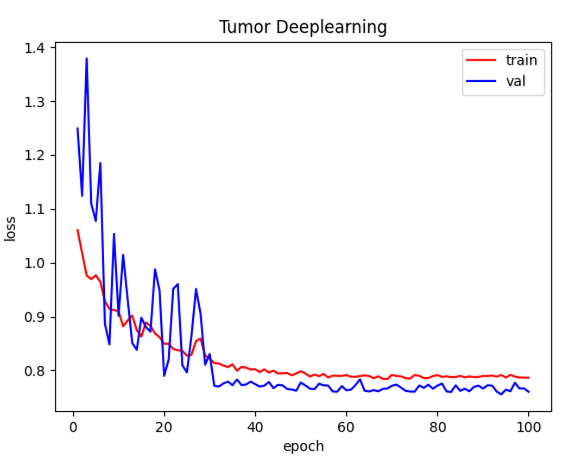
초반에 Validation loss의 변동폭이 매우 컸지만 epoch이 진행될수록 loss가 정상적으로 줄어드네요
6) 테스트 실시
elif phase == "n":
test_results = []
grad_image = []
model = network(class_num=class_num)
model.load_state_dict(torch.load(save_path))
model.eval()
for i,batch_index in enumerate(test_dataloader):
inputs, labels = batch_index
inputs = inputs.float()
labels = labels[0]
result1 = torch.where(labels == labels.max())[0]
with torch.no_grad():
outputs = model(inputs)[0]
result2= torch.where(outputs == outputs.max())[0]
test_result = True if result1 == result2 else False
print(test_result)
test_results.append(test_result)
ok = test_results.count(True)
ng = test_results.count(False)
accuracy = ok / (ok+ng)
print(f"Test 결과 OK 개수:{ok}, NG개수:{ng}, 정확도 : {accuracy}")train signal을 n으로 줘서 test만 한다고 설정했을 때 실행 되는 구문입니다.
train Network와 동일한 Structure를 구성하기 위해 같은 instantce를 생성한 뒤 저장한 모델(weight)들을 뒤집어 씌웁니다.
validation과 유사하게 Network를 eval모드로 바꾸고 input을 test 데이터들을 Dataloader로 Network에 입력시켜 test를 실시합니다.후에 predicted 값들과 실제 라벨값들을 비교해서accuracy를 측정합니다.
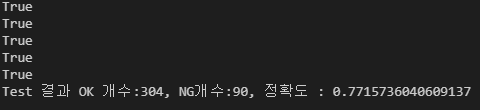
정확도가 77%네요 앞선 엑셀데이터 보다는 전이 학습을 실시 했음에도 많이 하락했습니다 여러가지 요인이 있겠지만 아마도 초반에 말했던 이미지 크기가 다른게 큰것 같네요.
train, validation 이미지 크기는 비슷한데 비해 testing 이미지 크기는 100픽셀보다 적었네요
loss가 굉장히 낮았던 validation set으로 검사해보니 아래와 같이 결과가 나오네요

역시 딥러닝 정확도는 데이터가 딥러닝 적용에 알맞은 데이터일 수록 상승하네요!
전체코드
import os
import torch
import numpy as np
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
import pandas as pd
import albumentations as A
from torchvision import models
from PIL import Image
from torchinfo import summary
from torch.utils.data import Dataset, DataLoader
from albumentations.pytorch.transforms import ToTensorV2
# dataset class
class dataset(Dataset):
def __init__(self, data):
self.x = data["numpy"]
self.y = data["label"]
def __len__(self):
return len(self.y)
def __getitem__(self, index):
single_x = self.x[index]
single_y = self.y.iloc[index]
single_y = torch.tensor(single_y)
self.augmentor = self.augmentation()
augmented = self.augmentor(image=single_x)["image"]
normalizated = self.normalization(augmented)
return normalizated, single_y
def augmentation(self):
pipeline = []
pipeline.append(A.HorizontalFlip(p=0.5))
pipeline.append(A.RandomBrightnessContrast(p=0.5))
pipeline.append(A.CenterCrop(height=167,width=174,p=1))
pipeline.append(ToTensorV2(transpose_mask=True, p=1))
return A.Compose(pipeline, p=1)
def normalization(self, array):
normalizated_array = (array - array.min()) / (array.max() - array.min())
return normalizated_array
class network(nn.Module):
def __init__(self, class_num):
super().__init__()
self.class_num = class_num
self.init = torch.nn.Conv2d(in_channels=1, out_channels=3, kernel_size=(1, 1))
self.model = models.resnet18(pretrained=True)
self.num_ftrs = self.model.fc.in_features
self.model.fc = nn.Linear(
in_features=self.num_ftrs, out_features=self.class_num
)
self.softmax = torch.nn.Softmax(dim=1)
def forward(self, x):
output = self.init(x)
output = self.model(output)
output = self.softmax(output)
return output
def split_feature_label(file_path):
label = file_path.split("\\")[1]
img = Image.open(file_path).convert("L")
img_array = np.array(img, dtype=np.uint8)
return img_array, label
def fileopen_splitdata_labeling(dir):
train_data = {"numpy": [], "label": []}
val_data = {"numpy": [], "label": []}
test_data = {"numpy": [], "label": []}
train_shape = np.zeros(2)
val_shape = np.zeros(2)
test_shape = np.zeros(2)
test_path = []
for (directory, _, filenames) in os.walk(dir):
if "Training" in directory:
for filename in filenames:
if ".jpg" in filename:
file_path = os.path.join(directory, filename)
img_array, label = split_feature_label(file_path=file_path)
train_shape = train_shape + img_array.shape
train_data["numpy"].append(img_array)
train_data["label"].append(label)
elif "Validation" in directory:
for filename in filenames:
if ".jpg" in filename:
file_path = os.path.join(directory, filename)
img_array, label = split_feature_label(file_path=file_path)
val_shape = val_shape + img_array.shape
val_data["numpy"].append(img_array)
val_data["label"].append(label)
elif "Testing" in directory:
for filename in filenames:
if ".jpg" in filename:
file_path = os.path.join(directory, filename)
test_path.append(file_path)
img_array, label = split_feature_label(file_path=file_path)
test_shape = test_shape + img_array.shape
test_data["numpy"].append(img_array)
test_data["label"].append(label)
train_data["label"] = pd.get_dummies(train_data["label"])
val_data["label"] = pd.get_dummies(val_data["label"])
test_data["label"] = pd.get_dummies(test_data["label"])
train_avg_shape = train_shape / len(train_data["numpy"])
val_avg_shape = val_shape / len(val_data["numpy"])
test_avg_shape = test_shape / len(test_data["numpy"])
print(f"\n\n###데이터 셋 별 평균 이미지 크기 확인###\n!!!!WARNING!!!!")
print(f"1. train데이터 평균 이미지 크기 : {train_avg_shape}")
print(f"2. val데이터 평균 이미지 크기 : {val_avg_shape}")
print(f"3. test데이터 평균 이미지 크기 : {test_avg_shape}")
return train_data, val_data, test_data,test_path
if __name__ == "__main__":
dir = "./Brain Tumor MRI Classfication/"
save_path = "./model/brain_tumor_epoch30.pt"
train_data, val_data, test_data,test_path = fileopen_splitdata_labeling(dir=dir)
class_num = len(set(train_data["label"]))
train_dataset = dataset(train_data)
val_dataset = dataset(val_data)
test_dataset = dataset(test_data)
print("\n###데이터셋 정의완료###")
train_batch = 32
val_batch = 1
test_batch = 1
lr = 0.001
step_size = 30
gamma = 0.01
total_epoch = 1
train_dataloader = DataLoader(train_dataset, batch_size=train_batch,shuffle=True)
val_dataloader = DataLoader(val_dataset, batch_size=val_batch)
test_dataloader = DataLoader(test_dataset, batch_size=test_batch)
print("###데이터로더 정의완료###")
model = network(class_num=class_num)
print("###모델 정의 완료(resnet18)###\n", summary(model))
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device=device)
print(f"\n### The device is --{device}-- that we use ###")
phase = input(str("Do you want to train ? (y or n) : "))
if phase == "y":
optimizer = optim.Adam(model.parameters(), lr=lr)
scheduler = optim.lr_scheduler.StepLR(
optimizer=optimizer, step_size=step_size, gamma=gamma
)
criterion = nn.CrossEntropyLoss()
total_loss = {"Train": [], "Val": []}
for epoch in range(total_epoch):
model.train()
epoch_train_loss = 0.0
for batch_index in (train_dataloader):
inputs, labels = batch_index
inputs = inputs.float()
labels = labels.float()
optimizer.zero_grad() # 초기화
if device == torch.device("cuda"):
inputs.to(device=device)
outputs = model(inputs)
else:
outputs = model(inputs)
loss = criterion(outputs, labels)
batch_train_loss = loss.item() # loss만 가져오기
print(batch_train_loss)
# print(batch_train_loss)
loss.backward() # 역전파 기록 저장
optimizer.step() # 업데이트
epoch_train_loss += batch_train_loss
avg_train_loss = epoch_train_loss / len(train_dataloader)
model.eval()
val_epoch_loss = 0.0
for batch_index in (val_dataloader):
inputs, labels = batch_index
inputs = inputs.float()
labels = labels.float()
with torch.no_grad():
if device == torch.device("cuda"):
inputs.to(device=device)
outputs = model(inputs)
else:
outputs = model(inputs)
loss = criterion(outputs, labels)
val_batch_loss = loss.item()
val_epoch_loss += val_batch_loss
avg_val_loss = val_epoch_loss / len(val_dataloader)
total_loss["Train"].append(avg_train_loss)
total_loss["Val"].append(avg_val_loss)
print(
f"epoch : {epoch} The train loss is {avg_train_loss}, valid loss is {avg_val_loss}"
)
scheduler.step()
torch.save(model.state_dict(),save_path)
x = np.arange(1, total_epoch + 1)
plt.plot(x, total_loss["Train"], "r", label="train")
plt.plot(x, total_loss["Val"], "b", label="val")
plt.legend()
plt.title("Tumor Deeplearning")
plt.xlabel("epoch")
plt.ylabel("loss")
plt.show()
elif phase == "n":
test_results = []
model = network(class_num=class_num)
model.load_state_dict(torch.load(save_path))
model.eval()
for i,batch_index in enumerate(val_dataloader):
inputs, labels = batch_index
inputs = inputs.float()
labels = labels[0]
result1 = torch.where(labels == labels.max())[0]
with torch.no_grad():
outputs = model(inputs)[0]
result2= torch.where(outputs == outputs.max())[0]
test_result = True if result1 == result2 else False
print(test_result)
test_results.append(test_result)
ok = test_results.count(True)
ng = test_results.count(False)
accuracy = ok / (ok+ng)
print(f"Test 결과 OK 개수:{ok}, NG개수:{ng}, 정확도 : {accuracy}")
이미지 멀티 레이블 classification 할때 도움됐으면 좋겠습니다.

test와 val dataset에도 실수로 train과 같은 aug를 줘버렸네요 원래는 pipeline에 test,val일 경우 Hoz flip과 RandomBrightnessContrast aug는 빼는게 맞습니다.